FAKTORER SOM PÅVERKAR RISKEN ATT AVLIDA EFTER EN STROKE
|
|
|
- Klara Johansson
- för 5 år sedan
- Visningar:
Transkript

1 FAKTORER SOM PÅVERKAR RISKEN ATT AVLIDA EFTER EN STROKE En överlevnadsanalys med fokus på interaktion mellan kön och socioekonomiska faktorer Fredrik Nilsson, Mikael Marklund Hjelm Kandidatuppsats 15 hp Statistik C2 15 hp Umeå Universitet Vt 2017
2 Sammanfattning Stroke är den tredje vanligaste dödsorsaken i Sverige efter hjärtsjukdom och cancer. Varje år insjuknar personer för första gången och ytterligare personer återinsjuknar i sjukdomen. Datamaterialet till den här studien erhölls från kvalitetsregistret för svensk strokevård, Riksstroke. Riksstroke har som huvudsyfte att se till att strokesjukvården på våra sjukhus ständigt förbättras och utvecklas. Uppsatsens syfte var att förklara vilka faktorer som påverkar dödlighet efter insjuknande i stroke samt undersöka om det fanns någon interaktion mellan kön och socioekonomiska faktorer(utbildningsnivå, inkomstnivå och ensamboende). Studien genomfördes med överlevnadsanalys där metoden Cox proportional hazard regression tillämpades. Resultaten visade att faktorerna ålder, medvetandegrad vid ankomst till sjukhus, kön, rökning, typ av stroke, boende på institution, annan sjuklighet och olika socioekonomiska faktorer hade en signifikant effekt på risken att dö efter insjuknande i stroke. Om en individ var medvetslös vid inläggning så var risken 7,9 (hasard-kvot (HR), 7,876; 95 % konfidensintervall (KI), 7,546 8,221) gånger högre att avlida efter en stroke jämfört med en individ som var alert vid inläggning. För en patient som var 85 år eller äldre var risken 5,8 (HR, 5,779; 95 % KI, 5,389 6,197) gånger högre att avlida jämfört med en patient som var mellan år. Dessutom visade det sig att det fanns en interaktion mellan kön och inkomstnivå. Lägre inkomstnivå ökade risken att avlida efter insjuknande i stroke för män dagar efter insjuknande i stroke var sannolikheten för en man med hög inkomstnivå att överleva cirka 70 %, medan den var 65 % för en man med låg inkomstnivå. För kvinnor varierade sannolikheten att överleva dagar mellan % för de olika inkomstgrupperna. Varför det skiljer sig mellan inkomstgrupper för de båda könen är svårt att sia om utifrån våra resultat. Ytterligare undersökningar kring detta samband bör genomföras. 2
3 Abstract Title: Factors affecting the risk of death after stroke - A survival analysis focusing on the interaction between gender and socioeconomic factors Stroke is the third most common cause of death in Sweden after cardiovascular disease and cancer. Every year people gets the disease for the first time and people get a recurrent stroke. The data material used in this study comes from the Swedish stroke register, Riksstroke. Riksstrokes main purpose is to ensure that the stroke care in our hospitals is continually improved and developed. The purpose of the thesis is to explain the factors that affects mortality after stroke and see if there is any interaction between gender and socio-economic factors (education level, income level, living alone). The analysis was performed with survival analysis using Cox proportional hazard regression. It was found that several factors affect the risk of death after stroke and that there was an interaction between gender and income level. If an individual was unconscious when they were hospitalized the risk was 7.9 (Hazard ratio (HR), 7.876; 95 % Confidence interval (CI), ) times higher to die after a stroke compared to an individual who was alert when hospitalized. For a person who was 85 years of age or older, the risk was 5.8 (HR, 5.779; 95% CI, ) times higher to die than a person who was between years of age. The study showed that low disposable income increased the risk of dying after stroke for men, while it hardly affected the risk for women. The probability to survive 1000 days after a stroke was, for a man with high income, about 70%, while it was 65% for a man with lowincome. For women, the probability to survive 1000 days varied between 69-70%, barely any difference. Why the effect of income on death differs between men and women is difficult to determine based on our results. Further investigations about this relationship should be made. 3
4 Populärvetenskaplig sammanfattning Varje år insjuknar svenskar i stroke och det är den tredje vanligaste dödsorsaken i Sverige. Syftet med den här studien var att ta reda på vilka faktorer som påverkar risken att avlida efter en stroke, där ett speciellt fokus läggs på att undersöka hur socioekonomiska faktorer(utbildningsnivå, inkomstnivå och ensamboende) samvarierar med kön. Genom överlevnadsanalys har den här studien analyserat ett data på drygt patienter mellan åren 2010 till 2012 från Riksstroke. Riksstroke är ett register där cirka 95 % av de som drabbas av stroke registreras. Våra resultat visade att faktorerna ålder, medvetandegrad vid ankomst till sjukhus, kön, rökning, typ av stroke, boende på institution, annan sjuklighet och olika socioekonomiska faktorer påverkar risken att dö efter en stroke. Faktorn medvetandegrad hade störst påverkan, en patient som var medvetslös vid inläggning hade en 7,9 gånger högre risk att avlida efter en stroke jämfört med en patient som var alert vid inläggning. Ålder hade näst störst påverkan. För en patient som var 85 år eller äldre var risken 5,8 gånger högre att avlida jämfört med en patient som var mellan år. Resultaten visade även att inkomstnivå samvarierar med kön. Det visade sig att lägre inkomst var en större riskfaktor för män än för kvinnor. 4
5 Innehållsförteckning 1. Bakgrund Syfte och frågeställningar Överlevnadsanalys Censurering Kaplan-Meier Cox proportional hazard regression Kontroll av antagande för Cox proportional hazard regression Interaktioner Hantering av bortfall Empiriskt exempel: Överlevnad efter stroke Beskrivning av datamaterialet Transformationer Hantering av bortfall Statistisk analys Etiska överväganden Resultat Grafisk överblick Cox proportional hazard regression antaganden Slutgiltig Cox PH-modell Diskussion Datamaterial- och metoddiskussion Resultatdiskussion Tillkännagivande Referenser Appendix 1 - Kaplan-Meier-kurvor Appendix 2 Utskrift för Log-rank-testen Appendix 3 Utskrift för tidsberoende testen Appendix 4 - Log-log plottar Appendix 5 Cox-överlevnadskurvor Appendix 6 Typ av stroke (CVSA) modifierad
6 1. Bakgrund Stroke är ett tillstånd där en person fått en del av hjärnans nervceller skadade på grund av syrebrist. Orsaken till detta är antingen en hjärnblödning eller en hjärninfarkt(propp). Stroke är den tredje vanligaste dödsorsaken i Sverige efter hjärtsjukdom och cancer. Varje år insjuknar personer för första gången och ytterligare personer återinsjuknar i sjukdomen (Jönsson, 2012). Av personer som har fått stroke är cirka 87 % fortfarande vid liv efter tre månader (Eriksson, Norrving, Terént, & Stegmayr, 2008). Av de drabbade är 80 % över 65 års ålder. Stroke är den icke-psykiska sjukdom som svarar för flest vårddagar på svenska sjukhus, närmare 1 miljon årligen. För personer som drabbats av stroke krävs stora resurser från samhället i kommunala boenden och hemtjänst. Den totala samhällskostnaden beräknas uppgå till drygt 18 miljarder kronor varje år (Riksstroke, 2017). Datamaterialet till den här studien har erhållits från Riksstroke. Riksstroke är ett nationellt kvalitetsregister som startade Ett nationellt kvalitetsregister innehåller individbaserade uppgifter om resultat inom hälso- och sjukvård och bidrar till att utveckla kvalitén inom hälso- och sjukvården. Således har Riksstroke som huvudsyfte att se till att strokesjukvården på våra sjukhus ständigt förbättras och utvecklas och att skillnader mellan regioner och sjukhus utjämnas. Varje år registreras vårdtillfällen. Det inkluderar akuta insjuknanden och uppföljningar som görs tre och tolv månader efter insjuknandet. Utifrån 2011 års data registreras cirka 95 % av alla som insjuknar i stroke i registret (Riksstroke, 2017). Tidigare forskning har visat att det finns ett samband mellan låg överlevnad efter stroke och ett flertal olika faktorer. Däribland hög ålder, manligt kön, diabetes och rökning. Det finns även dokumenterat att socioekonomisk status spelar en roll (Eriksson, Asplund, Glader, & Norrving, 2015), där personer med lägre socioekonomisk status har en ökad risk att avlida efter insjuknande i stroke. Det har gjorts färre studier där man tittar mer specifikt på interaktionstermer mellan kön och socioekonomiska faktorer. I en tidigare studie på datamaterial från Riksstroke för åren har skillnader i överlevnad mellan könen i socioekonomiska faktorer visats för patienter i åldrarna och som drabbats av stroke för första gången (Lindmark, Glader, Asplund, Norrving, & Eriksson, 2014). 1.1 Syfte och frågeställningar Vi vill skatta hur olika faktorer påverkar risken att avlida efter att man har insjuknat i stroke. För att ta reda på detta kommer vi att göra en överlevnadsanalys. Överlevnadsanalys är en samling statistiska metoder som används för att analysera om och när en händelse av intresse inträffar under en given tidsperiod (Mills, 2011). Vår överlevnadsanalys kommer att ske med Cox proportional hazard regression model. Vår uppsats ämnar mer specifikt att: 1. Beskriva metoder för överlevnadsanalys 6
7 2. Analysera vilka faktorer har en påverkan på risken att avlida efter insjuknande i stroke, med fokus på att undersöka om det finns någon interaktion mellan kön och socioekonomiska faktorer (utbildningsnivå, disponibel inkomst och ensamboende). 2. Överlevnadsanalys Detta avsnitt kommer att behandla överlevnadsanalys. I överlevnadsanalys är responsvariabeln tid tills en händelse inträffar (Kleinbaum & Klein, 2005). Responsvariabeln som används i överlevnadsanalys innehåller två delar med information, vilket gör att den skiljer sig åt från vanlig statistisk analys (Guo, 2010). Den första biten av information är tid, och tid räknas från att undersökningen startar tills händelsen av intresse inträffar. Den andra biten av information är händelse och med händelse avses en intressant händelse som drabbar en individ. Död, återfall i sjukdom och återhämtning från sjukdom är exempel på olika händelser. Händelsen anges i regel som ett misslyckande, eftersom händelsen ofta är en negativ händelse. I denna studie kommer överlevnadsanlys användas där tiden är antal dagar och händelsen att en individ avlider. 2.1 Censurering Ett centralt problem som måste hanteras med överlevnadsanalys är censurering. Censurering av en observation inträffar när det inte finns exakt information om när händelsen inträffar eller har inträffat, men det finns information om överlevnadstiden (Klein & Moeschberger, 2003). Om händelsen är att en individ avlider uppstår ofta fallet att en stor andel av individerna är vid liv när studien slutar. Dessa kommer att censureras. Censurering gör att vanlig statistisk analys inte räcker till. Om istället en logistisk regression med en binär responsvariabel (där 1=avlider och 0=överlever) väljs, skulle man inte ta hänsyn till tiden som individerna deltog i studien och därmed ignorera viktig information. Eftersom tiden som individerna deltar i studien kan i sig förklara varför de utsätts för händelsen. En logistisk regression kan inte besvara när och hur länge det tog för en individ att avlida. Logistisk regression ignorerar överlevnadstid och censurering. Ett annat alternativ skulle vara att välja en vanlig linjär regressionsmodell. Detta skulle också skapa problem eftersom den skulle tolka de censurerade som helt observerade och icke-censurerade. På grund av censurering fungerar inte logistik regression eller vanlig regression för tid till händelse data (Guo, 2010). Det finns tre olika kategorier av censurering Högercensurering Högercensurering innebär att observationen inte utsätts för händelsen innan studien har avslutats (Klein & Moeschberger, 2003). Högercensurering kan bero på tre orsaker: 1. Individen blir inte utsatt för händelsen av intresse innan studien är slut. 2. Individen försvinner under uppföljningsperioden. 3. Individen ångrar sig och väljer att inte längre delta i studien. 7
8 Denna typ av censurering förekommer i datamaterialet som ligger till grund för denna studie, eftersom det förekommer individer som inte avlidit under studiens tid Vänstercensurering Vänstercensurering inträffar när en observation utsätts för händelsen innan studien startat. I vänstercensurering vet man att observationen har utsatts för händelsen före studien påbörjat, men vet inte exakt vilken tidpunkt (Klein & Moeschberger, 2003). Vänstercensurering förekommer inte i datamaterialet till den här studien Intervallcensurering Intervallcensurering inträffar när överlevnadstiden för en observation enbart är känd inom vissa intervall och om observationen utsätts för händelsen i något intervall så vet man inte exakt när i intervallet detta inträffar (Klein & Moeschberger, 2003). Intervallcensurering förekommer inte i datamaterialet till den här studien. 2.2 Kaplan-Meier Kaplan-Meier-analys möjliggör uppskattning av överlevnadssannolikheter över den valda tidsperioden, även när individer censureras eller studeras under olika lång tid. Ett centralt begrepp inom överlevnadsanalys är överlevnadsfunktionen, S(t). Låt T vara en slumpmässig variabel för en individs överlevnadstid, T 0. Där t betecknar ett specifikt värde av överlevnadstiden T. Exempelvis, för att veta sannolikheten att en individ överlever mer än 10 år skulle då T>t=10 anges. Överlevnadsfunktionen ger en sannolikhet för att en individ undviker händelsen längre än tiden t. Om t=0 är sannolikheten att en individ undviker händelsen 1, eftersom ingen händelse kan då ha inträffat. Medan när tiden t blir sannolikheten 0 att en individ undviker händelsen (Kleinbaum & Klein, 2005). Överlevnadsfunktionen skrivs som: S t = P T t, t > 0. Antag att det finns n stycken oberoende observationer som betecknas (t i, c i ), i=1,2,3,,n, av den underliggande överlevnadstiden T och censureringsindikatorvariabeln C, där enbart högercensurering förekommer om inget annat anges (Hosmer, Lemeshow, & May, 2008). Bland de n observationerna existerar det n-m censurerade observationer, där m n. Överlevnadstiden rangordnas i storleksordning t (1) <t (2) < <t (m). Låt antalet som riskerar att avlida vid t (i) betecknas n i och det observerade antalet avlidna betecknas d i. Kaplan-Meierskattningen för överlevnadsfunktionen vid tidpunkt t är: S t = P T > t = n. d. n., där S t = 1, om t < t (1) (Hosmer, Lemeshow, & May, 2008). 8
9 2.2.1 Log-rank test För att jämföra Kaplan-Meier-överlevnadskurvor för kategoriska variabler används log-rank test. Nollhypotesen för en kategorisk variabel med två kategorier är att det inte förekommer någon övergripande skillnad mellan de två överlevnadskurvorna (Kleinbaum & Klein, 2005). Om den kategoriska variabeln har tre eller fler kategorier är nollhypotesen att de har en gemensam överlevnadskurva (Kleinbaum & Klein, 2005). 2.3 Cox proportional hazard regression model Cox proportional hazard regression model (Cox PH) var först introducerad i Regression Models and Life Tables (Cox, 1972). Cox PH ger ett uttryck för hasarden, risken att utsättas för en händelse, vid en tidpunkt t för en individ med ett givet antal förklaringsvariabler. Cox PH-modellen har två egenskaper som gör den attraktiv att använda. Den första är att den inte gör något antagande om fördelningen, det vill säga det är en fördelningsfri modell vilket gör den mer flexibel. Det andra är att den är robust, vilket betyder att den generellt ger bra approximationer oavsett vilken den sanna fördelningen är (Kleinbaum & Klein, 2005). Hasard-funktionen, h(t), anger den momentana sannolikheten att vid tidpunkten t utsättas för händelsen, givet att händelsen inte har inträffat än. Med andra ord ger hasardfunktionen på sätt och vis den omvända informationen jämfört med överlevnadsfunktionen (Kleinbaum & Klein, 2005). Cox PH använder inte tiden T till att händelsen inträffar som responsvariabel. Istället används hasard-funktionen: h t = lim 91 :; T < t + Δt t T P(t ). Δt Cox PH ger ett uttryck för risken att händelsen inträffar vid tidpunkt t för en individ med ett specifikt antal förklaringsvariabler X. Cox PH-modellen anges vanligtvis i termer av hasardmodellen: H F h t, X = h : t e 2IJ 2 G 2. (1) I formel (1) är h t, X den beroende variabeln ( riskrangen vid tidpunkt t för individ i). X är en vektor som innehåller k stycken förklaringsvariabler X 1, X 2,...,X k som används för att prediktera individ i:s risk. β 1 till β k är regressionskoefficienterna. Cox PH-modellen har egenskapen att om varje förklaringsvariabel är lika med noll reduceras formeln till h 0 (t). Det vill säga att den exponentiella delen av formeln blir e : = 1. Denna egenskap hos Cox PHmodellen är anledningen till varför h 0 (t) kallas baseline hasard-funktionen. Effekterna av förklaringsvariablerna är inte tidsberoende. En annan viktig egenskap hos Cox PH är att det är en semi-parametrisk modell. Modellen lämnar baseline-funktionen ospecificerad. Den andra delen av ekvationen består av e upphöjt till en linjär funktion av k stycken förklaringsvariabler. Vilket innebär att den skrivs som en linjär modell för log-hasarden 9
10 (Mills, 2011). Om exempelvis den rätta parametriska modellen är exponentiell kommer Cox PH-modellens resultat att vara jämförbart med resultat från en exponentiell modell (Kleinbaum & Klein, 2005). Detsamma gäller för andra parametriska modeller. Cox PH använder en partiell likelihood-funktion för att skatta parametrarna. Här tar likelihood formeln enbart hänsyn till individer som utsattes för händelsen och inte för de som blev censurerade (Mills, 2011). Genom att maximera denna funktion erhålls skattningarna av β., β.. Ett antagande som man gör i Cox PH-modellen är proportionell hasard. Överlevnadskurvor för kategorierna inom varje enskild förklaringsvariabel ska ha hasard-funktioner som är proportionella över tid. Med detta antagande stryks baseline hasard-funktionen, h : t, ur formeln och en skattad hasard-kvot, HR, för två individer kan uttryckas som: H HR = h(t, X ) h(t, X) = h R2 P t e 2IJ H = exp β. (X R h T t e 2IJ 2 S. X. ), 2 S 2 W.XY där X = X Y, X ],, X W och X = (X Y, X ],, X W ). X betecknar uppsättningen av förklaringsvariabler för en individ och X betecknar uppsättningen för en annan. Genomgående när tak/hatt används betecknar det en skattning. W HR = exp β. (X. X. ). Här framgår att hasard-kvoter kan skattas utan att specificera baseline-funktionen..xy 2.4 Kontroll av antagande för Cox proportional hazard regression Ett antagande för Cox PH är non-informative censoring. För att detta antagande ska vara uppfyllt ska orsaken till censurering av en individ inte vara relaterad till sannolikheten till att händelsen inträffar Antagandet om linjäritet Ett krav för att kunna använda Cox PH-modellen är att linjäritetsantagandet måste vara uppfyllt för de kontinuerliga variablerna, effekten av variabeln ska vara linjär avseende ln(hr) (Mills, 2011). För att kontrollera antagandet plottas Martingale-residualerna mot den förklarande variabeln för att upptäcka icke-linjäritet. Man inför en smoothing-line, anpassade kurva, i grafen med de plottade Martingale-Residualerna. Om linjäritetsantagandet är uppfyllt ska den anpassade kurvan följa en rät linje som har ett intercept och lutning som är lika med noll (Mills, 2011). 10
11 2.4.2 Antagandet om proportionell hasard Test för om en variabel är tidsberoende Vid bedömning av PH-antagandet för en förklaringsvariabel i taget är en metod att använda den utökade Cox PH-modellen, där antagandet om proportionell hasard inte krävs. Här visas den för förklaringsvariabel X: h t, X = h : t exp β Y X + β ] (X g t ), där g(t) är en funktion av tiden (Kleinbaum & Klein, 2005). Med ovanstående modell bedöms PH-antagandet genom att testa signifikansen för interaktionstermen. Där nollhypotesen är β 2 =0. Observera att om nollhypotesen inte kan förkastas exkluderas interaktionstermen och modellen reduceras till Cox PH-modellen enbart innehållandes variabeln X. Testet kan genomföras med antingen ett Wald-test eller ett likelihood ratio-test. I båda fallen har teststatistikan en χ 2 -fördelning med en frihetsgrad under nollhypotesen. Exempelvis, om PH-antagandet bedöms för kön utökas Cox PHmodellen till att inkludera en interaktion mellan kön och en funktion av tid. Om koefficienten för interaktionstermen är signifikant dras slutsatsen att PH-antagandet inte är uppfyllt (Kleinbaum & Klein, 2005) och problemet åtgärdas genom att använda den utökade Cox PHmodellen. Om man väljer att ignorera överträdelsen kommer Cox PH-modellen fungera som en relativt bra approximation (Allison, 1984). Om PH-antagandet inte är uppfyllt för en förklaringsvariabel representerar koefficienten ett genomsnittligt värde av effekten över observationsperioden (Allison, 2017). Om β ] 0 PH-antagandet ej uppfyllt. h t, X = h : t exp β Y sex + β ] (sex t). Ett annat sätt att hantera överträdelser av proportionalitetsantagandet är att använda sig utav det stratifierade Cox tillvägagångssättet. De förklaringsvariabler som uppfyller antagandet inkluderas i modellen och man stratifierar för den förklaringsvariabel som inte uppfyller antagandet (Kleinbaum & Klein, 2005). Man antar att den stratifierade variabeln har en påverkan på resultatet men att dess betydelse är sekundär jämfört med de variabler som är inkluderade i modellen (Hosmer, Lemeshow, & May, 2008) Grafisk granskning av proportionalitetsantagandet Kaplan-Meier-plottar är ett sätt att grafiskt kontrollera PH-antagandet. Genom att jämföra Kaplan-Meier-kurvor kan skillnader i överlevnad mellan olika grupper undersökas. Kurvorna jämförs för att se om de är proportionella och konstanta över tid. 11
12 Log-log-plottar är ett annat sätt att grafiskt undersöka PH-antagandet för en given kategorisk förklaringsvariabel där man justerar för de andra förklaringsvariablerna i modellen (Kleinbaum & Klein, 2005). Det finns ett matematiskt förhållande mellan hasard-funktionen och motsvarande överlevnadsfunktion för Cox PH-modellen (Kleinbaum & Klein, 2005). På så vis erhålls överlevnadsfunktionen från ekvation (1): S t, X = S T (t) c H 2IJ d 2 e 2, S 0 (t) betecknar baseline-överlevnadsfunktionen, som kan erhållas matematiskt givet att man känner till baseline-hasardfunktionen h 0 (t). Genom att ta logaritmen av Cox PH:s överlevnadsfunktion två gånger genereras: ln ln S(t, X = β i X i ln ln S 0 t. k i=1 Överlevnadsfunktionen tar ett värde mellan 0 och 1, och den naturliga logaritmen av ett sådant värde är negativt. För att kunna ta logaritmen en andra gång tillsätts ett minustecken i ekvationen. Eftersom man inte kan ta logaritmen av ett negativt tal. Betrakta två olika specifikationer av x-vektorn som motsvarar två olika individer, X * och X. De motsvarande log-log-kurvorna blir då: ln lns t, X = β. X. ln ( ln S : t W.XY W ln lns t, X = β. X. ln ( ln S : t.xy. Genom att subtrahera den andra log-log-kurvan från den första och via omskrivning ger detta: ln lns t, X = ln lns t, X + β. X. X. W.XY. Notera att baseline överlevnadsfunktionerna har tagit ut varandra och kvar blir ett uttryck för skillnaderna mellan log-log-kurvorna som inte innehåller t. Genom att plotta de två transformerade överlevnadsfunktionerna mot varandra kan PH-antagandet undersökas. Vid ett konstant avstånd mellan funktionerna är detta uppfyllt. (Kleinbaum & Klein, 2005) 12
13 2.5 Interaktioner En interaktionsterm är samspel mellan två förklaringsvariabler, effekten av den ena variabeln beror på värdet av den andra. Det finns olika sätt att bestämma vilka interaktionstermer som ska ingå i en modell. Vid inkludering av en interaktionsterm i modellen bör man även inkludera de ursprungliga förklaringsvariablerna, även om de inte är signifikanta när interaktionstermen inkluderas (Hosmer, Lemeshow, & May, 2008). Ett sätt att bestämma vilka interaktionstermer som ska inkluderas i modellen är att först inkludera alla möjliga interaktionstermer i modellen, för att sedan utesluta de som inte är signifikanta (Hosmer, Lemeshow, & May, 2008). Ett annat sätt är att på förhand välja ut och testa ett antal interaktionstermer som är av klinisk relevans (Hosmer, Lemeshow, & May, 2008). 2.6 Hantering av bortfall Det finns två olika typer av bortfall, dels att vissa observationer saknas helt eller partiellt bortfall där det saknas information för vissa variabler. Det finns flera olika metoder om hur bortfall ska hanteras. Nedan beskrivs tre olika tillvägagångssätt för att hantera bortfall Complete case-analys Vid användandet av complete case-analys exkluderas alla observationer som har något bortfall från analysen. Om datamaterialet har ett stort antal partiella bortfall går man miste om många observationer. Om de partiella bortfallen är slumpmässiga uppstår ingen bias, däremot minskar styrkan( power ) för analysen eftersom analysen utförs på färre observationer (Graham, 2012) Bortfall som en egen kategori För kategoriska variabler är ett annat sätt att hantera bortfall att inkludera de som en egen kategori. Observationer där värde saknas inkluderas i en ny kategori okänd där bortfallen hanteras som en enskild kategori. På så vis blir observationer med partiellt bortfall kvar i analysen (Jones, 1996) Multipel imputation Imputation används för att ersätta partiella bortfall med olika värden. En metod för imputation är multipel imputation. Varje saknat värde imputeras m gånger, där m 2. Detta ger m stycken olika datamaterial där inget utav dessa har något bortfall. Vanligtvis används samma stokastiska modell för varje imputation. Därefter analyseras alla m stycken datamaterial som om imputation aldrig har skett, de olika resultaten ger ett mått av den extra variansen som imputation medför (Lohr, 2010). 3. Empiriskt exempel: Överlevnad efter stroke Syftet med studien är att undersöka hur olika faktorer påverkar risken att avlida efter man har insjuknat i stroke och för att se om det fanns någon interaktion mellan kön och socioekonomiska faktorer(utbildningsnivå, inkomstnivå och ensamboende). 13
14 3.1 Beskrivning av datamaterialet Undersökningen baseras på ett datamaterial från Riksstroke som är insamlat mellan åren Datamaterialet innehåller observationer och 17 variabler. För uppgifter om överlevnad har patienterna följts upp genom samkörning med Socialstyrelsens dödsorsaksregister fram till Datamaterialet omfattar 15 stycken förklarande variabler och utfallet som innehåller två variabler(tid till händelse och typ av händelse: död/censurering). De förklarande variablerna består av år för insjuknande, ålder, medvetandegrad vid ankomst till sjukhus, kön, typ av stroke, rökning, boende på institution, ensamboende, kapabel att klara dagliga aktiviteter själv, tidigare stroke, förmaksflimmer, diabetes, blodtryckssänkande medicin, utbildningsnivå och disponibel inkomst. Av variablerna är disponibel inkomst och ålder kontinuerliga medan övriga är kategoriska, se Tabell 1. Tabell 1. Utförlig information om datamaterialets 17 ursprungliga variabler. Variabelnamn Förklaring av variabel Typ av variabel Kategori (*=referenskategori) InsjuknandeAr År vid insjuknande Kategorisk Andel obs i %/ Medel (sd) 33,9 33,3 32,8 Partiellt bortfall (*=Okänd behandlas som en egen kategori) 0 Alder Ålder Kontinuerlig Medel(sd): 75,7(12,4) 2 MedvetandegradA Medvetandesgrad vid ankomst till sjukhus Kategorisk 1=Alert* 2= Dåsig 3=Medvetslös Sex Kön Kategorisk 0=Kvinna* 1=Man CVSA Typ av stroke Kategorisk 61=Blödning 63=Propp/Infarkt* 64=Okänd RokerA Rökning Kategorisk -9=Okänd 1=Ja 2=nej* Institution_bl Boende på institution Kategorisk 0=Nej* 1=Ja LivingAlone_bl Om man lever ensam Kategorisk 0=Nej* 1=Ja ADL_bl Om man var beroende av hjälp för att klara dagliga aktiviteter innan insjuknandet (Toabesök, påklädning, gå inomhus). Kategorisk 0=Nej* 1=Ja 9=Okänd 81,4 12,3 5,2 48,8 51,2 11,8 86,6 1,5 8,1 12,7 79,1 89,6 10,0 49,2 50,2 86,1 11,8 2, * * 14
15 Diabetes Om man har diabetes Kategorisk 0=Nej* 1=Ja Hbp_bl Om man tar Kategorisk 0=Nej* blodtryckssänkande 1=Ja medicin AF Förmaksflimmer Kategorisk 0=Nej* 1=Ja Prevstroke Om man har drabbats av Kategorisk 0=Nej* stroke tidigare 1=Ja Edu_3cat Utbildningsnivå Kategorisk -9= Okänd 1=Grundskola 2=Gymnasium 3=Universitet* Income_adj Disponibel inkomst för hushållet justerad för konsumentprisindex Censor Överlevnad efter ha Kategorisk 0=Avliden insjuknat i stroke 1=Vid liv Timetoevent Tid, antal dagar, tills man avlider efter man har insjuknat i stroke(tid till händelse). Alternativt antal dagar man är med i studien till dess slut 31 dec , ,4 38,9 60, ,6 28,6 74,5 24,7 2,8 46,8 35,0 15, * Kontinuerlig Medel(sd): 1831,7(2320,6) ,0 71,0 Kontinuerlig Medel(sd): 415,2(336,7) Transformationer För en kontinuerlig variabel i Cox PH-modellen måste linjäritetsantagandet vara uppfyllt. Kontroll av antagandet genomfördes genom att undersöka Martingale-residual-plottar. För både ålder och disponibel inkomst var antagandet ej uppfyllt, vilket visas i avsnitt I tidigare studier från Riksstroke har ålder transformerats till en kategorisk variabel och delats upp i intervallen 18-64, 65-74, och 85 år och äldre (Eriksson, Asplund, Glader, & Norrving, 2015). Här utfördes indelningen på samma sätt. Variabeln disponibel inkomst transformerades till en kategorisk variabel med tre nivåer(låg, medel och hög inkomst). Där 19,2, 60 och 20,8 % av observationerna ingick i respektive grupp. 3.3 Hantering av bortfall Riksstroke har en täckningsgrad på cirka 95 % (Riksstroke, 2017). I datamaterialet förekom en del partiella bortfall. På grund av storleken på det partiella bortfallet för tre av de kategoriska variablerna har det behandlats som en egen kategori. Dessa variabler var rökning, utbildningsnivå och om man var beroende av hjälp för att klara dagliga aktiviteter. De hade ett partiellt bortfall på 6 148, respektive stycken. Ytterligare tio av de andra variablerna hade partiellt bortfall, men i mindre mängd, se Tabell 1. Dessa partiella bortfall behandlades med complete case-analys, med andra ord uteslöts de patienterna ur analysen. Detta ledde till att totalt (4,3 %) observationer uteslöts ur analysen från det ursprungliga datamaterialet. 15
16 3.4 Statistisk analys I denna studie blev en patient censurerad om patienten överlevde hela studietiden eller valde att hoppa av. I praktiken kan avhopp endast ske genom emigration, eftersom patienterna då inte följs upp i Socialstyrelsens dödsregister. Antalet patienter som emigrerar är väldigt begränsat. Antagandet om non-informative censoring bedöms som rimligt och antogs vara uppfyllt. Kaplan-Meier-kurvor användes för att deskriptivt undersöka överlevnad i olika grupper av patienter. Viktigt att tänka på när Kaplan-Meier-kurvor analyseras är att variablerna är ojusterade för övriga variabler. Hasard-kvoter skattades med Cox proportional hazard regression model, där Wald-test användes för att testa signifikansen för förklaringsvariablerna i modellen samt att ge 95%-iga konfidensintervall för hasard-kvoterna. Antagandet om linjäritet undersöktes för de kontinuerliga förklaringsvariablerna genom att plotta Martingale-residualerna mot respektive variabel. Överträdelse av antagandet behandlades genom att transformera variabeln till en kategorisk variabel. Kontroll av det proportionella hasard-antagandet undersöktes först genom ett test av tidsberoende effekt. För att utvärdera storleken på eventuella avvikelser från antagandet undersöktes dessa sedan grafiskt genom log-log-plottar. Då undersökning via log-logplottarna fortfarande vittnade om större avvikelser från PH-antagandet utfördes ytterligare analys. Först testades variablerna genom att använda det stratifierade Coxtillvägagångssättet. Sedan testades de genom att inkluderas som tidsberoende variabler. Vid byggandet av Cox PH-modellen inkluderas samtliga förklarande variabler. Vid ett ickesignifikant p-värde på teststatistikan hos en variabel uteslöts den ur modellen. Vid flera ickesignifikanta variabler utesluts den variabel med högst p-värde på teststatistikan och den nya modellen testas. Detta upprepades till dess att en modell med enbart signifikanta variabler erhölls. Eftersom syftet med den här studien var att undersöka om socioekonomiska faktorer har olika påverkan på risken att avlida för män och kvinnor innebar det att det på förhand existerade ett antal specificerade interaktionstermer som var av klinisk relevans. Interaktionstermer mellan kön och de socioekonomiska faktorerna utbildningsnivå, inkomstnivå och ensamboende inkluderades. De icke-signifikanta interaktionstermerna uteslöts ur modellen. Alla test utfördes på 5 % signifikansnivå. IBM SPSS Statistics Version 24 användes för de statistiska analyserna. 3.5 Etiska överväganden Riksstroke är ett kvalitetsregister vars syfte är att bidra till en bättre och likvärdig strokevård bland alla patienter på alla sjukhus i Sverige. De deltagande, alltså de som drabbas av stroke, och deras anhöriga informeras om Riksstrokes grundläggande syfte och att data kan 16
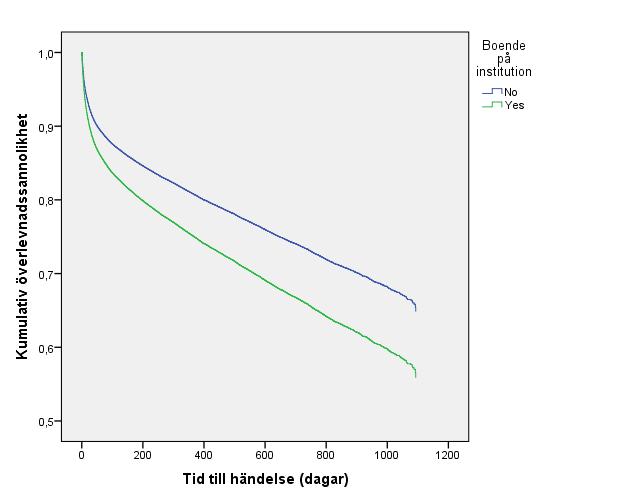
17 användas till forskningsändamål efter etikprövning. De deltagande får också veta att de har rätt att avstå från att registreras i kvalitetsregistret, vilket väldigt få väljer att göra. (Eriksson M., Ojämlikheter i svensk strokevård med avseende på socioekonomisk status, födelseland, kön och ålder, 2012) Riksstroke har skickat sitt data till SCB och Socialstyrelsen som skött samkörningar på individnivå med hjälp av personnummer för deltagarna som medverkat i studien. Dessa samkörda filer avidentifierades av SCB och Socialstyrelsen. Avidentifieringen skedde genom att personnumren togs bort. De avidentifierade filerna är de filer som forskare fått tillgång till. Data presenteras på gruppnivå vilket gör att identifiering av enskilda individer är omöjligt. Att delta i kvalitetsregistret utsatte inte patienterna för någon större risk. Risken var att obehöriga kommer åt uppgifter och får information om vård och hälsa för en patient. För de patienter som valde att delta i kvalitetsregistret skyddas uppgifterna av hälso- och sjukvårdssekretessen i Offentlighets- och sekretesslagen. Det innebar att enbart uppgifter som inte kan skada patienten eller dess anhöriga lämnades ut. Uppgifterna i kvalitetsregistret skyddas så att inga obehöriga kommer åt dem. Detta utfördes genom att kryptera data och att det krävs inloggning för att få ta del av uppgifterna som ingår i kvalitetsregistret (Eriksson G., 2012). Den här uppsatsen ingår som en del i EqualStroke-projektet som godkänts av etikprövningsnämnden i Umeå (DNR: M ). Filerna som vi fått tillgång till innehåller en begränsad mängd variabler, utan kodnyckel och utan möjlighet till bakåtspårning av individer. Till exempel har inga datum lämnats ut, utan enbart tid från insjuknande till död i antal dagar. 4. Resultat Under en sammanlagd observationstid på tre år avled (29 %) patienter. 4.1 Grafisk överblick Kaplan-Meier Detta avsnitt avser att presentera och jämföra Kaplan-Meier-kurvor för fyra stycken kategoriska förklaringsvariabler, se Figur 1. Beroende på vilken inkomstgrupp en patient tillhörde skilde sannolikheten att överleva dagar efter insjuknande i stroke, se grafen längst upp till vänster. För patienter med hög inkomst var sannolikheten 80 %, för de med låg inkomst 65 % och för de med medel inkomst 60 %. Överlevnad varierade också med grad av utbildning. För patienter med universitetsutbildning var sannolikheten att överleva efter dagar 75 %, de med gymnasieutbildning hade en sannolikhet på 70 % och motsvarande sannolikhet för de med grundskoleutbildning var 60 %. Även ålder hade en betydelse, ökad ålder medförde en ökad risk att avlida. Patienter i åldrarna år var sannolikheten att överleva dagar 90 %. För patienter i åldersgrupperna 65-74, och 85 eller äldre 17


18 var sannolikheten att överleva 85, 65 respektive 35 %. Även mellan könen varierar sannolikheten för överlevnad, se grafen längst ned till höger. Efter dagar var sannolikheten för kvinnor att överleva 60 %, 10 procentenheter lägre jämfört mot männens 70 %. Se Appendix 1 för Kaplan-Meier-kurvor för övriga variabler. Figur 1. Kaplan-Meier-överlevnadskurvor för inkomstgrupper, utbildningsnivåer, åldersgrupper och kön Log-rank test Samtliga log-rank-test var signifikanta, se Tabell 2. För varje variabel var det en signifikant skillnad mellan minst två av variabelkategoriernas överlevnadskurvor. Tabell 2. P-värden för Log-Rank-testen. Originalutskriften för log-rank-testen återfinns i Appendix 2. Variabel p-värde Åldersgrupper <0,001 Medvetandegrad <0,001 Kön <0,001 Typ av stroke <0,001 18
19 Rökning <0,001 Boende på institution <0,001 Ensamboende <0,001 Beroende av hjälp för att klara <0,001 dagliga aktiviteter innan insjuknandet Tidigare stroke <0,001 Förmaksflimmer <0,001 Diabetes <0,001 Blodtryckssänkande medicin <0,001 Utbildningsnivå <0,001 Inkomstgrupper <0, Cox proportional hazard regression antaganden Antagandet om linjäritet: I Figur 2 undersöks om linjäritetsantagandet är uppfyllt för de två kontinuerliga variablerna ålder och disponibel inkomst. I grafen för disponibel inkomst följer inte dess smoothing-line den streckade räta linjen som har interceptet och lutningen som är lika med noll. Detta indikerar att antagandet ej är uppfyllt. För grafen med ålder ser det ut som dess smoothingline först har en negativ lutning för att sedan vid ålder 78 övergå till en positiv lutning. Även för variabeln ålder tycks antagandet inte vara uppfyllt, men det är inte lika tydligt som för disponibel inkomst. För vidare undersökning av antagandet inkluderades ålder i kvadrat som en förklaringsvariabel i modellen. Den kvadratiska termen visade sig vara signifikant (p<0,001), vilket stöder att åldersambandet inte är linjärt. Eftersom linjäritetsantagandet ej var uppfyllt transformerades dessa variabler till två kategoriska variabler. 19


20 Figur 2. Martingale-residualer för att kontrollera linjäritetsantagandet för de två kontinuerliga variablerna. Den grönstreckade linjen har ett intercept och lutning som är lika med noll. Den röda linjen är respektive variabels smoothing-line Antagandet om proportionell hasard Tidsberoende test I Tabell 3 presenteras en sammanfattning av de tidsberoende testen. Alla test utfördes på 5 % signifikansnivå och under nollhypotesen att proportionalitetsantagandet var uppfyllt. Antagandet var inte uppfyllt för variablerna åldersgrupper, medvetandegrad, kön, typ av stroke, rökning, beroende av hjälp för att klara dagliga aktiviteter, tidigare stroke, förmaksflimmer, diabetes och blodtryckssänkande medicin. Tabell 3. Visar p-värdena för alla variabler vid test av tidsberoende och exponentiella parameterskattningen, Exp(β), för tidsberoende variabeln. Se Appendix 3 för utförliga utskrifter. Variabel p-värde Exp(β) Åldersgrupper <0,001 1,000 Medvetandegrad <0,001 1,000 Kön <0,001 0,997 Typ av stroke <0,001 1,001 Rökning <0,001 1,000 Boende på institution 0,394 1,000 Ensamboende 0,887 1,000 Beroende av hjälp för att klara <0,001 1,000 dagliga aktiviteter innan insjuknandet Tidigare stroke <0,001 1,000 Förmaksflimmer 0,024 1,000 Diabetes 0,001 1,000 Blodtryckssänkande medicin <0,001 1,211 Utbildningsnivå 0,673 1,000 Inkomstgrupper 0,495 1,000 20
21 Log-log-plots För att kontrollera storleken på avvikelsen från proportionalitetsantagandet ytterligare undersöktes variablerna grafiskt i log-log-plottar. I Figur 3 nedan presenteras log-log-plottar för fyra variabler, plottar för övriga variabler återfinns i Appendix 4. För variablerna åldersgrupper och kön, de övre plottarna, ser avstånden ut att vara konstanta mellan de olika kurvorna, vilket innebär att den avvikelse som testet indikerade är liten. I grafen längst ned till höger, för variabeln typ av stroke, kan man urskilja att avståndet mellan linjerna minskar över tid och där två linjer korsar varandra. Proportionalitetsantagandet kan på så sätt inte tyckas vara uppfyllt för typ av stroke. Liknande tendenser för variabeln medvetandegrad kan tydas, att avståndet mellan linjerna tycks minska över tid, men att antagandet ändå antas vara uppfyllt. Figur 3. Log-log plots för att kontrollera PH-antagandet. Då både tidsberoendetest och undersökning via log-log-plottarna fortfarande vittnade om avvikelser från PH-antagande för variabeln typ av stroke utfördes ytterligare analyser. Först via stratifiering för variabeln och sedan genom att lägga in den som en tidsberoende variabel, se Appendix 6. Resultatet efter stratifiering för variabeln skilde sig knappt från de resultat utan stratifiering, detsamma gällde för resultatet då variabeln lades in som en tidsberoende variabel. På grund av detta valdes en modell innehållandes typ av stroke och 21
22 medvetandegrad trots avvikelse från PH-antagandet att presenteras. Effekten kan då tolkas som en genomsnittlig effekt över tidsintervallet. 4.3 Slutgiltig Cox PH-modell I Tabell 3 visas skattade parametervärden och hasard-kvoter för de variabler som ingår i den slutgiltiga modellen. I Figur 4 visas de skattade överlevnadskurvorna för medvetandegrad, utbildningsnivå, åldersgrupper och typ av stroke. Den kumulativa sannolikheten plottas mot tid till händelse för en variabel åt gången, där variabeln är justerad för de andra variablerna som är med i modellen. Resterande överlevnadskurvor återfinns i Appendix 5. Alla variabler som var med i modellen var signifikanta, utom kön och inkomstgrupper. Det beror på att interaktionstermen mellan kön och inkomstgrupper var med i modellen. Värdena på variablerna kön och inkomstgrupper kan inte tolkas separat utan endast genom interaktionstermen. Värdet på hasard-kvoten tolkas i förhållande till referensgruppen (givet att de andra är konstanta och är med i modellen). Medvetandegrad hade störst påverkan på risken att dö efter en stroke, se Tabell 3 och Figur 4. För en patient som var medvetslös vid inläggning var risken större att dö efter en stroke jämfört mot en patient som var i referensgruppen alert (HR = 7,876; 95 % KI, 7,546 8,221). För en patient som var dåsig var HR = 2,865 (95 % KI, 2,769 2,963) jämfört mot en patient som var alert. Risken att dö efter att man drabbats av stroke ökade med åldern. Hasard-kvoterna presenteras för de olika åldersgrupperna mot referensgruppen år. För en patient som var mellan år var HR = 2,001 (95 % KI, 1,865 2,155), för åringar var HR = 3,380 (95 % KI, 3,156 3,620) och för de som var 85 år och äldre var HR = 5,779 (95 % KI, 5,389 6,197). För patienter som drabbats av hjärnblödning var HR = 1,736 (95 % KI, 1,592 1,892) jämfört mot de som drabbats av en propp. För de patienter som rökte var HR = 1,097 (95 % KI, 1,038 1,159) och där rökstatus var okänd var HR = 1,383 (95 % KI, 1,324 1,444). För de patienter som behövde hjälp för att klara dagliga aktiviteter innan insjuknandet var HR = 1,606 (95 % KI, 1,543 1,672) och där statusen var okänd var HR = 2,160 (95 % KI, 2,010 2,321). Vidare visade resultaten på att ju lägre utbildningsnivå en individ hade desto högre var risken att dö efter en stroke. Jämfört mot referensgruppen universitetsutbildade var HR = 1,150 (95 % KI, 1,095 1,207) för de som hade en gymnasieutbildning. För de som hade en grundskoleutbildning och där utbildningsnivån var okänd var hasard-kvoterna 1,221 (95 % KI, 1,165 1,279) respektive 1,265 (95 % KI, 1,153 1,389). Dessutom visade en rad andra faktorer ökad risk för att avlida efter en stroke: Boende på institution (HR = 1,345; 95 % KI, 1,289 1,402), ensamboende (HR = 1,079; 95 % KI, 1,045 22
23 1,115), tidigare stroke (HR = 1,067; 95 % KI, 1,035 1,100), förmaksflimmer (HR = 1,436; 95 % KI, 1,395 1,478), diabetes (HR = 1,176; 95 % KI, 1,137 1,216) och blodtryckssänkande medicin (HR = 1,031; 95 % KI, 1,001 1,062). När interaktionen mellan kön och ensamboende inkluderades erhölls ett icke-signifikant p- värde. Detsamma gällde för interaktionen mellan kön och utbildningsnivå. På grund av deras icke-signifikanta p-värden uteslöts dessa interaktionstermer ur modellen. Interaktionstermen mellan kön och inkomstnivå erhöll ett signifikant p-värde(p=0,037) och blev således den enda interaktionstermen som ingick i den slutgiltiga Cox PH-modellen. När en interaktionsterm är inkluderad i modellen tolkas den inte på det intuitiva sättet genom att läsa av variabelvärdet. I variabeln inkomstgrupper läser man av hasard-kvoten för kvinnor med låg, medel och hög inkomst, där kvinnor med hög inkomst är referensgrupp. Kvinnor med låg och medel inkomst löpte en större risk att dö efter en stroke, HR = 1,016 (95 % KI, 0,942 1,096) respektive HR = 1,063 (95 % KI, 0,991-1,139). För att beräkna männens hasard-kvoter, i förhållande till referensgruppen hög inkomst, ser man på inkomstgrupper i kombination med interaktionstermen. Värdet på gruppen låg inkomst multipliceras med värdet på interaktionstermen för låg inkomst och kön: 1,016*1,146 = 1,1643. Motsvarande uträkning för män med medel inkomst blir: 1,063*1,077 = 1,1448. Inkomstnivå är av större betydelse för män än för kvinnor med avseende på risken att avlida, se Figur 5. Tabell 3. Slutgiltig Cox PH-modell. Variables in the Equation 95%-igt konfidensintervall för HR Referensgrupp) β SE Wald Frihetsgrader p-värde HR Undre Övre Medvetandegrad (Alert) 10051,634 2,000 Dåsig 1,052, ,575 1,000 2,865 2,769 2,963 Medvetslös 2,064, ,290 1,000 7,876 7,546 8,221 Kön (Kvinna),041,041 1,006 1,316 1,042,961 1,129 Typ av stroke (Propp/Infarkt) 883,405 2,000 Okänd,551, ,227 1,000 1,736 1,592 1,892 Blödning,541, ,927 1,000 1,718 1,654 1,784 Rökning (Icke-Rökare) 218,807 2,000 Okänd,324, ,950 1,000 1,383 1,324 1,444 Rökare,092,028 10,786 1,001 1,097 1,038 1,159 Boende på institution (Nej),296, ,009 1,000 1,345 1,289 1,402 Ensamboende (Nej),076,016 21,615 1,000 1,079 1,045 1,115 Beroende av hjälp för dagliga 770,600 2,000 aktiviteter (Nej) Ja,474, ,941 1,000 1,606 1,543 1,672 Okänd,770, ,174 1,000 2,160 2,010 2,321 Tidigare stroke (Nej),065,016 17,690 1,000 1,067 1,035 1,100 23
 74,146 3,000 Okänd,235,048 24,509 1,000 1,265 1,153 1,389 Grundskola,199,024 69,266 1,000 1,221 1,165 1,279 Gymnasium,139,025 31,506 1,000 1,150 1,095 1,207 Inkomstgrupp")
24 Förmaksflimmer (Nej),362, ,676 1,000 1,436 1,395 1,478 Diabetes (Nej),162,017 89,646 1,000 1,176 1,137 1,216 Blodtryckssänkande medicin,030,015 4,079 1,043 1,031 1,001 1,062 (Nej) Utbildningsnivå (Universitet) 74,146 3,000 Okänd,235,048 24,509 1,000 1,265 1,153 1,389 Grundskola,199,024 69,266 1,000 1,221 1,165 1,279 Gymnasium,139,025 31,506 1,000 1,150 1,095 1,207 Inkomstgrupp (Hög) 5,966 2,051 Låg,016,039,164 1,685 1,016,942 1,096 Medel,061,036 2,915 1,088 1,063,991 1,139 Åldersgrupper (<65 år) 3540,261 3, år,696, ,887 1,000 2,005 1,865 2, år 1,218, ,266 1,000 3,380 3,156 3,620 >84 år 1,754, ,715 1,000 5,779 5,389 6,197 Inkomstgrupp(Hög)*Sex 6,611 2,037 Låg*Sex,136,053 6,580 1,010 1,146 1,033 1,272 Medel*Sex,074,044 2,818 1,093 1,077,988 1,174 Figur 4. Cox-överlevnadskurvor för medevetandegrad, utbildningsnivå, åldersgrupper och typ av stroke. Kurvorna är justerade för de övriga variablerna som är med i den slutgiltiga Cox PH-modellen. 24
25 I Figur 5 nedan visas Cox-överlevnadskurva för interaktionstermen mellan inkomstgrupp och kön. För män med hög inkomst var sannolikheten att överleva dagar efter att man har insjuknat i stroke 70 %. Motsvarande sannolikhet för en man med låg eller medel inkomst var 65 %. Sannolikheten för kvinnor att överleva efter dagar varierade mellan % för de olika inkomstgrupperna. Figur 5. Cox-överlevnadskurva för interaktionen mellan kön och inkomstnivåer, justerad för övriga variabler som är med i modellen. 5. Diskussion 5.1 Datamaterial- och metoddiskussion Vi hade partiellt bortfall på ett antal variabler. Detta kan bero på ett mänskligt misstag från den som fyllde i formulären eller att patienten inte kunde uppge uppgifterna. Eftersom uppgifterna fylls i manuellt måste man ha med i åtanke att viss felinmatning kan förekomma. Vissa variabler hade ett större partiellt bortfall än andra. För de variabler som hade stort partiellt bortfall kan orsaken vara att informationen om variabeln saknades i journalen. Svar 25
26 på vissa variabler, för exempelvis rökning, krävde att personalen på sjukhusen var tvungna att prata med patienterna för att tillskansa sig informationen. Detta glöms kanske bort att göras i vissa fall och det kan även vara så att patienten inte vill/kan berätta om hen röker eller inte. Medan för andra variabler är det enklare att hitta uppgifterna i journalen. Detsamma kan gälla för variabeln om man behöver hjälp för att klara dagliga aktiviteter, där vi också hade rätt stort partiellt bortfall. Eventuellt är detta variabler som man skulle kunna få svar på när uppföljningarna genomfördes? Ytterligare en sak att ha i åtanke är att variabeln tidigare stroke anger om en patient drabbats av en stroke tidigare. Detta innebär om en patient haft tidigare stroke under perioden kommer den att förekomma mer än en gång i analysen. För det partiella bortfallet i utbildningsnivå, rökning och beroende av hjälp för att klara dagliga aktiviteter skapades en ny kategori okänd. När de okända grupperna var relativt stora ville vi undersöka om det kunde finnas ett samband mellan okänd och dödlighet. Att behandla okänd som en kategori för de variablerna minskar det totala bortfallet för studien. För de andra variablerna valde vi att hantera bortfallet med complete case-analys. Om de partiella bortfallen är helt slumpmässiga kommer complete case-analysen att vara en bra metod. Patienter i vårt datamaterial med partiellt bortfall har det oftast i fler än en variabel, vilket indikerar att de inte ser ut att vara helt slumpmässiga. Detta kan eventuellt medföra en bias i analysen (Graham, 2012). Val av detta tillvägagångssätt medförde att 4,3 % av observationerna uteslöts ur analysen. Vi diskuterade ett alternativt sätt att hantera de partiella bortfallen och det var genom att använda oss utav multipel imputation. Detta hade medfört en högre power till analysen. En nackdel med multipel imputation är att vissa värden inte är verkligt observerade och den sanna variansen är egentligen större än den som skattas med imputation (Lohr, 2010). Med detta i åtanke ansåg vi att vårt tillvägagångsätt fungerar för vår analys eftersom bortfallet var relativt litet. Vi tror inte att bortfallen har påverkat analysen nämnvärt. Vi delade in de kontinuerliga variablerna ålder och disponibel inkomst till kategoriska variabler, detta eftersom de inte uppfyllde linjäritetsantagandet. För båda variablerna gäller det att tolkningsbarheten ökar då de inkluderas som kategoriska variabler. Vi valde att dela in dessa efter tidigare studier för att avgränsa grupperna tydligare. Hade dessa variabler istället delats in i exakt lika stora kategorier hade det kunnat medföra en högre power. Att vi nu har alla variabler som kategoriska underlättar när vi ska genomföra log-log-plottarna. Variabeln typ av stroke innehåller en okänd grupp som inte är missing utan som är inmatad som okänd från sjukhusen. Det kan till exempel vara patienter som dör tidigt på sjukhus, innan röntgen genomförts för att fastställa diagnos. I och med att vi väljer att inkludera på förhand valda interaktionstermer mellan socioekonomiska faktorer och kön, istället för att inkludera alla möjliga interaktionstermer i modellen och därefter plocka bort de icke-signifikanta, finns risken att vi missar andra interaktioner som hade varit intressanta. Men då fokus låg på interaktion mellan socioekonomiska faktorer och kön valde vi att avgränsa oss till dessa. Dock vore undersökning om andra möjliga interaktionstermer intressant. I den slutgiltiga modell valde vi en modell där PH-antagandet för variabeln typ av stroke tycks inte var helt uppfyllt. En sensitivitetsanalys visade att hasard-kvoterna blev likvärdiga 26
27 när typ av stroke inkluderades som stratifierat eller tidsberoende variabel valde vi att ändå inkludera den som vanligt. Men man bör dock vara försiktig när man tolkar hasard-kvoten på den enskilda variabeln typ av stroke eftersom den variabeln är tidsberoende. Vid PHavvikelse blir hasard-kvoten, enligt Paul D. Allison, ett genomsnittligt värde på hasard-kvoten (Allison, 2017). I vårt fall för typ av stroke underskattas hasard-kvoten mellan blödning och propp/infarkt i början och överskattas i slutet. Även de andra plottarna kan vi se att antagandet om proportionell hasard inte är 100 % uppfyllt. Dock är avvikelserna mindre här och anses inte vara tillräckliga för ytterligare transformering. När det kommer till hypotestesten för tidsberoende bör man vara medveten om att ett p- värde påverkas av stickprovets storlek. En grov överträdelse av antagandet i nollhypotesen kan ge ett icke statistiskt signifikant p-värde om stickprovet är litet. Å andra sidan kan en liten överträdelse av antagandet i nollhypotesen ge ett högt statistiskt signifikant p-värde om stickprovet är väldigt stort (Kleinbaum & Klein, 2005). Detta kan vara en förklaring varför många variabler fick signifikanta p-värden i tidsberoendetestet utan att vi kunde observera några större avvikelser grafiskt. Cox PH-modellen producerar resultat som är jämförbara med resultat från paramateriska analyser där den sanna fördelningen är känd. Om vi hade vetat den sanna fördelningen vore ett parametriskt test att föredra, eftersom det hade mest troligt ledat till bättre skattningar. Exempelvis, om den sanna fördelningen vore Poisson hade en analys med hjälp av Poisson regression varit att föredra. I vissa fall kan det vara svårt att ta reda på den sanna fördelningen och vara tidskrävande. När det är tveksamt vilken som är den sanna fördelningen är Cox PH-modellen ett säkert modellval (Kleinbaum & Klein, 2005). 5.2 Resultatdiskussion Studien visade på att högre inkomstnivå hade större betydelse för överlevnaden för män än kvinnor. För män som hade en hög inkomstnivå var sannolikheten att överleva efter insjunkande i stroke 5 procentenheter högre jämfört med män med låg inkomstnivå, för kvinnor var det knappt någon skillnad. Det är svårt att säga exakt varför inkomstnivå har en större påverkan på män jämfört med kvinnor. Tar kvinnor sjukdomen på större allvar än män? Eventuellt kan inkomst vara ett dåligt mått av socioekonomisk status för kvinnor. Det är stor skillnad på sannolikheten att överleva mellan åldersgrupperna. De stora skillnaderna kan förklaras i att risken att dö ökar ju äldre man blir. Ju äldre man blir desto fler andra riskfaktorer tillkommer. Att sannolikheten att överleva efter tre år är relativt mycket lägre för de som är 85 år eller äldre beror delvis på att många hade avlidit i vilket fall inom den tidsperioden, oavsett om de drabbats av stroke eller inte. Det är exempelvis stor skillnad i fysisk status för en 18-åring och en 85-åring. Det vore av intresse att inkludera en variabel om patientens tidigare fysiska aktiviteter för att se hur den fysiska statusen påverkar sannolikheten att överleva. Ett resultat som var förvånande var att variabeln tidigare stroke inte hade en större hasard-kvot än 1,067. Kan detta tyda på att många som drabbats av en stroke tidigare oftast återhämtar sig relativt bra? För de socioekonomiska faktorerna ensamboende, utbildningsnivå och inkomstgrupper ser vi ett samband mellan lägre socioekonomisk status och ökad risk för att avlida. Detta stämmer överens med två tidigare studier, en där man undersökte skillnader i strokevården (Eriksson, Asplund, Glader, & 27
28 Norrving, 2015) och en där man undersökte socioekonomiska faktorer (Lindmark, Glader, Asplund, Norrving, & Eriksson, 2014). I de variabler där en okänd-kategori är med har den kategorin störst risk att dö. I datamaterialet kunde vi se att patienter som hade partiellt bortfall ofta hade det i mer än en variabel. En förklaring till detta kan vara att patienterna var i för dåligt skick att göra vidare undersökningar på eller att de var oförmögna att svara på frågor om sin status. Det kan vara en förklaring till att de patienter som tillhör kategorin okänd är värre drabbade och således har sämre prognos att klara sig. I Kaplan-Meier plottarna är variabeln inte justerade för övriga variabler. Kaplan-Meier grafen för kön visade att kvinnor hade högre risk att avlida än män. Detta förklaras av att kvinnor som drabbats av stroke hade en högre medelålder än männen. I Cox-överlevnadskurvor som är justerad för övriga variabler, däribland åldersgrupper, visade det sig att män hade en högre risk att avlida än kvinnor. I Cox-överlevnadskurvor framgår det att människor med lägre utbildningsnivå löper en högre risk att avlida efter insjuknande i stroke. Är det verkligen så att om alla personer med lägre utbildning skaffar en universitetsutbildning får de omgående en högre sannolikhet att överleva? Mest troligen inte, utan det kan bero på bakomliggande faktorer som vad högre utbildning medför. Exempelvis, arbeten som kräver universitetsutbildning finns i högre utsträckning i städer vilket leder till kortare tid till sjukhus där man snabbare kan få vård. Resultaten från vår och den tidigare studien (Lindmark, Glader, Asplund, Norrving, & Eriksson, 2014) har visat på att det finns skillnader mellan könen i socioekonomiska faktorer. Den tidigare studien visar på skillnader mellan könen för ensamboende medan vår studie visar på skillnader mellan inkomstnivåer. Eftersom vi har studerat olika datamaterial är det inte förvånade att vi har fått olika resultat, däremot är det intressant att båda studierna visar på att socioekonomiska faktorer skiljer sig mellan könen när det gäller risken att avlida efter insjuknande i stroke. Vad de bakomliggande faktorerna till dessa skillnader är vore ett intressant framtida forskningsområde. 28
29 Tillkännagivande Först och främst vill vi tacka vår handledare Marie Eriksson som har varit ett stort stöd genom hela uppsatsen. Hon har varit engagerad i uppsatsen genom att besvara de frågor vi haft och kommit med tips. Vi vill även tacka Riksstroke som har tillhandahållit datamaterialet vilket har gett oss möjligheten att fördjupa våra kunskaper och utföra vår överlevnadsanalys om stroke. 29
30 Referenser Allison, P. D. (2017, 05 02). Retrieved from Survival Analysis: Allison, P.D. (1984). Event History analysis - Regression for longitudinal event data. University of Pennslyvania: Sage Publications, Inc. Cox, D. R. (1972). Regression Models and Life-Tables. In D. R. Cox, Regression Models and Life-Tables (pp ). Journal of the Royal Statistical Society. Eriksson, G. (2012, 10 02). Ärende, beslut eller annan åtgärd. Protokollsutdrag. Umeå: Regionala Etikprövningsnämnden. Dnr: M. Eriksson, M. (2012). Ojämlikheter i svensk strokevård med avseende på socioekonomisk status, födelseland, kön och ålder. DNR: M. Eriksson, M., Asplund, K., Glader, E.-L., & Norrving, B. (2015). Kvalitetsregistret Riksstroke visar på ojämlik strokevård. Läkartidningen. Eriksson, M., Norrving, B., Terént, A., & Stegmayr, B. (2008). Functional Outcome 3 Months after Stroke Predicts Long-Term Survival DOI: / Basel: S. Karger AG. Graham, J. (2012). Missing Data: Analysis and Design. New York: Springer-Verlag New York. Guo, S. (2010). Survival Analysis. New York: Oxford University Press. Hosmer, D., Lemeshow, S., & May, S. (2008). Applied Survival Analysis: Regression Modeling of Timeto-Event Data. New Jersey: John Wiley & Sons. Jönsson, A.-C. (2012). Stroke-Patienters,närståendes och vårdares perspektiv Upplaga 1. Lund: Studentlitteratur AB. Jones, M. P. (1996). Indicator and Stratification Methods for Missing Explanatory Variables in Multiple LinearRegression. Journal of the American Statistical Association, 10. Klein, J. P., & Moeschberger, M. L. (2003). Survival Analysis: Techniques for Censored and Truncated Data Second Edition. New York: Springer-Verlag. Kleinbaum & Klein, D. (2005). Survival Analysis - A self-learning text. New York: Springer Science & Buisness Media, Inc. Lindmark, A., Glader, E.-L., Asplund, K., Norrving, B., & Eriksson, M. (2014). Socioeconomic disparities in stroke case fatality Observations from Riks-Stroke. International Journal of Stroke 2013 World Stroke Organization, Lohr, S. L. (2010). Sampling: Design and Analysis. Arizona State University: Brooks/Cole, Cengage Learning. Mills, M. (2011). Introducing Survival and Event History Analysis. London: SAGE Publication. Riksstroke. (2017, April 25). Retrieved from Riksstroke, Medicincentrum, Norrlands universitetssjukhus: Riksstroke, M. N. (2017, April 21). Riksstroke.org. Retrieved from Riksstroke, Medicincentrum, Norrlands universitetssjukhus: 30
31 Wahlgren, L. (2014). SPSS- steg för steg. Lund: Studentlitteratur AB. 31


32 Appendix 1 - Kaplan-Meier-kurvor 32
33 33
34 Appendix 2 Utskrift för Log-rank-testen Overall Comparisons Chi-Square df Sig. Log Rank (Mantel-Cox) 476,450 1,000 Test of equality of survival distributions for the different levels of Kön. Overall Comparisons Chi-Square df Sig. Log Rank (Mantel-Cox) 24909,441 2,000 Test of equality of survival distributions for the different levels of Medvetandegrad. Overall Comparisons Chi-Square df Sig. Log Rank (Mantel-Cox) 1655,091 2,000 Test of equality of survival distributions for the different levels of Typ av stroke. Overall Comparisons Chi-Square df Sig. Log Rank (Mantel-Cox) 1867,716 2,000 Test of equality of survival distributions for the different levels of Rökning. Overall Comparisons Chi-Square df Sig. Log Rank (Mantel-Cox) 7214,590 1,000 Test of equality of survival distributions for the different levels of Institutional living. Overall Comparisons Chi-Square df Sig. Log Rank (Mantel-Cox) 1979,475 1,000 Test of equality of survival distributions for the different levels of Living alone. Overall Comparisons Chi-Square df Sig. Log Rank (Mantel-Cox) 10072,520 2,000 Test of equality of survival distributions for the different levels of Dependent in p-adl before stroke. 34
35 Overall Comparisons Chi-Square df Sig. Log Rank (Mantel-Cox) 826,617 1,000 Test of equality of survival distributions for the different levels of Previous stroke. Overall Comparisons Chi-Square df Sig. Log Rank (Mantel-Cox) 3515,849 1,000 Test of equality of survival distributions for the different levels of AF. Overall Comparisons Chi-Square df Sig. Log Rank (Mantel-Cox) 70,390 1,000 Test of equality of survival distributions for the different levels of Diabetes. Overall Comparisons Chi-Square df Sig. Log Rank (Mantel-Cox) 265,631 1,000 Test of equality of survival distributions for the different levels of Hypertensive medication at BL. Overall Comparisons Chi-Square df Sig. Log Rank (Mantel-Cox) 1074,484 3,000 Test of equality of survival distributions for the different levels of Utbildningsnivå. Overall Comparisons Chi-Square df Sig. Log Rank (Mantel-Cox) 924,510 2,000 Test of equality of survival distributions for the different levels of inkomstgrupper. Overall Comparisons Chi-Square df Sig. Log Rank (Mantel-Cox) 9798,770 3,000 Test of equality of survival distributions for the different levels of Åldergrupper. 35
36 Appendix 3 Utskrift för tidsberoende testen B SE Wald df Sig. Exp(B) T_COV_,000,000,020 1,887 1,000 Living alone,615, ,296 1,000 1,849 B SE Wald df Sig. Exp(B) T_COV_,000,000 17,643 1,000 1,000 Sex -,335, ,107 1,000,715 B SE Wald df Sig. Exp(B) T_COV_ -,003, ,986 1,000,997 Level of consciousness 17204,684 2,000 Level of consciousness(1) -2,885, ,005 1,000,056 Level of consciousness(2) -1,099, ,400 1,000,333 B SE Wald df Sig. Exp(B) T_COV_,001, ,778 1,000 1,001 Diagnosis (ICD10) 2310,237 2,000 Diagnosis (ICD10)(1) 1,204, ,385 1,000 3,334 Diagnosis (ICD10)(2),916, ,257 1,000 2,499 B SE Wald df Sig. Exp(B) T_COV_,000, ,312 1,000 1,000 RokerA 1948,065 2,000 RokerA(1),797, ,664 1,000 2,219 RokerA(2) -,639, ,700 1,000,528 B SE Wald df Sig. Exp(B) T_COV_,000,000,728 1,394 1,000 Institutional living 1,286, ,500 1,000 3,617 B SE Wald df Sig. Exp(B) T_COV_,000,000 44,836 1,000 1,000 Dependent in p-adl before stroke 7757,444 2,000 Dependent in p-adl before 1,295, ,169 1,000 3,651 stroke(1) Dependent in p-adl before 1,872, ,578 1,000 6,502 stroke(2) 36
37 B SE Wald df Sig. Exp(B) T_COV_,000,000 21,882 1,000 1,000 Previous stroke,369, ,328 1,000 1,446 B SE Wald df Sig. Exp(B) T_COV_,000,000 5,109 1,024 1,000 AF,771, ,675 1,000 2,161 B SE Wald df Sig. Exp(B) T_COV_,000,000 10,568 1,001 1,000 Diabetes,100,020 25,336 1,000 1,105 B SE Wald df Sig. Exp(B) Hypertensive medication at BL,191, ,938 1,000 1,211 T_COV_,000,000 16,418 1,000 1,000 B SE Wald df Sig. Exp(B) T_COV_,000,000,178 1,673 1,000 Education 1015,072 3,000 Education(1),380,054 49,002 1,000 1,462 Education(2),592, ,544 1,000 1,808 Education(3),216,024 81,491 1,000 1,242 B SE Wald df Sig. Exp(B) T_COV_,000,000 93,104 1,000 1,000 Åldergrupper 4695,276 3,000 Åldergrupper(1),651, ,921 1,000 1,917 Åldergrupper(2) 1,270, ,653 1,000 3,561 Åldergrupper(3) 1,940, ,954 1,000 6,957 B SE Wald df Sig. Exp(B) T_COV_,000,000,466 1,495 1,000 Disposable incomegroups 792,961 2,000 Disposable incomegroups(1),532, ,558 1,000 1,702 Disposable incomegroups(2),617, ,903 1,000 1,854 37

38 Appendix 4 - Log-log plottar 38
39 39
40 40
41 Appendix 5 Cox-överlevnadskurvor 41
42 42
Innehåll: 3.4 Parametriskt eller ej 3.5 Life Table 3.6 Kaplan Meier 4. Cox Regression 4.1 Hazard Function 4.2 Estimering (PL)
") Innehåll: 1. Risk & Odds 1.1 Risk Ratio 1.2 Odds Ratio 2. Logistisk Regression 2.1 Ln Odds 2.2 SPSS Output 2.3 Estimering (ML) 2.4 Multipel 3. Survival Analys 3.1 vs. Logistisk 3.2 Censurerade data 3.3
Innehåll: 1. Risk & Odds 1.1 Risk Ratio 1.2 Odds Ratio 2. Logistisk Regression 2.1 Ln Odds 2.2 SPSS Output 2.3 Estimering (ML) 2.4 Multipel 3. Survival Analys 3.1 vs. Logistisk 3.2 Censurerade data 3.3
Överlevnadsanalys. 732G34 Statistisk analys av komplexa data
 Överlevnadsanalys 732G34 Statistisk analys av komplexa data 1 Tvärsnittsstudie Prospektiv Kohortstudie Observationsstudie Tvärsnittsstudie Retrospektiv Experimentell studie (alltid prospektiv) Klinisk
Överlevnadsanalys 732G34 Statistisk analys av komplexa data 1 Tvärsnittsstudie Prospektiv Kohortstudie Observationsstudie Tvärsnittsstudie Retrospektiv Experimentell studie (alltid prospektiv) Klinisk
Överlevnadsanalys. Överlevnadsanalys med tidsberoende kovariater. Tid till en händelse: observationer i kalendertid och som tid från start.
 Överlevnadsanalys Överlevnadsanalys med tidsberoende kovariater Peter Höglund USiL 10 februari 2010 Kaplan-Meier Logrank test Cox-regression Tidsberoende kovariater (Tidsuppdaterade kovariater tas inte
Överlevnadsanalys Överlevnadsanalys med tidsberoende kovariater Peter Höglund USiL 10 februari 2010 Kaplan-Meier Logrank test Cox-regression Tidsberoende kovariater (Tidsuppdaterade kovariater tas inte
Upplägg Dag 1 Tid till händelse Censurering Livslängdstabeller Överlevnadsfunktionen Kaplan-Meier Parametrisk skattning Jämföra överlevnadskurvor
 Survival analysis (Dag 1) Upplägg Dag 1 Tid till händelse Censurering Livslängdstabeller Överlevnadsfunktionen Kaplan-Meier Parametrisk skattning Jämföra överlevnadskurvor Henrik Källberg, 2012 Survival
Survival analysis (Dag 1) Upplägg Dag 1 Tid till händelse Censurering Livslängdstabeller Överlevnadsfunktionen Kaplan-Meier Parametrisk skattning Jämföra överlevnadskurvor Henrik Källberg, 2012 Survival
ST-fredag i Biostatistik & Epidemiologi När ska jag använda vilket test?
 ST-fredag i Biostatistik & Epidemiologi När ska jag använda vilket test? Mikael Eriksson Specialistläkare CIVA Karolinska Universitetssjukhuset, Solna Grund för hypotestestning 1. Definiera noll- och alternativhypotes,
ST-fredag i Biostatistik & Epidemiologi När ska jag använda vilket test? Mikael Eriksson Specialistläkare CIVA Karolinska Universitetssjukhuset, Solna Grund för hypotestestning 1. Definiera noll- och alternativhypotes,
Bild 1. Bild 2 Sammanfattning Statistik I. Bild 3 Hypotesprövning. Medicinsk statistik II
 Bild 1 Medicinsk statistik II Läkarprogrammet T5 HT 2014 Anna Jöud Arbets- och miljömedicin, Lunds universitet ERC Syd, Skånes Universitetssjukhus anna.joud@med.lu.se Bild 2 Sammanfattning Statistik I
Bild 1 Medicinsk statistik II Läkarprogrammet T5 HT 2014 Anna Jöud Arbets- och miljömedicin, Lunds universitet ERC Syd, Skånes Universitetssjukhus anna.joud@med.lu.se Bild 2 Sammanfattning Statistik I
Till ampad statistik (A5) Förläsning 13: Logistisk regression
 Förläsning 13: Logistisk regression") Till ampad statistik (A5) Förläsning 13: Logistisk regression Ronnie Pingel Statistiska institutionen Senast uppdaterad: 2016-03-08 Exempel 1: NTU2015 Exempel 2: En jobbannons Exempel 3 1 1 Klofstad, C.
Till ampad statistik (A5) Förläsning 13: Logistisk regression Ronnie Pingel Statistiska institutionen Senast uppdaterad: 2016-03-08 Exempel 1: NTU2015 Exempel 2: En jobbannons Exempel 3 1 1 Klofstad, C.
Användning. Fixed & Random. Centrering. Multilevel Modeling (MLM) Var sak på sin nivå
 Var sak på sin nivå") Användning Multilevel Modeling (MLM) Var sak på sin nivå Kimmo Sorjonen Sektionen för Psykologi Karolinska Institutet Kärt barn har många namn: (1) Random coefficient models; () Mixed effect models; (3)
Användning Multilevel Modeling (MLM) Var sak på sin nivå Kimmo Sorjonen Sektionen för Psykologi Karolinska Institutet Kärt barn har många namn: (1) Random coefficient models; () Mixed effect models; (3)
Regressionsanalys med SPSS Kimmo Sorjonen (2010)
") 1 Regressionsanalys med SPSS Kimmo Sorjonen (2010) 1. Multipel regression 1.1. Variabler I det aktuella exemplet ingår följande variabler: (1) life.sat, anger i vilket utsträckning man är nöjd med livet;
1 Regressionsanalys med SPSS Kimmo Sorjonen (2010) 1. Multipel regression 1.1. Variabler I det aktuella exemplet ingår följande variabler: (1) life.sat, anger i vilket utsträckning man är nöjd med livet;
Instuderingsfrågor till avsnittet om statistik, kursen Statistik och Metod, Psykologprogrammet på KI, T8
 1 Instuderingsfrågor till avsnittet om statistik, kursen Statistik och Metod, Psykologprogrammet på KI, T8 Dessa instuderingsfrågor är främst tänkta att stämma överens med innehållet i föreläsningarna,
1 Instuderingsfrågor till avsnittet om statistik, kursen Statistik och Metod, Psykologprogrammet på KI, T8 Dessa instuderingsfrågor är främst tänkta att stämma överens med innehållet i föreläsningarna,
Logistisk regression och Indexteori. Patrik Zetterberg. 7 januari 2013
 Föreläsning 9 Logistisk regression och Indexteori Patrik Zetterberg 7 januari 2013 1 / 33 Logistisk regression I logistisk regression har vi en binär (kategorisk) responsvariabel Y i som vanligen kodas
Föreläsning 9 Logistisk regression och Indexteori Patrik Zetterberg 7 januari 2013 1 / 33 Logistisk regression I logistisk regression har vi en binär (kategorisk) responsvariabel Y i som vanligen kodas
Upprepade mätningar och tidsberoende analyser. Stefan Franzén Statistiker Registercentrum Västra Götaland
 Upprepade mätningar och tidsberoende analyser Stefan Franzén Statistiker Registercentrum Västra Götaland Innehåll Stort område Simpsons paradox En mätning per individ Flera mätningar per individ Flera
Upprepade mätningar och tidsberoende analyser Stefan Franzén Statistiker Registercentrum Västra Götaland Innehåll Stort område Simpsons paradox En mätning per individ Flera mätningar per individ Flera
Tillämpad statistik (A5), HT15 Föreläsning 11: Multipel linjär regression 2
, HT15 Föreläsning 11: Multipel linjär regression 2") Tillämpad statistik (A5), HT15 Föreläsning 11: Multipel linjär regression 2 Ronnie Pingel Statistiska institutionen Senast uppdaterad: 2015-11-23 Faktum är att vi i praktiken nästan alltid har en blandning
Tillämpad statistik (A5), HT15 Föreläsning 11: Multipel linjär regression 2 Ronnie Pingel Statistiska institutionen Senast uppdaterad: 2015-11-23 Faktum är att vi i praktiken nästan alltid har en blandning
Metod och teori. Statistik för naturvetare Umeå universitet
 Statistik för naturvetare -6-8 Metod och teori Uppgift Uppgiften är att undersöka hur hjärtfrekvensen hos en person påverkas av dennes kroppstemperatur. Detta görs genom enkel linjär regression. Låt signifikansnivån
Statistik för naturvetare -6-8 Metod och teori Uppgift Uppgiften är att undersöka hur hjärtfrekvensen hos en person påverkas av dennes kroppstemperatur. Detta görs genom enkel linjär regression. Låt signifikansnivån
MULTIPEL IMPUTATION. Ett sätt att fylla i hålen i ditt datamaterial?
 MULTIPEL IMPUTATION Ett sätt att fylla i hålen i ditt datamaterial? Pär Ola Bendahl IKVL, Avdelningen för Onkologi Lunds Universitet Par Ola.Bendahl@med.lu.se Översikt 1. Introduktion till problemet 2.
MULTIPEL IMPUTATION Ett sätt att fylla i hålen i ditt datamaterial? Pär Ola Bendahl IKVL, Avdelningen för Onkologi Lunds Universitet Par Ola.Bendahl@med.lu.se Översikt 1. Introduktion till problemet 2.
Skolprestationer på kommunnivå med hänsyn tagen till socioekonomi
 1(6) PCA/MIH Johan Löfgren 2016-11-10 Skolprestationer på kommunnivå med hänsyn tagen till socioekonomi 1 Inledning Sveriges kommuner och landsting (SKL) presenterar varje år statistik över elevprestationer
1(6) PCA/MIH Johan Löfgren 2016-11-10 Skolprestationer på kommunnivå med hänsyn tagen till socioekonomi 1 Inledning Sveriges kommuner och landsting (SKL) presenterar varje år statistik över elevprestationer
Matematikcentrum 1(4) Matematisk Statistik Lunds Universitet MASB11 HT10. Laboration. Regressionsanalys (Sambandsanalys)
 Matematisk Statistik Lunds Universitet MASB11 HT10. Laboration. Regressionsanalys (Sambandsanalys)") Matematikcentrum 1(4) Matematisk Statistik Lunds Universitet MASB11 HT10 Laboration Regressionsanalys (Sambandsanalys) Grupp A: 2010-11-24, 13.15 15.00 Grupp B: 2010-11-24, 15.15 17.00 Grupp C: 2010-11-25,
Matematikcentrum 1(4) Matematisk Statistik Lunds Universitet MASB11 HT10 Laboration Regressionsanalys (Sambandsanalys) Grupp A: 2010-11-24, 13.15 15.00 Grupp B: 2010-11-24, 15.15 17.00 Grupp C: 2010-11-25,
732G71 Statistik B. Föreläsning 4. Bertil Wegmann. November 11, IDA, Linköpings universitet
 732G71 Statistik B Föreläsning 4 Bertil Wegmann IDA, Linköpings universitet November 11, 2016 Bertil Wegmann (IDA, LiU) 732G71, Statistik B November 11, 2016 1 / 34 Kap. 5.1, korrelationsmatris En korrelationsmatris
732G71 Statistik B Föreläsning 4 Bertil Wegmann IDA, Linköpings universitet November 11, 2016 Bertil Wegmann (IDA, LiU) 732G71, Statistik B November 11, 2016 1 / 34 Kap. 5.1, korrelationsmatris En korrelationsmatris
Medicinsk statistik II
 Medicinsk statistik II Läkarprogrammet termin 5 VT 2013 Susanna Lövdahl, Msc, doktorand Klinisk koagulationsforskning, Lunds universitet E-post: susanna.lovdahl@med.lu.se Dagens föreläsning Fördjupning
Medicinsk statistik II Läkarprogrammet termin 5 VT 2013 Susanna Lövdahl, Msc, doktorand Klinisk koagulationsforskning, Lunds universitet E-post: susanna.lovdahl@med.lu.se Dagens föreläsning Fördjupning
F18 MULTIPEL LINJÄR REGRESSION, FORTS. (NCT
 Stat. teori gk, ht 006, JW F18 MULTIPEL LINJÄR REGRESSION, FORTS. (NCT 1.1, 13.1-13.6, 13.8-13.9) Modell för multipel linjär regression Modellantaganden: 1) x-värdena är fixa. ) Varje y i (i = 1,, n) är
Stat. teori gk, ht 006, JW F18 MULTIPEL LINJÄR REGRESSION, FORTS. (NCT 1.1, 13.1-13.6, 13.8-13.9) Modell för multipel linjär regression Modellantaganden: 1) x-värdena är fixa. ) Varje y i (i = 1,, n) är
Jämlik strokevård En analys av skillnader mellan patientgrupper avseende vård på strokeenhet, åren
 Jämlik strokevård En analys av skillnader mellan patientgrupper avseende vård på strokeenhet, åren 1995-2009 Hilda Edlund och Maria Sukhova Handledare: Marie Eriksson Student Vt 2012 Examensarbete, 15
Jämlik strokevård En analys av skillnader mellan patientgrupper avseende vård på strokeenhet, åren 1995-2009 Hilda Edlund och Maria Sukhova Handledare: Marie Eriksson Student Vt 2012 Examensarbete, 15
2. Lära sig skatta en multipel linjär regressionsmodell samt plotta variablerna. 4. Lära sig skatta en linjär regressionsmodell med interaktionstermer
 Datorövning 2 Regressions- och tidsserieanalys Syfte 1. Lära sig skapa en korrelationsmatris 2. Lära sig skatta en multipel linjär regressionsmodell samt plotta variablerna mot varandra 3. Lära sig beräkna
Datorövning 2 Regressions- och tidsserieanalys Syfte 1. Lära sig skapa en korrelationsmatris 2. Lära sig skatta en multipel linjär regressionsmodell samt plotta variablerna mot varandra 3. Lära sig beräkna
Föreläsning 2. Kap 3,7-3,8 4,1-4,6 5,2 5,3
 Föreläsning Kap 3,7-3,8 4,1-4,6 5, 5,3 1 Kap 3,7 och 3,8 Hur bra är modellen som vi har anpassat? Vi bedömer modellen med hjälp av ett antal kriterier: visuell bedömning, om möjligt F-test, signifikanstest
Föreläsning Kap 3,7-3,8 4,1-4,6 5, 5,3 1 Kap 3,7 och 3,8 Hur bra är modellen som vi har anpassat? Vi bedömer modellen med hjälp av ett antal kriterier: visuell bedömning, om möjligt F-test, signifikanstest
1. INLEDNING Problemformulering Syfte Avgränsningar 4 2. TIDIGARE STUDIER 5 3. METOD Överlevnadsanalys 6 3.
 Sammanfattning Denna uppsats använder sig av SCB:s registerdata som omfattar samtliga par som gifte sig för första gången under 1998, dessa par studeras under cirka elva år fram till den 31 december 2008.
Sammanfattning Denna uppsats använder sig av SCB:s registerdata som omfattar samtliga par som gifte sig för första gången under 1998, dessa par studeras under cirka elva år fram till den 31 december 2008.
Regressions- och Tidsserieanalys - F3
 Regressions- och Tidsserieanalys - F3 Multipel regressionsanalys kap 4.8-4.10 Linda Wänström Linköpings universitet 7 maj Wänström (Linköpings universitet) F3 7 maj 1 / 26 Lite som vi inte hann med när
Regressions- och Tidsserieanalys - F3 Multipel regressionsanalys kap 4.8-4.10 Linda Wänström Linköpings universitet 7 maj Wänström (Linköpings universitet) F3 7 maj 1 / 26 Lite som vi inte hann med när
Spridningsdiagram (scatterplot) Fler exempel. Korrelation (forts.) Korrelation. Enkel linjär regression. Enkel linjär regression (forts.
 Fler exempel. Korrelation (forts.) Korrelation. Enkel linjär regression. Enkel linjär regression (forts.") Spridningsdiagram (scatterplot) En scatterplot som visar par av observationer: reklamkostnader på -aeln and försäljning på -aeln ScatterplotofAdvertising Ependitures ()andsales () 4 Fler eempel Notera:
Spridningsdiagram (scatterplot) En scatterplot som visar par av observationer: reklamkostnader på -aeln and försäljning på -aeln ScatterplotofAdvertising Ependitures ()andsales () 4 Fler eempel Notera:
I. Grundläggande begrepp II. Deskriptiv statistik III. Statistisk inferens Parametriska Icke-parametriska
 Innehåll I. Grundläggande begrepp II. Deskriptiv statistik III. Statistisk inferens Hypotesprövnig Statistiska analyser Parametriska analyser Icke-parametriska analyser Univariata analyser Univariata analyser
Innehåll I. Grundläggande begrepp II. Deskriptiv statistik III. Statistisk inferens Hypotesprövnig Statistiska analyser Parametriska analyser Icke-parametriska analyser Univariata analyser Univariata analyser
Risk Ratio, Odds Ratio, Logistisk Regression och Survival Analys med SPSS Kimmo Sorjonen, 2012
 Risk Ratio, Odds Ratio, Logistisk Regression och Survival Analys med SPSS Kimmo Sorjonen, 2012 1. Risk Ratio & Odds Ratio Risk- och odds ratio beräknar sambandet mellan två dikotoma variabler. Inom forskning
Risk Ratio, Odds Ratio, Logistisk Regression och Survival Analys med SPSS Kimmo Sorjonen, 2012 1. Risk Ratio & Odds Ratio Risk- och odds ratio beräknar sambandet mellan två dikotoma variabler. Inom forskning
Kapitel 15: INTERAKTIONER, STANDARDISERADE SKALOR OCH ICKE-LINJÄRA EFFEKTER
 Kapitel 15: INTERAKTIONER, STANDARDISERADE SKALOR OCH ICKE-LINJÄRA EFFEKTER När vi mäter en effekt i data så vill vi ofta se om denna skiljer sig mellan olika delgrupper. Vi kanske testar effekten av ett
Kapitel 15: INTERAKTIONER, STANDARDISERADE SKALOR OCH ICKE-LINJÄRA EFFEKTER När vi mäter en effekt i data så vill vi ofta se om denna skiljer sig mellan olika delgrupper. Vi kanske testar effekten av ett
Laboration 5: Regressionsanalys. 1 Förberedelseuppgifter. 2 Enkel linjär regression DATORLABORATION 5 MATEMATISK STATISTIK FÖR I, FMS 012, HT-08
 LUNDS TEKNISKA HÖGSKOLA MATEMATIKCENTRUM MATEMATISK STATISTIK Laboration 5: Regressionsanalys DATORLABORATION 5 MATEMATISK STATISTIK FÖR I, FMS 012, HT-08 Syftet med den här laborationen är att du skall
LUNDS TEKNISKA HÖGSKOLA MATEMATIKCENTRUM MATEMATISK STATISTIK Laboration 5: Regressionsanalys DATORLABORATION 5 MATEMATISK STATISTIK FÖR I, FMS 012, HT-08 Syftet med den här laborationen är att du skall
7.5 Experiment with a single factor having more than two levels
 7.5 Experiment with a single factor having more than two levels Exempel: Antag att vi vill jämföra dragstyrkan i en syntetisk fiber som blandats ut med bomull. Man vet att inblandningen påverkar dragstyrkan
7.5 Experiment with a single factor having more than two levels Exempel: Antag att vi vill jämföra dragstyrkan i en syntetisk fiber som blandats ut med bomull. Man vet att inblandningen påverkar dragstyrkan
Rapport från valideringsprojekt Delrapport 2. Tolkningsfel i akutformuläret.
 Rapport från valideringsprojekt 2012 2013 Delrapport 2. Tolkningsfel i akutformuläret. 1 BAKGRUND Akutformuläret fylls i av personalen på sjukhuset där patienten vårdats. Det kan vara personer i olika
Rapport från valideringsprojekt 2012 2013 Delrapport 2. Tolkningsfel i akutformuläret. 1 BAKGRUND Akutformuläret fylls i av personalen på sjukhuset där patienten vårdats. Det kan vara personer i olika
Laboration 2 multipel linjär regression
 Laboration 2 multipel linjär regression I denna datorövning skall ni 1. analysera data enligt en multipel regressionsmodell, dvs. inkludera flera förklarande variabler i en regressionsmodell 2. studera
Laboration 2 multipel linjär regression I denna datorövning skall ni 1. analysera data enligt en multipel regressionsmodell, dvs. inkludera flera förklarande variabler i en regressionsmodell 2. studera
Sänkningen av parasitnivåerna i blodet
 4.1 Oberoende (x-axeln) Kön Kön Längd Ålder Dos Dos C max Parasitnivå i blodet Beroende (y-axeln) Längd Vikt Vikt Vikt C max Sänkningen av parasitnivåerna i blodet Sänkningen av parasitnivåerna i blodet
4.1 Oberoende (x-axeln) Kön Kön Längd Ålder Dos Dos C max Parasitnivå i blodet Beroende (y-axeln) Längd Vikt Vikt Vikt C max Sänkningen av parasitnivåerna i blodet Sänkningen av parasitnivåerna i blodet
Föreläsning 4. NDAB01 Statistik; teori och tillämpning i biologi
 Föreläsning 4 Statistik; teori och tillämpning i biologi 1 Dagens föreläsning o Icke-parametriska test Mann-Whitneys test (kap 8.10 8.11) Wilcoxons test (kap 9.5) o Transformationer (kap 13) o Ev. Andelar
Föreläsning 4 Statistik; teori och tillämpning i biologi 1 Dagens föreläsning o Icke-parametriska test Mann-Whitneys test (kap 8.10 8.11) Wilcoxons test (kap 9.5) o Transformationer (kap 13) o Ev. Andelar
Grundläggande matematisk statistik
 Grundläggande matematisk statistik Linjär Regression Uwe Menzel, 2018 uwe.menzel@slu.se; uwe.menzel@matstat.de www.matstat.de Linjär Regression y i y 5 y 3 mätvärden x i, y i y 1 x 1 x 2 x 3 x 4 x 6 x
Grundläggande matematisk statistik Linjär Regression Uwe Menzel, 2018 uwe.menzel@slu.se; uwe.menzel@matstat.de www.matstat.de Linjär Regression y i y 5 y 3 mätvärden x i, y i y 1 x 1 x 2 x 3 x 4 x 6 x
Betrakta kopparutbytet från malm från en viss gruva. För att kontrollera detta tar man ut n =16 prover och mäter kopparhalten i dessa.
 Betrakta kopparutbytet från malm från en viss gruva. Anta att budgeten för utbytet är beräknad på att kopparhalten ligger på 70 %. För att kontrollera detta tar man ut n =16 prover och mäter kopparhalten
Betrakta kopparutbytet från malm från en viss gruva. Anta att budgeten för utbytet är beräknad på att kopparhalten ligger på 70 %. För att kontrollera detta tar man ut n =16 prover och mäter kopparhalten
En scatterplot gjordes, och linjär regression utfördes därefter med följande hypoteser:
 1 Uppgiftsbeskrivning Syftet med denna laboration var att utifrån uppmätt data avgöra: (i) Om något samband finnes mellan kroppstemperatur och hjärtfrekvens. (ii) Om någon signifikant skillnad i sockerhalt
1 Uppgiftsbeskrivning Syftet med denna laboration var att utifrån uppmätt data avgöra: (i) Om något samband finnes mellan kroppstemperatur och hjärtfrekvens. (ii) Om någon signifikant skillnad i sockerhalt
STOCKHOLMS UNIVERSITET VT 2011 Avd. Matematisk statistik GB DATORLABORATION 3: MULTIPEL REGRESSION.
 MATEMATISKA INSTITUTIONEN Tillämpad statistisk analys, GN STOCKHOLMS UNIVERSITET VT 2011 Avd. Matematisk statistik GB 2011-04-13 DATORLABORATION 3: MULTIPEL REGRESSION. Under Instruktioner och data på
MATEMATISKA INSTITUTIONEN Tillämpad statistisk analys, GN STOCKHOLMS UNIVERSITET VT 2011 Avd. Matematisk statistik GB 2011-04-13 DATORLABORATION 3: MULTIPEL REGRESSION. Under Instruktioner och data på
1. Lära sig plotta en beroende variabel mot en oberoende variabel. 2. Lära sig skatta en enkel linjär regressionsmodell
 Datorövning 1 Regressions- och tidsserieanalys Syfte 1. Lära sig plotta en beroende variabel mot en oberoende variabel 2. Lära sig skatta en enkel linjär regressionsmodell 3. Lära sig beräkna en skattning
Datorövning 1 Regressions- och tidsserieanalys Syfte 1. Lära sig plotta en beroende variabel mot en oberoende variabel 2. Lära sig skatta en enkel linjär regressionsmodell 3. Lära sig beräkna en skattning
Tre av tio har avgått
 Statistiska institutionen Tre av tio har avgått En överlevnadsstudie av tiden till avgång för kommunfullmäktigeledamöter i Stockholms län. Three in ten has resigned A survival analysis of time to resignation
Statistiska institutionen Tre av tio har avgått En överlevnadsstudie av tiden till avgång för kommunfullmäktigeledamöter i Stockholms län. Three in ten has resigned A survival analysis of time to resignation
LÖSNINGSFÖRSLAG TILL TENTAMEN I MATEMATISK STATISTIK 2007-08-29
 UMEÅ UNIVERSITET Institutionen för matematik och matematisk statistik Statistik för Teknologer, 5 poäng (TNK, ET, BTG) Peter Anton, Per Arnqvist Anton Grafström TENTAMEN 7-8-9 LÖSNINGSFÖRSLAG TILL TENTAMEN
UMEÅ UNIVERSITET Institutionen för matematik och matematisk statistik Statistik för Teknologer, 5 poäng (TNK, ET, BTG) Peter Anton, Per Arnqvist Anton Grafström TENTAMEN 7-8-9 LÖSNINGSFÖRSLAG TILL TENTAMEN
1 Förberedelseuppgifter
 LUNDS TEKNISKA HÖGSKOLA MATEMATIKCENTRUM MATEMATISK STATISTIK LABORATION 2 MATEMATISK STATISTIK FÖR B, K, N, BME OCH KEMISTER; FMS086 & MASB02 Syfte: Syftet med dagens laborationen är att du skall: bli
LUNDS TEKNISKA HÖGSKOLA MATEMATIKCENTRUM MATEMATISK STATISTIK LABORATION 2 MATEMATISK STATISTIK FÖR B, K, N, BME OCH KEMISTER; FMS086 & MASB02 Syfte: Syftet med dagens laborationen är att du skall: bli
Missing data och imputation eller Får man hitta på data? Lars Lindhagen, UCR 2014-05-21
 Missing data och imputation eller Får man hitta på data? Lars Lindhagen, UCR 2014-05-21 Inledning Saknat data finns alltid, åtminstone i stora registerstudier. Ett problem som måste hanteras på något sätt.
Missing data och imputation eller Får man hitta på data? Lars Lindhagen, UCR 2014-05-21 Inledning Saknat data finns alltid, åtminstone i stora registerstudier. Ett problem som måste hanteras på något sätt.
Gör uppgift 6.10 i arbetsmaterialet (ingår på övningen 16 maj). För 10 torskar har vi värden på variablerna Längd (cm) och Ålder (år).
. För 10 torskar har vi värden på variablerna Längd (cm) och Ålder (år).") Matematikcentrum Matematisk statistik MASB11: BIOSTATISTISK GRUNDKURS DATORLABORATION 4, 21 MAJ 2018 REGRESSION OCH FORTSÄTTNING PÅ MINIPROJEKT II Syfte Syftet med dagens laboration är att du ska bekanta
Matematikcentrum Matematisk statistik MASB11: BIOSTATISTISK GRUNDKURS DATORLABORATION 4, 21 MAJ 2018 REGRESSION OCH FORTSÄTTNING PÅ MINIPROJEKT II Syfte Syftet med dagens laboration är att du ska bekanta
Statistik B Regressions- och tidsserieanalys Föreläsning 1
 Statistik B Regressions- och tidsserieanalys Föreläsning Kurskod: 732G7, 8 hp Lärare och examinator: Ann-Charlotte (Lotta) Hallberg Lärare och lektionsledare: Isak Hietala Labassistenter Kap 3,-3,6. Läs
Statistik B Regressions- och tidsserieanalys Föreläsning Kurskod: 732G7, 8 hp Lärare och examinator: Ann-Charlotte (Lotta) Hallberg Lärare och lektionsledare: Isak Hietala Labassistenter Kap 3,-3,6. Läs
Laboration 4 R-versionen
 Matematikcentrum 1(5) Matematisk Statistik Lunds Universitet MASB11 VT13, lp3 Laboration 4 R-versionen Regressionsanalys 2013-03-07 Syftet med laborationen är att vi skall bekanta oss med lite av de funktioner
Matematikcentrum 1(5) Matematisk Statistik Lunds Universitet MASB11 VT13, lp3 Laboration 4 R-versionen Regressionsanalys 2013-03-07 Syftet med laborationen är att vi skall bekanta oss med lite av de funktioner
Föreläsning 9. NDAB01 Statistik; teori och tillämpning i biologi
 Föreläsning 9 Statistik; teori och tillämpning i biologi 1 (kap. 20) Introduktion I föregående föreläsning diskuterades enkel linjär regression, där en oberoende variabel X förklarar variationen hos en
Föreläsning 9 Statistik; teori och tillämpning i biologi 1 (kap. 20) Introduktion I föregående föreläsning diskuterades enkel linjär regression, där en oberoende variabel X förklarar variationen hos en
Regressions- och Tidsserieanalys - F7
 Regressions- och Tidsserieanalys - F7 Tidsserieregression, kap 6.1-6.4 Linda Wänström Linköpings universitet November 25 Wänström (Linköpings universitet) F7 November 25 1 / 28 Tidsserieregressionsanalys
Regressions- och Tidsserieanalys - F7 Tidsserieregression, kap 6.1-6.4 Linda Wänström Linköpings universitet November 25 Wänström (Linköpings universitet) F7 November 25 1 / 28 Tidsserieregressionsanalys
Stroke många drabbas men allt fler överlever
 Stroke många drabbas men allt fler överlever Birgitta Stegmayr Docent i medicin Stroke är en vanlig sjukdom. Här i Sverige drabbas troligen 30 000 35 000 personer per år av ett slaganfall, som också är
Stroke många drabbas men allt fler överlever Birgitta Stegmayr Docent i medicin Stroke är en vanlig sjukdom. Här i Sverige drabbas troligen 30 000 35 000 personer per år av ett slaganfall, som också är
LABORATION 3 - Regressionsanalys
 Institutionen för teknikvetenskap och matematik S0001M Matematisk statistik, LP1, HT 2015, Adam Jonsson LABORATION 3 - Regressionsanalys I denna laboration ska du lösa ett antal uppgifter i enkel regressionsanalys
Institutionen för teknikvetenskap och matematik S0001M Matematisk statistik, LP1, HT 2015, Adam Jonsson LABORATION 3 - Regressionsanalys I denna laboration ska du lösa ett antal uppgifter i enkel regressionsanalys
Multipel Regressionsmodellen
 Multipel Regressionsmodellen Koefficienterna i multipel regression skattas från ett stickprov enligt: Multipel Regressionsmodell med k förklarande variabler: Skattad (predicerad) Värde på y y ˆ = b + b
Multipel Regressionsmodellen Koefficienterna i multipel regression skattas från ett stickprov enligt: Multipel Regressionsmodell med k förklarande variabler: Skattad (predicerad) Värde på y y ˆ = b + b
ordinalskala kvotskala F65A nominalskala F65B kvotskala nominalskala (motivering krävs för full poäng)
") 1 F1 ordinalskala F2 kvotskala F65A nominalskala F65B kvotskala F81 nominalskala (motivering krävs för full poäng) b) Variabler som används är F2 och F65b. Eftersom det är kvotskala på båda kan vi använda
1 F1 ordinalskala F2 kvotskala F65A nominalskala F65B kvotskala F81 nominalskala (motivering krävs för full poäng) b) Variabler som används är F2 och F65b. Eftersom det är kvotskala på båda kan vi använda
F3 Introduktion Stickprov
 Utrotningshotad tandnoting i arktiska vatten Inferens om väntevärde baserat på medelvärde och standardavvikelse Matematik och statistik för biologer, 10 hp Tandnoting är en torskliknande fisk som lever
Utrotningshotad tandnoting i arktiska vatten Inferens om väntevärde baserat på medelvärde och standardavvikelse Matematik och statistik för biologer, 10 hp Tandnoting är en torskliknande fisk som lever
10.1 Enkel linjär regression
 Exempel: Hur mycket dragkraft behövs för att en halvledare skall lossna från sin sockel vid olika längder på halvledarens ben. De halvledare vi betraktar är av samma storlek (bortsett benlängden). 70 Scatterplot
Exempel: Hur mycket dragkraft behövs för att en halvledare skall lossna från sin sockel vid olika längder på halvledarens ben. De halvledare vi betraktar är av samma storlek (bortsett benlängden). 70 Scatterplot
Regressions- och Tidsserieanalys - F4
 Regressions- och Tidsserieanalys - F4 Modellbygge och residualanalys. Kap 5.1-5.4 (t.o.m. halva s 257), ej C-statistic s 23. Linda Wänström Linköpings universitet Wänström (Linköpings universitet) F4 1
Regressions- och Tidsserieanalys - F4 Modellbygge och residualanalys. Kap 5.1-5.4 (t.o.m. halva s 257), ej C-statistic s 23. Linda Wänström Linköpings universitet Wänström (Linköpings universitet) F4 1
Regressions- och Tidsserieanalys - F3
 Regressions- och Tidsserieanalys - F3 Multipel regressionsanalys kap 4.8-4.10 Linda Wänström Linköpings universitet November 6, 2013 Wänström (Linköpings universitet) F3 November 6, 2013 1 / 22 Interaktion
Regressions- och Tidsserieanalys - F3 Multipel regressionsanalys kap 4.8-4.10 Linda Wänström Linköpings universitet November 6, 2013 Wänström (Linköpings universitet) F3 November 6, 2013 1 / 22 Interaktion
MULTIPEL IMPUTATION - Ett sätt att hantera problemet med missing data
 MULTIPEL IMPUTATION - Ett sätt att hantera problemet med missing data Pär-Ola Bendahl IKVL, Avdelningen för Onkologi Lunds Universitet Par-Ola.Bendahl@med.lu.se Översikt Introduktion till problemet Enkla
MULTIPEL IMPUTATION - Ett sätt att hantera problemet med missing data Pär-Ola Bendahl IKVL, Avdelningen för Onkologi Lunds Universitet Par-Ola.Bendahl@med.lu.se Översikt Introduktion till problemet Enkla
Grundläggande Biostatistik. Joacim Rocklöv, Lektor Epidemiologi och global hälsa Umeå Universitet
 Grundläggande Biostatistik Joacim Rocklöv, Lektor Epidemiologi och global hälsa Umeå Universitet Formell analys Informell data analys Design and mätning Problem Formell analys Informell data analys Hur
Grundläggande Biostatistik Joacim Rocklöv, Lektor Epidemiologi och global hälsa Umeå Universitet Formell analys Informell data analys Design and mätning Problem Formell analys Informell data analys Hur
Kapitel 18: LINJÄRA SANNOLIKHETSMODELLER, LOGIT OCH PROBIT
 Kapitel 18: LINJÄRA SANNOLIKHETSMODELLER, LOGIT OCH PROBIT Regressionsanalys handlar om att estimera hur medelvärdet för en variabel (y) varierar med en eller flera oberoende variabler (x). Exempel: Hur
Kapitel 18: LINJÄRA SANNOLIKHETSMODELLER, LOGIT OCH PROBIT Regressionsanalys handlar om att estimera hur medelvärdet för en variabel (y) varierar med en eller flera oberoende variabler (x). Exempel: Hur
Autokorrelation och Durbin-Watson testet. Patrik Zetterberg. 17 december 2012
 Föreläsning 6 Autokorrelation och Durbin-Watson testet Patrik Zetterberg 17 december 2012 1 / 14 Korrelation och autokorrelation På tidigare föreläsningar har vi analyserat korrelationer för stickprov
Föreläsning 6 Autokorrelation och Durbin-Watson testet Patrik Zetterberg 17 december 2012 1 / 14 Korrelation och autokorrelation På tidigare föreläsningar har vi analyserat korrelationer för stickprov
Bilaga 6 till rapport 1 (5)
") till rapport 1 (5) Bilddiagnostik vid misstänkt prostatacancer, rapport UTV2012/49 (2014). Värdet av att undvika en prostatabiopsitagning beskrivning av studien SBU har i samarbete med Centrum för utvärdering
till rapport 1 (5) Bilddiagnostik vid misstänkt prostatacancer, rapport UTV2012/49 (2014). Värdet av att undvika en prostatabiopsitagning beskrivning av studien SBU har i samarbete med Centrum för utvärdering
Jämförande av risk för omoperation mellan två operationsmetoder vid ljumskbråck
 Jämförande av risk för omoperation mellan två operationsmetoder vid ljumskbråck En tillämpning av överlevnadsanalys Andreas Lövgren & Joakim Strandberg Umeå Universitet Examensarbete, 15 hp Vt 2019 Handledare:
Jämförande av risk för omoperation mellan två operationsmetoder vid ljumskbråck En tillämpning av överlevnadsanalys Andreas Lövgren & Joakim Strandberg Umeå Universitet Examensarbete, 15 hp Vt 2019 Handledare:
Skrivning i ekonometri torsdagen den 8 februari 2007
 LUNDS UNIVERSITET STATISTISKA INSTITUTIONEN MATS HAGNELL STA2:3 Skrivning i ekonometri torsdagen den 8 februari 27. Vi vill undersöka hur variationen i lön för 2 belgiska löntagare = WAGE (timlön i euro)
LUNDS UNIVERSITET STATISTISKA INSTITUTIONEN MATS HAGNELL STA2:3 Skrivning i ekonometri torsdagen den 8 februari 27. Vi vill undersöka hur variationen i lön för 2 belgiska löntagare = WAGE (timlön i euro)
Statistiska metoder. - Praktiska erfarenheter från Riksstrokes forskning
 Statistiska metoder - Praktiska erfarenheter från Riksstrokes forskning Marie Eriksson, Docent Enheten för Statistik, Umeå universitet Riksstroke, Norrlands Universitetssjukhus Allmänt om stroke Tredje
Statistiska metoder - Praktiska erfarenheter från Riksstrokes forskning Marie Eriksson, Docent Enheten för Statistik, Umeå universitet Riksstroke, Norrlands Universitetssjukhus Allmänt om stroke Tredje
För logitmodellen ges G (=F) av den logistiska funktionen: (= exp(z)/(1+ exp(z))
 av den logistiska funktionen: (= exp(z)/(1+ exp(z))") Logitmodellen För logitmodellen ges G (=F) av den logistiska funktionen: F(z) = e z /(1 + e z ) (= exp(z)/(1+ exp(z)) Funktionen motsvarar den kumulativa fördelningsfunktionen för en standardiserad logistiskt
Logitmodellen För logitmodellen ges G (=F) av den logistiska funktionen: F(z) = e z /(1 + e z ) (= exp(z)/(1+ exp(z)) Funktionen motsvarar den kumulativa fördelningsfunktionen för en standardiserad logistiskt
Residualanalys. Finansiell statistik, vt-05. Normalfördelade? Normalfördelade? För modellen
 Residualanalys För modellen Johan Koskinen, Statistiska institutionen, Stockholms universitet Finansiell statistik, vt-5 F7 regressionsanalys antog vi att ε, ε,..., ε är oberoende likafördelade N(,σ Då
Residualanalys För modellen Johan Koskinen, Statistiska institutionen, Stockholms universitet Finansiell statistik, vt-5 F7 regressionsanalys antog vi att ε, ε,..., ε är oberoende likafördelade N(,σ Då
Tentamen i Tillämpad statistisk analys, GN, 7.5 hp. 23 maj 2013 kl. 9 14
 STOCKHOLMS UNIVERSITET MT4003 MATEMATISKA INSTITUTIONEN LÖSNINGAR Avd. Matematisk statistik 3 maj 013 Lösningar Tentamen i Tillämpad statistisk analys, GN, 7.5 hp 3 maj 013 kl. 9 14 Uppgift 1 a Eftersom
STOCKHOLMS UNIVERSITET MT4003 MATEMATISKA INSTITUTIONEN LÖSNINGAR Avd. Matematisk statistik 3 maj 013 Lösningar Tentamen i Tillämpad statistisk analys, GN, 7.5 hp 3 maj 013 kl. 9 14 Uppgift 1 a Eftersom
Statistiska metoder för säkerhetsanalys
 F10: Intensiteter och Poissonmodeller Frågeställningar Konstant V.v.=Var Cyklister Poissonmodeller för frekvensdata Vi gör oberoende observationer av de (absoluta) frekvenserna n 1, n 2,..., n k från den
F10: Intensiteter och Poissonmodeller Frågeställningar Konstant V.v.=Var Cyklister Poissonmodeller för frekvensdata Vi gör oberoende observationer av de (absoluta) frekvenserna n 1, n 2,..., n k från den
Tillämpad statistik (A5), HT15 Föreläsning 10: Multipel linjär regression 1
, HT15 Föreläsning 10: Multipel linjär regression 1") Tillämpad statistik (A5), HT15 Föreläsning 10: Multipel linjär regression 1 Ronnie Pingel Statistiska institutionen Senast uppdaterad: 2015-11-19 Motivering Vi motiverade enkel linjär regression som ett
Tillämpad statistik (A5), HT15 Föreläsning 10: Multipel linjär regression 1 Ronnie Pingel Statistiska institutionen Senast uppdaterad: 2015-11-19 Motivering Vi motiverade enkel linjär regression som ett
FACIT (korrekta svar i röd fetstil)
") v. 2013-01-14 Statistik, 3hp PROTOKOLL FACIT (korrekta svar i röd fetstil) Datorlaboration 2 Konfidensintervall & hypotesprövning Syftet med denna laboration är att ni med hjälp av MS Excel ska fortsätta
v. 2013-01-14 Statistik, 3hp PROTOKOLL FACIT (korrekta svar i röd fetstil) Datorlaboration 2 Konfidensintervall & hypotesprövning Syftet med denna laboration är att ni med hjälp av MS Excel ska fortsätta
En rät linje ett enkelt samband. En rät linje + slumpbrus. Observationspar (X i,y i ) MSG Staffan Nilsson, Chalmers 1.
 MSG Staffan Nilsson, Chalmers 1.") En rät linje ett enkelt samband Y β 1 Lutning (slope) β 0 Skärning (intercept) 1 Y= β 0 + β 1 X X En rät linje + slumpbrus Y Y= β 0 + β 1 X + brus brus ~ N(0,σ) X Observationspar (X i,y i ) Y Ökar/minskar
En rät linje ett enkelt samband Y β 1 Lutning (slope) β 0 Skärning (intercept) 1 Y= β 0 + β 1 X X En rät linje + slumpbrus Y Y= β 0 + β 1 X + brus brus ~ N(0,σ) X Observationspar (X i,y i ) Y Ökar/minskar
BETYDELSEN AV COMPETING RISK
 BETYDELSEN AV COMPETING RISK En analys av demens utifrån Betulaprojektets datainsamling när konkurrerande utfall tas i beaktande. Jesper Ericson, Härje Widing Kandidatuppsats, 15 hp Statistik C2, 15 hp
BETYDELSEN AV COMPETING RISK En analys av demens utifrån Betulaprojektets datainsamling när konkurrerande utfall tas i beaktande. Jesper Ericson, Härje Widing Kandidatuppsats, 15 hp Statistik C2, 15 hp
Laboration 2: Styrkefunktion samt Regression
 Lunds Tekniska Högskola Matematikcentrum Matematisk statistik Laboration 2 Styrkefunktion & Regression FMSF70&MASB02, HT19 Laboration 2: Styrkefunktion samt Regression Syfte Styrkefunktion Syftet med dagens
Lunds Tekniska Högskola Matematikcentrum Matematisk statistik Laboration 2 Styrkefunktion & Regression FMSF70&MASB02, HT19 Laboration 2: Styrkefunktion samt Regression Syfte Styrkefunktion Syftet med dagens
Lösningar till SPSS-övning: Analytisk statistik
 UMEÅ UNIVERSITET Statistiska institutionen 2006--28 Lösningar till SPSS-övning: Analytisk statistik Test av skillnad i medelvärden mellan två grupper Uppgift Testa om det är någon skillnad i medelvikt
UMEÅ UNIVERSITET Statistiska institutionen 2006--28 Lösningar till SPSS-övning: Analytisk statistik Test av skillnad i medelvärden mellan två grupper Uppgift Testa om det är någon skillnad i medelvikt
Sammanfattning. Förord
 Sammanfattning Varför regerar vissa ledare längre än andra? Uppsatsen använder ett datamaterial över ledares tid vid makten i 167 länder från början av 1800-talet till 1987 för att försöka besvara denna
Sammanfattning Varför regerar vissa ledare längre än andra? Uppsatsen använder ett datamaterial över ledares tid vid makten i 167 länder från början av 1800-talet till 1987 för att försöka besvara denna
Legitimacy of newness and smallness - En studie i överlevnad för små och nya företag
 Legitimacy of newness and smallness - En studie i överlevnad för små och nya företag Cecilia Söderberg Kandidatuppsats i matematisk statistik Bachelor Thesis in Mathematical Statistics Kandidatuppsats
Legitimacy of newness and smallness - En studie i överlevnad för små och nya företag Cecilia Söderberg Kandidatuppsats i matematisk statistik Bachelor Thesis in Mathematical Statistics Kandidatuppsats
Matematisk statistik för D, I, Π och Fysiker
 Matematisk statistik för D, I, Π och Fysiker Föreläsning 15 Johan Lindström 4 december 218 Johan Lindström - johanl@maths.lth.se FMSF45/MASB3 F15 1/28 Repetition Linjär regression Modell Parameterskattningar
Matematisk statistik för D, I, Π och Fysiker Föreläsning 15 Johan Lindström 4 december 218 Johan Lindström - johanl@maths.lth.se FMSF45/MASB3 F15 1/28 Repetition Linjär regression Modell Parameterskattningar
Kapitel 12: TEST GÄLLANDE EN GRUPP KOEFFICIENTER - ANOVA
 Kapitel 12: TEST GÄLLANDE EN GRUPP KOEFFICIENTER - ANOVA 12.1 ANOVA I EN MULTIPEL REGRESSION Exempel: Tjänar man mer som egenföretagare? Nedan visas ett utdrag ur ett dataset som innehåller information
Kapitel 12: TEST GÄLLANDE EN GRUPP KOEFFICIENTER - ANOVA 12.1 ANOVA I EN MULTIPEL REGRESSION Exempel: Tjänar man mer som egenföretagare? Nedan visas ett utdrag ur ett dataset som innehåller information
Syftet med den här laborationen är att du skall bli mer förtrogen med det i praktiken kanske viktigaste området inom kursen nämligen
 LUNDS TEKNISKA HÖGSKOLA MATEMATIKCENTRUM MATEMATISK STATISTIK DATORLABORATION 6 MATEMATISK STATISTIK, AK FÖR I, FMS 120, HT-00 Laboration 6: Regression Syftet med den här laborationen är att du skall bli
LUNDS TEKNISKA HÖGSKOLA MATEMATIKCENTRUM MATEMATISK STATISTIK DATORLABORATION 6 MATEMATISK STATISTIK, AK FÖR I, FMS 120, HT-00 Laboration 6: Regression Syftet med den här laborationen är att du skall bli
Föreläsning 12: Regression
 Föreläsning 12: Regression Matematisk statistik David Bolin Chalmers University of Technology Maj 15, 2014 Binomialfördelningen Låt X Bin(n, p). Vi observerar x och vill ha information om p. p = x/n är
Föreläsning 12: Regression Matematisk statistik David Bolin Chalmers University of Technology Maj 15, 2014 Binomialfördelningen Låt X Bin(n, p). Vi observerar x och vill ha information om p. p = x/n är
Användning. Fixed & Random. Centrering. Multilevel Modeling (MLM) Var sak på sin nivå
 Var sak på sin nivå") Användning Multilevel Modeling (MLM) Var sak på sin nivå Kimmo Sorjonen Sektionen för Psykologi Karolinska Institutet Kärt barn har många namn: (1) Random coefficient models; (2) Mixed effect models; (3)
Användning Multilevel Modeling (MLM) Var sak på sin nivå Kimmo Sorjonen Sektionen för Psykologi Karolinska Institutet Kärt barn har många namn: (1) Random coefficient models; (2) Mixed effect models; (3)
Tentamen för kursen. Linjära statistiska modeller. 16 augusti 2007 9 14
 STOCKHOLMS UNIVERSITET MATEMATISK STATISTIK Tentamen för kursen Linjära statistiska modeller 16 augusti 2007 9 14 Examinator: Anders Björkström, tel. 16 45 54, bjorks@math.su.se Återlämning: Rum 312, hus
STOCKHOLMS UNIVERSITET MATEMATISK STATISTIK Tentamen för kursen Linjära statistiska modeller 16 augusti 2007 9 14 Examinator: Anders Björkström, tel. 16 45 54, bjorks@math.su.se Återlämning: Rum 312, hus
I vår laboration kom vi fram till att kroppstemperaturen påverkar hjärtfrekvensen enligt
 Introduktion Vi har fått ta del av 13 mätningar av kroppstemperatur och hjärtfrekvens, varav på hälften män, hälften kvinnor, samt en studie på 77 olika flingsorters hyllplaceringar och sockerhalter. Vi
Introduktion Vi har fått ta del av 13 mätningar av kroppstemperatur och hjärtfrekvens, varav på hälften män, hälften kvinnor, samt en studie på 77 olika flingsorters hyllplaceringar och sockerhalter. Vi
Socioekonomiska ojämlikheter i prehospital strokevård
 Socioekonomiska ojämlikheter i prehospital strokevård Amanda Niklasson 1, MD. Johan Herlitz 2, MD, PhD. Katarina Jood 1, MD, PhD. 1. Sektionen för klinisk neurovetenskap, Institutionen för neurovetenskap
Socioekonomiska ojämlikheter i prehospital strokevård Amanda Niklasson 1, MD. Johan Herlitz 2, MD, PhD. Katarina Jood 1, MD, PhD. 1. Sektionen för klinisk neurovetenskap, Institutionen för neurovetenskap
Kapitel 4: SAMBANDET MELLAN VARIABLER: REGRESSIONSLINJEN
 Kapitel 4: SAMBANDET MELLAN VARIABLER: REGRESSIONSLINJEN Spridningsdiagrammen nedan representerar samma korrelationskoefficient, r = 0,8. 80 80 60 60 40 40 20 20 0 0 20 40 0 0 20 40 Det finns dock två
Kapitel 4: SAMBANDET MELLAN VARIABLER: REGRESSIONSLINJEN Spridningsdiagrammen nedan representerar samma korrelationskoefficient, r = 0,8. 80 80 60 60 40 40 20 20 0 0 20 40 0 0 20 40 Det finns dock två
För logitmodellen ges G (=F) av den logistiska funktionen: (= exp(z)/(1+ exp(z))
 av den logistiska funktionen: (= exp(z)/(1+ exp(z))") Logitmodellen För logitmodellen ges G (=F) av den logistiska funktionen: F(z) = e z /(1 + e z ) (= exp(z)/(1+ exp(z)) Funktionen motsvarar den kumulativa fördelningsfunktionen för en standardiserad logistiskt
Logitmodellen För logitmodellen ges G (=F) av den logistiska funktionen: F(z) = e z /(1 + e z ) (= exp(z)/(1+ exp(z)) Funktionen motsvarar den kumulativa fördelningsfunktionen för en standardiserad logistiskt
TVM-Matematik Adam Jonsson
 TVM-Matematik Adam Jonsson 014-1-09 LABORATION 3 I MATEMATISK STATISTIK, S0001M REGRESSIONSANALYS I denna laboration ska du lösa ett antal uppgifter i regressionsanalys med hjälp av statistikprogrammet
TVM-Matematik Adam Jonsson 014-1-09 LABORATION 3 I MATEMATISK STATISTIK, S0001M REGRESSIONSANALYS I denna laboration ska du lösa ett antal uppgifter i regressionsanalys med hjälp av statistikprogrammet
Analytisk statistik. Mattias Nilsson Benfatto, PhD.
 Analytisk statistik Mattias Nilsson Benfatto, PhD Mattias.nilsson@ki.se Beskrivande statistik kort repetition Centralmått Spridningsmått Normalfördelning Konfidensintervall Korrelation Analytisk statistik
Analytisk statistik Mattias Nilsson Benfatto, PhD Mattias.nilsson@ki.se Beskrivande statistik kort repetition Centralmått Spridningsmått Normalfördelning Konfidensintervall Korrelation Analytisk statistik
LABORATION 3 - Regressionsanalys
 Institutionen för teknikvetenskap och matematik S0001M Matematisk statistik LABORATION 3 - Regressionsanalys I denna laboration ska du lösa ett antal uppgifter i regressionsanalys med hjälp av statistik-programmet
Institutionen för teknikvetenskap och matematik S0001M Matematisk statistik LABORATION 3 - Regressionsanalys I denna laboration ska du lösa ett antal uppgifter i regressionsanalys med hjälp av statistik-programmet
Statistik och epidemiologi T5
 Statistik och epidemiologi T5 Anna Axmon Biostatistiker Yrkes- och miljömedicin Dagens föreläsning Fördjupning av hypotesprövning Repetition av p-värde och konfidensintervall Tester för ytterligare situationer
Statistik och epidemiologi T5 Anna Axmon Biostatistiker Yrkes- och miljömedicin Dagens föreläsning Fördjupning av hypotesprövning Repetition av p-värde och konfidensintervall Tester för ytterligare situationer
Medicinsk statistik II
 Medicinsk statistik II Läkarprogrammet T5 HT 2014 Susann Ullén FoU-centrum Skåne Skånes Universitetssjukhus Hypotesprövning Man sätter upp en nollhypotes (H0) och en mothypotes (H1) H0: Ingen effekt H1:
Medicinsk statistik II Läkarprogrammet T5 HT 2014 Susann Ullén FoU-centrum Skåne Skånes Universitetssjukhus Hypotesprövning Man sätter upp en nollhypotes (H0) och en mothypotes (H1) H0: Ingen effekt H1:
Examensarbete 2007:19
 Matematisk statistik Stockholms universitet Prevalens och förväntad återstående livslängd som funktion av incidens och mortalitet. Utveckling och tillämpning av en modell för demens i en population Tommy
Matematisk statistik Stockholms universitet Prevalens och förväntad återstående livslängd som funktion av incidens och mortalitet. Utveckling och tillämpning av en modell för demens i en population Tommy
Dekomponering av löneskillnader
 Lönebildningsrapporten 2013 133 FÖRDJUPNING Dekomponering av löneskillnader Den här fördjupningen ger en detaljerad beskrivning av dekomponeringen av skillnader i genomsnittlig lön. Först beskrivs metoden
Lönebildningsrapporten 2013 133 FÖRDJUPNING Dekomponering av löneskillnader Den här fördjupningen ger en detaljerad beskrivning av dekomponeringen av skillnader i genomsnittlig lön. Först beskrivs metoden
a) Anpassa en trinomial responsmodell med övriga relevanta variabler som (icketransformerade)
 Anpassa en trinomial responsmodell med övriga relevanta variabler som (icketransformerade)") 5:1 Studien ifråga, High School and beyond, går ut på att hitta ett samband mellan vilken typ av program generellt, praktiskt eller akademiskt som studenter väljer baserat på olika faktorer kön, ras, socioekonomisk
5:1 Studien ifråga, High School and beyond, går ut på att hitta ett samband mellan vilken typ av program generellt, praktiskt eller akademiskt som studenter väljer baserat på olika faktorer kön, ras, socioekonomisk
Instruktioner till Inlämningsuppgift 1 och Datorövning 1
 STOCKHOLMS UNIVERSITET HT 2005 Statistiska institutionen 2005-10-14 MC Instruktioner till Inlämningsuppgift 1 och Datorövning 1 Kurs i Ekonometri, 5 poäng. Uppgiften ingår i examinationen för kursen och
STOCKHOLMS UNIVERSITET HT 2005 Statistiska institutionen 2005-10-14 MC Instruktioner till Inlämningsuppgift 1 och Datorövning 1 Kurs i Ekonometri, 5 poäng. Uppgiften ingår i examinationen för kursen och
F19, (Multipel linjär regression forts) och F20, Chi-två test.
 och F20, Chi-två test.") Partiella t-test F19, (Multipel linjär regression forts) och F20, Chi-två test. Christian Tallberg Statistiska institutionen Stockholms universitet Då man testar om en enskild variabel X i skall vara med
Partiella t-test F19, (Multipel linjär regression forts) och F20, Chi-två test. Christian Tallberg Statistiska institutionen Stockholms universitet Då man testar om en enskild variabel X i skall vara med
Uppföljning Nationella strokekampanjen. Susanne Hillberger
 Uppföljning Nationella strokekampanjen Susanne Hillberger 2013-04-12 Vad är stroke? Från hjärnan styrs flera av kroppens funktioner bland annat rörelse, tankar och sömn. Miljarder hjärnceller samarbetar
Uppföljning Nationella strokekampanjen Susanne Hillberger 2013-04-12 Vad är stroke? Från hjärnan styrs flera av kroppens funktioner bland annat rörelse, tankar och sömn. Miljarder hjärnceller samarbetar
Regressions- och Tidsserieanalys - F3
 Regressions- och Tidsserieanalys - F3 Multipel regressionsanalys kap 4.8-4.10 Linda Wänström Linköpings universitet Wänström (Linköpings universitet) F3 1 / 21 Interaktion Ibland ser sambandet mellan en
Regressions- och Tidsserieanalys - F3 Multipel regressionsanalys kap 4.8-4.10 Linda Wänström Linköpings universitet Wänström (Linköpings universitet) F3 1 / 21 Interaktion Ibland ser sambandet mellan en
TENTAMEN I MATEMATISK STATISTIK
 UMEÅ UNIVERSITET Institutionen för matematisk statistik Regressions- och variansanalys, 5 poäng MSTA35 Leif Nilsson TENTAMEN 2003-01-10 TENTAMEN I MATEMATISK STATISTIK Regressions- och variansanalys, 5
UMEÅ UNIVERSITET Institutionen för matematisk statistik Regressions- och variansanalys, 5 poäng MSTA35 Leif Nilsson TENTAMEN 2003-01-10 TENTAMEN I MATEMATISK STATISTIK Regressions- och variansanalys, 5