Kapitel 12: TEST GÄLLANDE EN GRUPP KOEFFICIENTER - ANOVA
|
|
|
- Elias Blomqvist
- för 7 år sedan
- Visningar:
Transkript
1 Kapitel 12: TEST GÄLLANDE EN GRUPP KOEFFICIENTER - ANOVA 12.1 ANOVA I EN MULTIPEL REGRESSION Exempel: Tjänar man mer som egenföretagare? Nedan visas ett utdrag ur ett dataset som innehåller information om 293 amerikanska manliga arbetare. Egenföretagare är en dummy som antar värdet 1 för egenföretagare och värdet 0 för andra arbetare; alder mäter personens ålder och ln(timlön) är timlönen mätt på en loggad skala. id egenföretagare alder ln(timlön) , , , , , , Regressionen nedan visar att egenföretagarna tjänar cirka 4 procent mer än övriga kontrollerat för ålder. Men skillnaden är inte signifikant, t = 0,041/0,100 = 0,41 (standardfel ges inom parentes). Däremot har ålder en signifikant effekt på lönen; för varje ytterligare år så ökar lönen med cirka 1 procent, t = 0,010/0,003 3,33. ln (timlön) = 1,30 + 0,041 egenföretagare + 0,010 alder (0,100) (0,003) Nedan visas resultatet då vi kört regressionen med hjälp av statistikprogrammet STATA:
2 I rött ges resultatet från t-testerna. Men dessa är inte de enda tester som finns med i regressionsutskriften. Regressionsutskriften innehåller också ett annat test som kallas för F-testet. Inrutat i blått finns det så kallade F-värdet (6,54) med tillhörande p-värde (0,0017). Så vad använder vi detta test till? Jo, här kan vi se om regressionsmodellen som helhet har signifikant förklaringsstyrka. Eftersom p-värdet (0,0017) är mindre än 0,05 så är svaret ja. Vi ska nu se närmare på vad det här betyder. Och vi ska börja med att repetera förklaringsgraden. Förklaringsgraden, R 2 I regressionen ovan så är förklaringsgraden 0,0432. (Du hittar förklaringsgraden under F-testet: R-squared = 0,0432.) Det betyder att 4,32 procent av variationen i loggade löner kan förklaras av x-variablerna (egenföretagare, alder). Förklaringsgraden är alltså en andel och kan därför anta värden mellan 0 och 1. Det kan vara bra att fundera på vad de två extremfallen betyder. Vad skulle det betyda om förklaringsgraden vore 1? Jo, det betyder att 100 procent av variationen i utfallsvariabeln (y) kan förklaras av x-variablerna; residualen är då noll för varje observation i data. Residualen visar skillnaden mellan det verkliga värdet på y och prediktionen. Exempel: Den första personen i data är inte egenföretagare (egenföretagare = 0) och 32 år gammal. Han predikteras då tjäna ~1,62 enheter: ln (timlön) = 1,30+ 0,041 egenföretagare =0 + 0,010 alder =32
3 = 1,62 Men personen tjänar egentligen ~1,96 enheter, dvs. ungefär 0,34 enheter mer än predikterat. Residualen är alltså ~0,34 enheter. På det här viset kan vi ta fram residualen för varje person i data: id egenföretagare alder ln(timlön) Prediktion Residual , , , , , , , , , , , , , , , , , , Om vi hade en regression där alla residualer vore noll så skulle x- variablerna prediktera utfallsvariabeln perfekt. Förklaringsgraden skulle vara 1. Vad skulle det betyda om förklaringsgraden vore 0? Jo, det betyder att 0 procent av variationen i y förklaras av x- variablerna. Det här skulle innebära att vi hade en regression där alla regressionskoefficienter vore 0: ln (timlön) = 1, egenföretagare + 0 alder Om vi ändå använde den här regressionen för att göra prediktioner så skulle alla personer i data ha en predikterad loggad lön på 1,69 enheter. 1,69 är den genomsnittliga loggade lönen i data. Det här skulle betyda att x-variablerna inte bidrar med någon information alls; om vi ska gissa hur mycket en person tjänar så gör vi bäst i att bara använda medelvärdet. F-värdet Exempel forts. I regressionen ovan så är förklaringsgraden 0,0432: Cirka 4 procent av variationen i löner kan förklaras av x- variablerna (egenföretagare, alder). Men detta är förklaringsgraden i samplet: Är det möjligt att populationens förklaringsgrad egentligen är noll? Det skulle betyda att den sanna effekten av att vara egenföretagare är noll (β egen = 0) och att den sanna effekten av ålder är noll (β alder = 0). Vi kallar denna möjlighet för nollhypotesen.
4 Den andra möjligheten är att åtminstone en av effekterna (β egen, β alder eller bägge) är olika noll. Eller med andra ord: Den sanna förklaringsgraden är större än noll. Vi kallar denna möjlighet för mothypotesen. Kan vi förkasta nollhypotesen om att populationens förklaringsgrad är noll? För att svara på den frågan så skulle vi vilja veta hur vanligt är det att få en förklaringsgrad på 0,0432 bara av slumpen. Är detta något som händer ofta då den sanna förklaringsgraden är noll, eller är detta något som händer sällan? Det går att räkna ut den sannolikheten: I det här fallet så är sannolikheten för att bara av slumpen få ett sampel där förklaringsgraden blir 0,0432 eller större 0,17 procent: P(R 2 0,0432) = 0,0017 Den uppmätta förklaringsgraden i samplet hör alltså till de 0,17 procent extremaste som man kan få bara av slumpen. Även om förklaringsgraden (0,0432) är liten, så är det alltså mycket osannolikt att få en såhär pass hög förklaringsgrad bara av slumpen. Vi säger då att regressionsmodellen har signifikant förklaringsstyrka: p-värdet är 0,0017 som är mindre än 0,05. Eftersom p-värdet är mindre än 0,01 så har regressionsmodellen också signifikant förklaringsstyrka på 1-procentsnivån. Notera här att p-värdet (0,0017) är samma p-värde som ges i regressionsutskriften, inringat i blått: F-testet används alltså för att ta reda på om regressionsmodellen har signifikant förklaringsstyrka. Men varifrån kommer då F- värdet på 6,54? F-värdet är en transformation av förklaringsgraden (R 2 ):
5 p F = (1 R 2 ) (n p 1) R 2 där p är antalet oberoende variabler. Vi kan nu räkna ut att F- värdet är 6,54: p 0,0432/2 F = (1 R 2 = ) (n p 1) (1 0,0432)/( ) 6,54 R 2 Ju större förklaringsgrad, desto större F-värde. Om förklaringsgraden istället hade varit 0,5 så hade vi fått ett F-värde på 145: p 0,5/2 F = (1 R 2 = ) (n p 1) (1 0,5)/( ) = 145 R 2 När vi vill ta reda på sannolikheten för att, bara av slumpen, få ett sampel där förklaringsgraden blir minst 0,0432 så är det samma sak som att ställa sig frågan: Hur stor är sannolikheten för att, bara av slumpen, få ett F-värde på minst 6,54? Eller med andra ord: P(R 2 0,0432) = P(F 6,54) Vi såg redan att den sannolikheten är 0,0017. Figuren nedan illustrerar detta: Det här är ett exempel på en F-fördelning. Om nollhypotesen är sann (den sanna förklaringsgraden är noll) så får vi ett sampel där F-värdet hamnar någonstans mellan 0 och 3 i 95 procent av fallen. (Ett F-värde någonstans mellan 0 och 3 motsvarar här en förklaringsgrad någonstans mellan 0 och 0,02.) Om vårt F-värde faller inom detta intervall (om R 2 blir mindre än 0,02) så är
6 resultatet insignifikant; den uppmätta förklaringsgraden i samplet skulle kunna skyllas på slumpen. I 5 procent av fallen får vi ett F-värde som är större än 3. Om vi får ett sampel där F- värdet blir 3,0 så betyder det att samplet hör till de 5 procent mest extrema som man kan få bara av slumpen och p-värdet är då 0,05; vi har då ett bra stöd för att påstå att den sanna förklaringsgraden är större än 0. Men vi fick ett F-värde på 6,54 vilket ger ett p-värde på 0,0017. Regressionsmodellen har med andra ord signifikant förklaringsstyrka också på 1-procentsnivån: p-värdet = 0,0017 < 0,01. I det här exemplet så är 3,0 det kritiska värdet på 5-procentsnivån. Det krävs med andra ord ett F-värde på 3,0 eller större för att resultatet ska vara signifikant på 5-procentsnivån (för att p- värdet ska bli mindre än 0,05). Det kritiska värdet på 1- procentsnivån är 4,7; det krävs ett F-värde på 4,7 eller större för att resultatet ska vara signifikant på 1-procentsnivån (för att p-värdet ska bli mindre än 0,01). Hur stora de kritiska värdena är varierar från fall till fall; sannolikheten för att bara av slumpen få ett sampel där F-värdet blir större än 6,54 beror också på antalet observationer (n) och antalet oberoende variabler (p). Det här betyder att F-fördelningens utseende varierar beroende på n och p. Man säger att F- fördelningen har två parametrar som bestämmer hur den ser ut. Vi kan jämföra detta med normalfördelningen som också har två parametrar (µ och σ) som bestämmer hur normalfördelningen ser ut. F-fördelningens parametrar kallas för frihetsgradsantalet i täljaren och frihetsgradsantalet i nämnaren. Frihetsgradsantalet i täljaren är antalet oberoende variabler (p); frihetsgradsantalet i nämnaren är antalet observationer (n) minus antalet oberoende variabler (p) minus ett (n-p-1): p F = (1 R 2 ) (n p 1) R 2 Säg att vi drar ett sampel och får ett F-värde på 6,54 (precis som tidigare). Precis som tidigare tänker vi oss att vi har 239 observationer, men anta att vi nu har 10 oberoende variabler: p = 10, n p 1 = 228. Figuren nedan visar hur den här F- fördelningen ser ut. Det kritiska värdet på 5-procentsnivån är nu 1,87 och på 1-procentsnivån 2,40. P-värdet är 0,
7 T-test kontra F-test Exempel forts. Vi beskrev noll- och mothypoteserna: Nollhypotesen: Den sanna effekten av att vara egenföretagare är noll (β egen = 0) och den sanna effekten av ålder är noll (β alder = 0). Eller med andra ord: Populationens förklaringsgrad är 0. Mothypotesen: Åtminstone en av effekterna är olika noll populationens förklaringsgrad är större än 0. Ett signifikant resultat betyder att vi kan förkasta nollhypotesen. Men behöver vi verkligen ett F-test för att avgöra detta? Vi vet ju redan att ålder har en signifikant effekt på lön: Om ålder har en signifikant effekt på lön så måste väl också F- testet per konstruktion visa att regressionsmodellen har signifikant förklaringsstyrka? Svaret är nej. Anta att nollhypotesen är sann; ingen av x-variablerna har någon effekt på utfallsvariabeln. Ju fler x-variabler vi inkluderar i regressionen, desto högre är sannolikheten för att åtminstone en effekt ändå
8 blir signifikant. Nedan visas ett exempel på detta. Här har vi en regression med 20 oberoende variabler (x1, x2,..., x20). Ingen av dessa har egentligen någon effekt på utfallsvariabeln; de effekter vi ser i data beror på slumpen. I de flesta fall har vi fått estimat som ligger nära 0 och som är icke-signifikanta. Men det finns ett misstag; t-testet visar att effekten av x4 är signifikant. Ju fler t-tester desto större är chansen för att åtminstone ett sådant här misstag begås. (På samma sätt som chansen för att få en sexa ökar ju fler gånger vi kastar en tärning.) Om, de facto, ingen av x-variablerna har någon effekt på utfallsvariabeln så kan vi ändå förvänta oss att 5 procent av effekterna blir signifikanta: Vi säger ju att en effekt är signifikant om den hör till de 5 procent extremaste som man kan få bara av slumpen i 5 procent av fallen är slumpen framme och ger oss ett signifikant resultat av misstag. I fallet ovan så är populationens sanna förklaringsgrad 0; ingen av de 20 x-variablerna har någon egentlig effekt på utfallsvariabeln. F-testet visar också att regressionsmodellen inte har en signifikant förklaringsstyrka (F = 0,89, p-värdet = 0,6023). På motsvarande sätt kan det också finnas situationer där F-testet blir signifikant trots att ingen av de enskilda t-testerna ger
9 signifikanta resultat. I vissa regressioner är det tydligt att någon (eller flera) x-variabler har en effekt på utfallsvariabeln, men det är svårt att peka ut vilken eller vilka. Detta inträffar då x- variablerna är starkt korrelerade. Vi kan förstå detta genom följande analogi: Säg att du gått ner tio kilo efter att du börjat träna och ändrat diet. Det kan då vara svårt att avgöra om träningen eller dieten var orsaken (eller om bägge bidrog). Träning och diet är så att säga starkt korrelerade; du började med bägge samtidigt. Men även om det är svårt att påstå att träningen har effekt eller att dieten har effekt så är det lätt att påstå att träningen eller dieten (eller bägge) har effekt, vilket skulle motsvara ett signifikant resultat på F-testet trots att ingen av de enskilda t-testerna är signifikanta. F-test och t-test används generellt sett för att besvara olika frågeställningar. Med ett undantag: Om vi bara har en oberoende variabel så är t-testet och F-testet exakt samma sak. Exempel forts. Nedan visas resultat från en regression med loggad timlön som utfallsvariabel och dummyn egenföretagare som oberoende variabel. Här har vi inte kontrollerat för ålder. Egenföretagarna tjänar i snitt drygt 4 procent mer än övriga arbetare, men skillnaden är inte signifikant (t = 0,42, p-värdet = 0,676). Regressionsmodellen har inte heller signifikant förklaringsstyrka (F = 0,17, p-värdet = 0,6765). Notera här att p- värdena är lika stora. Detta beror på att bägge testar exakt samma sak. När vi bara har en oberoende variabel så kommer vi från t-värdet till F-värdet genom att kvadrera t-värdet: 0,42 2 0,17.
10 12.2 ANOVA I REGRESSIONER MED FAKTORVARIABLER Om du läser en statistisk rapport där man gjort en multipel regression så är chansen stor att de inte rapporterar resultatet från F-testet. Ofta ligger intresset i att estimera effekten av en x- variabel på utfallsvariabeln, kontrollerat för några andra variabler. Om regressionsmodellen har signifikant förklaringsstyrka eller inte är då irrelevant. Men det finns också fall där F-testet är av huvudsakligt intresse. Detta gäller inte minst då vi har regressioner med faktorvariabler. Vi ska se två exempel på det här. Exempel: Vi ska lansera en ny läskedryck och ska nu besluta oss för vilken färg vi vill använda på förpackningen. Vi utför följande experiment. Tio kvartersbutiker ingår i studien; fem av dessa lottas ut och får röda läskeburkar medan de andra fem får blåa. Efter en vecka mäter vi försäljningen i varje butik (mätt som antalet backar). Tabellen nedan visar data. Butik Färg Röd Försäljning 1 Blå Blå Blå Blå Blå Röd Röd Röd Röd Röd 1 6 I genomsnitt såldes 5 backar av de blåa burkarna och 7 backar av de röda. Det är en genomsnittlig skillnad på 2 backar. Eller uttryckt som en regression: försäljning = röd. Är skillnaden signifikant? Nästan. Standardfelet för skillnaden är 1 vilket ger ett t-värde på 2 (t = 2/1 =2). Detta motsvarar ett p- värde på 0,081. (I det här exemplet räcker ett t-värde på 2 inte riktigt till för att skillnaden ska bli signifikant på 5- procentsnivån. Detta beror på att samplet är så pass litet, bara tio observationer.) Men anta nu att vi istället hade gjort följande experiment: Vi använder nu 15 butiker varav fem lottas ut för att få röda burkar;
11 fem får blåa burkar och fem får vita. Ett utdrag av data visas nedan: Butik Färg Röd Blå Försäljning 1 Blå Blå Blå Blå Blå Röd Röd Röd Röd Röd Vit Vit Vit Vit Vit I genomsnitt såldes 5 backar av de blåa burkarna; 7 backar av de röda och 3 backar av de vita. Uttryckt som en regression så kan vi beskriva dessa skillnader som: försäljning = röd + 2 blå där referensgruppen är vita burkar. Färg kallas här för en faktor; när vi inkluderar information om burkarnas färg genom en rad dummy-variabler så har vi gjort en regression med en faktorvariabel. Har regressionen signifikant förklaringsstyrka? Svaret är ja: F- värdet är 8,57 och p-värdet är 0,0049: Regressionsmodellen har med andra ord också signifikant förklaringsstyrka på 1-procentsnivån (0,0049 < 0,01). Eller med andra ord: Vi kan förkasta nollhypotesen om att den sanna
12 förklaringsgraden är noll. Men i det här exemplet så kan vi också formulera nollhypotesen på ett annat mer intuitivt sätt: Nollhypotesen: μ vita = μ röda = μ blå Om den sanna förklaringsgraden är noll så betyder det att försäljningen inte varierar beroende på burkens färg eller med andra ord: Genomsnittlig försäljning är lika stor oavsett färg: μ vita = μ röda = μ blå. Detta är i sin tur samma sak som att säga att det inte finns några verkliga genomsnittliga skillnader mellan röda och vita burkar, eller mellan blåa och vita burkar: β röda = 0, β blå = 0. Mothypotesen: Åtminstone en av grupperna (vita, röda, blåa) skiljer sig från de övriga. I det här fallet kunde vi konstatera att det finns signifikanta skillnader i genomsnittlig försäljning beroende på burkens färg. F-testet säger dock inte vilka färger som skiljer sig signifikant från andra; eller om det finns signifikanta skillnader mellan alla tre färger. När man på det här viset testar om det finns skillnader i medelvärden mellan grupper så kallar man det för en envägsvariansanalys (envägs-anova). Exempel: Hur varierar tentresultat beroende på hur mycket man sovit natten innan tenten? Efter en stor tentamen låter vi studenterna fylla i en enkät där de uppskattar hur många timmar de sov natten innan. De kan välja mellan följande alternativ: 0-2 timmar, 2-4 timmar, 4-6 timmar och 6+ timmar. I tabellen nedan presenteras genomsnittligt resultat för varje sömngrupp (1-4). Sömngrupp Medelvärde # obs. 1 (0-2 timmar) 49, (2-4 timmar) 61,9 8 3 (4-6 timmar) 66, (6+ timmar) 78,0 50 Samma information som presenteras i tabellen ovan kan vi också beskriva genom en regression: resultat = 49,8 + 12,1 sömn2 + 16,3 sömn3 + 28,2 sömn4
13 där sömn2 en dummy som antar värdet 1 för dem som sov 2-4 timmar och värdet 0 för övriga; sömn3 är en dummy som antar värdet 1 för dem som sov 4-6 timmar och värdet 0 för övriga; sömn4 är en dummy för dem som sov 6+ timmar och värdet 0 för övriga. Referensgruppen är de som sovit 0-2 timmar. Den här regressionen visar exempelvis att de som sov 6+ timmar (sömn4 = 1) i snitt presterade 28,2 procentenheter bättre än de som sov 0-2 timmar. Så finns det signifikanta skillnader i genomsnittligt tentresultat beroende på sömngrupp? Regressionsutskriften nedan visar att svaret är ja (F = 11,84; p-värdet = 0,000). Notera här att det här inte betyder att vi skulle ha visat att det finns skillnader mellan alla fyra grupper; utan bara att åtminstone en sömngrupp skiljer sig från de andra. Exempel forts. Anta att vi nu också frågat studenterna hur många timmar de jobbat med kursen per vecka (variabeln timmar). Ett utdrag av data ges nedan: Id Sömn Sömn2 Sömn3 Sömn4 Timmar Resultat Vi har då möjlighet att ställa oss följande fråga: Om vi kontrollerar för antalet arbetstimmar, finns det då fortfarande skillnader i resultat beroende på sömngrupp? Vi inkluderar då antalet arbetstimmar (timmar) som en oberoende variabel i regressionen vilket ger resultatet:
14 Regressionsekvationen: resultat = 19,1 + 2,6 sömn2 + 6,3 sömn3 + 10,6 sömn4 + 4,2 timmar Som du märker så minskar nu skillnaderna mellan sömngrupperna. Exempel: Tidigare såg vi att de som sovit 6+ timmar i snitt skrivit 28,2 procentenheter bättre än de som sovit 0-2 timmar. Men då vi kontrollerar för antalet arbetstimmar så sjunker skillnaden till 10,6 procentenheter. (Det här betyder att personer som sovit 6+ timmar i snitt jobbat mer under kursens lopp, vilket delvis förklarar varför de klarar sig bättre på tenten.) Tidigare såg vi att det fanns signifikanta skillnader i tentamensresultat beroende på sömngrupp. Men frågan blir nu: Finns det fortfarande signifikanta skillnader mellan sömngrupper efter att vi kontrollerat för tentamensresultat? Nollhypotesen: Kontrollerat för antalet arbetstimmar så finns det inga genomsnittliga skillnader i tentamensresultat beroende på sömngrupp. Eller med andra ord: β sömn2 = 0, β sömn3 = 0, β sömn4 = 0 Mothypotesen: Åtminstone en av grupperna skiljer sig från de övriga. Eller med andra ord: Åtminstone en av effekterna (β sömn2, β sömn3, β sömn4 ) är olika noll. Så kan vi förkasta nollhypotesen om inga skillnader? Från regressionsutskriften ovan så ser vi att regressionsmodellen har signifikant förklaringsstyrka (F = 81,21; p = 0,000). Men det här är inte samma sak som att fråga om det finns signifikanta skillnader mellan sömngrupper kontrollerat för antalet
15 arbetstimmar. Regressionsutskriften ger oss inte svaret på den här frågan, men vi kan beställa detta F-test skilt: F-värdet är 4,87 och p-värdet är 0,0034. Det finns med andra ord fortfarande signifikanta skillnader i tentamensresultat beroende på sömngrupp, även efter att vi kontrollerat för antalet arbetstimmar. F-testet säger alltså inte att det finns skillnader mellan alla fyra sömngrupper (kontrollerat för antalet arbetstimmar) men bara att åtminstone en grupp skiljer sig från de andra. Rent konkret så kan vi räkna ut detta F-värde genom följande formel: F = (R 2 2 med R utan )/(p med p utan ) 2 (1 R med )/(n p med 1) 2 där R med är förklaringsgraden i en regression där vi tagit med alla oberoende variabler; p med är antalet oberoende variabler i 2 den regressionen. R utan är förklaringsgraden i en regression där vi inte tagit med sömngrupperna som dummyvariabler, dvs. en regression med enbart en oberoende variabel: timmar. p utan är antalet oberoende variabler i den regressionen. Regressionsutskriften nedan visar att R med = 0,7737; p med = 2 4.
16 Regressionsutskriften nedan visar 2 att R utan = 0,7390 och p utan = 1. Vi kan nu räkna ut att F-värdet är 4,87: F = (R 2 2 med R utan )/(p med p utan ) 2 (1 R med )/(n p med 1) = (0,7737 0,7390)/(4 1) (1 0,7737)/( ) 4,87 I det här fallet följer F-värdet en F-fördelning med (4-1) frihetsgrader i täljaren och ( ) frihetsgrader i nämnaren: De kritiska värdena på 5- och 1-procentsnivån är 2,71 och 4,00. Eftersom 4,87 är större än det kritiska värdet på 1-procentsnivån så är resultatet signifikant på 1-procentsnivån. Tidigare såg vi också att p-värdet var 0,0034.
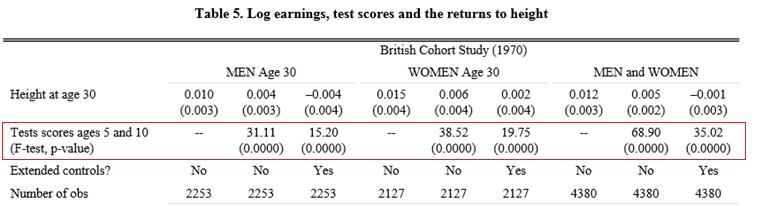
17 Det här F-testet är en generaliserad version av de F-tester vi sett på tidigare. Om vi vill testa om regressionsmodellen som helhet har signifikant förklaringsstyrka så vill vi, så att säga, se om en regression som inkluderar alla x-variabler är signifikant bättre på att prediktera utfallsvariabeln än en regression utan några x- variabler (bara ett intercept = medelvärdet för utfallsvariabeln). 2 En regression utan x-variabler har R utan = 0 och p utan = 0 vilket tar oss tillbaka till det gamla F-testet: F = (R 2 2 med R utan )/(p med p utan ) R 2 /p 2 = (1 R med )/(n p med 1) (1 R 2 )/(n p 1) Test gällande en delgrupp koefficienter I exemplet ovan så använde vi F-testet för att se om det finns signifikanta skillnader i tentamensresultat beroende på sömngrupp (kontrollerat för antalet arbetstimmar). Nollhypotesen gällde då en delgrupp av koefficienterna i regressionen: β sömn2 = 0, β sömn3 = 0, β sömn4 = 0 Det finns dock inget som säger att dessa koefficienter (β) måste vara just koefficienter för dummy-variabler skapade utifrån en faktorvariabel (sömngrupp). F-testet kan generaliseras till att testa vilken delgrupp av koefficienter som helst. Exempel: Tabellen på nästa sida är klippt ur artikeln Stature and Status: Health, Ability and Labor Market outcomes. Här har man mätt sambandet mellan längd och lön för ett sampel brittiska män och kvinnor. Man har också kontrollerat för testresultat i ung ålder (Test scores ages 5 and 10) där testresultatet mäter antalet poäng på kognitiva tester. Se samplet för männen, den andra kolumnen. Regressionen: ln(earnings) = a + 0,004 height + b2 test5 + b 3 test10 där test5 är testresultat vid fem års ålder och test10 är testresultat vid 10 års ålder. Den enda regressionskoefficienten som ges i tabellen är den för height. På raden för Test scores ages 5 and 10 får vi istället ett F-test (F = 31,11, p-värdet =
18 0,000). Så vad visar det här F-testet? Jo, att testresultat i ung ålder har en signifikant effekt på löner i vuxen ålder (kontrollerat för längd). I den här studien är det ointressant att göra en skillnad mellan effekten av testresultat vid 5 och 10 års ålder; istället testar författarna om dessa variabler tillsammans bidrar till att förklara variationen i löner. Och svaret är ja (p-värdet 0).
19
20 Antaganden De villkor som gäller för t-testet gäller också för F-testet. Här är bara en kort repetition: 1) Slumpmässigt draget sampel eller ett sampel som stratifierat på en eller flera x-variabler i regressionen. 2) Utfallsvariabeln är normalfördelad för olika värden på x-variablerna, eller så har vi ett relativt stort sampel. 3) Homoskedasticitet: Variansen i utfallsvariabeln är jämnstor för olika värden på x-variablerna.
ATT KONTROLLERA FÖR BAKOMLIGGANDE FAKTORER
 ATT KONTROLLERA FÖR BAKOMLIGGANDE FAKTORER 1. Regressionen nedan visar hur kvinnors arbetsmarknadsdeltagande varierar beroende på om de har småbarn eller inte. Datamaterialet gäller 753 amerikanska kvinnor
ATT KONTROLLERA FÖR BAKOMLIGGANDE FAKTORER 1. Regressionen nedan visar hur kvinnors arbetsmarknadsdeltagande varierar beroende på om de har småbarn eller inte. Datamaterialet gäller 753 amerikanska kvinnor
ATT KONTROLLERA FÖR BAKOMLIGGANDE FAKTORER
 ATT KONTROLLERA FÖR BAKOMLIGGANDE FAKTORER 1. Regressionen nedan visar hur kvinnors arbetsmarknadsdeltagande varierar beroende på om de har småbarn eller inte. Datamaterialet gäller 753 amerikanska kvinnor
ATT KONTROLLERA FÖR BAKOMLIGGANDE FAKTORER 1. Regressionen nedan visar hur kvinnors arbetsmarknadsdeltagande varierar beroende på om de har småbarn eller inte. Datamaterialet gäller 753 amerikanska kvinnor
ÖVNINGSUPPGIFTER KAPITEL 6
 ÖVNINGSUPPGIFTER KAPITEL 6 ATT KONTROLLERA FÖR BAKOMLIGGANDE FAKTORER 1. Regressionen nedan visar hur kvinnors arbetsmarknadsdeltagande varierar beroende på om de har småbarn eller inte. Datamaterialet
ÖVNINGSUPPGIFTER KAPITEL 6 ATT KONTROLLERA FÖR BAKOMLIGGANDE FAKTORER 1. Regressionen nedan visar hur kvinnors arbetsmarknadsdeltagande varierar beroende på om de har småbarn eller inte. Datamaterialet
ÖVNINGSUPPGIFTER KAPITEL 12
 ÖVNINGSUPPGIFTER KAPITEL 12 ANOVA I EN MULTIPEL REGRESSION 1. I en amerikansk studie samlade man in data för 601 gifta personer, och mätte hur många utomäktenskapliga affärer de haft under det senaste
ÖVNINGSUPPGIFTER KAPITEL 12 ANOVA I EN MULTIPEL REGRESSION 1. I en amerikansk studie samlade man in data för 601 gifta personer, och mätte hur många utomäktenskapliga affärer de haft under det senaste
Kapitel 15: INTERAKTIONER, STANDARDISERADE SKALOR OCH ICKE-LINJÄRA EFFEKTER
 Kapitel 15: INTERAKTIONER, STANDARDISERADE SKALOR OCH ICKE-LINJÄRA EFFEKTER När vi mäter en effekt i data så vill vi ofta se om denna skiljer sig mellan olika delgrupper. Vi kanske testar effekten av ett
Kapitel 15: INTERAKTIONER, STANDARDISERADE SKALOR OCH ICKE-LINJÄRA EFFEKTER När vi mäter en effekt i data så vill vi ofta se om denna skiljer sig mellan olika delgrupper. Vi kanske testar effekten av ett
ÖVNINGSUPPGIFTER KAPITEL 8
 ÖVNINGSUPPGIFTER KAPITEL 8 SAMPEL KONTRA POPULATION 1. Nedan beskrivs fyra frågeställningar. Ange om populationen är ändlig eller oändlig i respektive fall. Om ändlig, beskriv också vem eller vad som ingår
ÖVNINGSUPPGIFTER KAPITEL 8 SAMPEL KONTRA POPULATION 1. Nedan beskrivs fyra frågeställningar. Ange om populationen är ändlig eller oändlig i respektive fall. Om ändlig, beskriv också vem eller vad som ingår
Kapitel 17: HETEROSKEDASTICITET, ROBUSTA STANDARDFEL OCH VIKTNING
 Kapitel 17: HETEROSKEDASTICITET, ROBUSTA STANDARDFEL OCH VIKTNING När vi gör en regressionsanalys så bygger denna på vissa antaganden: Vi antar att vi dragit ett slumpmässigt sampel från en population
Kapitel 17: HETEROSKEDASTICITET, ROBUSTA STANDARDFEL OCH VIKTNING När vi gör en regressionsanalys så bygger denna på vissa antaganden: Vi antar att vi dragit ett slumpmässigt sampel från en population
Kapitel 18: LINJÄRA SANNOLIKHETSMODELLER, LOGIT OCH PROBIT
 Kapitel 18: LINJÄRA SANNOLIKHETSMODELLER, LOGIT OCH PROBIT Regressionsanalys handlar om att estimera hur medelvärdet för en variabel (y) varierar med en eller flera oberoende variabler (x). Exempel: Hur
Kapitel 18: LINJÄRA SANNOLIKHETSMODELLER, LOGIT OCH PROBIT Regressionsanalys handlar om att estimera hur medelvärdet för en variabel (y) varierar med en eller flera oberoende variabler (x). Exempel: Hur
Kapitel 4: SAMBANDET MELLAN VARIABLER: REGRESSIONSLINJEN
 Kapitel 4: SAMBANDET MELLAN VARIABLER: REGRESSIONSLINJEN Spridningsdiagrammen nedan representerar samma korrelationskoefficient, r = 0,8. 80 80 60 60 40 40 20 20 0 0 20 40 0 0 20 40 Det finns dock två
Kapitel 4: SAMBANDET MELLAN VARIABLER: REGRESSIONSLINJEN Spridningsdiagrammen nedan representerar samma korrelationskoefficient, r = 0,8. 80 80 60 60 40 40 20 20 0 0 20 40 0 0 20 40 Det finns dock två
Kapitel 22: KLUSTRADE SAMPEL OCH PANELDATA
 Kapitel 22: KLUSTRADE SAMPEL OCH PANELDATA Statistiska tester bygger alltid på vissa antaganden. Är feltermen homoskedastisk? Är den normalfördelad? Dessa antaganden är faktiskt aldrig uppfyllda i praktiken,
Kapitel 22: KLUSTRADE SAMPEL OCH PANELDATA Statistiska tester bygger alltid på vissa antaganden. Är feltermen homoskedastisk? Är den normalfördelad? Dessa antaganden är faktiskt aldrig uppfyllda i praktiken,
Lösningsförslag till tentamen på. Statistik och kvantitativa undersökningar STA100, 15 hp. Fredagen den 13 e mars 2015
 MÄLARDALENS HÖGSKOLA Akademin för ekonomi, samhälle och teknik Statistik Lösningsförslag till tentamen på Statistik och kvantitativa undersökningar STA100, 15 hp Fredagen den 13 e mars 015 1 a 13 och 14
MÄLARDALENS HÖGSKOLA Akademin för ekonomi, samhälle och teknik Statistik Lösningsförslag till tentamen på Statistik och kvantitativa undersökningar STA100, 15 hp Fredagen den 13 e mars 015 1 a 13 och 14
Multipel Regressionsmodellen
 Multipel Regressionsmodellen Koefficienterna i multipel regression skattas från ett stickprov enligt: Multipel Regressionsmodell med k förklarande variabler: Skattad (predicerad) Värde på y y ˆ = b + b
Multipel Regressionsmodellen Koefficienterna i multipel regression skattas från ett stickprov enligt: Multipel Regressionsmodell med k förklarande variabler: Skattad (predicerad) Värde på y y ˆ = b + b
Föreläsning 9. NDAB01 Statistik; teori och tillämpning i biologi
 Föreläsning 9 Statistik; teori och tillämpning i biologi 1 (kap. 20) Introduktion I föregående föreläsning diskuterades enkel linjär regression, där en oberoende variabel X förklarar variationen hos en
Föreläsning 9 Statistik; teori och tillämpning i biologi 1 (kap. 20) Introduktion I föregående föreläsning diskuterades enkel linjär regression, där en oberoende variabel X förklarar variationen hos en
Hypotesprövning. Andrew Hooker. Division of Pharmacokinetics and Drug Therapy Department of Pharmaceutical Biosciences Uppsala University
 Hypotesprövning Andrew Hooker Division of Pharmacokinetics and Drug Therapy Department of Pharmaceutical Biosciences Uppsala University Hypotesprövning Liksom konfidensintervall ett hjälpmedel för att
Hypotesprövning Andrew Hooker Division of Pharmacokinetics and Drug Therapy Department of Pharmaceutical Biosciences Uppsala University Hypotesprövning Liksom konfidensintervall ett hjälpmedel för att
Bild 1. Bild 2 Sammanfattning Statistik I. Bild 3 Hypotesprövning. Medicinsk statistik II
 Bild 1 Medicinsk statistik II Läkarprogrammet T5 HT 2014 Anna Jöud Arbets- och miljömedicin, Lunds universitet ERC Syd, Skånes Universitetssjukhus [email protected] Bild 2 Sammanfattning Statistik I
Bild 1 Medicinsk statistik II Läkarprogrammet T5 HT 2014 Anna Jöud Arbets- och miljömedicin, Lunds universitet ERC Syd, Skånes Universitetssjukhus [email protected] Bild 2 Sammanfattning Statistik I
Föreläsning 8. NDAB02 Statistik; teori och tillämpning i biologi
 Föreläsning 8 Statistik; teori och tillämpning i biologi 1 Dagens föreläsning o Enkel linjär regression (kap 17.1 17.5) o Skatta regressionslinje (kap 17.2) o Signifikant lutning? (kap 17.3, 17.5a) o Förklaringsgrad
Föreläsning 8 Statistik; teori och tillämpning i biologi 1 Dagens föreläsning o Enkel linjär regression (kap 17.1 17.5) o Skatta regressionslinje (kap 17.2) o Signifikant lutning? (kap 17.3, 17.5a) o Förklaringsgrad
ÖVNINGSUPPGIFTER KAPITEL 4
 ÖVNINGSUPPGIFTER KAPITEL 4 REGRESSIONSLINJEN: NIVÅ OCH LUTNING 1. En av regressionslinjerna nedan beskrivs av ekvationen y = 20 + 2x; en annan av ekvationen y = 80 x; en tredje av ekvationen y = 20 + 3x
ÖVNINGSUPPGIFTER KAPITEL 4 REGRESSIONSLINJEN: NIVÅ OCH LUTNING 1. En av regressionslinjerna nedan beskrivs av ekvationen y = 20 + 2x; en annan av ekvationen y = 80 x; en tredje av ekvationen y = 20 + 3x
Tentamen på Statistik och kvantitativa undersökningar STA001, 15 hp. Exempeltenta 4
 MÄLARDALENS HÖGSKOLA Akademin för hållbar samhälls- och teknikutveckling Statistik Tentamen på Statistik och kvantitativa undersökningar STA001, 15 hp Tillåtna hjälpmedel: Miniräknare (Formelsamling bifogas
MÄLARDALENS HÖGSKOLA Akademin för hållbar samhälls- och teknikutveckling Statistik Tentamen på Statistik och kvantitativa undersökningar STA001, 15 hp Tillåtna hjälpmedel: Miniräknare (Formelsamling bifogas
Föreläsning 9. NDAB02 Statistik; teori och tillämpning i biologi
 Föreläsning 9 Statistik; teori och tillämpning i biologi 1 (kap. 20) Introduktion I föregående föreläsning diskuterades enkel linjär regression, där en oberoende variabel X förklarar variationen hos en
Föreläsning 9 Statistik; teori och tillämpning i biologi 1 (kap. 20) Introduktion I föregående föreläsning diskuterades enkel linjär regression, där en oberoende variabel X förklarar variationen hos en
Medicinsk statistik II
 Medicinsk statistik II Läkarprogrammet termin 5 VT 2013 Susanna Lövdahl, Msc, doktorand Klinisk koagulationsforskning, Lunds universitet E-post: [email protected] Dagens föreläsning Fördjupning
Medicinsk statistik II Läkarprogrammet termin 5 VT 2013 Susanna Lövdahl, Msc, doktorand Klinisk koagulationsforskning, Lunds universitet E-post: [email protected] Dagens föreläsning Fördjupning
InStat Exempel 4 Korrelation och Regression
 InStat Exempel 4 Korrelation och Regression Vi ska analysera ett datamaterial som innehåller information om kön, längd och vikt för 2000 personer. Materialet är jämnt fördelat mellan könen (1000 män och
InStat Exempel 4 Korrelation och Regression Vi ska analysera ett datamaterial som innehåller information om kön, längd och vikt för 2000 personer. Materialet är jämnt fördelat mellan könen (1000 män och
Korrelation kausalitet. ˆ Y =bx +a KAPITEL 6: LINEAR REGRESSION: PREDICTION
 KAPITEL 6: LINEAR REGRESSION: PREDICTION Prediktion att estimera "poäng" på en variabel (Y), kriteriet, på basis av kunskap om "poäng" på en annan variabel (X), prediktorn. Prediktion heter med ett annat
KAPITEL 6: LINEAR REGRESSION: PREDICTION Prediktion att estimera "poäng" på en variabel (Y), kriteriet, på basis av kunskap om "poäng" på en annan variabel (X), prediktorn. Prediktion heter med ett annat
LTH: Fastighetsekonomi 23-24 sep 2008. Enkel och multipel linjär regressionsanalys HYPOTESPRÖVNING
 LTH: Fastighetsekonomi 23-24 sep 2008 Enkel och multipel linjär regressionsanalys HYPOTESPRÖVNING Hypotesprövning (statistisk inferensteori) Statistisk hypotesprövning innebär att man med hjälp av slumpmässiga
LTH: Fastighetsekonomi 23-24 sep 2008 Enkel och multipel linjär regressionsanalys HYPOTESPRÖVNING Hypotesprövning (statistisk inferensteori) Statistisk hypotesprövning innebär att man med hjälp av slumpmässiga
Lektionsanteckningar 11-12: Normalfördelningen
 Lektionsanteckningar 11-12: Normalfördelningen När utfallsrummet för en slumpvariabel kan anta vilket värde som helst i ett givet intervall är variabeln kontinuerlig. Det är väsentligt att utfallsrummet
Lektionsanteckningar 11-12: Normalfördelningen När utfallsrummet för en slumpvariabel kan anta vilket värde som helst i ett givet intervall är variabeln kontinuerlig. Det är väsentligt att utfallsrummet
Linjär regressionsanalys. Wieland Wermke
 + Linjär regressionsanalys Wieland Wermke + Regressionsanalys n Analys av samband mellan variabler (x,y) n Ökad kunskap om x (oberoende variabel) leder till ökad kunskap om y (beroende variabel) n Utifrån
+ Linjär regressionsanalys Wieland Wermke + Regressionsanalys n Analys av samband mellan variabler (x,y) n Ökad kunskap om x (oberoende variabel) leder till ökad kunskap om y (beroende variabel) n Utifrån
Hypotestestning och repetition
 Hypotestestning och repetition Statistisk inferens Vid inferens använder man urvalet för att uttala sig om populationen Centralmått Medelvärde: x= Σx i / n Median Typvärde Spridningsmått Används för att
Hypotestestning och repetition Statistisk inferens Vid inferens använder man urvalet för att uttala sig om populationen Centralmått Medelvärde: x= Σx i / n Median Typvärde Spridningsmått Används för att
ÖVNINGSUPPGIFTER KAPITEL 10
 ÖVNINGSUPPGIFTER KAPITEL 10 För vissa uppgifter behöver du en tabell över den standardiserade normalfördelningen. Se här. SAMPLING 1. Nedan ges beskrivningar av fyra sampel. Ange i respektive fall om detta
ÖVNINGSUPPGIFTER KAPITEL 10 För vissa uppgifter behöver du en tabell över den standardiserade normalfördelningen. Se här. SAMPLING 1. Nedan ges beskrivningar av fyra sampel. Ange i respektive fall om detta
Föreläsning 3. NDAB02 Statistik; teori och tillämpning i biologi
 Föreläsning 3 Statistik; teori och tillämpning i biologi 1 Dagens föreläsning o Inferens om två populationer (kap 8.1 8.) o Parvisa observationer (kap 9.1 9.) o p-värde (kap 6.3) o Feltyper, styrka, stickprovsstorlek
Föreläsning 3 Statistik; teori och tillämpning i biologi 1 Dagens föreläsning o Inferens om två populationer (kap 8.1 8.) o Parvisa observationer (kap 9.1 9.) o p-värde (kap 6.3) o Feltyper, styrka, stickprovsstorlek
34% 34% 13.5% 68% 13.5% 2.35% 95% 2.35% 0.15% 99.7% 0.15% -3 SD -2 SD -1 SD M +1 SD +2 SD +3 SD
 6.4 Att dra slutsatser på basis av statistisk analys en kort inledning - Man har ett stickprov, men man vill med hjälp av det få veta något om hela populationen => för att kunna dra slutsatser som gäller
6.4 Att dra slutsatser på basis av statistisk analys en kort inledning - Man har ett stickprov, men man vill med hjälp av det få veta något om hela populationen => för att kunna dra slutsatser som gäller
1. a) F4 (känsla av meningslöshet) F5 (okontrollerade känlsoyttringar)
 F4 (känsla av meningslöshet) F5 (okontrollerade känlsoyttringar)") 1. a) F1(Sysselsättning) F2 (Ålder) F3 (Kön) F4 (känsla av meningslöshet) F5 (okontrollerade känlsoyttringar) nominalskala kvotskala nominalskala ordinalskala ordinalskala b) En möjlighet är att beräkna
1. a) F1(Sysselsättning) F2 (Ålder) F3 (Kön) F4 (känsla av meningslöshet) F5 (okontrollerade känlsoyttringar) nominalskala kvotskala nominalskala ordinalskala ordinalskala b) En möjlighet är att beräkna
Analytisk statistik. Mattias Nilsson Benfatto, PhD.
 Analytisk statistik Mattias Nilsson Benfatto, PhD [email protected] Beskrivande statistik kort repetition Centralmått Spridningsmått Normalfördelning Konfidensintervall Korrelation Analytisk statistik
Analytisk statistik Mattias Nilsson Benfatto, PhD [email protected] Beskrivande statistik kort repetition Centralmått Spridningsmått Normalfördelning Konfidensintervall Korrelation Analytisk statistik
Föreläsning G60 Statistiska metoder
 Föreläsning 9 Statistiska metoder 1 Dagens föreläsning o Regression Regressionsmodell Signifikant lutning? Prognoser Konfidensintervall Prediktionsintervall Tolka Minitab-utskrifter o Sammanfattning Exempel
Föreläsning 9 Statistiska metoder 1 Dagens föreläsning o Regression Regressionsmodell Signifikant lutning? Prognoser Konfidensintervall Prediktionsintervall Tolka Minitab-utskrifter o Sammanfattning Exempel
ÖVNINGSUPPGIFTER KAPITEL 10
 ÖVNINGSUPPGIFTER KAPITEL 10 För vissa uppgifter behöver du en tabell över den standardiserade normalfördelningen. Se här. SAMPLING 1. Nedan ges beskrivningar av fyra sampel. Ange i respektive fall om detta
ÖVNINGSUPPGIFTER KAPITEL 10 För vissa uppgifter behöver du en tabell över den standardiserade normalfördelningen. Se här. SAMPLING 1. Nedan ges beskrivningar av fyra sampel. Ange i respektive fall om detta
EXAMINATION KVANTITATIV METOD vt-11 (110204)
") ÖREBRO UNIVERSITET Hälsoakademin Idrott B Vetenskaplig metod EXAMINATION KVANTITATIV METOD vt-11 (110204) Examinationen består av 11 frågor, flera med tillhörande följdfrågor. Besvara alla frågor i direkt
ÖREBRO UNIVERSITET Hälsoakademin Idrott B Vetenskaplig metod EXAMINATION KVANTITATIV METOD vt-11 (110204) Examinationen består av 11 frågor, flera med tillhörande följdfrågor. Besvara alla frågor i direkt
Statistik B Regressions- och tidsserieanalys Föreläsning 1
 Statistik B Regressions- och tidsserieanalys Föreläsning Kurskod: 732G7, 8 hp Lärare och examinator: Ann-Charlotte (Lotta) Hallberg Lärare och lektionsledare: Isak Hietala Labassistenter Kap 3,-3,6. Läs
Statistik B Regressions- och tidsserieanalys Föreläsning Kurskod: 732G7, 8 hp Lärare och examinator: Ann-Charlotte (Lotta) Hallberg Lärare och lektionsledare: Isak Hietala Labassistenter Kap 3,-3,6. Läs
Sänkningen av parasitnivåerna i blodet
 4.1 Oberoende (x-axeln) Kön Kön Längd Ålder Dos Dos C max Parasitnivå i blodet Beroende (y-axeln) Längd Vikt Vikt Vikt C max Sänkningen av parasitnivåerna i blodet Sänkningen av parasitnivåerna i blodet
4.1 Oberoende (x-axeln) Kön Kön Längd Ålder Dos Dos C max Parasitnivå i blodet Beroende (y-axeln) Längd Vikt Vikt Vikt C max Sänkningen av parasitnivåerna i blodet Sänkningen av parasitnivåerna i blodet
Tentamen på. Statistik och kvantitativa undersökningar STA001, 15 hp. Exempeltenta 5. Poäng. Totalt 40. Betygsgränser: G 20 VG 30
 MÄLARDALENS HÖGSKOLA Akademin för hållbar samhälls- och teknikutveckling Statistik Tentamen på Statistik och kvantitativa undersökningar STA001, 15 hp Exempeltenta 5 Tillåtna hjälpmedel: Miniräknare (Formelsamling
MÄLARDALENS HÖGSKOLA Akademin för hållbar samhälls- och teknikutveckling Statistik Tentamen på Statistik och kvantitativa undersökningar STA001, 15 hp Exempeltenta 5 Tillåtna hjälpmedel: Miniräknare (Formelsamling
Användning. Fixed & Random. Centrering. Multilevel Modeling (MLM) Var sak på sin nivå
 Var sak på sin nivå") Användning Multilevel Modeling (MLM) Var sak på sin nivå Kimmo Sorjonen Sektionen för Psykologi Karolinska Institutet Kärt barn har många namn: (1) Random coefficient models; () Mixed effect models; (3)
Användning Multilevel Modeling (MLM) Var sak på sin nivå Kimmo Sorjonen Sektionen för Psykologi Karolinska Institutet Kärt barn har många namn: (1) Random coefficient models; () Mixed effect models; (3)
Analys av medelvärden. Jenny Selander , plan 3, Norrbacka, ingång via den Samhällsmedicinska kliniken
 Analys av medelvärden Jenny Selander [email protected] 524 800 29, plan 3, Norrbacka, ingång via den Samhällsmedicinska kliniken Jenny Selander, Kvant. metoder, FHV T1 december 20111 Innehåll Normalfördelningen
Analys av medelvärden Jenny Selander [email protected] 524 800 29, plan 3, Norrbacka, ingång via den Samhällsmedicinska kliniken Jenny Selander, Kvant. metoder, FHV T1 december 20111 Innehåll Normalfördelningen
Tentamen på. Statistik och kvantitativa undersökningar STA100, 15 hp. Fredagen den 16 e januari 2015
 MÄLARDALENS HÖGSKOLA Akademin för ekonomi, samhälle och teknik Statistik Tentamen på Statistik och kvantitativa undersökningar STA100, 15 hp Fredagen den 16 e januari 2015 Tillåtna hjälpmedel: Miniräknare
MÄLARDALENS HÖGSKOLA Akademin för ekonomi, samhälle och teknik Statistik Tentamen på Statistik och kvantitativa undersökningar STA100, 15 hp Fredagen den 16 e januari 2015 Tillåtna hjälpmedel: Miniräknare
F18 MULTIPEL LINJÄR REGRESSION, FORTS. (NCT
 Stat. teori gk, ht 006, JW F18 MULTIPEL LINJÄR REGRESSION, FORTS. (NCT 1.1, 13.1-13.6, 13.8-13.9) Modell för multipel linjär regression Modellantaganden: 1) x-värdena är fixa. ) Varje y i (i = 1,, n) är
Stat. teori gk, ht 006, JW F18 MULTIPEL LINJÄR REGRESSION, FORTS. (NCT 1.1, 13.1-13.6, 13.8-13.9) Modell för multipel linjär regression Modellantaganden: 1) x-värdena är fixa. ) Varje y i (i = 1,, n) är
Instuderingsfrågor till avsnittet om statistik, kursen Statistik och Metod, Psykologprogrammet på KI, T8
 1 Instuderingsfrågor till avsnittet om statistik, kursen Statistik och Metod, Psykologprogrammet på KI, T8 Dessa instuderingsfrågor är främst tänkta att stämma överens med innehållet i föreläsningarna,
1 Instuderingsfrågor till avsnittet om statistik, kursen Statistik och Metod, Psykologprogrammet på KI, T8 Dessa instuderingsfrågor är främst tänkta att stämma överens med innehållet i föreläsningarna,
Tentamen i statistik (delkurs C) på kursen MAR103: Marina Undersökningar - redskap och metoder.
 på kursen MAR103: Marina Undersökningar - redskap och metoder.") Tentamen 2014-12-05 i statistik (delkurs C) på kursen MAR103: Marina Undersökningar - redskap och metoder. Tillåtna hjälpmedel: Miniräknare och utdelad formelsamling med tabeller. C1. (6 poäng) Ange för
Tentamen 2014-12-05 i statistik (delkurs C) på kursen MAR103: Marina Undersökningar - redskap och metoder. Tillåtna hjälpmedel: Miniräknare och utdelad formelsamling med tabeller. C1. (6 poäng) Ange för
Spridningsdiagram (scatterplot) Fler exempel. Korrelation (forts.) Korrelation. Enkel linjär regression. Enkel linjär regression (forts.
 Fler exempel. Korrelation (forts.) Korrelation. Enkel linjär regression. Enkel linjär regression (forts.") Spridningsdiagram (scatterplot) En scatterplot som visar par av observationer: reklamkostnader på -aeln and försäljning på -aeln ScatterplotofAdvertising Ependitures ()andsales () 4 Fler eempel Notera:
Spridningsdiagram (scatterplot) En scatterplot som visar par av observationer: reklamkostnader på -aeln and försäljning på -aeln ScatterplotofAdvertising Ependitures ()andsales () 4 Fler eempel Notera:
FACIT (korrekta svar i röd fetstil)
") v. 2013-01-14 Statistik, 3hp PROTOKOLL FACIT (korrekta svar i röd fetstil) Datorlaboration 2 Konfidensintervall & hypotesprövning Syftet med denna laboration är att ni med hjälp av MS Excel ska fortsätta
v. 2013-01-14 Statistik, 3hp PROTOKOLL FACIT (korrekta svar i röd fetstil) Datorlaboration 2 Konfidensintervall & hypotesprövning Syftet med denna laboration är att ni med hjälp av MS Excel ska fortsätta
Föreläsning G60 Statistiska metoder
 Föreläsning 7 Statistiska metoder 1 Dagens föreläsning o Hypotesprövning för två populationer Populationsandelar Populationsmedelvärden Parvisa observationer Relation mellan hypotesprövning och konfidensintervall
Föreläsning 7 Statistiska metoder 1 Dagens föreläsning o Hypotesprövning för två populationer Populationsandelar Populationsmedelvärden Parvisa observationer Relation mellan hypotesprövning och konfidensintervall
F19, (Multipel linjär regression forts) och F20, Chi-två test.
 och F20, Chi-två test.") Partiella t-test F19, (Multipel linjär regression forts) och F20, Chi-två test. Christian Tallberg Statistiska institutionen Stockholms universitet Då man testar om en enskild variabel X i skall vara med
Partiella t-test F19, (Multipel linjär regression forts) och F20, Chi-två test. Christian Tallberg Statistiska institutionen Stockholms universitet Då man testar om en enskild variabel X i skall vara med
FÖRELÄSNINGSMATERIAL. diff SE. SE x x. Grundläggande statistik 2: KORRELATION OCH HYPOTESTESTNING. Påbyggnadskurs T1. Odontologisk profylaktik
 Grundläggande statistik Påbyggnadskurs T1 Odontologisk profylaktik FÖRELÄSNINGSMATERIAL : KORRELATION OCH HYPOTESTESTNING t diff SE x 1 diff SE x x 1 x. Analytisk statistik Regression & Korrelation Oberoende
Grundläggande statistik Påbyggnadskurs T1 Odontologisk profylaktik FÖRELÄSNINGSMATERIAL : KORRELATION OCH HYPOTESTESTNING t diff SE x 1 diff SE x x 1 x. Analytisk statistik Regression & Korrelation Oberoende
F14 HYPOTESPRÖVNING (NCT 10.2, , 11.5) Hypotesprövning för en proportion. Med hjälp av data från ett stickprov vill vi pröva
 Hypotesprövning för en proportion. Med hjälp av data från ett stickprov vill vi pröva") Stat. teori gk, ht 006, JW F14 HYPOTESPRÖVNING (NCT 10., 10.4-10.5, 11.5) Hypotesprövning för en proportion Med hjälp av data från ett stickprov vill vi pröva H 0 : P = P 0 mot någon av H 1 : P P 0 ; H
Stat. teori gk, ht 006, JW F14 HYPOTESPRÖVNING (NCT 10., 10.4-10.5, 11.5) Hypotesprövning för en proportion Med hjälp av data från ett stickprov vill vi pröva H 0 : P = P 0 mot någon av H 1 : P P 0 ; H
Analytisk statistik. Tony Pansell, optiker Universitetslektor
 Analytisk statistik Tony Pansell, optiker Universitetslektor Analytisk statistik Att dra slutsatser från det insamlade materialet. Två metoder: 1. att generalisera från en mindre grupp mot en större grupp
Analytisk statistik Tony Pansell, optiker Universitetslektor Analytisk statistik Att dra slutsatser från det insamlade materialet. Två metoder: 1. att generalisera från en mindre grupp mot en större grupp
Elementa om Variansanalys
 Elementa om Variansanalys för kursen sf9, Statistik för bioteknik Harald Lang 06 Envägs variansanalys. Kapitel tio beskrev metoder för att testa om x,, xk och y, ym kommer från fördelningar med samma väntevärde
Elementa om Variansanalys för kursen sf9, Statistik för bioteknik Harald Lang 06 Envägs variansanalys. Kapitel tio beskrev metoder för att testa om x,, xk och y, ym kommer från fördelningar med samma väntevärde
Standardfel (Standard error, SE) SD eller SE. Intervallskattning MSG Staffan Nilsson, Chalmers 1
 SD eller SE. Intervallskattning MSG Staffan Nilsson, Chalmers 1") Standardfel (Standard error, SE) Anta vi har ett stickprov X 1,,X n där varje X i has medel = µ och std.dev = σ. Då är Det sista kalls standardfel (eng:standard error of mean (SEM) eller (SE) och skattas
Standardfel (Standard error, SE) Anta vi har ett stickprov X 1,,X n där varje X i has medel = µ och std.dev = σ. Då är Det sista kalls standardfel (eng:standard error of mean (SEM) eller (SE) och skattas
MVE051/MSG Föreläsning 14
 MVE051/MSG810 2016 Föreläsning 14 Petter Mostad Chalmers December 14, 2016 Beroende och oberoende variabler Hittills i kursen har vi tittat på modeller där alla observationer representeras av stokastiska
MVE051/MSG810 2016 Föreläsning 14 Petter Mostad Chalmers December 14, 2016 Beroende och oberoende variabler Hittills i kursen har vi tittat på modeller där alla observationer representeras av stokastiska
Föreläsning 2. Kap 3,7-3,8 4,1-4,6 5,2 5,3
 Föreläsning Kap 3,7-3,8 4,1-4,6 5, 5,3 1 Kap 3,7 och 3,8 Hur bra är modellen som vi har anpassat? Vi bedömer modellen med hjälp av ett antal kriterier: visuell bedömning, om möjligt F-test, signifikanstest
Föreläsning Kap 3,7-3,8 4,1-4,6 5, 5,3 1 Kap 3,7 och 3,8 Hur bra är modellen som vi har anpassat? Vi bedömer modellen med hjälp av ett antal kriterier: visuell bedömning, om möjligt F-test, signifikanstest
Tentamen på. Statistik och kvantitativa undersökningar STA001, 15 hp. Exempeltenta 2
 MÄLARDALENS HÖGSKOLA Akademin för hållbar samhälls- och teknikutveckling Statistik Tentamen på Statistik och kvantitativa undersökningar STA001, 15 hp Exempeltenta 2 Tillåtna hjälpmedel: Miniräknare (Formelsamling
MÄLARDALENS HÖGSKOLA Akademin för hållbar samhälls- och teknikutveckling Statistik Tentamen på Statistik och kvantitativa undersökningar STA001, 15 hp Exempeltenta 2 Tillåtna hjälpmedel: Miniräknare (Formelsamling
Tentamen i Statistik, STA A10 och STA A13 (9 poäng) Fredag 8 december 2006, Kl
 Fredag 8 december 2006, Kl") Tentamen i Statistik, STA A10 och STA A13 (9 poäng) Fredag 8 december 2006, Kl 08.15-13.15 Tillåtna hjälpmedel: Bifogad formelsamling, approximationsschema och tabellsamling (dessa skall returneras). Egen
Tentamen i Statistik, STA A10 och STA A13 (9 poäng) Fredag 8 december 2006, Kl 08.15-13.15 Tillåtna hjälpmedel: Bifogad formelsamling, approximationsschema och tabellsamling (dessa skall returneras). Egen
Föreläsning 2. NDAB01 Statistik; teori och tillämpning i biologi
 Föreläsning 2 Statistik; teori och tillämpning i biologi 1 Normalfördelning Samplingfördelningar och CGS Fördelning för en stickprovsstatistika (t.ex. medelvärde) kallas samplingfördelning. I teorin är
Föreläsning 2 Statistik; teori och tillämpning i biologi 1 Normalfördelning Samplingfördelningar och CGS Fördelning för en stickprovsstatistika (t.ex. medelvärde) kallas samplingfördelning. I teorin är
TENTAMEN I REGRESSIONSANALYS OCH TIDSSERIEANALYS
 STOCKHOLMS UNIVERSITET Statistiska institutionen Marcus Berg VT2014 TENTAMEN I REGRESSIONSANALYS OCH TIDSSERIEANALYS Fredag 23 maj 2014 kl. 12-17 Skrivtid: 5 timmar Godkända hjälpmedel: Kalkylator utan
STOCKHOLMS UNIVERSITET Statistiska institutionen Marcus Berg VT2014 TENTAMEN I REGRESSIONSANALYS OCH TIDSSERIEANALYS Fredag 23 maj 2014 kl. 12-17 Skrivtid: 5 timmar Godkända hjälpmedel: Kalkylator utan
Tentamen på. Statistik och kvantitativa undersökningar STA001, 15 hp. Exempeltenta 2
 MÄLARDALENS HÖGSKOLA Akademin för hållbar samhälls- och teknikutveckling Statistik Tentamen på Statistik och kvantitativa undersökningar STA001, 15 hp Exempeltenta 2 Tillåtna hjälpmedel: Miniräknare (Formelsamling
MÄLARDALENS HÖGSKOLA Akademin för hållbar samhälls- och teknikutveckling Statistik Tentamen på Statistik och kvantitativa undersökningar STA001, 15 hp Exempeltenta 2 Tillåtna hjälpmedel: Miniräknare (Formelsamling
Repetitionsföreläsning
 Population / Urval / Inferens Repetitionsföreläsning Ett företag som tillverkar byxor gör ett experiment för att kontrollera kvalitén. Man väljer slumpmässigt ut 100 par som man utsätter för hård nötning
Population / Urval / Inferens Repetitionsföreläsning Ett företag som tillverkar byxor gör ett experiment för att kontrollera kvalitén. Man väljer slumpmässigt ut 100 par som man utsätter för hård nötning
FÖRELÄSNING 8:
 FÖRELÄSNING 8: 016-05-17 LÄRANDEMÅL Konfidensintervall för väntevärdet då variansen är okänd T-fördelningen Goodness of fit-test χ -fördelningen Hypotestest Signifikansgrad Samla in data Sammanställ data
FÖRELÄSNING 8: 016-05-17 LÄRANDEMÅL Konfidensintervall för väntevärdet då variansen är okänd T-fördelningen Goodness of fit-test χ -fördelningen Hypotestest Signifikansgrad Samla in data Sammanställ data
Residualanalys. Finansiell statistik, vt-05. Normalfördelade? Normalfördelade? För modellen
 Residualanalys För modellen Johan Koskinen, Statistiska institutionen, Stockholms universitet Finansiell statistik, vt-5 F7 regressionsanalys antog vi att ε, ε,..., ε är oberoende likafördelade N(,σ Då
Residualanalys För modellen Johan Koskinen, Statistiska institutionen, Stockholms universitet Finansiell statistik, vt-5 F7 regressionsanalys antog vi att ε, ε,..., ε är oberoende likafördelade N(,σ Då
Tentamen på. Statistik och kvantitativa undersökningar STA101, 15 hp. Torsdagen den 22 mars TEN1, 9 hp
 MÄLARDALENS HÖGSKOLA Akademin för ekonomi, samhälle och teknik Statistik Tentamen på Statistik och kvantitativa undersökningar STA101, 15 hp Torsdagen den 22 mars 2018 TEN1, 9 hp Tillåtna hjälpmedel: Miniräknare
MÄLARDALENS HÖGSKOLA Akademin för ekonomi, samhälle och teknik Statistik Tentamen på Statistik och kvantitativa undersökningar STA101, 15 hp Torsdagen den 22 mars 2018 TEN1, 9 hp Tillåtna hjälpmedel: Miniräknare
MSG830 Statistisk analys och experimentplanering
 MSG830 Statistisk analys och experimentplanering Tentamen 20 Mars 2015, 8:30-12:30 Examinator: Staan Nilsson, telefon 073 5599 736, kommer till tentamenslokalen 9:30 och 11:30 Tillåtna hjälpmedel: Valfri
MSG830 Statistisk analys och experimentplanering Tentamen 20 Mars 2015, 8:30-12:30 Examinator: Staan Nilsson, telefon 073 5599 736, kommer till tentamenslokalen 9:30 och 11:30 Tillåtna hjälpmedel: Valfri
Att välja statistisk metod
 Att välja statistisk metod en översikt anpassad till kursen: Statistik och kvantitativa undersökningar 15 HP Vårterminen 2018 Lars Bohlin Innehåll Val av statistisk metod.... 2 1. Undersökning av en variabel...
Att välja statistisk metod en översikt anpassad till kursen: Statistik och kvantitativa undersökningar 15 HP Vårterminen 2018 Lars Bohlin Innehåll Val av statistisk metod.... 2 1. Undersökning av en variabel...
Envägs variansanalys (ANOVA) för test av olika väntevärde i flera grupper
 för test av olika väntevärde i flera grupper") Envägs variansanalys (ANOVA) för test av olika väntevärde i flera grupper Tobias Abenius February 21, 2012 Envägs variansanalys (ANOVA) I envägs variansanalys utnyttjas att
Envägs variansanalys (ANOVA) för test av olika väntevärde i flera grupper Tobias Abenius February 21, 2012 Envägs variansanalys (ANOVA) I envägs variansanalys utnyttjas att
Regressionsanalys. - en fråga om balans. Kimmo Sorjonen Sektionen för Psykologi Karolinska Institutet
 Regressionsanalys - en fråga om balans Kimmo Sorjonen Sektionen för Psykologi Karolinska Institutet Innehåll: 1. Enkel reg.analys 1.1. Data 1.2. Reg.linjen 1.3. Beta (β) 1.4. Signifikansprövning 1.5. Reg.
Regressionsanalys - en fråga om balans Kimmo Sorjonen Sektionen för Psykologi Karolinska Institutet Innehåll: 1. Enkel reg.analys 1.1. Data 1.2. Reg.linjen 1.3. Beta (β) 1.4. Signifikansprövning 1.5. Reg.
Föreläsning 4. NDAB01 Statistik; teori och tillämpning i biologi
 Föreläsning 4 Statistik; teori och tillämpning i biologi 1 Dagens föreläsning o Icke-parametriska test Mann-Whitneys test (kap 8.10 8.11) Wilcoxons test (kap 9.5) o Transformationer (kap 13) o Ev. Andelar
Föreläsning 4 Statistik; teori och tillämpning i biologi 1 Dagens föreläsning o Icke-parametriska test Mann-Whitneys test (kap 8.10 8.11) Wilcoxons test (kap 9.5) o Transformationer (kap 13) o Ev. Andelar
732G71 Statistik B. Föreläsning 1, kap Bertil Wegmann. IDA, Linköpings universitet. Bertil Wegmann (IDA, LiU) 732G71, Statistik B 1 / 20
 732G71, Statistik B 1 / 20") 732G71 Statistik B Föreläsning 1, kap. 3.1-3.7 Bertil Wegmann IDA, Linköpings universitet Bertil Wegmann (IDA, LiU) 732G71, Statistik B 1 / 20 Exempel, enkel linjär regressionsanalys Ett företag vill veta
732G71 Statistik B Föreläsning 1, kap. 3.1-3.7 Bertil Wegmann IDA, Linköpings universitet Bertil Wegmann (IDA, LiU) 732G71, Statistik B 1 / 20 Exempel, enkel linjär regressionsanalys Ett företag vill veta
Tentamentsskrivning: Matematisk Statistik med Metoder MVE490 1
 Tentamentsskrivning: Matematisk Statistik med Metoder MVE490 1 Tentamentsskrivning i Matematisk Statistik med Metoder MVE490 Tid: den 22 december, 2016 Examinatorer: Kerstin Wiklander och Erik Broman.
Tentamentsskrivning: Matematisk Statistik med Metoder MVE490 1 Tentamentsskrivning i Matematisk Statistik med Metoder MVE490 Tid: den 22 december, 2016 Examinatorer: Kerstin Wiklander och Erik Broman.
Matematisk statistik, Föreläsning 5
 Matematisk statistik, Föreläsning 5 Ove Edlund LTU 2011-12-09 Ove Edlund (LTU) Matematisk statistik, Föreläsning 5 2011-12-09 1 / 25 Laboration 4 Jobba i grupper med storlek 2 Ove Edlund (LTU) Matematisk
Matematisk statistik, Föreläsning 5 Ove Edlund LTU 2011-12-09 Ove Edlund (LTU) Matematisk statistik, Föreläsning 5 2011-12-09 1 / 25 Laboration 4 Jobba i grupper med storlek 2 Ove Edlund (LTU) Matematisk
F3 Introduktion Stickprov
 Utrotningshotad tandnoting i arktiska vatten Inferens om väntevärde baserat på medelvärde och standardavvikelse Matematik och statistik för biologer, 10 hp Tandnoting är en torskliknande fisk som lever
Utrotningshotad tandnoting i arktiska vatten Inferens om väntevärde baserat på medelvärde och standardavvikelse Matematik och statistik för biologer, 10 hp Tandnoting är en torskliknande fisk som lever
Tentamen på. Statistik och kvantitativa undersökningar STA100, 15 HP. Ten1 9 HP. 19 e augusti 2015
 MÄLARDALENS HÖGSKOLA Akademin för ekonomi, samhälle och teknik Statistik Tentamen på Statistik och kvantitativa undersökningar STA100, 15 HP Ten1 9 HP 19 e augusti 2015 Tillåtna hjälpmedel: Miniräknare
MÄLARDALENS HÖGSKOLA Akademin för ekonomi, samhälle och teknik Statistik Tentamen på Statistik och kvantitativa undersökningar STA100, 15 HP Ten1 9 HP 19 e augusti 2015 Tillåtna hjälpmedel: Miniräknare
Rättningstiden är i normalfall 15 arbetsdagar, till detta tillkommer upp till 5 arbetsdagar för administration, annars är det detta datum som gäller:
 Matematisk Statistik Provmoment: Ladokkod: Tentamen ges för: Tentamen 6.5 hp AT1MS1 DTEIN16h 7,5 högskolepoäng TentamensKod: Tentamensdatum: 1 juni 2017 Tid: 14-18 Hjälpmedel: Miniräknare Totalt antal
Matematisk Statistik Provmoment: Ladokkod: Tentamen ges för: Tentamen 6.5 hp AT1MS1 DTEIN16h 7,5 högskolepoäng TentamensKod: Tentamensdatum: 1 juni 2017 Tid: 14-18 Hjälpmedel: Miniräknare Totalt antal
Föreläsning 5. Kapitel 6, sid Inferens om en population
 Föreläsning 5 Kapitel 6, sid 153-185 Inferens om en population 2 Agenda Statistisk inferens om populationsmedelvärde Statistisk inferens om populationsandel Punktskattning Konfidensintervall Hypotesprövning
Föreläsning 5 Kapitel 6, sid 153-185 Inferens om en population 2 Agenda Statistisk inferens om populationsmedelvärde Statistisk inferens om populationsandel Punktskattning Konfidensintervall Hypotesprövning
Obligatorisk uppgift, del 1
 Obligatorisk uppgift, del 1 Uppgiften består av tre sannolikhetsproblem, som skall lösas med hjälp av miniräknare och tabellsamling. 1. Vid tillverkning av en produkt är felfrekvensen 0,02, dvs sannolikheten
Obligatorisk uppgift, del 1 Uppgiften består av tre sannolikhetsproblem, som skall lösas med hjälp av miniräknare och tabellsamling. 1. Vid tillverkning av en produkt är felfrekvensen 0,02, dvs sannolikheten
Föreläsning 12: Regression
 Föreläsning 12: Regression Matematisk statistik David Bolin Chalmers University of Technology Maj 15, 2014 Binomialfördelningen Låt X Bin(n, p). Vi observerar x och vill ha information om p. p = x/n är
Föreläsning 12: Regression Matematisk statistik David Bolin Chalmers University of Technology Maj 15, 2014 Binomialfördelningen Låt X Bin(n, p). Vi observerar x och vill ha information om p. p = x/n är
Föreläsning 1. Repetition av sannolikhetsteori. Patrik Zetterberg. 6 december 2012
 Föreläsning 1 Repetition av sannolikhetsteori Patrik Zetterberg 6 december 2012 1 / 28 Viktiga statistiska begrepp För att kunna förstå mer avancerade koncept under kursens gång är det viktigt att vi förstår
Föreläsning 1 Repetition av sannolikhetsteori Patrik Zetterberg 6 december 2012 1 / 28 Viktiga statistiska begrepp För att kunna förstå mer avancerade koncept under kursens gång är det viktigt att vi förstår
En scatterplot gjordes, och linjär regression utfördes därefter med följande hypoteser:
 1 Uppgiftsbeskrivning Syftet med denna laboration var att utifrån uppmätt data avgöra: (i) Om något samband finnes mellan kroppstemperatur och hjärtfrekvens. (ii) Om någon signifikant skillnad i sockerhalt
1 Uppgiftsbeskrivning Syftet med denna laboration var att utifrån uppmätt data avgöra: (i) Om något samband finnes mellan kroppstemperatur och hjärtfrekvens. (ii) Om någon signifikant skillnad i sockerhalt
Tentamen Statistik och dataanalys 1, 5p Institutionen för matematik, natur- och datavetenskap, Högskolan i Gävle
 Tentamen Statistik och dataanalys 1, 5p Institutionen för matematik, natur- och datavetenskap, Högskolan i Gävle Lärare: Mikael Elenius, 2006-08-25, kl:9-14 Betygsgränser: 65 poäng Väl Godkänt, 50 poäng
Tentamen Statistik och dataanalys 1, 5p Institutionen för matematik, natur- och datavetenskap, Högskolan i Gävle Lärare: Mikael Elenius, 2006-08-25, kl:9-14 Betygsgränser: 65 poäng Väl Godkänt, 50 poäng
Statistik 1 för biologer, logopeder och psykologer
 Innehåll 1 Hypotesprövning Innehåll Hypotesprövning 1 Hypotesprövning Inledande exempel Hypotesprövning Exempel. Vi är intresserade av en variabel X om vilken vi kan anta att den är (approximativt) normalfördelad
Innehåll 1 Hypotesprövning Innehåll Hypotesprövning 1 Hypotesprövning Inledande exempel Hypotesprövning Exempel. Vi är intresserade av en variabel X om vilken vi kan anta att den är (approximativt) normalfördelad
Korrelation och autokorrelation
 Korrelation och autokorrelation Låt oss begrunda uttrycket r = i=1 (x i x) (y i y) n i=1 (x i x) 2 n. i=1 (y i y) 2 De kvadratsummor kring de aritmetiska medelvärdena som står i nämnaren är alltid positiva.
Korrelation och autokorrelation Låt oss begrunda uttrycket r = i=1 (x i x) (y i y) n i=1 (x i x) 2 n. i=1 (y i y) 2 De kvadratsummor kring de aritmetiska medelvärdena som står i nämnaren är alltid positiva.
Regressionsanalys med SPSS Kimmo Sorjonen (2010)
") 1 Regressionsanalys med SPSS Kimmo Sorjonen (2010) 1. Multipel regression 1.1. Variabler I det aktuella exemplet ingår följande variabler: (1) life.sat, anger i vilket utsträckning man är nöjd med livet;
1 Regressionsanalys med SPSS Kimmo Sorjonen (2010) 1. Multipel regression 1.1. Variabler I det aktuella exemplet ingår följande variabler: (1) life.sat, anger i vilket utsträckning man är nöjd med livet;
MSG830 Statistisk analys och experimentplanering
 MSG830 Statistisk analys och experimentplanering Tentamen 16 April 2015, 8:30-12:30 Examinator: Staan Nilsson, telefon 073 5599 736, kommer till tentamenslokalen 9:30 och 11:30 Tillåtna hjälpmedel: Valfri
MSG830 Statistisk analys och experimentplanering Tentamen 16 April 2015, 8:30-12:30 Examinator: Staan Nilsson, telefon 073 5599 736, kommer till tentamenslokalen 9:30 och 11:30 Tillåtna hjälpmedel: Valfri
Medicinsk statistik II
 Medicinsk statistik II Läkarprogrammet T5 HT 2014 Susann Ullén FoU-centrum Skåne Skånes Universitetssjukhus Hypotesprövning Man sätter upp en nollhypotes (H0) och en mothypotes (H1) H0: Ingen effekt H1:
Medicinsk statistik II Läkarprogrammet T5 HT 2014 Susann Ullén FoU-centrum Skåne Skånes Universitetssjukhus Hypotesprövning Man sätter upp en nollhypotes (H0) och en mothypotes (H1) H0: Ingen effekt H1:
Parade och oparade test
 Parade och oparade test Andrew Hooker Division of Pharmacokinetics and Drug Therapy Department of Pharmaceutical Biosciences Uppsala University Hypotesprövning: möjliga jämförelser Jämförelser mot ett
Parade och oparade test Andrew Hooker Division of Pharmacokinetics and Drug Therapy Department of Pharmaceutical Biosciences Uppsala University Hypotesprövning: möjliga jämförelser Jämförelser mot ett