Examensarbete 2007:19
|
|
|
- Helena Nilsson
- för 8 år sedan
- Visningar:
Transkript
1 Matematisk statistik Stockholms universitet Prevalens och förväntad återstående livslängd som funktion av incidens och mortalitet. Utveckling och tillämpning av en modell för demens i en population Tommy Andersson Examensarbete 007:9

2 Postal address: Matematisk statistik Dept. of Mathematics Stockholms universitet SE-06 9 Stockholm Sweden Internet:

3 Matematisk statistik Stockholms universitet Examensarbete 007:9, Prevalens och förväntad återstående livslängd som funktion av incidens och mortalitet. Utveckling och tillämpning av en modell för demens i en population Tommy Andersson November 007 Sammanfattning Föreliggande rapport ger en redogörelse för hur man kan konstruera en modell som beskriver prevalens (andel sjuka personer vid en viss tidpunk som resultat av incidens (andel friska personer som insjuknar under en viss tidsperiod) och mortalitet (andel personer som avlider under en viss tidsperiod). Dessutom beskrivs hur man kan konstruera en modell som skattar återstående livslängd uppdelat på friska och sjuka år. Avslutningsvis görs ett försök att beskriva en modell som, under vissa antaganden, säger något om framtiden. Postal address: Matematisk statistik, Stockholms universitet, SE-06 9, Stockholm, Sweden. tommy@rumsventilation.se. Handledare: Anders Björkström
. Dessutom beskrivs hur man kan konstruera en modell som skattar återstående livslängd uppdelat på friska och sjuka år.")
4 Abstract This report gives an account of the creation of a model that describes prevalence (the share of ill persons at a certain point in time) as a result of incidence (the share of persons who becomes ill during a defined time interval) and mortality (the share of persons who dies during a defined time interval). Furthermore, it describes how to construct a model that estimates life expectancy divided into healthy and ill years. Finally, it makes an attempt to describe a model that, under certain assumptions, can tell us something about the future.

5 Förord Denna rapport utgör mitt examensarbete för en magisterexamen i matematisk statistik på Stockholms Universitet. Initiativtagare till detta arbete är Mårten Lagergren, docent på Stiftelsen Stockholms Läns Äldrecentrum, och till honom vill jag rikta ett stort tack. Mårten har under arbetets gång lärt mig otroligt mycket och utan honom hade denna rapport aldrig blivit av. I arbetet tar jag även hjälp av modellerna från två andra examensarbeten som är skrivna av Sofia Qvarnström och Malin Düring och de båda förtjänar ett tack. Min handledare Anders Björkström förtjänar också slutligen ett stort tack för att han outtröttligt har svarat på alla mina frågor. 3

6 4
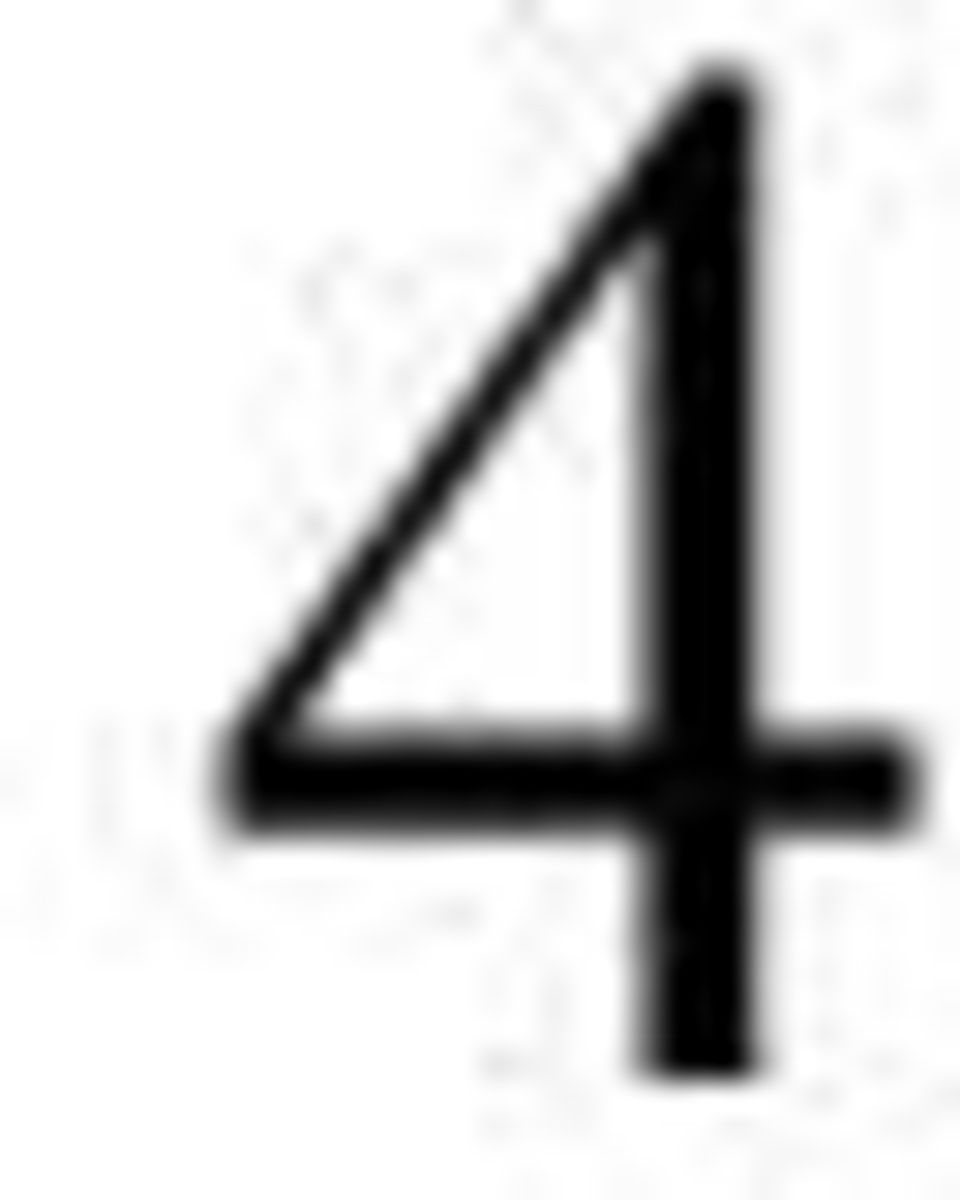
7 Innehåll. Inledning Målsättning Data Modell och Metod Övergångssannolikheter Prevalens Återstående livslängd Tillämpning, av modellen, på Sverige PIM-modellen Återstående livslängd Antagande om p ˆ och p ˆ Appendix A, Formler Appendix B, Tabeller Referenser

8 6
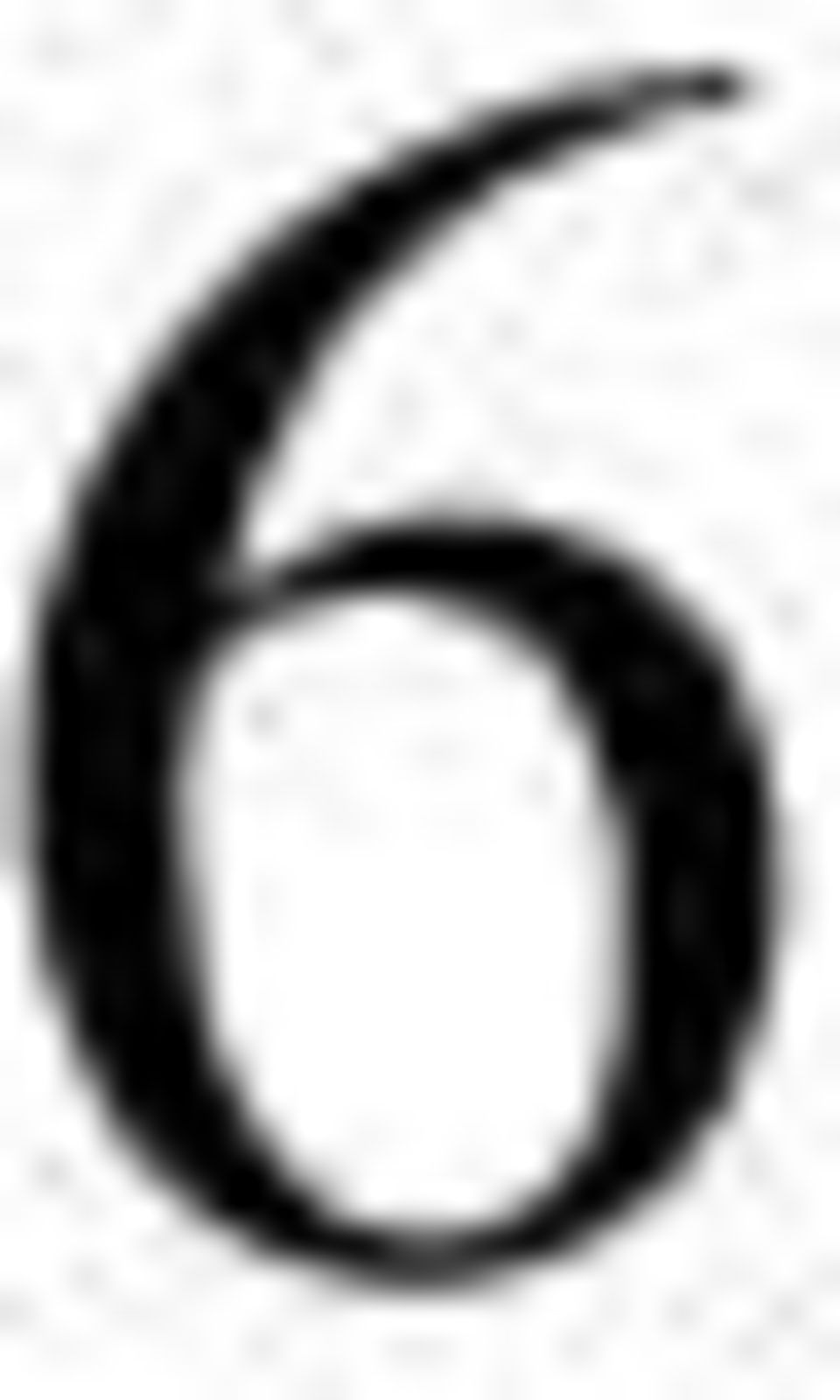
9 . Inledning Den här rapporten är skriven på uppdrag av Stiftelsen Stockholms Läns Äldrecentrum. Stiftelsen har till uppgift att initiera och genomföra forskning samt att verka för att praktiskt omsätta erfarenheter och forskningsresultat inom områden av särskild betydelse för äldres situation i samhället. Mårten Lagergren, docent på Äldrecentrum, har bidragit med det datamaterial som har använts och det är även han som har formulerat problemet.. Målsättning I den här rapporten tittar vi på tre storheter: Prevalens Andel sjuka personer vid en viss tidpunkt. Alltså antalet personer som är sjuka vid en viss tidpunkt i förhållande till alla som lever vid motsvarande tidpunkt. Incidens Andel personer som insjuknar under en viss tidsperiod. Mortalitet Andel personer som dör under en viss tidsperiod. Vi vill göra en prevalens, incidens och mortalitetsmodell där vi beskriver hur prevalensen beror på incidensen och mortaliteten, med avseende på ålder. Denna modell kallar vi hädan efter för en PIM-modell. Vi vill även göra det möjligt att se hur en förändring av incidens och mortalitet skulle påverka prevalensen. Från dessa storheter ska vi också göra en modell som ger återstående livslängd uppdelat på friska och sjuka år. Tanken är också att vi ska försöka tillämpa modellerna på Sverige och under vissa antaganden se hur många sjuka personer vi kan komma att ha i varje åldersgrupp i framtiden. Med samma antaganden ska vi också få ut förväntat återstående friska och sjuka år för dessa. Som grund till modellen för prevalens används Sofia Qvarnströms rapport Modellering av prevalens som resultat av incidens och mortalitet och som grund till modellen för återstående livslängd används Malin Dürings rapport Kommer en längre livslängd innebära fler friska år? 3. Båda dessa modeller har även i denna rapport utvecklats för att på ett bättre sätt stämma överens med verkligheten. Mer information om Äldrecentrum finns på Qvarnström S, Modellering av prevalens som resultat av incidens och mortalitet, Examensarbete 006:4, Matematisk statistik, Stockholms Universitet 3 Düring M, Kommer en längre livslängd att innebära fler friska år?, Examensarbete 006:9, Matematisk statistik, Stockholms Universitet 7

10 3. Data De data som den här rapporten är baserad på kommer från Kungsholmsprojektet 4 som hade syftet att studera förekomsten av sjukdomar bland en stor grupp av äldre personer. Projektet pågick mellan 987 och 000 och alla personer som var födda före 93 och bosatta i Kungsholms församling i Stockholm var inbjudna att delta. Senare utökades datasetet till att även omfatta alla personer över 90 år som var bosatta i S:t Görans församling, som är ett angränsande område. Dessa inkluderades för att undvika att det skulle bli för få observationer i de högre åldrarna. De 368 personer som var med från början kom både från eget och institutionaliserat boende och varje individ fick först genomgå en omfattande klinisk undersökning. Den första undersökningen följdes sedan upp av ytterligare fyra undersökningar. Totalt skulle alltså varje individ genomföra 5 undersökningar så länge de inte under projektets gång avlidit eller av annan anledning avbrutit projektet. Tiden mellan undersökningarna är olika och oberoende och till största delen slumpmässiga. Deltagarna blev intervjuade av sjuksköterskor och undersökta av läkare som mätte blodtryck, längd och vikt och de blev undersökta av en psykolog som även gjorde en omfattande bedömning av minnet. En familjeintervju genomfördes med en nära anhörig eller närstående. Under den intervjun behandlades deltagarens tidigare och nuvarande hälsa, samt utvalda riskfaktorer för de vanligaste kroniska neurodegenerativa sjukdomarna (t.ex. Alzheimers eller Parkinsons sjukdom). Information samlades också in om särskilda ämnen, som till exempel detaljerade uppgifter om yrkesliv, vårdgivarnas börda och användningen av hemsjukvård och hemtjänst. I det dataset som vi har tillgång till ingår bland annat variabler som beskriver fysisk funktionsförmåga utifrån aktiviteter i dagliga livet (ADL), boendeform (eget, hemtjänst eller heldygnsomsorg) samt demens. För demensvariabeln, som vi ska titta på, existerar ingen data för den sista undersökningen så vi går tyvärr miste om mycket information om de högre åldrarna. Det ingår alldeles för få män i det datasetet som samlades in för att vi ska kunna säga något realistiskt om dem, därför tittar vi bara på kvinnorna. För att utöka antalet observationer skulle man kunna använda en modell som behandlar datasetet oberoende av kön, men eftersom vi av erfarenhet vet att kvinnor i snitt lever längre än män skulle den modellen inte bli realistisk, varför det alternativet uteslutits. Vi har dessutom alldeles för få observationer på personer över 95 år så vi nöjer oss med att titta på åldrarna mellan 75 och 95 år. Vi använder även ett dataset från Statistiska Centralbyrån som innehåller Sveriges befolkningsmängd för olika åldrar, kön och årtal. 4 Mer fakta om Kungsholmsprojektet finns på 8

11 4. Modell och Metod 4. Övergångssannolikheter Vi börjar med att konstatera att demensvariabeln har 3 tillstånd: Tillstånd = Frisk Tillstånd = Dement Tillstånd 3 = Död För att beräkna prevalensen och förväntad återstående livstid som frisk respektive sjuk behöver vi skatta sannolikheten att, givet en viss ålder, gå från ett tillstånd till ett annat. Åldern räknas i år och vi behandlar den som en diskret variabel. Vårt dataset börjar vid 75 års ålder och för den åldern har vi individer i både tillstånd och. Vi kan konstatera att en person inte kan gå från sjuk till frisk, eftersom demens är en sjukdom som ej går att bota, och att en död person förblir död. Om man vill använda den här modellen till någon annan sjukdomsvariabel måste man givetvis anta att endast dessa övergångar är möjliga. Detta kan betraktas som en markovkedja med 43 tillstånd. Ett friskt tillstånd för varje ålder, ett dement tillstånd för varje ålder och det absorberande tillståndet död. Tillstånd 3 = Död Tillstånd = Dement Ålder Tillstånd = Frisk Vi definierar p (x) som sannolikheten att gå till tillstånd j vid åldern x + givet att man befinner sig i tillstånd i vid åldern x. Exempelvis är p (80) sannolikheten för en frisk 80-åring att vara sjuk vid 8 års ålder. Vi antar att p ( ), p ( ) och p ( ) varierar med åldern x enligt. x 3 x 3 x log( p ) = α + β x, i < j i =, j =, 3 där α och β är okända parametrar som kan skattas från data. 9

12 För att nu skatta p (x) vill vi beräkna antalet personer i datamaterialet som insjuknar respektive dör vid varje ålder. Vi vet personernas ålder vid varje undersökningstillfälle och vi vet också vilken ålder varje person har när de dör. Vi vet dock inte vid vilken ålder personerna blir sjuka. Det enda vi vet är att om en person är frisk vid en undersökning och sjuk vid nästa har personen blivit sjuk vid någon tidpunkt där emellan. Vi kommer därför att räkna med två olika antaganden: Antagande : Individerna blir sjuka precis efter den sista undersökningen där de observerades vara i tillstånd och har då fortfarande samma ålder som vid undersökningen. Antagande : Individerna blir sjuka precis före den första undersökningen där de observerades vara i tillstånd och har vid insjuknandet samma ålder som vid den undersökningen. Under antagande adderar vi, för varje ålder x, antalet personer som vid åldern x observerades vara i tillstånd och vid nästa undersökning observerades vara i tillstånd. Vi får då summan av antalet personer som antas insjukna vid åldern x. Under antagande adderar vi, för varje ålder x, antalet personer som vid åldern x observerades vara i tillstånd och vid undersökningen innan observerades vara i tillstånd. Även här får vi summan av antalet personer som antas insjukna vid åldern x, men eftersom detta görs under ett annat antagande kommer vi få ett annorlunda resultat. Slutligen gör vi ett medelvärdesantagande för dessa två. Vi säger att A (x) är antalet personer som enligt vårt medelvärdesantagande går från tillstånd i vid åldern x till tillstånd j vid åldern x +. Vi betraktar A (x) som Bin( A( x), p ) 3 j=, i j i =, j =,, 3 och skattar p (x) genom att sätta A p ˆ = 3, i j i =, j =,, 3 A( x) j= Observera att när dessa skattas tas det inte hänsyn till hur länge en person har befunnit sig i tillstånd i. 0

13 Om vi nu plottar dessa skattade övergångssannolikheter ser vi att p och p faktiskt verkar öka exponentiellt med avseende på åldern. Om vi tittar på p så är den betydligt mer oregelbunden. Vi vill dock hålla modellen så enkel som möjligt och antar därför att även den ökar exponentiellt. ˆ ˆ 3 ˆ3 Med hjälp av minsta kvadratmetoden utjämnar vi de ettåriga övergångssannolikheterna med avseende på åldern. Vi skattar alltså linjen α + β x så att summan av kvadraterna på avstånden mellan linjen och observationernas logaritmerade värden minimeras. Observera här att det alltså är det vertikala avståndet vi menar.

14 De nya skattningarna av övergångssannolikheterna blir nu en exponentiell kurva. αˆ + βˆ x pˆ ( x ) = e, j i < i =, j =, 3 3 j=i ( x Givetvis gäller p =, i =, och denna formel används för att skatta p ( ) och p ). x Här skiljer sig vår modell från Sofia Qvarnströms på så sätt att hon gör följande skattningar pˆ = ˆ α + ˆ β x, i j i =, j =,, 3 och hon får då att p blir större än 0 först efter 75 års ålder vilket givetvis är ˆ3 fullkomligt orimligt. Samma sak gäller även för p ˆ och hon hanterar det genom att säga att pˆ är skattningar som gäller givet att individen är frisk vid 75 års ålder. Detta känns inte som en modell som är realistisk och därför har vi istället gjort en exponentiell utjämning enligt ovan. Incidensen motsvaras här av p ˆ och mortaliteten av p ˆ3 och p och med dessa ska vi nu skatta prevalensen. ˆ 3 4. Prevalens Färre än % av Sveriges 65-åringar lider av demens 5 så vi börjar med att göra en approximation och säger att 0 % av de 65-åriga kvinnorna är dementa. Detta kommer inte påverka vårt resultat nämnvärt eftersom vi tittar på intervallet år. Vi definierar sannolikheten att vara frisk respektive sjuk vid åldern x, givet att man var frisk när man var 65, som p ( ) respektive p ( ). x p ˆ får vi ut genom att titta på sannolikheten att vara frisk året innan och multiplicera den med sannolikheten att stanna kvar i det friska tillståndet. ˆ p får vi ut på liknande sätt, men här tar vi hänsyn till att man kan befinna sig i antingen det friska eller det sjuka tillståndet året innan. Vi skriver: p ˆ( x) = pˆ ( x ) pˆ ( x ) p ˆ = pˆ ( x ) pˆ ( x ) + pˆ ( x ) pˆ ( x ) 5 Läs mer om demens på x

15 Vi sätter enligt vår tidigare approximation p ˆ (65) = och givetvis p ˆ (65) = 0. Eftersom vi endast har data för intervallet år så gör vi ett antagande om att kurvorna för övergångssannolikheterna i intervallet år har samma parametrar som de i intervallet år. ˆ 3 Den övre kurvan visar här p och under den finns p och p och nu kan vi alltså stega oss fram för att få ut alla värden på p och p. Prevalensen definieras som andelen av de levande personerna som är sjuka vid en specifik ålder. Denna kan beskrivas med hjälp av sannolikheten att vara sjuk delat med sannolikheten att vara levande. Vi betecknar prevalensen vid åldern x som prev (x). pˆ prev ˆ = pˆ + pˆ ˆ ˆ ˆ ˆ3 3

16 4.3 Återstående livslängd. Vi börjar med att konstatera att den återstående livslängden består av antalet återstående friska och sjuka år samt att dessa givetvis beror på i fall man är frisk eller sjuk vid tidpunkten som vi vill skatta för. Vi definierar storheterna som: f ( ) = förväntat antal återstående friska år för en frisk x-årig individ. x s ( ) = förväntat antal kommande sjuka år för en frisk x-årig individ. x s ( ) = förväntat antal återstående sjuka år för en sjuk x-årig individ. x Observera att vi givetvis inte heller här tar hänsyn till hur länge en person har befunnit sig i ett tillstånd, i. Antag nu att vi kan skatta f ˆ(95), s ˆ(95) och s ˆ (95). Med hjälp av de skattade övergångssannolikheterna kan vi nu skriva en rekursiv formel för att baklänges få fram återstående livslängd för de tidigare åldrarna. Om en individ är frisk vid x + års ålder har hon varit frisk ett år längre än vid åldern x. Sannolikheten för att en individ som är frisk vid x års ålder ska vara frisk vid x + är p. ˆ Vi får alltså: f ˆ = pˆ ( + fˆ ( x + )) Om en individ är sjuk vid x + års ålder har hon varit sjuk ett år längre än vid åldern x. Sannolikheten för att en individ som är sjuk vid x års ålder ska vara sjuk vid x + är p. ˆ Vi får alltså: s ˆ = pˆ ( + sˆ ( x + )) Motsvarande resonemang förs för s ˆ. Här tas dock hänsyn till att en person vid nästa ålder antingen kan vara fortsatt frisk eller ha övergått till sjuk. Vi får alltså: s ˆ = pˆ ( x) (0 + sˆ ( x + )) + pˆ ( + sˆ ( x + )) Frågan är nu bara, hur ska vi skatta våra startvärden? 4
 = förväntat antal återstående sjuka år för en sjuk x-årig individ. x Observera att vi givetvis inte heller här tar hänsyn till hur länge en person har befunnit sig i ett tillstånd, i.")
17 Vi börjar med att skatta f (95) och sedan kan man på analogt vis skatta s (95) och s (95) 6. Vi kan börja med att konstatera att det finns individer som blir äldre än 95 år och således är f (95) 0. > Vi kan också konstatera att en 95-åring har färre förväntat återstående friska år än en 94-åring, alltså f 95) < (94). ( f Den övre gränsen för f (95) är alltså mindre än värdet vi får om vi sätter f ( 95) = f(94) och om vi sätter in den likheten i formeln för f ( x) får vi p(94) f(94) = p (94) ( + f(94)) f(94) = ( p (94)) Vi vet alltså att: 0 < p(94) f(95) < ( p (94)) och vi sätter då givetvis 0 < ˆ pˆ (94) f(95) < ( pˆ (94)) Ett problem som vi dock ställs inför är att vi inte kan veta exakt hur stor f ˆ(95) ska vara, men under något lämpligt antagande så borde vi ändå kunna komma nära sanningen. 6 Dessa uträkningar finns i appendix A. 5
) Vi vet alltså att: 0 < p(94) f(95) < ( p (94)) och vi sätter då givetvis 0 < ˆ pˆ (94) f(95) < ( pˆ (94)) Ett problem som vi dock ställs inför är att vi inte kan veta exakt hur stor f ˆ(95) ska")
18 Om vi tittar på plotten för återstående friska år så borde den, eftersom p ˆ minskar med tiden, ha en avtagande negativ lutning och gå mot 0. Dock vet ingen idag exakt hur gammal en människa egentligen kan bli och således vet vi ej om det finns eller i så fall vid vilken ålder som det förväntade antal återstående friska åren är 0. För att hantera detta tittar vi på den årliga förändringen, med avseende på ålder, av antalet återstående friska år. Detta kan vi göra med hjälp av att rekursivt ta fram f ˆ dels med hjälp den undre och dels med den övre gränsen av f ˆ(95). Den skattade förändringen är alltså f ˆ ( ) / ˆ x + f( x). Resultatet för de båda gränserna visar vi i en plot där vi till exempel ser att de förväntade återstående friska åren för en 76- åring är strax under 95% av antalet för en 75-åring. Avståndet mellan förändringskurvorna är litet för de lägre åldrarna och förändringen verkar vara linjär där. Detta skulle kunna vara ett lämpligt antagande, men för att förenkla lite skattar vi fˆ(95 ) med ett värde som ger fˆ ˆ (95) f(94) fˆ (94) fˆ (93) Eftersom vi dels inte vet det exakta värdet på f (95) utan snarare är ute efter att komma nära sanningen räcker det gott med att dessa förändringar ligger nära varandra. Dessutom är det inte helt avgörande vilket antagande vi väljer eftersom det kommer att röra sig om ett fåtal dagar mellan det linjära antagandet och det antagande som vi nu gör. 6
. Den skattade förändringen är alltså f ˆ ( ) / ˆ x + f( x).")
19 Med samma antagande för s ˆ(95) och s ˆ (95) som för f ˆ(95) kan vi nu skatta återstående friska och sjuka år för de olika åldrarna. Man skulle kunna tänka sig att man istället gör ett antagande om att det, även för åldrar över 95 år, gäller att αˆ + βˆ x pˆ ( x ) = e, j i < i =, j =, 3 Vi prövar nu att göra det antagandet i stället och för att lagen om total sannolikhet ska 3 gälla säger vi att om p ˆ så gäller att p = pˆ ( ) och om p ˆ3 > j= j > ˆ 3 x så sätter vi att p ˆ3 =. Under detta antagande får vi alltså en ålder där f ˆ = 0 och det värdet kan vi alltså sätta in i vår rekursionsformel och vi skattar på samma sätt som tidigare återstående livslängd uppdelat på friska och sjuka år. 7

20 Om man tittar på plottarna för de två olika antagandena så ser man att de ligger väldigt nära varandra för de höga åldrarna och att de är näst intill identiska för de lägre. Exempel på resultat under det första antagandet är f ˆ (75) = år och f ˆ (95) =.55 år som kan jämföras mot f ˆ (75) = år och f ˆ (95) =. 47 år under det andra antagandet. Vi ser alltså att det inte är helt avgörande vilket antagande vi väljer. Detta verkar rimligt eftersom vi använder samma skattningar på övergångssannolikheterna i de båda fallen. För de högre åldrarna kan det skilja lite, men för de lägre kommer vi att få samma värden. Malin Düring konstaterade i sin rapport att p(94) f(95) <. ( p (94)) Dock sattes där värdet på f ˆ(95) så att det låg så nära f ˆ(94) som möjligt. 8
 f(95) <.")
21 5. Tillämpning, av modellen, på Sverige 5. PIM-modellen Vi vill alltså nu försöka använda denna modell för att göra det möjligt att säga något om antalet dementa kvinnor i Sverige i dag. Vi vill även säga något om hur det kan komma att utvecklas i framtiden. Problemet vi har är att det inte är helt självklart att det går att jämföra Sveriges äldre kvinnor i dag med de i Kungsholmsprojektet. Kungsholmsprojektet sträcker sig lite över ett decennium och under den perioden kan incidensen och mortaliteten ha förändrats och dessutom har det, om man tittar på Sverige i dag, gått ytterligare 7 år sedan projektet avslutades. Vi har också problemet med den geografiska skillnaden mellan Kungsholmen och Sverige. Om man jämför inkomstfördelningen för de två regionerna kan man dock finna stöd för att Kungsholmsprojektet är representativt för Sverige 7. För Sverige har vi data för antalet levande personer i varje åldersgrupp och årtal, således kan vi få ut dödssannolikheterna för dessa 8. Vi tittar på mortaliteten för individer i Sverige mellan 75 och 95 år de senaste 30 åren. Om vi logaritmerar dessa värden så verkar de, för varje år, vara linjära med avseende på åldern. Precis som tidigare jämnar vi ut kurvorna med minsta kvadrat metoden. Nedan har vi som exempel plottat mortaliteten för år För ytterligare läsning se Hallberg D, Lagergren M, Moving in and out of public geriatric care in Sweden, Working Paper 007:, Department of Economics, Uppsala Universitet. 8 Här finns hela datasetet 9
22 Tanken är nu att vi ska titta på den skattade kurvans parametrar och se om de verkar bero på tiden och i så fall hur de förändras. Genom att plotta parametrarna för varje år ser vi att α verkar vara linjär med avseende på tiden och verkar ha en negativ lutning medan β verkar vara linjär med en positiv lutning 9. För det första måste man diskutera i fall det är rimligt att lutningen på β är positiv, eftersom detta medför att kurvorna för mortaliteten, för olika årtal, kommer att skära varandra. Om vi nöjer oss med att inte titta längre än 0-30 år fram i tiden kommer det dock att ske utanför det åldersintervall vi tittar på. Vi tänker oss därför att denna utveckling av parametrarna gäller i intervallet år och vi extrapolerar dessa parameterkurvor för att vi kan få fram mortaliteten för en viss ålder ett visst framtida år. När vi tidigare gjorde vår PIM-modell gjordes den med antagande om att övergångssannolikheterna ej beror på årtal men den mortalitet vi har i Sverige visar att de beror på både ålder och årtal. Vi definierar dödssannolikheten för en godtycklig person vid en viss ålder, x, och ett visst år, t, som p g ) och eftersom vi har skattat de värdena kan vi under vissa 3 t antagande ta fram en formel som ger oss prevalensen för olika åldrar och årtal. Vi börjar med att konstatera att pˆ g t = pˆ ( prev ˆ ) + pˆ prev ˆ ) ( ) och här använder vi oss alltså av samma beteckningar som tidigare, men vi har nu också infört beroendet av årtal. 9 observera här att P g = e α + β x 3 och värdena på x är till 60 dvs x= motsvarar år 976 0
23 Vi har, enligt samma resonemang som i modellen, formlerna p ˆ( x, = pˆ ( x, t ) pˆ ( x, t ) p ˆ = pˆ ( x, t ) pˆ ( x, t ) + pˆ ( x, t ) pˆ ( x, t ) Kom ihåg att vi sätter p ˆ (65, = och följaktligen p ˆ (65, = 0. Om vi nu gör antaganden om hur p ˆ samt p ser ut kan vi således skatta prevalensen för olika åldrar och årtal. För att leda oss i rätt riktning om vilka antaganden vi ska göra kan vi titta på p g. ˆ 3 Observera här att vi för varje steg i rekursionen måste gå tillbaka till ( ) för att lösa ut p. ˆ3 Vi får även ut p och p eftersom ˆ ˆ p + pˆ + pˆ och ˆ 3 = p ˆ ˆ + p3 = Precis som tidigare, fast nu även med beroende på tiden, gäller givetvis att ˆ 3 prev ˆ = pˆ pˆ + pˆ Vi vet hur många personer som i dag finns i varje åldersgrupp och vi har skattat mortaliteten för framtiden så från det kan vi direkt skatta antalet personer i en viss åldersgrupp ett visst framtida år. Med hjälp av den skattade prevalensen kan vi alltså då även skatta antalet dementa kvinnor i varje åldersgrupp vid ett visst framtida årtal.
24 5. Återstående livslängd ˆ 3 Under antaganden för p ˆ samt p kan vi också, precis som tidigare, få ut förväntad återstående livslängd för en viss åldersgrupp ett visst framtida år. Återigen måste vi ta hänsyn till årtal och vi konstaterar att en person som till exempel var 85 år i början på 006 var 84 år i början på 005. Vi får då rekursionsformlerna: f ˆ = pˆ ( + fˆ ( x +, t + )) s ˆ = pˆ ( + sˆ ( x +, t + )) s ˆ = pˆ ( x, (0 + sˆ ( x +, t + )) + pˆ ( + sˆ ( x +, t + )) 5. Antagande om p och p ˆ ˆ 3 För att se skillnad på data för Sverige och för Kungsholmsprojektet börjar vi med att lägga till ett k i index hos data från Kungsholmsprojektet. Vi kan konstatera att vi inte vet hur, eller om, p förändras med tiden. Men vi har p k från Kungsholmsprojektet, som avslutades år 000. Vi börjar därför med ˆ ˆ att anta att p k gäller för år 000 och alla årtal innan det. pˆ k x = pˆ ( ), t 000 För att göra något antagande om åren efter år 000 sätter vi en konstant, c, som representerar en årlig förändring av incidensen. Vi sätter här samma konstant för alla åldrar för att göra modellen enkel. p ˆ ˆ c, t > 000 = pk t 000 ˆ 3 När det gäller p så angriper vi den på samma sätt med en motsvarande konstant c 3. Vilka värden som är rimliga att sätta på konstanterna kan vara svårt att veta eftersom vi inte har någon som helst data för deras förändring med tiden. Mårten Lagergren menar att ett lämpligt antagande är att mortalitetsförändringen för dementa är proportionell mot förändringen för en godtycklig individ och att incidensen är konstant med avseende på tiden.
25 Vi har ju för enkelhetens skull antagit att c 3 är lika för alla åldrar. Dock har vi konstaterat att förändringen av p g ) är beroende av åldern. För att hantera detta 3 t gör vi antagandet att c 3 är lika med medelförändringen, av alla åldrar, för p g 3( x,. 95 p g3 t + ) = 75 p 3 c 3 = x g g, för något t Med våra antaganden om p g ) får vi att mortaliteten för dementa minskar med 3 t.% per år, c = Vi säger också att incidensen är konstant med avseende på tiden, alltså c =. Egentligen innebär antagandet om att mortalitetsförändringen för dementa är proportionellt mot förändringen av friska att vår konstant beror på åldern. Men att sätta en konstant för alla åldrar gör det lättare att tolka modellen och att jämföra olika antaganden om c 3. Det går givetvis här att göra andra antaganden om c och c 3, till exempel för att se hur en eventuell medicin skulle kunna påverka antalet sjuka personer, men vi nöjer oss med dessa. Med dem kan vi beräkna prevalensen, antal sjuka individer och det förväntade antalet återstående friska och sjuka år 0. 0 Här har vi till vänster plottat förväntad prevalens för år 05 och till höger förväntat återstående friska och sjuka år för 007 (undre linjer) samt 05 (övre linjer). Exempel på tabeller över förväntat antal dementa kvinnor finns i appendix B. 3
26 6. Resultat Målet med den här rapporten var att göra en prevalens, incidens och mortalitets modell för Kungsholmsprojektet samt en modell för återstående livslängd uppdelad på friska och sjuka år. Den första modellen gjordes och som resultat fick vi ut en plot som visar den skattade prevalensen för dementa kvinnor i projektet. Från resultatet till den andra modellen kan vi till exempel se att en frisk 75-årig kvinna från datasetet kunde förväntas leva i nästan år till och av dem skulle hon vara dement i ungefär år. Sedan skulle vi tillämpa dessa modeller på Sverige och försöka säga något om framtiden. Om alla övergångssannolikheter vore konstanta med avseende på tiden skulle förmodligen resultaten från kungsholmprojektet kunna tillämpas direkt på Sverige. Men när vi tittade på hur antalet personer i olika åldersgrupper förändrades med tiden konstaterade vi att mortaliteten beror på tiden. Alltså gick inte Kungsholmsprojektet att tillämpa direkt på Sverige. Tyvärr så visste vi inte hur incidensen och mortaliteten för en sjuk individ förändras med tiden utan fick nöja oss med att göra antaganden om dessa. Om mortaliteten minskar kommer kvinnor att leva längre och den förväntade extra livslängden kommer att bestå av både friska och sjuka år. Så länge inte incidensen minskar kommer vi alltså att med tiden få fler och fler dementa kvinnor i Sverige. Här skulle vi ha kunnat göra olika antaganden för att se hur mycket det påverkar resultatet, men vi nöjde oss med att titta på det antagande som Mårten Lagergren ansåg att var mest troligt. I plotten på sid 3 kan vi se vilket resultat våra antaganden får på återstående livslängd. Som exempel jämför vi år 007 och 05 och vi ser att den förväntade återstående livslängden ökar med både friska och sjuka år. I tabell i Appendix B kan vi se det förväntade antalet dementa kvinnor vid åren 007 och 05. Med en minskad mortalitet kommer vi på sikt att få fler kvinnor och därför även fler dementa kvinnor. För att få fram riktigt bra resultat skulle vi helst vilja ha ett dataset som innehåller antal personer i varje åldersgrupp, för varje år, och som även är uppdelat på friska och dementa personer. Med ett sådant dataset skulle man kunna titta på hur incidensen och mortaliteten har förändrats de senaste åren och sedan göra antaganden om framtiden på samma sätt som vi har gjort med p g ). 3 t 4
27 7. Appendix A, Formler Beräkning av förväntad återstående livstid för en dement. Förväntade antalet sjuka år givet att man är sjuk är större än 0, s ˆ (95) > 0 Sambandet pˆ (94) sˆ (94) = får vi genom att sätta s ˆ ˆ (95) = s (94) ( pˆ (94)) men vi vet ju att s 95) < (94) så alltså får vi ( s pˆ (94) 0 < sˆ (95) < ( pˆ (94)) och vi skattar s (95) genom att sätta dess värde så att sˆ (95) sˆ (94) sˆ (94) sˆ (93) Beräkning av förväntat antal återstående dementa år för en frisk. Förväntade antalet sjuka år givet att man är frisk är större än 0, s ˆ (95) > 0 Om vi skulle sätta s (95) = ˆ (94) så skulle vi få ˆ s sˆ (94) = pˆ (94) (0 + sˆ (94)) + pˆ (94) ( + sˆ (95)) sˆ (94) = pˆ (94) ( + sˆ (95)) pˆ (94) men vi vet ju att s 95) < (94) och alltså gäller ( s 0 < sˆ (95) < pˆ (94) ( + sˆ (95)) pˆ (94) och skattar s (95) genom att sätta dess värde så att sˆ (95) sˆ (94) sˆ (94) sˆ (93) 5
28 9. Appendix B, Tabeller Tabell : Förväntade antalet dementa kvinnor i åldrarna år. ÅR 007 ÅR 05 Ålder Antal Sjuka Antal Personer Antal Sjuka Antal Personer , , , , Totalt Tabell : Återstående friska respektive sjuka år. År 05 Ålder Friska år givet frisk Sjuka år givet frisk Totala år givet frisk Sjuka år givet sjuk 75,9 3,48 4,76 8, ,67 3,37 4,03 8,5 77 0,05 3,5 3,30 7, ,44 3,4,58 7,6 79 8,84 3,0,86 7,3 80 8,5,90,5 7,0 8 7,67,77 0,45 6,74 8 7,,65 9,76 6, ,55,5 9,08 6,9 84 6,0,40 8,4 5, ,48,7 7,75 5, ,97,4 7, 5, ,48,0 6,49 5,0 88 4,00,89 5,89 4, ,54,77 5,3 4, ,0,65 4,75 4,53 9,68,54 4, 4,33 9,8,44 3,7 4,3 93,9,36 3,7 3,95 94,58,3,89 3,77 95,30,6,56 3,60 6
29 Tabell 3: Återstående friska och sjuka år för en godtycklig individ. År 05 Ålder Friska år Sjuka år Totala år 75 9,85 4,3 3, ,6 4,06 3, 77 8,49 3,98, ,85 3,89, ,3 3,80, ,64 3,7 0,34 8 6,06 3,6 9,67 8 5,5 3,50 9,0 83 4,99 3,40 8, ,49 3,9 7, ,0 3,9 7,9 86 3,55 3,08 6, ,,98 6,0 88,7,88 5,59 89,33,79 5, 90,97,70 4,67 9,64,63 4,6 9,33,57 3,89 93,05,53 3, ,80,5 3,3 95 0,60,5 3, 7
30 0. Referenser Mer information om Äldrecentrum finns på Qvarnström S, Modellering av prevalens som resultat av incidens och mortalitet, Examensarbete 006:4, Matematisk statistik, Stockholms Universitet Düring M, Kommer en längre livslängd att innebära fler friska år?, Examensarbete 006:9, Matematisk statistik, Stockholms Universitet Mer fakta om Kungsholmsprojektet finns på Läs mer om demens på Hallberg D, Lagergren M, Moving in and out of public geriatric care in Sweden, Working Paper 007:, Department of Economics, Uppsala Universitet. Här finns hela datasetet med Sverieges befolkningsmängd i olika åldrar 8
Att mäta hälsa och sjukdom. Kvantitativa metoder II: teori och tillämpning Folkhälsovetenskap 4, termin 6 Hanna Hultin hanna.hultin@ki.
 Att mäta hälsa och sjukdom Kvantitativa metoder II: teori och tillämpning Folkhälsovetenskap 4, termin 6 Hanna Hultin hanna.hultin@ki.se Disposition Introduktion Vad är epidemiologi? Varför behövs epidemiologin?
Att mäta hälsa och sjukdom Kvantitativa metoder II: teori och tillämpning Folkhälsovetenskap 4, termin 6 Hanna Hultin hanna.hultin@ki.se Disposition Introduktion Vad är epidemiologi? Varför behövs epidemiologin?
Hur länge ska fisken vara i dammen?
 Hur länge ska fisken vara i dammen? Frågeställning Uppgift 10 fiskodling Uppgiften går ut på att ta reda på hur länge ett stim fisk ska växa upp i en fiskodling för att få den maximala vikten tillsammans.
Hur länge ska fisken vara i dammen? Frågeställning Uppgift 10 fiskodling Uppgiften går ut på att ta reda på hur länge ett stim fisk ska växa upp i en fiskodling för att få den maximala vikten tillsammans.
Optimering av depåpositioner för den minimala bensinförbrukningen i öknen
 Optimering av depåpositioner för den minimala bensinförbrukningen i öknen Frågeställning: En jeep kan sammanlagt ha 200 liter bensin i tanken samt i lösa dunkar. Jeepen kommer 2,5 km på 1 liter bensin.
Optimering av depåpositioner för den minimala bensinförbrukningen i öknen Frågeställning: En jeep kan sammanlagt ha 200 liter bensin i tanken samt i lösa dunkar. Jeepen kommer 2,5 km på 1 liter bensin.
STATISTIKUNDERLAG för befolkningsprognoser
 STATISTIKUNDERLAG för befolkningsprognoser Statistiska centralbyrån (SCB) är en statlig myndighet. Vår uppgift är att framställa och sprida statistik till bland andra beslutsfattare, forskare och allmänhet.
STATISTIKUNDERLAG för befolkningsprognoser Statistiska centralbyrån (SCB) är en statlig myndighet. Vår uppgift är att framställa och sprida statistik till bland andra beslutsfattare, forskare och allmänhet.
Lektionsanteckningar 11-12: Normalfördelningen
 Lektionsanteckningar 11-12: Normalfördelningen När utfallsrummet för en slumpvariabel kan anta vilket värde som helst i ett givet intervall är variabeln kontinuerlig. Det är väsentligt att utfallsrummet
Lektionsanteckningar 11-12: Normalfördelningen När utfallsrummet för en slumpvariabel kan anta vilket värde som helst i ett givet intervall är variabeln kontinuerlig. Det är väsentligt att utfallsrummet
Postadress: Internet: Matematisk statistik Matematiska institutionen Stockholms universitet Stockholm Sverige.
 "!# " $ %'&)(+*,*-(+.0/,132 465 7+. (8594)*-(+1;: : %=:@?A*CBD46B 465 /E13FG/&)(+1;: %'F9H < %).IBD4)*J/CB (8B KMLONP=Q;RSPUTWVXEYIT[Z]\ ^`_a4)< (+1;:b49."cd(8B ( egfgfdhjik Postadress: Matematisk
"!# " $ %'&)(+*,*-(+.0/,132 465 7+. (8594)*-(+1;: : %=:@?A*CBD46B 465 /E13FG/&)(+1;: %'F9H < %).IBD4)*J/CB (8B KMLONP=Q;RSPUTWVXEYIT[Z]\ ^`_a4)< (+1;:b49."cd(8B ( egfgfdhjik Postadress: Matematisk
Postadress: Internet: Matematisk statistik Matematiska institutionen Stockholms universitet Stockholm Sverige.
 "!# " $&%(' ' )+* )+, -./,102* ) -4365879-./,10;: =?= 3@,A,1)+BC.C*D< E()+* FG*H367JI< K+*ML NPO"QSRUTWV8X"YZR[T\ ]_^`
"!# " $&%(' ' )+* )+, -./,102* ) -4365879-./,10;: =?= 3@,A,1)+BC.C*D< E()+* FG*H367JI< K+*ML NPO"QSRUTWV8X"YZR[T\ ]_^`
F13 Regression och problemlösning
 1/18 F13 Regression och problemlösning Måns Thulin Uppsala universitet thulin@math.uu.se Statistik för ingenjörer 4/3 2013 2/18 Regression Vi studerar hur en variabel y beror på en variabel x. Vår modell
1/18 F13 Regression och problemlösning Måns Thulin Uppsala universitet thulin@math.uu.se Statistik för ingenjörer 4/3 2013 2/18 Regression Vi studerar hur en variabel y beror på en variabel x. Vår modell
Tentamen för kursen. Linjära statistiska modeller. 16 augusti 2007 9 14
 STOCKHOLMS UNIVERSITET MATEMATISK STATISTIK Tentamen för kursen Linjära statistiska modeller 16 augusti 2007 9 14 Examinator: Anders Björkström, tel. 16 45 54, bjorks@math.su.se Återlämning: Rum 312, hus
STOCKHOLMS UNIVERSITET MATEMATISK STATISTIK Tentamen för kursen Linjära statistiska modeller 16 augusti 2007 9 14 Examinator: Anders Björkström, tel. 16 45 54, bjorks@math.su.se Återlämning: Rum 312, hus
Logistisk regression och Indexteori. Patrik Zetterberg. 7 januari 2013
 Föreläsning 9 Logistisk regression och Indexteori Patrik Zetterberg 7 januari 2013 1 / 33 Logistisk regression I logistisk regression har vi en binär (kategorisk) responsvariabel Y i som vanligen kodas
Föreläsning 9 Logistisk regression och Indexteori Patrik Zetterberg 7 januari 2013 1 / 33 Logistisk regression I logistisk regression har vi en binär (kategorisk) responsvariabel Y i som vanligen kodas
TAMS65 - Seminarium 4 Regressionsanalys
 TAMS65 - Seminarium 4 Regressionsanalys Martin Singull Matematisk statistik Matematiska institutionen Problem 1 PS29 Vid ett test av bromsarna på en bil bromsades bilen upprepade gånger från en hastighet
TAMS65 - Seminarium 4 Regressionsanalys Martin Singull Matematisk statistik Matematiska institutionen Problem 1 PS29 Vid ett test av bromsarna på en bil bromsades bilen upprepade gånger från en hastighet
Föreläsning G60 Statistiska metoder
 Föreläsning 3 Statistiska metoder 1 Dagens föreläsning o Samband mellan två kvantitativa variabler Matematiska samband Statistiska samband o Korrelation Svaga och starka samband När beräkna korrelation?
Föreläsning 3 Statistiska metoder 1 Dagens föreläsning o Samband mellan två kvantitativa variabler Matematiska samband Statistiska samband o Korrelation Svaga och starka samband När beräkna korrelation?
Datorövning 5 Exponentiella modeller och elasticitetssamband
 Datorövning 5 Exponentiella modeller och elasticitetssamband Datorövningen utförs i grupper om två personer. I denna datorövning skall ni använda Minitab för att 1. anpassa och tolka analysen av en exponentiell
Datorövning 5 Exponentiella modeller och elasticitetssamband Datorövningen utförs i grupper om två personer. I denna datorövning skall ni använda Minitab för att 1. anpassa och tolka analysen av en exponentiell
Övningshäfte 2: Induktion och rekursion
 GÖTEBORGS UNIVERSITET MATEMATIK 1, MMG200, HT2017 INLEDANDE ALGEBRA Övningshäfte 2: Induktion och rekursion Övning D Syftet är att öva förmågan att utgående från enkla samband, aritmetiska och geometriska,
GÖTEBORGS UNIVERSITET MATEMATIK 1, MMG200, HT2017 INLEDANDE ALGEBRA Övningshäfte 2: Induktion och rekursion Övning D Syftet är att öva förmågan att utgående från enkla samband, aritmetiska och geometriska,
Handisam. Beräkningsunderlag för undersökningspanel
 Beräkningsunderlag för undersökningspanel Kund Mottagare Ann Dahlberg Författare Johan Bring Granskare Gösta Forsman STATISTICON AB Östra Ågatan 31 753 22 UPPSALA Wallingatan 38 111 24 STOCKHOLM vxl: 08-402
Beräkningsunderlag för undersökningspanel Kund Mottagare Ann Dahlberg Författare Johan Bring Granskare Gösta Forsman STATISTICON AB Östra Ågatan 31 753 22 UPPSALA Wallingatan 38 111 24 STOCKHOLM vxl: 08-402
F12 Regression. Måns Thulin. Uppsala universitet Statistik för ingenjörer 28/ /24
 1/24 F12 Regression Måns Thulin Uppsala universitet thulin@math.uu.se Statistik för ingenjörer 28/2 2013 2/24 Dagens föreläsning Linjära regressionsmodeller Stokastisk modell Linjeanpassning och skattningar
1/24 F12 Regression Måns Thulin Uppsala universitet thulin@math.uu.se Statistik för ingenjörer 28/2 2013 2/24 Dagens föreläsning Linjära regressionsmodeller Stokastisk modell Linjeanpassning och skattningar
Bilaga 1. Kvantitativ analys
 bilaga till granskningsrapport dnr: 31-2013-0200 rir 2014:11 Bilaga 1. Kvantitativ analys Att tillvarata och utveckla nyanländas kompetens rätt insats i rätt tid? (RiR 2014:11) Bilaga 1 Kvantitativ analys
bilaga till granskningsrapport dnr: 31-2013-0200 rir 2014:11 Bilaga 1. Kvantitativ analys Att tillvarata och utveckla nyanländas kompetens rätt insats i rätt tid? (RiR 2014:11) Bilaga 1 Kvantitativ analys
Olle Johansson, docent Enheten för Experimentell Dermatologi, Institutionen för Neurovetenskap, Karolinska Institutet, S-171 77 Stockholm
 En dödlig utveckling Örjan Hallberg, civ.ing. Polkavägen 14B, 142 65 Trångsund Olle Johansson, docent Enheten för Experimentell Dermatologi, Institutionen för Neurovetenskap, Karolinska Institutet, S-171
En dödlig utveckling Örjan Hallberg, civ.ing. Polkavägen 14B, 142 65 Trångsund Olle Johansson, docent Enheten för Experimentell Dermatologi, Institutionen för Neurovetenskap, Karolinska Institutet, S-171
Laboration 4: Stora talens lag, Centrala gränsvärdessatsen och enkla punktskattningar
 LUNDS TEKNISKA HÖGSKOLA MATEMATIKCENTRUM MATEMATISK STATISTIK DATORLABORATION 4 MATEMATISK STATISTIK, FÖR I/PI, FMS 121/2, HT-3 Laboration 4: Stora talens lag, Centrala gränsvärdessatsen och enkla punktskattningar
LUNDS TEKNISKA HÖGSKOLA MATEMATIKCENTRUM MATEMATISK STATISTIK DATORLABORATION 4 MATEMATISK STATISTIK, FÖR I/PI, FMS 121/2, HT-3 Laboration 4: Stora talens lag, Centrala gränsvärdessatsen och enkla punktskattningar
1, 2, 3, 4, 5, 6,...
 Dagens nyhet handlar om talföljder, ändliga och oändliga. Talföljden 1,, 3, 4, 5, 6,... är det första vi, som barn, lär oss om matematik över huvud taget. Så småningom lär vi oss att denna talföljd inte
Dagens nyhet handlar om talföljder, ändliga och oändliga. Talföljden 1,, 3, 4, 5, 6,... är det första vi, som barn, lär oss om matematik över huvud taget. Så småningom lär vi oss att denna talföljd inte
Delrapport för projektet Granbarkborrens förökningsframgång 2010
 Bilaga 1 Uppsala 2010-08-2 Martin Schroeder Inst Ekologi SLU Delrapport för projektet Granbarkborrens förökningsframgång 2010 Under sommaren har granbarkborrens aktivitet följts upp i fem av de skyddade
Bilaga 1 Uppsala 2010-08-2 Martin Schroeder Inst Ekologi SLU Delrapport för projektet Granbarkborrens förökningsframgång 2010 Under sommaren har granbarkborrens aktivitet följts upp i fem av de skyddade
Upprepade mätningar och tidsberoende analyser. Stefan Franzén Statistiker Registercentrum Västra Götaland
 Upprepade mätningar och tidsberoende analyser Stefan Franzén Statistiker Registercentrum Västra Götaland Innehåll Stort område Simpsons paradox En mätning per individ Flera mätningar per individ Flera
Upprepade mätningar och tidsberoende analyser Stefan Franzén Statistiker Registercentrum Västra Götaland Innehåll Stort område Simpsons paradox En mätning per individ Flera mätningar per individ Flera
Tillämpad statistik (A5), HT15 Föreläsning 24: Tidsserieanalys III
, HT15 Föreläsning 24: Tidsserieanalys III") Tillämpad statistik (A5), HT15 Föreläsning 24: Tidsserieanalys III Sebastian Andersson Statistiska institutionen Senast uppdaterad: 16 december 2015 är en prognosmetod vi kan använda för serier med en
Tillämpad statistik (A5), HT15 Föreläsning 24: Tidsserieanalys III Sebastian Andersson Statistiska institutionen Senast uppdaterad: 16 december 2015 är en prognosmetod vi kan använda för serier med en
Introduktion till statistik för statsvetare
 "Det finns inget så praktiskt som en bra teori" September 2011 Inledning Introduktion till demografi Inledning Demografer (befolkningsanalytiker) studerar befolkningens sammansättning och dess förändringar.
"Det finns inget så praktiskt som en bra teori" September 2011 Inledning Introduktion till demografi Inledning Demografer (befolkningsanalytiker) studerar befolkningens sammansättning och dess förändringar.
Lennart Carleson. KTH och Uppsala universitet
 46 Om +x Lennart Carleson KTH och Uppsala universitet Vi börjar med att försöka uppskatta ovanstående integral, som vi kallar I, numeriskt. Vi delar in intervallet (, ) i n lika delar med delningspunkterna
46 Om +x Lennart Carleson KTH och Uppsala universitet Vi börjar med att försöka uppskatta ovanstående integral, som vi kallar I, numeriskt. Vi delar in intervallet (, ) i n lika delar med delningspunkterna
STOCKHOLMS UNIVERSITET MATEMATISKA INSTITUTIONEN Avd. Matematisk statistik, GA 08 januari 2015. Lösningar
 STOCKHOLMS UNIVERSITET MT712 MATEMATISKA INSTITUTIONEN LÖSNINGAR Avd. Matematisk statistik, GA 8 januari 215 Lösningar Tentamen i Livförsäkringsmatematik I, 8 januari 215 Uppgift 1 a) Först konstaterar
STOCKHOLMS UNIVERSITET MT712 MATEMATISKA INSTITUTIONEN LÖSNINGAR Avd. Matematisk statistik, GA 8 januari 215 Lösningar Tentamen i Livförsäkringsmatematik I, 8 januari 215 Uppgift 1 a) Först konstaterar
SVANTE JANSON OCH SVANTE LINUSSON
 EXEMPEL PÅ BERÄKNINGAR AV SANNOLIKHETER FÖR ATT FELAKTIGT HANTERADE RÖSTER PÅVERKAR VALUTGÅNGEN SVANTE JANSON OCH SVANTE LINUSSON 1. Inledning Vi skall här ge exempel på och försöka förklara matematiken
EXEMPEL PÅ BERÄKNINGAR AV SANNOLIKHETER FÖR ATT FELAKTIGT HANTERADE RÖSTER PÅVERKAR VALUTGÅNGEN SVANTE JANSON OCH SVANTE LINUSSON 1. Inledning Vi skall här ge exempel på och försöka förklara matematiken
Graärgning och kromatiska formler
 Graärgning och kromatiska formler Henrik Bäärnhielm, d98-hba 2 mars 2000 Sammanfattning I denna uppsats beskrivs, för en ickematematiker, färgning av grafer samt kromatiska formler för grafer. Det hela
Graärgning och kromatiska formler Henrik Bäärnhielm, d98-hba 2 mars 2000 Sammanfattning I denna uppsats beskrivs, för en ickematematiker, färgning av grafer samt kromatiska formler för grafer. Det hela
Säsongrensning i tidsserier.
 Senast ändrad 200-03-23. Säsongrensning i tidsserier. Kompletterande text till kapitel.5 i Tamhane och Dunlop. Inledning. Syftet med säsongrensning är att dela upp en tidsserie i en trend u t, en säsongkomponent
Senast ändrad 200-03-23. Säsongrensning i tidsserier. Kompletterande text till kapitel.5 i Tamhane och Dunlop. Inledning. Syftet med säsongrensning är att dela upp en tidsserie i en trend u t, en säsongkomponent
Provmoment: Tentamen 6,5 hp Ladokkod: A144TG Tentamen ges för: TGMAI17h, Maskiningenjör - Produktutveckling. Tentamensdatum: 28 maj 2018 Tid: 9-13
 Matematisk Statistik 7,5 högskolepoäng Provmoment: Tentamen 6,5 hp Ladokkod: A144TG Tentamen ges för: TGMAI17h, Maskiningenjör - Produktutveckling Tentamensdatum: 28 maj 2018 Tid: 9-13 Hjälpmedel: Miniräknare
Matematisk Statistik 7,5 högskolepoäng Provmoment: Tentamen 6,5 hp Ladokkod: A144TG Tentamen ges för: TGMAI17h, Maskiningenjör - Produktutveckling Tentamensdatum: 28 maj 2018 Tid: 9-13 Hjälpmedel: Miniräknare
Kapitel 4: SAMBANDET MELLAN VARIABLER: REGRESSIONSLINJEN
 Kapitel 4: SAMBANDET MELLAN VARIABLER: REGRESSIONSLINJEN Spridningsdiagrammen nedan representerar samma korrelationskoefficient, r = 0,8. 80 80 60 60 40 40 20 20 0 0 20 40 0 0 20 40 Det finns dock två
Kapitel 4: SAMBANDET MELLAN VARIABLER: REGRESSIONSLINJEN Spridningsdiagrammen nedan representerar samma korrelationskoefficient, r = 0,8. 80 80 60 60 40 40 20 20 0 0 20 40 0 0 20 40 Det finns dock två
MVE051/MSG Föreläsning 7
 MVE051/MSG810 2016 Föreläsning 7 Petter Mostad Chalmers November 23, 2016 Överblick Deskriptiv statistik Grafiska sammanfattningar. Numeriska sammanfattningar. Estimering (skattning) Teori Några exempel
MVE051/MSG810 2016 Föreläsning 7 Petter Mostad Chalmers November 23, 2016 Överblick Deskriptiv statistik Grafiska sammanfattningar. Numeriska sammanfattningar. Estimering (skattning) Teori Några exempel
1/31 REGRESSIONSANALYS. Statistiska institutionen, Stockholms universitet
 1/31 REGRESSIONSANALYS F1 Linda Wänström Statistiska institutionen, Stockholms universitet 2/31 Kap 4: Introduktion till regressionsanalys. Introduktion Regressionsanalys är en statistisk teknik för att
1/31 REGRESSIONSANALYS F1 Linda Wänström Statistiska institutionen, Stockholms universitet 2/31 Kap 4: Introduktion till regressionsanalys. Introduktion Regressionsanalys är en statistisk teknik för att
8-1 Formler och uttryck. Namn:.
 8-1 Formler och uttryck. Namn:. Inledning Ibland vill du lösa lite mer komplexa problem. Till exempel: Kalle är dubbelt så gammal som Stina, och tillsammans är de 33 år. Hur gammal är Kalle och Stina?
8-1 Formler och uttryck. Namn:. Inledning Ibland vill du lösa lite mer komplexa problem. Till exempel: Kalle är dubbelt så gammal som Stina, och tillsammans är de 33 år. Hur gammal är Kalle och Stina?
Föreläsning 12: Regression
 Föreläsning 12: Regression Matematisk statistik David Bolin Chalmers University of Technology Maj 15, 2014 Binomialfördelningen Låt X Bin(n, p). Vi observerar x och vill ha information om p. p = x/n är
Föreläsning 12: Regression Matematisk statistik David Bolin Chalmers University of Technology Maj 15, 2014 Binomialfördelningen Låt X Bin(n, p). Vi observerar x och vill ha information om p. p = x/n är
Vad Betyder måtten MAPE, MAD och MSD?
 Vad Betyder måtten MAPE, MAD och MSD? Alla tre är mått på hur bra anpassningen är och kan användas för att jämföra olika modeller. Den modell som har lägst MAPE, MAD och/eller MSD har bäst anpassning.
Vad Betyder måtten MAPE, MAD och MSD? Alla tre är mått på hur bra anpassningen är och kan användas för att jämföra olika modeller. Den modell som har lägst MAPE, MAD och/eller MSD har bäst anpassning.
Föreläsning 4. NDAB01 Statistik; teori och tillämpning i biologi
 Föreläsning 4 Statistik; teori och tillämpning i biologi 1 Dagens föreläsning o Icke-parametriska test Mann-Whitneys test (kap 8.10 8.11) Wilcoxons test (kap 9.5) o Transformationer (kap 13) o Ev. Andelar
Föreläsning 4 Statistik; teori och tillämpning i biologi 1 Dagens föreläsning o Icke-parametriska test Mann-Whitneys test (kap 8.10 8.11) Wilcoxons test (kap 9.5) o Transformationer (kap 13) o Ev. Andelar
F2 Introduktion. Sannolikheter Standardavvikelse Normalapproximation Sammanfattning Minitab. F2 Introduktion
 Gnuer i skyddade/oskyddade områden, binära utfall och binomialfördelningar Matematik och statistik för biologer, 10 hp Fredrik Jonsson Januari 2012 I vissa områden i Afrika har man observerat att förekomsten
Gnuer i skyddade/oskyddade områden, binära utfall och binomialfördelningar Matematik och statistik för biologer, 10 hp Fredrik Jonsson Januari 2012 I vissa områden i Afrika har man observerat att förekomsten
Statistik 1 för biologer, logopeder och psykologer
 Innehåll 1 Korrelation och regression Innehåll 1 Korrelation och regression Spridningsdiagram Då ett datamaterial består av två (eller era) variabler är man ofta intresserad av att veta om det nns ett
Innehåll 1 Korrelation och regression Innehåll 1 Korrelation och regression Spridningsdiagram Då ett datamaterial består av två (eller era) variabler är man ofta intresserad av att veta om det nns ett
Block 2 Algebra och Diskret Matematik A. Följder, strängar och tal. Referenser. Inledning. 1. Följder
 Block 2 Algebra och Diskret Matematik A BLOCK INNEHÅLL Referenser Inledning 1. Följder 2. Rekursiva definitioner 3. Sigmanotation för summor 4. Strängar 5. Tal 6. Övningsuppgifter Referenser Följder, strängar
Block 2 Algebra och Diskret Matematik A BLOCK INNEHÅLL Referenser Inledning 1. Följder 2. Rekursiva definitioner 3. Sigmanotation för summor 4. Strängar 5. Tal 6. Övningsuppgifter Referenser Följder, strängar
NATIONELLT KURSPROV I MATEMATIK KURS D HÖSTEN Del I, 9 uppgifter utan miniräknare 3. Del II, 8 uppgifter med miniräknare 6
 freeleaks NpMaD ht2007 för Ma4 1(10) Innehåll Förord 1 NATIONELLT KURSPROV I MATEMATIK KURS D HÖSTEN 2007 2 Del I, 9 uppgifter utan miniräknare 3 Del II, 8 uppgifter med miniräknare 6 Förord Kom ihåg Matematik
freeleaks NpMaD ht2007 för Ma4 1(10) Innehåll Förord 1 NATIONELLT KURSPROV I MATEMATIK KURS D HÖSTEN 2007 2 Del I, 9 uppgifter utan miniräknare 3 Del II, 8 uppgifter med miniräknare 6 Förord Kom ihåg Matematik
SF1905 Sannolikhetsteori och statistik: Lab 2 ht 2011
 Avd. Matematisk statistik Tobias Rydén 2011-09-30 SF1905 Sannolikhetsteori och statistik: Lab 2 ht 2011 Förberedelser. Innan du går till laborationen, läs igenom den här handledningen. Repetera också i
Avd. Matematisk statistik Tobias Rydén 2011-09-30 SF1905 Sannolikhetsteori och statistik: Lab 2 ht 2011 Förberedelser. Innan du går till laborationen, läs igenom den här handledningen. Repetera också i
Del I: Digitala verktyg är inte tillåtna. Endast svar krävs. Skriv dina svar direkt i provhäftet.
 Del I: Digitala verktyg är inte tillåtna. Endast svar krävs. Skriv dina svar direkt i provhäftet. 1) a) Bestäm ekvationen för den räta linjen i figuren. (1/0/0) b) Rita i koordinatsystemet en rät linje
Del I: Digitala verktyg är inte tillåtna. Endast svar krävs. Skriv dina svar direkt i provhäftet. 1) a) Bestäm ekvationen för den räta linjen i figuren. (1/0/0) b) Rita i koordinatsystemet en rät linje
Föreläsning 8. NDAB02 Statistik; teori och tillämpning i biologi
 Föreläsning 8 Statistik; teori och tillämpning i biologi 1 Dagens föreläsning o Enkel linjär regression (kap 17.1 17.5) o Skatta regressionslinje (kap 17.2) o Signifikant lutning? (kap 17.3, 17.5a) o Förklaringsgrad
Föreläsning 8 Statistik; teori och tillämpning i biologi 1 Dagens föreläsning o Enkel linjär regression (kap 17.1 17.5) o Skatta regressionslinje (kap 17.2) o Signifikant lutning? (kap 17.3, 17.5a) o Förklaringsgrad
LÖSNINGSFÖRSLAG TILL TENTAMEN I MATEMATISK STATISTIK 2007-08-29
 UMEÅ UNIVERSITET Institutionen för matematik och matematisk statistik Statistik för Teknologer, 5 poäng (TNK, ET, BTG) Peter Anton, Per Arnqvist Anton Grafström TENTAMEN 7-8-9 LÖSNINGSFÖRSLAG TILL TENTAMEN
UMEÅ UNIVERSITET Institutionen för matematik och matematisk statistik Statistik för Teknologer, 5 poäng (TNK, ET, BTG) Peter Anton, Per Arnqvist Anton Grafström TENTAMEN 7-8-9 LÖSNINGSFÖRSLAG TILL TENTAMEN
Härledning av Black-Littermans formel mha allmänna linjära modellen
 Härledning av Black-Littermans formel mha allmänna linjära modellen Ett sätt att få fram Black-Littermans formel är att formulera problemet att hitta lämpliga justerade avkastningar som ett skattningsproblem
Härledning av Black-Littermans formel mha allmänna linjära modellen Ett sätt att få fram Black-Littermans formel är att formulera problemet att hitta lämpliga justerade avkastningar som ett skattningsproblem
Grundläggande matematisk statistik
 Grundläggande matematisk statistik Linjär Regression Uwe Menzel, 2018 uwe.menzel@slu.se; uwe.menzel@matstat.de www.matstat.de Linjär Regression y i y 5 y 3 mätvärden x i, y i y 1 x 1 x 2 x 3 x 4 x 6 x
Grundläggande matematisk statistik Linjär Regression Uwe Menzel, 2018 uwe.menzel@slu.se; uwe.menzel@matstat.de www.matstat.de Linjär Regression y i y 5 y 3 mätvärden x i, y i y 1 x 1 x 2 x 3 x 4 x 6 x
732G71 Statistik B. Föreläsning 8. Bertil Wegmann. IDA, Linköpings universitet. Bertil Wegmann (IDA, LiU) 732G71, Statistik B 1 / 23
 732G71, Statistik B 1 / 23") 732G71 Statistik B Föreläsning 8 Bertil Wegmann IDA, Linköpings universitet Bertil Wegmann (IDA, LiU) 732G71, Statistik B 1 / 23 Klassisk komponentuppdelning Klassisk komponentuppdelning bygger på en intuitiv
732G71 Statistik B Föreläsning 8 Bertil Wegmann IDA, Linköpings universitet Bertil Wegmann (IDA, LiU) 732G71, Statistik B 1 / 23 Klassisk komponentuppdelning Klassisk komponentuppdelning bygger på en intuitiv
Sänkningen av parasitnivåerna i blodet
 4.1 Oberoende (x-axeln) Kön Kön Längd Ålder Dos Dos C max Parasitnivå i blodet Beroende (y-axeln) Längd Vikt Vikt Vikt C max Sänkningen av parasitnivåerna i blodet Sänkningen av parasitnivåerna i blodet
4.1 Oberoende (x-axeln) Kön Kön Längd Ålder Dos Dos C max Parasitnivå i blodet Beroende (y-axeln) Längd Vikt Vikt Vikt C max Sänkningen av parasitnivåerna i blodet Sänkningen av parasitnivåerna i blodet
Kapitel 15: INTERAKTIONER, STANDARDISERADE SKALOR OCH ICKE-LINJÄRA EFFEKTER
 Kapitel 15: INTERAKTIONER, STANDARDISERADE SKALOR OCH ICKE-LINJÄRA EFFEKTER När vi mäter en effekt i data så vill vi ofta se om denna skiljer sig mellan olika delgrupper. Vi kanske testar effekten av ett
Kapitel 15: INTERAKTIONER, STANDARDISERADE SKALOR OCH ICKE-LINJÄRA EFFEKTER När vi mäter en effekt i data så vill vi ofta se om denna skiljer sig mellan olika delgrupper. Vi kanske testar effekten av ett
Statistik B Regressions- och tidsserieanalys Föreläsning 1
 Statistik B Regressions- och tidsserieanalys Föreläsning Kurskod: 732G7, 8 hp Lärare och examinator: Ann-Charlotte (Lotta) Hallberg Lärare och lektionsledare: Isak Hietala Labassistenter Kap 3,-3,6. Läs
Statistik B Regressions- och tidsserieanalys Föreläsning Kurskod: 732G7, 8 hp Lärare och examinator: Ann-Charlotte (Lotta) Hallberg Lärare och lektionsledare: Isak Hietala Labassistenter Kap 3,-3,6. Läs
Finansiell Statistik (GN, 7,5 hp,, HT 2008) Föreläsning 3
 Föreläsning 3") Finansiell Statistik (GN, 7,5 hp,, HT 2008) Föreläsning 3 Kontinuerliga sannolikhetsfördelningar (LLL Kap 7 & 9) Department of Statistics (Gebrenegus Ghilagaber, PhD, Associate Professor) Financial Statistics
Finansiell Statistik (GN, 7,5 hp,, HT 2008) Föreläsning 3 Kontinuerliga sannolikhetsfördelningar (LLL Kap 7 & 9) Department of Statistics (Gebrenegus Ghilagaber, PhD, Associate Professor) Financial Statistics
b) Beräkna sannolikheten för att en person med språkcentrum i vänster hjärnhalva är vänsterhänt. (5 p)
 Beräkna sannolikheten för att en person med språkcentrum i vänster hjärnhalva är vänsterhänt. (5 p)") Avd. Matematisk statistik TENTAMEN I SF1922/SF1923/SF1924 SANNOLIKHETSTEORI OCH STATISTIK, MÅNDAGEN DEN 13:E AUGUSTI 2018 KL 8.00 13.00. Examinator för SF1922/SF1923: Tatjana Pavlenko, 08-790 84 66 Examinator
Avd. Matematisk statistik TENTAMEN I SF1922/SF1923/SF1924 SANNOLIKHETSTEORI OCH STATISTIK, MÅNDAGEN DEN 13:E AUGUSTI 2018 KL 8.00 13.00. Examinator för SF1922/SF1923: Tatjana Pavlenko, 08-790 84 66 Examinator
Laboration 5: Regressionsanalys. 1 Förberedelseuppgifter. 2 Enkel linjär regression DATORLABORATION 5 MATEMATISK STATISTIK FÖR I, FMS 012, HT-08
 LUNDS TEKNISKA HÖGSKOLA MATEMATIKCENTRUM MATEMATISK STATISTIK Laboration 5: Regressionsanalys DATORLABORATION 5 MATEMATISK STATISTIK FÖR I, FMS 012, HT-08 Syftet med den här laborationen är att du skall
LUNDS TEKNISKA HÖGSKOLA MATEMATIKCENTRUM MATEMATISK STATISTIK Laboration 5: Regressionsanalys DATORLABORATION 5 MATEMATISK STATISTIK FÖR I, FMS 012, HT-08 Syftet med den här laborationen är att du skall
Matematisk statistik kompletterande projekt, FMSF25 Övning om regression
 Lunds tekniska högskola, Matematikcentrum, Matematisk statistik Matematisk statistik kompletterande projekt, FMSF Övning om regression Denna övningslapp behandlar regression och är tänkt som förberedelse
Lunds tekniska högskola, Matematikcentrum, Matematisk statistik Matematisk statistik kompletterande projekt, FMSF Övning om regression Denna övningslapp behandlar regression och är tänkt som förberedelse
Föreläsning 1. Repetition av sannolikhetsteori. Patrik Zetterberg. 6 december 2012
 Föreläsning 1 Repetition av sannolikhetsteori Patrik Zetterberg 6 december 2012 1 / 28 Viktiga statistiska begrepp För att kunna förstå mer avancerade koncept under kursens gång är det viktigt att vi förstår
Föreläsning 1 Repetition av sannolikhetsteori Patrik Zetterberg 6 december 2012 1 / 28 Viktiga statistiska begrepp För att kunna förstå mer avancerade koncept under kursens gång är det viktigt att vi förstår
Experimentella metoder, FK3001. Datorövning: Finn ett samband
 Experimentella metoder, FK3001 Datorövning: Finn ett samband 1 Inledning Den här övningen går ut på att belysa hur man kan utnyttja dimensionsanalys tillsammans med mätningar för att bestämma fysikaliska
Experimentella metoder, FK3001 Datorövning: Finn ett samband 1 Inledning Den här övningen går ut på att belysa hur man kan utnyttja dimensionsanalys tillsammans med mätningar för att bestämma fysikaliska
Föreläsning 10, del 1: Icke-linjära samband och outliers
 Föreläsning 10, del 1: och outliers Pär Nyman par.nyman@statsvet.uu.se 19 september 2014-1 - Sammanfattning av tidigare kursvärderingar: - 2 - Sammanfattning av tidigare kursvärderingar: Kursen är för
Föreläsning 10, del 1: och outliers Pär Nyman par.nyman@statsvet.uu.se 19 september 2014-1 - Sammanfattning av tidigare kursvärderingar: - 2 - Sammanfattning av tidigare kursvärderingar: Kursen är för
Laboration 2: Styrkefunktion samt Regression
 Lunds Tekniska Högskola Matematikcentrum Matematisk statistik Laboration 2 Styrkefunktion & Regression FMSF70&MASB02, HT19 Laboration 2: Styrkefunktion samt Regression Syfte Styrkefunktion Syftet med dagens
Lunds Tekniska Högskola Matematikcentrum Matematisk statistik Laboration 2 Styrkefunktion & Regression FMSF70&MASB02, HT19 Laboration 2: Styrkefunktion samt Regression Syfte Styrkefunktion Syftet med dagens
TENTAMEN I SF1906 (f d 5B1506) MATEMATISK STATISTIK GRUNDKURS,
 MATEMATISK STATISTIK GRUNDKURS,") Avd. Matematisk statistik TENTAMEN I SF1906 (f d 5B1506) MATEMATISK STATISTIK GRUNDKURS, TORSDAGEN DEN 7 JUNI 2012 KL 14.00 19.00 Examinator:Gunnar Englund, 073 3213745 Tillåtna hjälpmedel: Formel- och
Avd. Matematisk statistik TENTAMEN I SF1906 (f d 5B1506) MATEMATISK STATISTIK GRUNDKURS, TORSDAGEN DEN 7 JUNI 2012 KL 14.00 19.00 Examinator:Gunnar Englund, 073 3213745 Tillåtna hjälpmedel: Formel- och
EPIDEMIOLOGI. Läran om sjukdomsförekomst i en befolkning (Ahlbom, Norell)
") EPIDEMIOLOGI Läran om sjukdomsförekomst i en befolkning (Ahlbom, Norell) Läran om utbredningen av och orsakerna till hälsorelaterade tillstånd eller förhållanden i specifika populationer och tillämpningen
EPIDEMIOLOGI Läran om sjukdomsförekomst i en befolkning (Ahlbom, Norell) Läran om utbredningen av och orsakerna till hälsorelaterade tillstånd eller förhållanden i specifika populationer och tillämpningen
Analytisk statistik. Mattias Nilsson Benfatto, PhD.
 Analytisk statistik Mattias Nilsson Benfatto, PhD Mattias.nilsson@ki.se Beskrivande statistik kort repetition Centralmått Spridningsmått Normalfördelning Konfidensintervall Korrelation Analytisk statistik
Analytisk statistik Mattias Nilsson Benfatto, PhD Mattias.nilsson@ki.se Beskrivande statistik kort repetition Centralmått Spridningsmått Normalfördelning Konfidensintervall Korrelation Analytisk statistik
Linjära ekvationer med tillämpningar
 UMEÅ UNIVERSITET Institutionen för matematik och matematisk statistik Olof Johansson, Nina Rudälv 2006-10-17 SÄL 1-10p Linjära ekvationer med tillämpningar Avsnitt 2.1 Linjära ekvationer i en variabel
UMEÅ UNIVERSITET Institutionen för matematik och matematisk statistik Olof Johansson, Nina Rudälv 2006-10-17 SÄL 1-10p Linjära ekvationer med tillämpningar Avsnitt 2.1 Linjära ekvationer i en variabel
1/23 REGRESSIONSANALYS. Statistiska institutionen, Stockholms universitet
 1/23 REGRESSIONSANALYS F4 Linda Wänström Statistiska institutionen, Stockholms universitet 2/23 Multipel regressionsanalys Multipel regressionsanalys kan ses som en utvidgning av enkel linjär regressionsanalys.
1/23 REGRESSIONSANALYS F4 Linda Wänström Statistiska institutionen, Stockholms universitet 2/23 Multipel regressionsanalys Multipel regressionsanalys kan ses som en utvidgning av enkel linjär regressionsanalys.
Regressionsmodellering inom sjukförsäkring
 Matematisk Statistik, KTH / SHB Capital Markets Aktuarieföreningen 4 februari 2014 Problembeskrivning Vi utgår från Försäkringsförbundets sjuklighetsundersökning och betraktar en portfölj av sjukförsäkringskontrakt.
Matematisk Statistik, KTH / SHB Capital Markets Aktuarieföreningen 4 februari 2014 Problembeskrivning Vi utgår från Försäkringsförbundets sjuklighetsundersökning och betraktar en portfölj av sjukförsäkringskontrakt.
1 Förberedelseuppgifter
 LUNDS TEKNISKA HÖGSKOLA MATEMATIKCENTRUM MATEMATISK STATISTIK LABORATION 2 MATEMATISK STATISTIK FÖR B, K, N, BME OCH KEMISTER; FMS086 & MASB02 Syfte: Syftet med dagens laborationen är att du skall: bli
LUNDS TEKNISKA HÖGSKOLA MATEMATIKCENTRUM MATEMATISK STATISTIK LABORATION 2 MATEMATISK STATISTIK FÖR B, K, N, BME OCH KEMISTER; FMS086 & MASB02 Syfte: Syftet med dagens laborationen är att du skall: bli
Kovarians och kriging
 Kovarians och kriging Bengt Ringnér November 2, 2007 Inledning Detta är föreläsningsmanus på lantmätarprogrammet vid LTH. 2 Kovarianser Sedan tidigare har vi, för oberoende X och Y, att VX + Y ) = VX)
Kovarians och kriging Bengt Ringnér November 2, 2007 Inledning Detta är föreläsningsmanus på lantmätarprogrammet vid LTH. 2 Kovarianser Sedan tidigare har vi, för oberoende X och Y, att VX + Y ) = VX)
3-8 Proportionalitet Namn:
 3-8 Proportionalitet Namn: Inledning Det här kapitlet handlar om samband mellan olika storheter och formler. När du är klar är du mästare på att arbeta med proportionalitet, det vill säga du klarar enkelt
3-8 Proportionalitet Namn: Inledning Det här kapitlet handlar om samband mellan olika storheter och formler. När du är klar är du mästare på att arbeta med proportionalitet, det vill säga du klarar enkelt
Weibullanalys. Maximum-likelihoodskattning
 1 Weibullanalys Jan Enger Matematisk statistik KTH Weibull-fördelningen är en mycket viktig fördelning inom tillförlitlighetsanalysen. Den används ofta för att modellera mekaniska komponenters livslängder.
1 Weibullanalys Jan Enger Matematisk statistik KTH Weibull-fördelningen är en mycket viktig fördelning inom tillförlitlighetsanalysen. Den används ofta för att modellera mekaniska komponenters livslängder.
inte följa någon enkel eller fiffig princip, vad man nu skulle mena med det. All right, men
 MATEMATISKA INSTITUTIONEN STOCKHOLMS UNIVERSITET Christian Gottlieb Gymnasieskolans matematik med akademiska ögon Induktion Dag 2. Explicita formler och rekursionsformler. Dag mötte vi flera talföljder,
MATEMATISKA INSTITUTIONEN STOCKHOLMS UNIVERSITET Christian Gottlieb Gymnasieskolans matematik med akademiska ögon Induktion Dag 2. Explicita formler och rekursionsformler. Dag mötte vi flera talföljder,
1 Förberedelser. 2 Att starta MATLAB, användning av befintliga m-filer. 3 Geometriskt fördelad avkomma
 LUNDS UNIVERSITET MATEMATIKCENTRUM MATEMATISK STATISTIK LABORATION 2: FÖRGRENINGSPROCESSER MATEMATISK STATISTIK AK, MAS 101:A, VT-01 1 Förberedelser Syftet med denna laboration är att du skall bli mer
LUNDS UNIVERSITET MATEMATIKCENTRUM MATEMATISK STATISTIK LABORATION 2: FÖRGRENINGSPROCESSER MATEMATISK STATISTIK AK, MAS 101:A, VT-01 1 Förberedelser Syftet med denna laboration är att du skall bli mer
PROGRAMFÖRKLARING III
 Statistik för modellval och prediktion att beskriva, förklara och förutsäga Georg Lindgren PROGRAMFÖRKLARING III Matematisk statistik, Lunds universitet stik för modellval och prediktion p./22 Statistik
Statistik för modellval och prediktion att beskriva, förklara och förutsäga Georg Lindgren PROGRAMFÖRKLARING III Matematisk statistik, Lunds universitet stik för modellval och prediktion p./22 Statistik
Mer om slumpvariabler
 1/20 Mer om slumpvariabler Måns Thulin Uppsala universitet thulin@math.uu.se Statistik för ingenjörer 4/2 2013 2/20 Dagens föreläsning Diskreta slumpvariabler Vilket kretskort ska man välja? Väntevärde
1/20 Mer om slumpvariabler Måns Thulin Uppsala universitet thulin@math.uu.se Statistik för ingenjörer 4/2 2013 2/20 Dagens föreläsning Diskreta slumpvariabler Vilket kretskort ska man välja? Väntevärde
Kapitel 4 Sannolikhetsfördelningar Sid Föreläsningsunderlagen är baserade på underlag skrivna av Karl Wahlin
 Kapitel 4 Sannolikhetsfördelningar Sid 79-14 Föreläsningsunderlagen är baserade på underlag skrivna av Karl Wahlin Slumpvariabel En variabel för vilken slumpen bestämmer utfallet. Slantsingling, tärningskast,
Kapitel 4 Sannolikhetsfördelningar Sid 79-14 Föreläsningsunderlagen är baserade på underlag skrivna av Karl Wahlin Slumpvariabel En variabel för vilken slumpen bestämmer utfallet. Slantsingling, tärningskast,
Att mäta hälsa och sjukdom med tillgänglig information Kvantitativa metoder II: Teori och tillämpning Folkhälsovetenskap 4, termin 6
 Att mäta hälsa och sjukdom med tillgänglig information Kvantitativa metoder II: Teori och tillämpning Folkhälsovetenskap 4, termin 6 Hanna Hultin hanna.hultin@ki.se Disposition Mortalitet Morbiditet Standardisering
Att mäta hälsa och sjukdom med tillgänglig information Kvantitativa metoder II: Teori och tillämpning Folkhälsovetenskap 4, termin 6 Hanna Hultin hanna.hultin@ki.se Disposition Mortalitet Morbiditet Standardisering
2011-09-02. Grunderna i epidemiologi. Innehåll: Vad är epidemiologi? Epidemiologins tillämpningsområden
 Innehåll: Grunderna i epidemiologi Vad är epidemiologi? Beskriva 5 olika typer av studiedesign Beskriva 3 olika typer av sjukdomsmått Emilie.agardh@ki.se Diskutera orsaker och samband Varför är epidemiologi
Innehåll: Grunderna i epidemiologi Vad är epidemiologi? Beskriva 5 olika typer av studiedesign Beskriva 3 olika typer av sjukdomsmått Emilie.agardh@ki.se Diskutera orsaker och samband Varför är epidemiologi
Dekomponering av löneskillnader
 Lönebildningsrapporten 2013 133 FÖRDJUPNING Dekomponering av löneskillnader Den här fördjupningen ger en detaljerad beskrivning av dekomponeringen av skillnader i genomsnittlig lön. Först beskrivs metoden
Lönebildningsrapporten 2013 133 FÖRDJUPNING Dekomponering av löneskillnader Den här fördjupningen ger en detaljerad beskrivning av dekomponeringen av skillnader i genomsnittlig lön. Först beskrivs metoden
Tentamen i Matematisk statistik Kurskod S0001M
 Tentamen i Matematisk statistik Kurskod S0001M Poäng totalt för del 1: 25 (10 uppgifter) Tentamensdatum 2015-10-23 Poäng totalt för del 2: 30 (3 uppgifter) Skrivtid 09.00 14.00 Lärare: Jesper Martinsson,
Tentamen i Matematisk statistik Kurskod S0001M Poäng totalt för del 1: 25 (10 uppgifter) Tentamensdatum 2015-10-23 Poäng totalt för del 2: 30 (3 uppgifter) Skrivtid 09.00 14.00 Lärare: Jesper Martinsson,
PROGRAMFÖRKLARING I. Statistik för modellval och prediktion. Ett exempel: vågriktning och våghöjd
 Statistik för modellval och prediktion att beskriva, förklara och förutsäga Georg Lindgren PROGRAMFÖRKLARING I Matematisk statistik, Lunds universitet stik för modellval och prediktion p.1/4 Statistik
Statistik för modellval och prediktion att beskriva, förklara och förutsäga Georg Lindgren PROGRAMFÖRKLARING I Matematisk statistik, Lunds universitet stik för modellval och prediktion p.1/4 Statistik
Explorativ övning 5 MATEMATISK INDUKTION
 Explorativ övning 5 MATEMATISK INDUKTION Syftet med denna övning är att introducera en av de viktigaste bevismetoderna i matematiken matematisk induktion. Termen induktion är lite olycklig därför att matematisk
Explorativ övning 5 MATEMATISK INDUKTION Syftet med denna övning är att introducera en av de viktigaste bevismetoderna i matematiken matematisk induktion. Termen induktion är lite olycklig därför att matematisk
Matematikcentrum 1(4) Matematisk Statistik Lunds Universitet MASB11 HT10. Laboration. Regressionsanalys (Sambandsanalys)
 Matematisk Statistik Lunds Universitet MASB11 HT10. Laboration. Regressionsanalys (Sambandsanalys)") Matematikcentrum 1(4) Matematisk Statistik Lunds Universitet MASB11 HT10 Laboration Regressionsanalys (Sambandsanalys) Grupp A: 2010-11-24, 13.15 15.00 Grupp B: 2010-11-24, 15.15 17.00 Grupp C: 2010-11-25,
Matematikcentrum 1(4) Matematisk Statistik Lunds Universitet MASB11 HT10 Laboration Regressionsanalys (Sambandsanalys) Grupp A: 2010-11-24, 13.15 15.00 Grupp B: 2010-11-24, 15.15 17.00 Grupp C: 2010-11-25,
Räkneövning 4. Om uppgifterna. 1 Uppgift 1. Statistiska institutionen Uppsala universitet. 14 december 2016
 Räkneövning 4 Statistiska institutionen Uppsala universitet 14 december 2016 Om uppgifterna Uppgift 2 kan med fördel göras med Minitab. I de fall en gur för tidsserien efterfrågas kan du antingen göra
Räkneövning 4 Statistiska institutionen Uppsala universitet 14 december 2016 Om uppgifterna Uppgift 2 kan med fördel göras med Minitab. I de fall en gur för tidsserien efterfrågas kan du antingen göra
Föreläsningsmanus i matematisk statistik för lantmätare, vecka 5 HT06
 Föreläsningsmanus i matematisk statistik för lantmätare, vecka 5 HT06 Bengt Ringnér September 20, 2006 Inledning Detta är preliminärt undervisningsmaterial. Synpunkter är välkomna. 2 Väntevärde standardavvikelse
Föreläsningsmanus i matematisk statistik för lantmätare, vecka 5 HT06 Bengt Ringnér September 20, 2006 Inledning Detta är preliminärt undervisningsmaterial. Synpunkter är välkomna. 2 Väntevärde standardavvikelse
Föreläsning 8, Matematisk statistik 7.5 hp för E Punktskattningar
 Föreläsning 8, Matematisk statistik 7.5 hp för E Punktskattningar Stas Volkov Stanislav Volkov s.volkov@maths.lth.se FMSF20 F8: Statistikteori 1/20 Översikt Exempel Repetition Exempel Matematisk statistik
Föreläsning 8, Matematisk statistik 7.5 hp för E Punktskattningar Stas Volkov Stanislav Volkov s.volkov@maths.lth.se FMSF20 F8: Statistikteori 1/20 Översikt Exempel Repetition Exempel Matematisk statistik
Eget val och brukares uppfattningar om kvalitet i hemtjänsten
 Eget val och brukares uppfattningar om kvalitet i hemtjänsten En sammanfattning av utvärderingen av införandet av Eget val ur ett brukarperspektiv Bo Davidson Linköpings universitet och FoU-centrum Under
Eget val och brukares uppfattningar om kvalitet i hemtjänsten En sammanfattning av utvärderingen av införandet av Eget val ur ett brukarperspektiv Bo Davidson Linköpings universitet och FoU-centrum Under
Kompletterande lösningsförslag och ledningar, Matematik 3000 kurs A, kapitel 4. b) = 3 1 = 2
 = 3 1 = 2") Kapitel.1 101, 102 Exempel som löses i boken 10 a) x= 1 11+ x= 11+ 1 = 2 c) x= 11 7 x= 7 11 = 77 b) x= 5 x 29 = 5 29 = 6 d) x= 2 26 x= 26 2= 1 10 a) x= 6 5+ 9 x= 5+ 9 6= 5+ 5= 59 b) a = 8a 6= 8 6= 2 6=
Kapitel.1 101, 102 Exempel som löses i boken 10 a) x= 1 11+ x= 11+ 1 = 2 c) x= 11 7 x= 7 11 = 77 b) x= 5 x 29 = 5 29 = 6 d) x= 2 26 x= 26 2= 1 10 a) x= 6 5+ 9 x= 5+ 9 6= 5+ 5= 59 b) a = 8a 6= 8 6= 2 6=
Föreläsning 4: Konfidensintervall (forts.)
") Föreläsning 4: Konfidensintervall forts. Johan Thim johan.thim@liu.se 3 september 8 Skillnad mellan parametrar Vi kommer nu fortsätta med att konstruera konfidensintervall och vi kommer betrakta lite olika
Föreläsning 4: Konfidensintervall forts. Johan Thim johan.thim@liu.se 3 september 8 Skillnad mellan parametrar Vi kommer nu fortsätta med att konstruera konfidensintervall och vi kommer betrakta lite olika
Linjär algebra förel. 10 Minsta kvadratmetoden
 Linjär algebra förel. 10 Minsta kvadratmetoden Niels Chr. Overgaard 015-09- c N. Chr. Overgaard Förel. 9 015-09- logoonly 1 / 17 Data från 1 vuxna män vikt (kg) längd (m) 58 1,69 83 1,77 80 1,79 77 1,80
Linjär algebra förel. 10 Minsta kvadratmetoden Niels Chr. Overgaard 015-09- c N. Chr. Overgaard Förel. 9 015-09- logoonly 1 / 17 Data från 1 vuxna män vikt (kg) längd (m) 58 1,69 83 1,77 80 1,79 77 1,80
Fri besöksvård för dem över 85 år
 RAPPORT 9-215 INVÅNARPANELEN 215 Fri besöksvård för dem över 85 år Sammanfattning av resultatet Panelen består idag av 35 deltagare. De som inte svarat på någon enkät på ett och ett halvt år eller mer
RAPPORT 9-215 INVÅNARPANELEN 215 Fri besöksvård för dem över 85 år Sammanfattning av resultatet Panelen består idag av 35 deltagare. De som inte svarat på någon enkät på ett och ett halvt år eller mer
Uppgift 1. f(x) = 2x om 0 x 1
 = 2x om 0 x 1") Avd. Matematisk statistik TENTAMEN I Matematisk statistik SF1907, SF1908 OCH SF1913 TORSDAGEN DEN 30 MAJ 2013 KL 14.00 19.00. Examinator: Gunnar Englund, 073 321 3745 Tillåtna hjälpmedel: Formel- och tabellsamling
Avd. Matematisk statistik TENTAMEN I Matematisk statistik SF1907, SF1908 OCH SF1913 TORSDAGEN DEN 30 MAJ 2013 KL 14.00 19.00. Examinator: Gunnar Englund, 073 321 3745 Tillåtna hjälpmedel: Formel- och tabellsamling
 Kursombud sökes! Kursens syfte är att ge en introduktion till metoder för att förutsäga realtidsegenskaper hos betjäningssystem, i synnerhet för data- och telekommunikationssystem. Såväl enkla betjäningssystem,
Kursombud sökes! Kursens syfte är att ge en introduktion till metoder för att förutsäga realtidsegenskaper hos betjäningssystem, i synnerhet för data- och telekommunikationssystem. Såväl enkla betjäningssystem,
Studietyper, inferens och konfidensintervall
 Studietyper, inferens och konfidensintervall Andrew Hooker Division of Pharmacokinetics and Drug Therapy Department of Pharmaceutical Biosciences Uppsala University Studietyper Experimentella studier Innebär
Studietyper, inferens och konfidensintervall Andrew Hooker Division of Pharmacokinetics and Drug Therapy Department of Pharmaceutical Biosciences Uppsala University Studietyper Experimentella studier Innebär
732G71 Statistik B. Föreläsning 4. Bertil Wegmann. November 11, IDA, Linköpings universitet
 732G71 Statistik B Föreläsning 4 Bertil Wegmann IDA, Linköpings universitet November 11, 2016 Bertil Wegmann (IDA, LiU) 732G71, Statistik B November 11, 2016 1 / 34 Kap. 5.1, korrelationsmatris En korrelationsmatris
732G71 Statistik B Föreläsning 4 Bertil Wegmann IDA, Linköpings universitet November 11, 2016 Bertil Wegmann (IDA, LiU) 732G71, Statistik B November 11, 2016 1 / 34 Kap. 5.1, korrelationsmatris En korrelationsmatris
Statistiska Institutionen Gebrenegus Ghilagaber (docent) Skriftlig tentamen i FINANSIELL STATISTIK, grundnivå, 7,5 hp, HT08. Torsdagen 15 januari 2009
 Skriftlig tentamen i FINANSIELL STATISTIK, grundnivå, 7,5 hp, HT08. Torsdagen 15 januari 2009") Statistiska Institutionen Gebrenegus Ghilagaber (docent) Skriftlig tentamen i FINANSIELL STATISTIK, grundnivå, 7,5 hp, HT08. Torsdagen 15 januari 009 Skrivtid: 5 timmar (13-18) Hjälpmedel: Miniräknare,
Statistiska Institutionen Gebrenegus Ghilagaber (docent) Skriftlig tentamen i FINANSIELL STATISTIK, grundnivå, 7,5 hp, HT08. Torsdagen 15 januari 009 Skrivtid: 5 timmar (13-18) Hjälpmedel: Miniräknare,
Statistik och epidemiologi T5
 Statistik och epidemiologi T5 Anna Axmon Biostatistiker Yrkes- och miljömedicin Biostatistik kursmål Dra slutsatser utifrån basala statistiska begrepp och analyser och själva kunna använda sådana metoder.
Statistik och epidemiologi T5 Anna Axmon Biostatistiker Yrkes- och miljömedicin Biostatistik kursmål Dra slutsatser utifrån basala statistiska begrepp och analyser och själva kunna använda sådana metoder.
4 Diskret stokastisk variabel
 4 Diskret stokastisk variabel En stokastisk variabel är en variabel vars värde bestäms av utfallet av ett slumpmässigt försök. En stokastisk variabel betecknas ofta med X, Y eller Z (i läroboken används
4 Diskret stokastisk variabel En stokastisk variabel är en variabel vars värde bestäms av utfallet av ett slumpmässigt försök. En stokastisk variabel betecknas ofta med X, Y eller Z (i läroboken används
Epidemiologi 1. Ragnar Westerling
 Epidemiologi 1 Ragnar Westerling Epidemiologi Läran om sjukdomars utbredning i befolkningen Epi bland Demo folk Logi läran om Epidemiologi Svarar på frågor om tid, plats, person Vem är det som drabbas
Epidemiologi 1 Ragnar Westerling Epidemiologi Läran om sjukdomars utbredning i befolkningen Epi bland Demo folk Logi läran om Epidemiologi Svarar på frågor om tid, plats, person Vem är det som drabbas
Labbrapport svängande skivor
 Labbrapport svängande skivor Erik Andersson Johan Schött Olof Berglund 11th October 008 Sammanfattning Grunden för att finna matematiska samband i fysiken kan vara lite svårt att förstå och hur man kan
Labbrapport svängande skivor Erik Andersson Johan Schött Olof Berglund 11th October 008 Sammanfattning Grunden för att finna matematiska samband i fysiken kan vara lite svårt att förstå och hur man kan
F11. Kvantitativa prognostekniker
 F11 Kvantitativa prognostekniker samt repetition av kursen Kvantitativa prognostekniker Vi har gjort flera prognoser under kursen Prognoser baseras på antagandet att historien upprepar sig Trenden följer
F11 Kvantitativa prognostekniker samt repetition av kursen Kvantitativa prognostekniker Vi har gjort flera prognoser under kursen Prognoser baseras på antagandet att historien upprepar sig Trenden följer