Prognostisering kontrollbesiktningar En rak väg eller en kurvig bana?
|
|
|
- Sebastian Magnusson
- för 8 år sedan
- Visningar:
Transkript

1 Kandidatuppsats Statistiska Institutionen Bachelor thesis, Department of Statistics Prognostisering kontrollbesiktningar En rak väg eller en kurvig bana? Forecasting vehicle inspections A straight road or a winding path? Milja Kohonen Självständigt arbete inom Statistik III, 15 högskolepoäng, HT 2012 Handledare: Göran Rundqvist

2 Innehållsförteckning Sammanfattning... iv Abstract... v 1. Inledning Marknad och utbud av kontrollbesiktningar Utbud av kontrollbesiktningar Syfte och problemformulering Avgränsningar Tidigare forskning och studier Teoretisk bakgrund - tidserieanalys och prognosmodeller Allmänt om tidserieanalys och prognosmetodik Utjämningsmetoder Ekvationsmodeller Box-Jenkins metod Användning av olika operatörer AR process MA process ARMA och SARIMA processer Övriga tidseriemodeller Metod Datamaterialet och datainsamling Analys av stationäritet Relevanta statistiska tester för stationäritet Olika faktorer som påverkar modellval Outliers - olika typer av extrema värden Modellval för Bilprovningens tidserier Överblick av olika prognosmodeller per län och per station Prognos och utvärdering av modellparametrar Allmänt om prognosfel Modellens förklaringsgrad Goodness-of-fit mått Jämförelse av prognosfel med konkurrerande modeller Allmänt om studiens resultat...35 ii

3 4.3. En säsongsbetingad enkel exponentiell utjämningsmodell Exponentiella utjämningsmetoder i jämförelse Winters additiva modell En säsongsbetingad slumpvandringsmodell utan drift Jämförelse mellan differentierade serier och den naiva prognosen Säsongsrensade MA modeller Jämförelse mellan olika SMA modeller och den naiva prognosen Olika autoregressiva modeller - AR, SAR, ISAR Jämförelse mellan SAR /ISAR modeller och den naiva prognosen Olika ARMA och ARIMA modeller ARMA/ARIMA modeller jämfört med den naiva prognosen Reflektioner angående prognosfelet Uppföljning av modellens prestanda Regionala skillnader finns dem? Diskussion Studiens slutsatser Det makroekonomiska perspektivet på fordonskontroller...53 Litteraturförteckning...55 Bilagor A. Bilprovningens ägare samt fordonsparkens utveckling B. Tidserieplottar per län ursprungliga dataserier per månad C. Plottdiagram samt ACF/PACF per län på säsongsrensade serier D. Ljung-Box Q statistik samt sammanställning av olika modeller som förekommer bland län och stationer E. Resultat angående modellens prestanda i olika modellgrupper iii

4 Sammanfattning Under de senaste åren har obligatoriska fordonskontroller övergått från monopol till en konkurrensutsatt marknad med nya och nygamla aktörer. Ett steg mot en fri och full konkurrens har varit avstyckning av och utförsäljning av två tredjedelar AB Svensk Bilprovningens stationsnät omfattande 216 besiktningsstationer. Att anpassa den nya Bilprovningen med en rikstäckande kedja på 89 stationsnät kommer att ställa nya krav på planering och optimering av verksamheten. För att upprätthålla kostnadseffektivitet och konkurrensförmåga behövs nya metoder för att optimera verksamheten när en del av de gamla skalfördelarna försvinner. I denna uppsats har Bilprovningens tidserier för kontrollbesiktning av personbilar studerats och analyserats för att hitta en lämplig prognosmodell för respektive län och station. Resultatet visar att både exponentiella utjämningsmetoder och säsongsbetingade ARIMA modeller kan användas för att prognostisera volym vid kontrollbesiktningar av personbilar. I studien diskuteras även betydelsen av outliers och huruvida hänsyn till dessa borde tas i analysen. Vidare har resultatet jämförts med en så kallad naiv prognos, det befintliga sättet som Bilprovningen använder i nuläget för framtagning av prognoser för kommande perioder. Denna jämförelse bekräftar att såväl exponentiella utjämningsmetoder som säsongsbetingade ARIMA modeller genererar betydligt lägre prognosfel såväl i absoluta tal som i procentuella termer för nästan samtliga stationer. Nyckelord: Tidserieanalys av fordonskontroller, trafiksäkerhet, kontrollbesiktning av personbilar, Bilprovningen, prognosmetoder, exponentiella utjämningsmetoder, enkel exponentiell utjämning med säsong, Winters additiva utjämningsmetod, Box-Jenkins metod, säsongsbetingade ARIMA modeller, SAR, SMA, ISAR, ARMA processer. iv

5 Abstract In recent years, the mandatory vehicle inspections have gradually shifted from a monopoly to a deregulated and competitive market with new and reinvented old actors. One step towards a free and full competition has been a sell-out of two thirds of AB Svensk Bilprovning network consisting of 216 control stations. Adapting the new organization with a nationwide network of 89 stations will set new requirements for the planning and optimization of business operations. In order to maintain its cost efficiency and competitiveness there is a need for new ways for forecasting business operations, especially when some of the previous economies of scale disappear. In this paper, the time series on the inspection of passenger cars of Bilprovningen have been studied and analyzed in order to find a suitable forecasting model for each county and station. The results show that the exponential smoothing methods and seasonal ARIMA models are suitable for forecasting the volume of vehicle inspections. The importance of outliers and whether these should be taken into account in the time series analysis is also discussed in this study. In addition, the results have been compared with a naive forecasting method, the current method used by Bilprovningen in forecasting the volume of vehicle inspections for upcoming periods. This comparison confirms that both the exponential smoothing methods and seasonal ARIMA models generate significantly lower forecasting errors both in absolute and in percentage terms for nearly all stations. Keywords: time series analysis of vehicle inspections, road safety, inspection of cars, Bilprovningen, forecasting methods, exponential smoothing methods, simple seasonal exponential smoothing, Winters additive smoothing method, Box-Jenkins method, seasonal ARIMA models, SAR, SMA, ISAR, ARMA processes. v

6 1. Inledning Time has wonderful way of showing us what really matters ~Margaret Peters~ Motorfordon som framförs på Sveriges vägar måste vara trafiksäkra och uppfylla specifika miljökrav. I Sverige blev fordonskontroller obligatoriska på 1960-talet som ett led i arbetet för bättre trafiksäkerhet och därmed minskning av antal trafikolyckor. Begreppet trafiksäkerhet är vid och kan omfatta flera infallsvinklar vad som menas med detta. I rapporten Trafiksäkerhetsutvecklingen i Sverige fram till år 2001 anges antal dödade och skadade i trafiken som mättal för de olika typerna av trafiksäkerhetsåtgärder (Nilsson, Andersson, Brüde, Larsson, & Thulin, 2002). Kontrollbesiktningen kan inte hindra förekomsten av trafikolyckor men fordonstekniska aspekter kan ha avgörande betydelse för utfallet av olyckan, det vill säga om personen allvarligt skadas eller till och med dödas vid en olycka. Fram till år 2010 hade AB Svensk Bilprovning (härefter kallad Bilprovningen) ensamrätt för obligatoriska fordonskontroller på lätta och tunga fordon. Bolagets omsättning var drygt 1,6 miljarder kronor år Största delen av intäkterna kommer från så kallade reglerade produkter, dvs. obligatoriska fordonskontroller. Kontrollbesiktning av personbilar är den största enskilda artikeln av samtliga fordonstyper och kontroller. Staten är majoritetsägare på Bilprovningen med sina 52 % av aktiekapitalet. Resten ägs av olika bilförsäkringsföretag och motorbranschorganisationer (se bilaga A, figur A.1). Bilprovningens monopol på periodiska fordonskontroller avskaffades formellt vid halvårsskiftet 2010 när privata aktörer tilläts ansöka ackreditering 1 för fordonskontroller. Sedan dess har tre större multinationella bolag etablerat sig på den 1 SWEDAC, Styrelsen för ackreditering och teknisk kontroll, beviljar tillstånd och agerar som tillsynsmyndighet inom en rad olika områden, bl.a. inom bilindustrin. 1

7 svenska besiktningsmarknaden, nämligen Carspect, DEKRA och Applus 2. Även tre lokala, privatägda aktörer har fått tillstånd för periodiska fordonskontroller, nämligen Ystad Bilbesiktning AB (YBB), Fordonsprovarna i Väst AB och det senaste tillskottet ClearCar AB. Samtliga företagen drivs av Bilprovningens före detta anställda. YBB riktar sig främst på registreringsbesiktningar av entusiastfordon och Fordonsprovarna i Väst har huvudfokus på obligatoriska kontroller av tunga fordon. Endast ClearCar AB konkurrerar i huvudsegmentet av obligatoriska fordonskontroller, nämligen kontrollbesiktningar av lätta fordon. I slutet av 2012 finns det cirka 268 besiktningsstationer i Sverige som erbjuder obligatoriska fordonskontroller (se tabell 1.1). Under 2011, cirka ett år efter avregleringen, beslutade regeringen vidare att en välfungerande konkurrens även kräver att Bilprovningens stationsnät på 216 stationer styckas i tre likvärdiga enheter och två av dessa säljs ut till andra aktörer. På hösten 2012 förvärvade Opus Prodox AB nordöstra gruppen medan försäljningen av den kvarvarande sydvästra gruppen är ännu inte avslutad. Tabell 1.1 Konkurrerande bolag inom obligatoriska fordonskontroller Bolag Stationer % andel Bilprovningen % Opus Prodox % Sydvästra gruppen % Carspect % Dekra 6 2 % Applus 5 2 % Övriga 4 1 % Totalt % 1.1. Marknad och utbud av kontrollbesiktningar Årligen besiktas närmare 3,5 miljoner personbilar i Sverige, vilket motsvarar cirka 80% av det trafikanmälda fordonsbeståndet. Sveriges fordonspark för personbilar har haft en nästan oavbruten tillväxt sedan mätningen påbörjades Det totala fordonsbeståndet består numera av 5,5 miljoner personbilar, varav runt en miljon bilar är avställda och resten är i trafik. Det 2 Carspect AB tillhör den finska koncernen A-Katsatus Group, Applus Bilprovning AB ingår i den globala besiktningskoncernen Applus Auto International och ägs av riskkapitalbolaget Carlyle Group samt DEKRA tillhör tyska DEKRA koncernen med bilbesiktningsverksamhet främst i centrala Europa. 2

8 finns en klar säsongsvariation i antal avställda personbilar. En del av dessa är säsongsfordon (t.ex. cabriolet) som ställs på under sommarmånaderna och återigen ställs av på hösten. Andel avställda personbilar är högst mellan november och mars månaderna och då står för cirka 20 % av fordonsbeståndet för att sjunka några procentenheter under våren och sommarmånaderna när säsongsbilarna tas i bruk. Antal bilar i trafik har ökat med 1,1 % i genomsnitt mellan januari 2006 och augusti Ökning beror främst på att antal nyregistreringar är större än avregistreringar (t.ex. skrotningar och utförda ur register), vilket också påverkar att det blir ett kontinuerligt nettotillskott i fordonsparken (se bilaga A, figur A.2) Utbud av kontrollbesiktningar En fri och full konkurrens i kontrollbesiktningar kan presenteras som en jämvikt mellan utbudet och efterfrågan. I denna uppsats används Sveriges officiella län och kommunindelning för att beskriva utbudet av kontrollbesiktningar som representeras av antal stationer i ett begränsat geografiskt område. Fordonsbeståndet inom en kommun eller ett län representerar den andra marknadsfaktorn, nämligen efterfrågan. Sverige är delad i 21 län och 290 kommuner. För tillfället saknar 111 kommuner (39%) en besiktningsstation inom sina kommungränser. I de flesta av dessa kommuner utan besiktningsstation var fordonsbeståndet mindre än personbilar i slutet av år Fem kommuner 3 har över registrerade personbilar utan att ha en etablerad besiktningsstation inom kommunen. Av olika besiktningsföretag har endast Bilprovningen med sina 89 stationer minst en station i varje län. Att ha en rikstäckande kedja är naturligtvis en tillgång för företaget att kunna erbjuda sina tjänster även i glesbygden och i mindre kommuner. Samtidigt är det svårare att upprätthålla en kostnadseffektiv verksamhetsstruktur baserad på skalfördelar med en kedja av små stationer utspridda över hela landet. Malmö betraktas ofta som en tillväxtregion tillsammans med Stockholm, Göteborg, Helsingborg, Linköping och övriga stora städer. Faktum är att fordonsbeståndet minskade med 9,4 % i Malmö kommun och ökade med 33,6 % i närliggande Lunds kommun mellan åren 2010 och Detta indikerar att det finns en förflyttning från 3 Värmdö, Lerum, Vellinge, Kävlinge och Härryda 3

9 storstäderna till omgivande kommuner eller att storstäderna "breder ut sig till närliggande kommuner. Den geografiska fördelningen per kommun är en viktig faktor i modellen eftersom majoriteten av personbilarna besiktas inom den kommunen där ägaren är bosatt eller verksam. I storstadsregioner, glesbygd samt bland de kommuner som saknar en besiktningsstation är länet den näst största geografiska fördelningen som styr efterfrågan mellan stationerna Syfte och problemformulering Volymutvecklingen på kontrollbesiktningar av personbilar har varit relativt stabil under de tidigare åren innan avregleringen. Volymvariation har påverkats till en viss del av exogena faktorer som till exempel förändringar i fordonsbeståndet eller gällande föreskrifter 4 vad avser obligatoriska fordonskontroller. Det legala ramverket styr hur och när fordonet skall kontrollbesiktigas. Huvudregeln för personbilar är att dessa skall besiktas för första gången cirka tre år efter att fordonet togs i bruk, nästa gång vid fem års ålder och därefter årligen. Kontrollbesiktning av personbilar är slutsifferstyrd, vilket betyder att slutsiffran i registreringsnummer anger bilens inställelsemånad och när kontrollbesiktning skall ske. En inställelsetermin är fem månader lång och sträcker sig två månader före och två månader efter fordonets inställelsemånad. Vissa fordon omfattas av särskilda besiktningsregler 5 och skall kontrollbesiktas årligen. De endogena faktorer som påverkar volymen är verksamhetsrelaterade faktorer som antal stationer, antal banor för olika fordonstyper, öppettider, bemanning och kompetens. Alla dessa faktorer påverkar kapaciteten och genom tillgänglighet har Bilprovningen delvis kunnat styra efterfrågan under åren med monopol. Efter avregleringen och utförsäljningen av 2/3 av Bilprovningens stationsnät kommer bolaget förlora en del information om marknaden, vilket naturligtvis påverkar 4 I Fordonsförordningen 2. Kap finns bestämmelser om fordonets beskaffenhet och utrustning. Fordonet skall vara tillförlitlig ur säkerhetssynpunkt samt uppfylla miljömässiga krav för att kunna trafikeras på vägarna. Vidare anges i 1. Kap. 1. allmänna bestämmelser vad avser besiktningsorgan som bedriver verksamhet inom fordonskontroll (SFS 2009:211) 5 Till dessa hör bland annat utryckningsfordon, hyrbilar, trafikskolebilar och bilar som används för yrkesmässig personbefordran. 4

10 produktionsplaneringen. I en fri konkurrenssituation kommer det att vara avgörande att kunna genomföra samma verksamhet i en mindre skala utan att förlora effektivitet och skalfördelar som tidigare stationsnätet på 216 stationer medförde. Avregleringen öppnar upp nya möjligheter för Bilprovningen men ställer samtidigt stora krav på organisationen att anpassa sig till full konkurrens något som Bilprovningen inte behövt fundera över under de fem decennier som bolaget har existerat. Ur konkurrenssynpunkt de utmaningar som Bilprovningen har på besiktningsmarknaden kan jämföras med situationen i flygbranschen där SAS har betydande svårigheter att anpassa sin verksamhet och organisation för att effektivt konkurrera med lågprisflygbolag. Det är enklare att expandera verksamhet som byggs från grunden på en kostnadseffektiv struktur än att skala ner verksamhet och behålla kostnadseffektivitet som delvis bygger på skalfördelar. Det primära syftet med denna uppsats är att förstå och beskriva den datagenereringsprocess som ligger bakom kontrollbesiktningar av personbilar. Kunskap om detta kan ge nya insikter hur marknaden utvecklas i olika geografiska områden och således minska det informationstappet som omstrukturering av besiktningsmarknaden innebär. Genom att studera tidserier kan man beskriva volymutvecklingen i en komprimerad matematisk modell med hjälp av de komponenter som bäst förklarar dataseriens byggstenar. Med hjälp av denna modell kan man sedan skapa en realistisk prognos eller prediktion om framtiden. Vidare reflekteras över vilka gemensamma nämnare och eventuella skillnader som kan finnas mellan olika geografiska områden. Slutligen, baserad på tidserieanalys genereras en prognosmodell för respektive län och station. I denna del diskuteras hur väl de framtagna modellerna lämpar sig till prognossyfte av kontrollbesiktningar Avgränsningar I denna uppsats behandlas endast kontrollbesiktningar på personbilar, vilket genererar den största volymen och även intäkterna av samtliga obligatoriska fordonskontroller som årligen genomförs i Sverige. Andra fordonstyper och fordonskontroller lämnas utanför denna studie och analys, främst på grund av att volymer på dessa kontroller är relativt små jämfört med personbilar och styrs även av 5

11 andra faktorer och regler. Vidare behandlas endast den nya Bilprovningens stationer, dvs. de 89 stationer som finns kvar i bolaget när utförsäljningen av den kvarstående delen (sydvästra gruppen) är avslutad. Det vore naturligtvis önskvärt att skapa en multivariat modell som tar hänsyn samtliga fordonstyper och/eller olika produktgrupper. Men ytterligare olika fordonstyper (lastbil, buss, motorcykel osv.) ökar komplexiteten av en prognosmodell eftersom säsongsfordon, t.ex. motorcyklar och bildragna släp påverkar kapaciteten och tillgängligheten av kontrollbesiktningar vissa månader. Dessutom varierar det legala ramverket mellan olika fordonstyper. Olika produktgrupper (reglerade och oreglerade produkter) är en annan aspekt som skulle kräva en multivariat tidserieanalys. En sådan studie är för omfattande för en kandidatuppsats på 15 högskolepoäng Tidigare forskning och studier Det finns en uppsjö av studier, artiklar, rapporter och litteratur som relaterar till olika typer av tidserieanalyser och prognosmodeller. Däremot finns det få studier och tidserieanalyser med fokus på volymutvecklingen på enkom obligatoriska fordonskontroller. Fordonsrelaterade tidserieanalyser och forskning har naturligtvis ett stort samhällsekonomisk intresse för transportsektor, beslutsfattare och fordonstillverkare. Vanligen relaterar dessa till olika fordonstekniska aspekter, transporter, infrastruktur- eller miljörelaterade frågor. Volymbaserade tidserieanalyser eller studier om obligatoriska fordonskontroller kunde inte heller hittas i grannländerna som har avreglerat sina besiktningsmarknader för flera år sedan. I Finland konkurrensutsattes besiktningsmarknaden mellan och det statliga besiktningsbolaget såldes år I Danmark avreglerades besiktningsmarknaden år 2005 (Eriksson, 2011). Även om de avreglerade nordiska och övriga länderna har studerats noggrant i samband med den svenska avregleringen av fordonsbesiktningen har fokus på dessa studier främst varit hur den svenska besiktningsmarknaden utvecklas före och efter monopolen. Transportsektor, myndigheter och olika forskningsinstitut producerar mycket material vad gäller trafiksäkerhet och med avseende på de olika direkta och indirekta 6
 ökar komplexiteten av en prognosmodell eftersom säsongsfordon, t.ex. motorcyklar och bildragna släp påverkar kapaciteten och tillgängligheten av kontrollbesiktningar vissa månader.")
12 faktorer som påverkar trafiksäkerhetsutvecklingen i Sverige. Väg- och Transportforskningsinstitutet (VTI) använder tidserie- och regressionsmodeller för att följa trafiksäkerhetsutvecklingen och för att göra prognoser om dödsriskfaktorer. Man har bland annat gjort beräkningar hur mycket utglesning av intervallet från a) 2 till 3 år för den första och b) 4 till 5 år för den andra obligatoriska kontrollbesiktningen och c) därefter årligen påverkar på antalet fordonsfel i fordonsparken. Ett ökat antal fordonsfel medför att olycksrisken ökar och effekten syns i antal dödade eller skadade i trafiken på grund av fordonsfel (Nilsson, Andersson, Brüde, Larsson, & Thulin, 2002). Fordonskontroller verkar även ha varit en sluten värld eller av icke-intresse för uppsatsskrivande studenter. En sökning bland uppsatser 6 från svenska högskolor resulterade totalt fyra uppsatser. Endast en uppsats handlade om den avreglerade marknaden ur konkurrensperspektiv och det nya läget för Bilprovningen. Man kan konstatera att tidserieanalys på fordonskontroller generellt sett är ett lite studerat område. Man kan hitta en mängd olika intressanta infallsvinklar på ämnet, speciellt hur dessa kan återkopplas till det makroekonomiska perspektivet av trafiksäkerheten. Några tankar lyfts upp i diskussionsdelen i kapitel 5. 6 En sökning på Internet på den 24/09/2012 gjordes med följande sökorden kontrollbesiktning, fordonskontroller, fordonsbesiktning, Bilprovningen. 7


13 2. Teoretisk bakgrund - tidserieanalys och prognosmodeller 2.1. Allmänt om tidserieanalys och prognosmetodik Tidserier erbjuder ett bra underlag för en prognosmodell och används bland annat för planering av operativ verksamhet (Montgomery, Jennings, & Kulachi, 2008). Montgomery (2008) m.fl. delar prognosprocess till sju olika sammanlänkade faser (se figur 2.1) som börjar från problemformulering och avslutar med uppföljning av prognosmodellens prestanda, det vill säga huruvida modellen kan skapa ändamålsenliga prognoser. Denna studie följer detta ramverk ganska väl och således ger också strukturen för uppsatsens uppbyggnad. Figur 2.1 Flöde i en prognosprocess enligt Montgomery, Jennings & Kulachi (2008) Bilprovnigens data : kontrollbesiktningar av personbilar under jan sept 2012 Utjämningsmetoder? ARIMA modeller? Betydelse av outliers? Tillämpning av valda modeller Kan kontrollbesiktningar av personbilar prognostiseras med tidserier? Vilken typ av modell passar bäst till data? IBM SPSS 20 Undersökning av tidseriens stationäritet Korrelogram Undersökning av prognosfel Standardiserade statistiska mått: - MSE - MAPE - MAE - Förklaringsgrad R 2 - BIC, AIC, SIC, P-P plott Shewhart, CUSUM, EWMA kvalitetskontroll av prognosfelet Enligt Wikipedia 7 används begreppet tidserier i statistiska sammanhang för att beskriva en sekvens av datapunkter som mäts vid successiva tidpunkter och som är åtskilda från varandra med en likformig tidsintervall. Med en tidserieanalys menas de 7 hämtad 18/09/2012 8
 som börjar från problemformulering och avslutar med uppföljning av prognosmodellens prestanda, det vill säga huruvida modellen kan skapa ändamålsenliga prognoser.")
14 metoder som används för att analysera kronologiskt organiserad data för att hitta de egenskaper i data och en modell som har bäst förmåga att beskriva eller förklara mönstret i dataserien. Detta mönster eller tidsbunden variation kan bestå av en eller flera olika komponenter. I tidserieanalys nämns vanligen om fyra komponenter som kan variera över tiden, nämligen trend, konjunktur, säsong och slump. (Stockhammar, 2002). Trend kan beskrivas som en långsam, successivt ökande eller avtagande variation i dataserien och uppstår när tidseriens observationer är korrelerade med varandra. Ofta utgår man ifrån att dessa nivåvariationer genereras av en viss typ av linjär process som antingen kan vara en deterministisk eller stokastiskt trend. I praktiken kan det vara svårt att explicit klassificera om en tidserie bygger på en deterministisk eller en stokastisk trendkomponent. En gemensam nämnare är att båda är icke-stationära processer men kan bygga på annorlunda linjära strukturer. Säsongsvariation är ett kortsiktigt och framför allt periodiskt återkommande mönster som uppstår kring trendlinjen. Konjunktur 8 ger betydligt långsammare svängningar i dataserien. Begreppet att svårare beskriva i statistiska termer eftersom konjunktur förknippas och definieras med makroekonomiska termer. Något förenklat kunde man beskriva att dessa långsamma svängningar får trenden att byta riktning till motsatta bana eller t.o.m. orsaka ett trendbrott där trenden skiftar plötsligt till ett nytt läge och därefter skapar en ny trendlinje som kan beskrivas med någon prognosmodell. Konjunkturläge påverkar naturligtvis fordonsindustrin, speciellt vad avser nybilsförsäljningen och därmed med några års fördröjning antal kontrollbesiktningar som görs på nya bilar. Effekten är dock minimal på grund av den låga andelen av nya bilar som kontrollbesiktas årligen. För att kunna urskilja hur mycket konjunktursvängningar påverkar besiktningsvolymen krävs ett betydligt längre tidsperspektiv än vad denna studie baserar sig på. Därmed trend, säsong och slumpmässig variation är huvudsakliga komponenter av de olika tidseriemodeller som tagits fram i denna studie. 8 Enligt Konjunkturinstitutet, konjunkturcykeln är en 3-8 år lång återkommande variation i ekonomisk aktivitet i förhållande till trend eller jämviktsnivå. Ekonomisk aktivitet mäts normalt i BNP tillväxt (Konjukturterminologi, Konjunkturinsitutet) 9

15 I bilaga A, figur A.2 visas fordonsbeståndets utveckling mellan Bilden visar hur fordonsparken har en kontinuerlig växande trend som påverkas av säsongsvariationen i både antal personbilar i trafik och antal avställda. Båda dessa delkomponenter av fordonsparken visar också en svag ökande linjär trend. I antal avställda ser man även en klar säsongsvariation kring trendlinjen. I matematiska termer fordonsbeståndets volymutveckling kan beskrivas som tidserie bestående av trend, säsong ( )och slumpmässig variation vid tidpunkt (se formel 2-1). Formel 2-1 Mönstret i tidserien eller successiva observationer kan således beskrivas som en matematisk modell i syfte för att beskriva data i mer förenklat format men även för att kunna räkna estimat framåt i tiden. Med prognos menas vanligen att man använder en modell som bygger på historiska datavärden för att kunna framskriva värden på kommande observationer. De vanligaste modellerna som används i prognossyfte är 1) utjämningsmetoder, bland annat glidande medelvärde, Holts och Winters metoder, 2) enkla ekvationsmodeller såsom enkel linjär, icke-linjär eller logistisk regressionsmodell 3) simultana ekvationsmodeller 4) ARIMA modeller och 5) VAR modeller (Gurajati & Porter, 2009). Dessa metoder beskrivs kortfattad under nästkommande sektioner i detta kapitel Utjämningsmetoder En grundläggande tanke bakom olika utjämningsmetoder är att reducera tidseriens slumpmässiga variation för att analysera serien i ett mer utjämnat format eller för att skapa en prognos för kommande period(er). En dataserie anses bestå av minst två komponenter: a) signal och b) brus där signal representerar det underliggande mönstret i dataserien och brus är de slumpmässiga variationerna eller avvikelserna från detta mönster (Montgomery, Jennings, & Kulachi, 2008). Den enklaste formen av en dataserie är en konstant process som kan matematiskt beskrivas enligt formel
och slumpmässig variation vid tidpunkt (se formel 2-1).")
16 Formel 2-2 där medelvärdet representerar en konstant signal och en felterm eller brus vid tidpunkt. Syftet med en utjämningsteknik är att separera signal och brus från varandra så att det underliggande mönstret i dataserien kan tydliggöras och således få en skattning för signalen. (Montgomery, Jennings, & Kulachi, 2008). Feltermen kallas för vitt brus, när dess väntevärde är 0 och variansen konstant, dvs. När en serie av feltermer är oberoende, normalfördelade och deras statistiska egenskaper inte förändras över tiden, dvs., fyller tidserien även villkoren för strikt stationäritet (Gurajati & Porter, 2009). Den enklaste formen av utjämning är glidande medelvärde (eng. moving average eller MA) där ett antal successiva observationer inom ett kontinuum N utjämnas med k antal perioder där k >1. Det utjämnade medelvärdet, MA, vid tidpunkt beräknas enligt formel 2-3. Formel 2-3 Fördelen med glidande medelvärde är att det är enkelt att använda och har mindre varians tack vare utjämningseffekten jämfört med den ursprungliga dataserien. Valet av påverkar den utjämnade dataserien. Ju mindre värde får, desto mindre blir utjämningseffekten och således ökar även variansen på dataserien. Ett litet däremot fångar snabbare upp de senaste förändringarna i dataserien. Nackdelen med glidande medelvärde är att denna metod resulterar ett prognosvärde som är lika med det senaste medelvärdet för antal perioder tillbaka i tiden. Trots att enskilda observationer är oberoende är de utjämnade medelvärdena autokorrelerade med varandra eftersom två successiva medelvärden delar samma observationer (Montgomery, Jennings, & Kulachi, 2008). Glidande medelvärdesprocess även används 11

17 i Box-Jenkins metodik för att jämna ut de slumpmässiga variationerna (feltermerna) för att få en bättre anpassning till data. Mer om denna process beskrivs i sektion 2.4. Exponentiella utjämningsmetoder är ett annat sätt att åstadkomma en utjämningseffekt på tidserien. Dessa metoder bygger på tre olika utjämningskonstanter som är avsedda att jämna ut nivåvariation eller, trend och/eller säsongsvariation. Samtliga utjämningskonstanter anges ett värde mellan 0 och 1, dvs.. Vilka utjämningsparametrar finns med i modellen beror på vilka av dessa tre olika komponenter (trend, säsong, slump) finns med i tidserien. I en enkel exponentiell utjämning antas att varken trend eller säsongskomponent påverkar tidserien. Prognosmodellen kan således beskrivas som en linjär funktion av nivå och slumpmässig variation eller brus vid tidpunkt i likhet med en konstant process som beskrivs i formel 2-2. Enligt Montgomery (2008) m.fl. rekommenderas ofta ett värde mellan 0,1 och 0,4 för nivåparameter för bästa resultat. Utjämningskonstanten, där, kan härledas från summan av viktade observationer där vikten är geometrisk avtagande (minskar) ju längre tillbaka tiden vi går. Ju lägre vikt som läggs på utjämningsparametern, desto större vikt får de tidigare observationerna i dataserien. Det finns även en enkel exponentiellt utjämningsalgoritm som tar hänsyn till säsongskomponenten i serien. Denna metod är lämplig när dataserien inte visar trend men däremot återkommande periodisk säsongsvariation. Den datagenererande processen är baserad på följande linjära modell (se formel 2-4): Formel 2-4 där representerar seriens konstanta medelvärde eller nivå, säsongsvariation samt är en felterm eller en slumpmässig variation vid tidpunkt. SPSS 20 använder formel (2-5) för en enkel säsongsbetingad exponentiell utjämning som bygger på två utjämningsparametrar, och, och där den första används för nivån och den andra för utjämningen av säsongsvariationen. 12

18 Formel 2-5 Det utjämnade värdet fås genom att summera nivå med säsongskomponenten, dvs.. När en dataserie innehåller en linjär trend, kan en dubbel exponentiell utjämningsmetod vara en bättre teoretisk modell att utgå ifrån. Denna metod är känd även som Holts metod och innehåller två utjämningsparametrar, en för nivå och en för trend. Modellen är en linjär trend modell och den generella formen kan matematiskt utryckas enligt formel 2-6. Formel 2-6 där representerar nivån och är parameter för trendkomponent vid tidpunkt. Winters metod är en utvidgning av Holts metod, även känd som Holt-Winters metod. Utöver nivån och trendkomponenten tar denna metod hänsyn till säsongsvariationen som utjämnas med hjälp av en säsongsparameter delta. Det finns två olika varianter av Winters metod som kallas den additiva respektive multiplikativa metoden. Skillnaden mellan dessa två metoder är att i den additiva modellen antas säsongsvariationen vara konstant från en cykel till en annan medan i den multiplikativa modellen är säsongssvängningarna proportionella mot storleken av data. Nivå och trend skattas på samma sätt i båda Winters metoder. Däremot skiljer sig beräkningsgrunderna åt mellan de additiva och multiplikativa metoderna vad avser säsongsvariationen samt framskrivningen av värden (prognos). Fomby (2008) skriver att exponentiella utjämningsmetoder har ersatts som prognosverktyg med Box-Jenkins metoder. En orsak till detta är att exponentiella utjämningsmetoder numera betraktas som en speciell undergrupp och klass av ARIMA modeller. En svaghet hos utjämningsmetoder är att det inte finns något objektivt identifierings- och utvärderingssystem att jämföra olika utjämningsmetoder och deras 13

19 Trend Säsong prestanda. Valet av utjämningskonstanter till exempel bestäms subjektivt enligt anpassning av data snarare än genom en hypotes som sedan testas med lämpliga statistiska metoder (Fomby, 2008). Alla utjämningsmodeller kan även uttryckas i ARIMA termer. I tabell 2.1 anges vilken typ av ARIMA modell motsvarar de vanligaste utjämningsmetoder beroende på om serien innehåller trend och/eller säsongsvariation. Tabell 2.1 Modellmotsvarighet mellan olika utjämningsmetoder och säsongsbetingade ARIMA modeller, källa: Fomby (2008) Utjämningsmetod Linjär modell SARIMA (p,d,q)(p,d,q) Linjär modell SARIMA med bakåtoperator Enkel exponentiell utjämning = + IMA (0,1,1) (1 B) = (1 θb) Nej Nej Dubbel exponentiell utjämning (Holts metod) = IMA (0,2,2) (1 B) 2 = (1 θb) 2 Ja Nej Enkel exponentiell säsongsutjämning = +,s + IMA (0,1,s+1)(0,1,0)s P+1 1 B (1 B) s = (1 θ B ) Nej Ja =1 Winters additiva metod = + 1 +,s + IMA (0,1,s+1)(0,1,0)s P+1 1 B (1 B) s = (1 θ B ) Ja Ja = Ekvationsmodeller Olika typer av regressionsmodeller används flitigt i tidserieanalyser och prognostisering. Dessa kan vara univariata eller multivariata modeller och regressionen kan vara baserad till exempel på linjär, icke-linjär eller någon form av logistiskt samband över tiden. Även mer komplexa simultana ekvationsmodeller används bland annat för att beskriva någon makro- eller mikroekonomisk fenomen när interaktion mellan de olika variablerna är av mer dynamisk karaktär. Ekvationsmodeller kommer väl till pass när man skall beskriva en prognosmodell i mer specifika matematiska termer Box-Jenkins metod George Box och Gwilym Jenkins revolutionerade tänkandet inom tidserieanalys och prognostisering med sin bok Time Series: Forecasting and Control som publicerades 14

20 1970. Den grundläggande idén bakom denna metod är att data talar för sig själv vilken modell kan bäst anpassas till dataserien. Metodiken omfattar fyra iterativa steg: 1) identifiering av modellens initiala komponenter, 2) skattning av modellparametrar, 3) analys och test av parametrarna i den valda modellen och 4) prognos för framtida värden (Yaffee & McGee, 2000). Tre processer i olika kombinationer är prognosmodellens byggstenar. Dessa är en autoregressiv process (AR), en glidande medelvärdes (MA) process och differentiering (I). En prognosmodell kan innehålla olika kombinationer av dessa beroende på hur många autoregressiva och glidande medelvärdestermer slutligen inkorporeras i modellen för att få bäst anpassning till data. Differentiering av den ursprungliga dataserien görs för att uppnå stationäritet innan de övriga komponenterna kan läggas på modellen. En akronym för Box-Jenkings metodik är ARIMA modeller och anges med en generell notation (p, d, q) där p står för antal autoregressiva (AR) termer d står för antal icke-säsongsbetingade differenser (I) q står för antal glidande medelvärdestermer (MA) Utgångspunkten för ett modellval är att en tidserie skall vara stationär, vilket enligt Box-Jenkings metodik refereras som d(i) ordningens transformation av serien. Om tidserien är stationär, pratar man att den är differentierad mellan 0 ordning, betecknad med. En stationär tidserie fluktuerar runt sitt långsiktiga medelvärde (eng. mean reverting process) samt uppfyller de formella villkoren för stationäritet. Dessa diskuteras vidare under analys av stationäritet i sektion 3.2. Säsongsvariation är också viktigt att identifiera, eftersom ARIMA modeller delas i två huvudgrupper: säsongs- och icke-säsongsbetingade. Om säsongsvariation inkluderas i modeller pratar man ofta om SARIMA modeller. En generell SARIMA modell beskrivs närmare i sektion
, en glidande medelvärdes (MA) process och differentiering (I).")
21 Användning av olika operatörer Bakåtoperator och differensoperator används frekvent för att beskriva och förenkla den linjära modellen av olika ARIMA komponenter. Box och Jenkings använder B som bakåtoperator för att beteckna värde av variabel vid tidpunkt, dvs. B. Symbol (nabla) betecknar en differensoperator och används för att beskriva skillnaden mellan två successiva tidsperioder och. Således,, vilket kan även skrivas med hjälp av bakåtoperator B som B. En exponentiell beteckning med en bakåt- eller differensoperator beskriver vilket tidsavstånd respektive differentiering har tillämpats på data. Till exempel notation B och andra ordningens differens anges med B B B B. Vidare kan man även ta differensen för en specifik lag, då noteras detta som AR process AR(p) process anger den autoregressiva komponenten i tidserien där (p) står för antal autoregressiva termer som inkluderas i modellen. Begreppet autoregressiv syftar på att en tidserie beskrivs som en linjär funktion av variabelns historiska värden. I en vanlig linjär regressionsmodell beskrivs den beroende variabeln normalt som en funktion av någon annan oberoende variabel (Janacek & Swift, 1993). En generell notation för en AR (p) process kan således skrivas som funktion av tidseriens laggade värden samt en slumpmässig variation ( och anges i formel 2-7. Koefficient anger vilken portion av det laggade värdet förs över till nästkommande period. Formel 2-7 För att skall vara stationär process skall rötterna som den karakteristiska ekvationen har alla vara mindre än 1 (Mills, 2011). Summan av koefficienterna anger om serien är stationär. Villkoren för stationäritet 16
22 kan således granskas i en AR process att summan av modellparametrarna ( mindre än ett. är MA process MA process fokuserar på tidseriens feltermer eftersom en tidserie kan antas vara en konstant process som består av signal (konstant) och vitt brus. Genom att ta hänsyn till effekten av den slumpmässiga variationen från föregående period(er) i någon proportion som anges med koefficient θ, får man fram en generell notation av en MA (q) process. Matematiskt kan processen för en stokastisk tidserie beskrivas som en linjär funktion eller med hjälp av bakåtoperator (se formel 2-8 härefter). Formel 2-8 θ θ eller θ B θ B θ B B där representerar konstant, representerar vitt brus och B är en förkortad version av θ B. En MA(q) process är alltid stationär, eftersom, dvs. väntevärdet för de slumpmässiga och oberoende feltermerna är noll. Däremot är processen inte alltid inverterbar till en AR (p) process vilket är det formella villkoret för en MA (q) process. Med invertibilitet menas att den slumpmässiga variationen även kan presenteras som en serie av autoregressiva termer. En MA (1) process är inverterbar till en oändlig serie av historiska observationer som är viktade enligt den geometriskt avtagande koefficienten θ. Processen förutsätter att denna oändliga serie kan konvergeras till slumptermen. Ekvationen i 2-9 uppfyller konvergeringskriteriet om den glidande medelvärdeskoefficienten är mindre än ett, dvs. θ (Yaffee & McGee, 2000). Formel 2-9 θ θ B θ B 17
23 θ B θ B θ B θ θ θ ARMA och SARIMA processer En tidserie som genereras av en ARMA (p,q) process omfattar p antal autoregressiva termer och q antal utjämnade slumptermer. Med konstant kan processen skrivas som en linjär representation eller i ett mer kompakt format med hjälp av bakåtoperatorn. I formel 2-10 anges en generell representation av en ARMA (p, q) process. Formel 2-10 θ θ θ B B där B respektive B är förkortade versioner av B för den autoregressiva processen samt θ B för den slumpmässiga variationen. SARIMA modeller anges med notation (p,d,q)x(p,d,q)s. En kompakt representation anges i formel 2-11 av den generella modellen där s anger säsongslängden samt bakåtoperator betecknar de förkortade summor av autoregressiva och medelvärdesprocesser för (p, q) på samma sätt som presenterades i formel Formel 2-11 B B B B B B T.ex. B B skall användas för månadsdata om säsongslängden är satt till ett år. Första differensen på säsongen kan därmed skrivas som B. På liknande sätt laggas säsongskomponent B enligt säsongslängden från föregående period in den proportionen som säsongskoefficienterna ( anger. I praktiken laggas säsongskomponenterna högst en säsongslängd bakåt i tiden. 18
24 En SAR process måste vara stationär både i den ordinarie- och säsongsdelen, vilket innebär att båda AR koefficienterna måste ligga inom intervallet (Box, Jenkins, & Reinsel, 2008). Även MA koefficienternas absolutvärde skall i likhet med AR process vara mindre än 1, dvs. θ θ på grund av konvergeringskriteriet Övriga tidseriemodeller Det finns en mängd olika ARIMA variationer beroende på vilken typ av tidserier som skall analyseras. ARCH/GARCH modeller används ofta i finansiella tidserier varför de även kallas för volatilitetsmodeller. Fokus på dessa modeller ligger på den betingade heteroskedastiska feltermen som antas följa någon struktur som är resultat av variansen från föregående period(er). När feltermens varians följer ARMA (p,q) process kallas modellen GARCH (eng. generalized autoregressive conditional heteroscedasticy). Multivariata tidserieanalyser kallas ofta för VAR modeller, dvs. vektor autoregressiva modeller som bygger på flera endogena men relaterade tidserier. Metoden påminner om simultana ekvationsmodeller där flera endogena variabler analyseras tillsammans för att undersöka interaktionen mellan de enskilda men samverkande tidserierna (Gurajati & Porter, 2009). Det finns även så kallade transfer function eller intervention modeller som fångar upp när det sker förändringar på input variabel som ändrar output variabeln på något sätt. I SPSS kan man laborera med olika transfer funktioner när man anger ARIMA parametrar för modellen. I denna uppsats har jag följt principen av Ockhams rakkniv som enligt Wikipedia 9 innebär att man inte ska anta fler företeelser eller ting än som behövs för att förklara de observationer man gör. Jag har därför studerat tidserierna med utgångspunkt att hitta den enklaste möjliga strukturen som kan förklara den underliggande datagenereringsprocessen i kontrollbesiktningar. 9 hämtad

25 3. Metod 3.1. Datamaterialet och datainsamling Bilprovningen har gett tillgång till rådata bestående av antal besiktade personbilar per dag och per station från och med januari 2007 fram till oktober Sedan 2007 har Bilprovningen öppnat årligen 2-4 nya stationer och har för närvarande 89 stationer i Figur 3.1 Årlig besiktningsvolym samt antal stationer från år 2007 fram till oktober 2012 Sverige. Besiktningsvolym samt antal stationer anges i figur 3.1. Data har bearbetats till månadsvolymer per station för att skapa en meningsfull enhet för prognosmodellen samt för att lättare kunna analysera materialet. Vidare har månadsdata från olika stationer summerats ihop per län för att undersöka om det finns geografiska skillnader mellan olika regioner men även för att kunna presentera metodiken och samtidigt skydda känslig stationsdata. Tidserierna har analyserats med hjälp av IBM SPSS Statistics 20. Box-Jenkins metodik utgår ifrån att observationerna är successiva och ligger med samma tidsavstånd från varandra och att inga värden saknas i tidserien. Vidare rekommenderas ofta i litteraturen att tidserien skall omfatta minst 50 observationer för att skapa en bra prognosmodell (Yaffee & McGee, 2000). Av samtliga Bilprovningens 89 stationer har 73 stycken (82 %) varit igång sedan början av år 2007 (se figur 3.1). Dessa tidserier består av sammanlagt 69 observationer. Som nämndes i första kapitel, Bilprovningen har närvaro med minst en station i varje län. I olika län finns från en upp till elva stationer och den genomsnittliga volymen varierade mellan 303 och kontrollbesiktningar per månad under den analyserade perioden. Totalt genomför Bilprovningen runt 1,2 miljoner kontrollbesiktningar av personbilar varje 20
26 år. Den totala volymen har ökat med 3-5 % årligen under de senaste fem åren bortsett år 2010 då den totala volymen minskade med 0,5 % jämfört med året innan. Antal tidserier som analyserades på länsnivå blev 20 stycken totalt eftersom Östergötlands län borttogs från vidare analys på grund av en alltför kort dataserie. På stationsnivå finns totalt 74 enheter som har en tillräckligt lång dataserie som bas för en prognosmodell. Två av dessa är mobila enheter som tillsammans betjänar sju olika stationer i norra Sverige. I detta syfte har två nya tidserier skapats, en för respektive mobilenhet. Tio stationer lämnades utanför en mer detaljerad analys av resultatet eftersom dessa stationer har för få observationer (n <30) för att ge ett pålitligt resultat. I detta kapitel presenteras några centrala begrepp i tidserier samt andra faktorer som behöver analyseras i samband med modellvalet. Länsindelning används främst i detta kapitel för att illustrera metodik som använts i denna studie och för att presentera några väsentliga faktorer i modellvalet. I kapitel 4 där resultat och modellernas prestanda i förhållande till olika statistiska mätmetoder diskuteras mer ingående så görs detta på stationsnivå eftersom i verkligheten görs prognos på artikelnivå för respektive station. En sammanställning av de olika utjämnings- och ARIMA modellerna på läns- och stationsnivå samt deras procentuella fördelning inom datamaterialet redovisas i bilaga E Analys av stationäritet Ett plottdiagram över successiva tidsperioder är ett enkelt sätt att undersöka mönstret i tidserierna och för att upptäcka eventuella problem med stationäritet eftersom ARIMA modeller förutsätter att modellanpassningen görs på en stationär tidserie. Med stationäritet menas att vissa statistiska egenskaper hos en tidserie, som dess väntevärde, varians och autokorrelation är tidsinvarianta, dvs. konstanta över tiden. Om vi låter beteckna en stokastisk tidserie, fyller dess egenskaper villkoren för en svag stationär tidserie om seriens väntevärde och varians är konstanta över tiden och 21
27 kovariansen beror endast på tidsavstånd (k) och inte på tiden (t). Dessa villkor beskrivs matematiskt i formel 3-1 härefter. Formel 3-1 där kovarians, dvs. samvariation mellan två stokastiska värden (slumpvariabler) som ligger k perioder från varandra vid tidpunkt t, betecknas med (Gurajati & Porter, 2009). Tidsavståndet k mellan två observationer ( och kallas lag. Kovarians vid lag betecknas med och är variansen för själva slumpvariabeln, med andra ord vid tidpunkt t (Montgomery, Jennings, & Kulachi, 2008). Villkoren för svagt stationäritet är väsentliga eftersom man eftersträvar en robust modell som kan användas för prognos av framtida observationer. Korrelationskoefficient är ett statistiskt mått som mäter styrkan och riktningen av sambandet mellan två stokastiska variabler. Populationsparametern betecknas med (rho) där När, sägs de två stokastiska variabler vara okorrelerade med varandra. I praktiken görs skattningar av den vanligen okända populationsparametern genom observationer inom ett bestämt antal tidsperioder. Skattningen, betecknad med eller, för respektive lag k fås enligt formel 3-2. Formel 3-2 där står för tidseriens medelvärde och är en observation vid tidpunkt. En samling av korrelationsskattningar för respektive lag där 10 kallas autokorrelationsfunktion (eng. ACF) alternativt sampel 10 Per definition är, eftersom och när 22
28 autokorrelationsfunktion (eng. SAC). ACF tillsammans med den partiella autokorrelationsfunktionen (eng. PACF) är ett viktigt verktyg i tidserieanalys. Genom att studera tidseriens autokorrelationsfunktioner kan man identifiera vilken typ av differentiering som behövs för att åstadkomma stationäritet. Det enklaste sättet är att göra ett korrelogram som är en grafisk presentation för hur autokorrelationen beter sig vid successiva laggar. Det finns en teoretisk beskrivning hur ACF och PACF utvecklas över successiva laggar beträffande AR, MA och ARMA processer. Dessa beskrivningar anges i tabell 3.1. Tabell 3.1 Teoretisk autokorrelationsfunktion för AR, MA och ARMA processer Modell ACF PACF AR (p) MA (q) ARMA (p,q) ACF avtar exponentiellt och/eller bildar en dämpad sinuskurva Signifikanta spikar i ACF som slutar efter lag q Signifikanta spikar i PACF som slutar efter lag p PACF avtar exponentiellt och/eller bildar en dämpad sinuskurva Avtar exponentiellt och/eller bildar en dämpad sinuskurva både i ACF och PAFC Tabell från (Montgomery, Jennings, & Kulachi, 2008), s. 256 och (Gurajati & Porter, 2009) s. 781 Vad beträffar Bilprovningens data så visar tidserieplottarna på respektive län att alla län har en kraftig periodisk volymnedgång i juli och december samt volymuppgång bland annat under mars och maj månaderna (se bilaga B). I några län kan man även ana en svag ökande eller avtagande volymtrend. Efter en visuell bedömning på tidserieplottar skall man även undersöka korrelogram för att se om hur mönstret ser ut i seriens autokorrelations- (ACF) och partiella autokorrelationsfunktion (PACF) 11. I figur 3.2 visas korrelogram för Västerbottens och Stockholms län på de ursprungliga tidserierna. Mönstren som förekommer i Västerbottens och Stockholms läns korrelogram är karakteristiska även för de andra länen. I de allra flesta län bildar ACF samma typ av mönster som i Stockholms län 11 Sampel autokorrelationsfunktion normalt refereras till SAC i litteraturen och den partiella autokorrelationen till SPAC. I denna studie används termerna och ACF/PACF för tydlighetens skull. 23

29 där 3-5 successiva positiva och negativa autokorrelationer avlöser varandra. ACF minskar inte avsevärt under de 24 laggarna som visas i korrelogram och har signifikanta periodiska spikar i jämna mellanrum. Vad gäller Västerbottens län visar ACF en stark positiv autokorrelation över flera laggar som avtar något längre bakåt i tiden. Även Uppsalas, Södermanlands och Östergötlands län har ett liknande mönster i ACF. Figur 3.2 PACF bildar däremot är inte lika entydigt mönster mellan olika län som ACF gör. En gemensam nämnare för alla dessa serier är att PACF vanligen visar signifikanta spikar vid första två laggar och återigen en eller två i mitten av den undersökta perioden. Signifikanta spikar i PACF lag 1 och 13 och därefter i jämna mellanrum tyder på säsongsvariation med säsongslängd på 12 månader. Från och med lag 13 håller PACF inom konfidensintervallet i samtliga län till slutet av de 24 laggarna som visas i korrelogram. Vidare skall noteras att växlar mellan positiva och negativa värden (oscillation) och bildar ett oregelbundet mönster som avtar i amplituden efter lag 13. Sammantaget från tidserieplottar och korrelogram kan man konstatera att någon typ differentiering behövs i de flesta länen för att åstadkomma stationäritet. Eftersom säsongsfluktuation är närvarande i alla serier, men endast några län visar trend, kan första differensen på säsongen också vara ett tänkbart alternativ för att stabilisera serierna. För att hitta det bästa alternativet har en jämförelse gjorts mellan tre olika transformationsalternativ: Korrelogram (ACF/PACF) för Västerbottens och Stockholms län ursprungliga tidserier, k(24) 24
30 1) Första differens på tidserien, dvs., 2) Första differens på säsongen, dvs. 3) Kombination av både d(1) och D(1). Orsaken till att jämföra alla tre olika kombinationer med varandra är att undvika överdifferentiering och för att hitta rätt metod från första början. Roten ur kvadratmedelfelet, RMSE (eng. root mean squared error), kan användas som ett statistisk mått för att jämföra dessa tre metoder med varandra samt identifiera den bästa transformationen som gör de flesta av tidserierna stationära. Differentiering som ger lägst MSE rekommenderas ofta att användas mellan konkurrerande modeller. En vanlig metod för att stabilisera en icke-stationär tidserie är att differentiera tidserien mellan första ordningen, dvs.. Första differensen hjälper till i de flesta fall att göra en icke-säsongsbetingad serie stationär. Med differens menas att man bildar en ny tidserie som bygger på första differensen på tidseriens successiva värden, dvs.. Denna metod baseras på antagandet att det finns en stokastisk, dvs. icke-förutsägbar trend i serien. Syftet med differentiering är att avlägsna den stokastiska trendkomponenten så att bara vitt brus (slumpmässig variation) återstår i den linjära modellen, vilket man vet är en stationär process. Den linjära modellen kallas då för slumpvandring (eng. random walk) och kan förekomma med eller utan konstant. En tidserie kan även innehålla en deterministisk trend och det är inte alltid lätt att identifiera vilken typ av trendprocess som genererar dataserien. I vissa fall kan tidserien formas av såväl deterministiska som stokastiska trendkomponenter. En generell definition för en deterministisk trend är att denna kan matematiskt beskrivas som en linjär eller en kvadratisk funktion av tiden, t.ex. där är konstant, anger lutningen på trendlinjen och är en slumpmässig variation (Gurajati & Porter, 2009). En tidserie med en deterministisk trend görs stationär genom detrending. Kortfattat betyder detta att man avlägsnar trendkomponenten med hjälp av regressionsanalys. En trendstationär serie är skillnaden mellan de aktuella och skattade värdena, dvs.. 25
31 Ett antal akademiska artiklar har publicerats om såväl teorin om trendgenerande processer som praktiska tillämpningar. Caiado och Crato (2007) använder en hierarkisk klustermetod för att identifiera de statistiska mått som bäst diskriminerar de stokastiska och deterministiska trendprocesserna 12 från varandra. Enligt författarna visar de första laggarna ofta tydligaste skillnaden mellan dessa två processer. En tidserie med en stokastisk trend har nära perfekt autokorrelation i ACF, dvs., medan i en deterministisk trendmodell vid första få laggar (k). I PACF spikar i en tidserie med stokastisk trend vid lag 1 och därefter avtar abrupt medan en tidserie med deterministisk trend bildar ett mönster i residualerna. Basantagandet i denna studie är att den trend som visas i Bilprovningens datamaterial är mer av stokastiskt än deterministiskt karaktär. En trend på länsnivå kan uppstå tillfälligt när antalet stationer ökar i ett begränsat geografiskt område, dvs. utbudet ökar. På samma sätt kan en negativ trend uppstå när fordonsägare flyttar mellan stationer och konkurrerande bolag. Detta behöver ändå inte tyda på att efterfrågan, dvs. fordonsbeståndet, minskar i ett län. En positiv trend i Bilprovningens data kan likaväl betyda en negativ trend för en annan aktör. Den lokala trenden beror helt och hållet på vilken jämvikt råder mellan utbudet och efterfrågan i det aktuella geografiska området. Resultat från olika differentieringsalternativ (se tabell 3.2) visar att säsongsrensningen ger lägst RMSE i genomsnitt och således räcker i de flesta av länen att uppnå stationäritet. Samtidigt bekräftar detta att säsongsanpassade modeller, oavsett om man använder utjämningsmetoder eller ARIMA modeller kommer förmodligen ge bäst anpassning till data. Tabell 3.2 RMSE resultat för olika differentieringsalternativ RMSE för Mean SE Minimum Maximum ARIMA (p,d,q)(p,d,q) (0,1,0)(0,0,0) 1135, , , ,045 (0,0,0)(0,1,0) 603, , , ,900 (0,1,0)(0,1,0) 729, , , , Monte Carlo simulation gjordes på fem deterministiska trendmodeller och fem stokastiska trendmodeller. Därefter tillämpades hierarkisk klustermetod för att hitta bäst diskrimination mellan de olika trendprocesserna. 26
32 Relevanta statistiska tester för stationäritet Trots att en grafisk analys och korrelogram ger mycket information om tidseriens stationäritet och vilka autokorrelationer är signifikanta skall man även tillämpa statistiska tester för att verifiera sina slutsatser från den visuella bedömningen. SPSS 20 använder Ljung-Box Q test för att beräkna om skattade autokorrelationer upp till antal laggar är gemensamt signifikanta. Ljung-Box testet görs på residualerna. Om vitt brus återstår efter differentiering, betyder detta att feltermerna är oberoende och okorrelerade med varandra, dvs. tidserien är stationär. Testvärdet för B fås enligt formel 3-3 som sedan jämförs med chitvåfördelningens kritiska värden för olika sannolikheter. Formel 3-3 B där approximativt följer fördelning med frihetsgrader. Ett lågt värde ger en högre sannolikhet att autokorrelationer för gemensamt antal laggar är noll. En jämförelse från Ljung-Box testet mellan olika differentieringsmetoder visas i tabell D.2, bilaga D. Det kritiska värdet är 28,87 i chitvå-fördelning med 18 frihetsgrader och 95 % konfidensnivå, dvs.. I 12 av 20 län ger första differens på säsongsdelen bättre resultat i Ljung-Box testet jämfört med de övriga differentieringsalternativen. Resultatet bekräftar även att säsongsrensning räcker i åtta utav tjugo länen. Dessa är Norrbotten (0,837), Jämtland (0,591), Örebro (0,144), Västra Götaland (0,445), Halland (0,272), Skåne (0,270), Kronoberg (0,782), och Stockholm (0,524) med respektive sannolikhet angiven i parentes att residualerna är okorrelerade. För två län, Jönköpings och Södermans län, kombinerad detrending och säsongsrensning ger bättre resultat i LB testet även om sannolikheten att det kvarstår autokorrelation i residualerna ligger nära gränsvärdet. I sex av länen (Västerbotten, Gävleborg, Västmanland, Värmland, Kalmar och 27
33 Uppsala) är LB (Q) testvärde mindre än signifikansnivå 0,05 vid alla differentieringsmetoder. I bilaga C. redovisas de säsongsrensade tidserierna samt korrelogrammen för respektive län. Ett annat sätt att testa stationäritet är att använda Dickey-Fullers (DF) test för enhetsrot. Om en misstanke kvarstår att differentiering inte räcker för att stabilisera serierna kan DF användas för att kolla vilka tidserier eventuellt har en enhetsrot. DF test består av tre olika regressionsmodeller, a) utan trend och konstant, dvs. en, b) med konstant, dvs., och c) med konstant och trend, dvs.. Dessa regressioner testas mot och där nollhypotes betyder att enhetsrot finns i den undersökta tidserien eftersom. Som beslutskriteriet jämförs testvärdet mot DFs kritiska värde. Om >DF kan man inte förkasta nollhypotesen, vilket innebär att enhetsrot existerar i tidserien Olika faktorer som påverkar modellval En stationär tidserie är en förutsättning för vidare anpassning av data, dvs. vilka andra AR(p), MA(q) eller ARMA (p,q) komponenter behövs och hur många termer av dessa. Syftet är att identifiera den datagenereringsprocess som bäst beskriver tidseriens struktur, dvs. modellen som kan tillämpas för prognostisering av kommande värden. I denna process samt i nästkommande steg kommer modelldiagnostiken vara avgörande, eftersom en till synes bra teoretiska anpassning till data kan ändå visa sig vara otillräcklig i verkligheten. Innan man kan gå vidare i modellbyggandet är det värt att diskutera betydelsen av outliers i dataserien. Dessa spelar även roll i Bilprovningens data och ändrar modellerna i många län och stationer beroende på vilken eller vilka olika typer av extrema värden förekommer i tidserierna Outliers - olika typer av extrema värden En outlier är en observation som numeriskt markant avviker från övriga värden i en dataserie. Även med vetskap att tidserien innehåller extrema värden så ignoreras ofta 28
34 deras betydelse. Detta kan lätt leda till att missledande slutsatser dras från dataserien (Tsay, 1988). Outliers klassificeras normalt i fyra olika typer beroende på hur datagenereringsprocessen ändras efter den extraordinära chocken eller störningen. De kan vara additiva (additive outlier, AO), innovativa (innovative outlier, IO), nivåförändringar (level shift, LS) eller övergående, kortvariga förändringar (transitional change outlier, TCO) av karaktären. En additiv störning (AO) påverkar endast en observation. Därefter återvänder tidserien till samma mönster som innan. Störningar som börjar från en tidpunkt och därefter påverkar kommande observationer kallas för innovativa outliers (IO). Till exempel lansering av en ny produkt kan orsaka denna typ av förändring i datagenereringsprocessen. TCO definieras som en extraordinär spik i serien vars effekt varar över några perioder tills effekten avtar exponentiellt. LS betyder en nivåförändring som ändrar processen till en icke-stationär process från en viss tidpunkt framåt. I en arbetsstudie för det spanska bankväsendet har Kaiser och Maravall studerat mer ingående de olika typerna av störningar som förekommer i tidserier och introducerar SLS, en säsongsbetingad variant av nivåförändringar (Kaiser & Maravall) Modellval för Bilprovningens tidserier I denna studie användes SPSS expert modeler i modellvalet. En manuell bearbetning av varje enskild tidserie, totalt 94 stycken, skulle kräva ett alltför omfattande och tidskrävande detektivarbete för att hitta de optimala modellerna och inte nödvändigtvis leda till en bättre lösning. Innan körningen görs i SPSS behöver man ange om outliers skall tillämpas i modellen, vilka typer av dessa samt om en konstant skall inkluderas i modellen. För att testa hur outliers generellt påverkar modellrekommendationen, gjordes två separata körningar på tidserierna, den ena baserad på antagandet att inga extrema värden existerar i serierna och den andra med en automatisk identifiering av de olika störningstyperna. Resultat diskuteras i mer detalj nästa kapitel här kan konstateras att extrema värden och störningar har betydelse för modellens prestanda. För att kolla om extrema värden förekommer även på aggregerad nivå gjordes en ytterligare körning på Bilprovningens 29
35 totalvolym. Denna tidserie blir stationär genom använda säsongsrensad serie. En observation (mars 2008) på totalnivå klassificerades som en additiv störning (AO). Om man analyserar förekomsten av olika störningar i länsbaserade tidserierna (se tabell 3.3) så återfinns mars 2008 såväl i totalserien som i fyra olika län. Alla dessa störningar är klassificerade som negativa additiva, vilket betyder att i dessa län fanns en extraordinär volymminskning i mars För övrigt är det intressant att notera att över 40 % av de extrema värdena förekommer under år 2008 och de flesta inträffar under första kvartalet. En additiv störning kan t.ex. förekomma på grund av väderförhållandena eller att det finns tillfälliga kapacitetsproblem som orsakar temporära volymflyttningar från en månad till en annan. En innovativ störning börjar från en tidpunkt och därefter påverkar kommande observationer. Öppnandet av en ny station kan till exempel vara en sådan händelse som orsakar en innovativ störning på länsnivå. Dessa kan även orsaka nivåförändringar eller visa sig som kortvariga spikar vars effekt avtar exponentiellt över kommande perioder. Man skall inte heller glömma bort att effekten av en störning eller extraordinär chock kan vara såväl positiv som negativ. I denna studie analyseras endast drygt en tredjedel av den totala besiktningsmarknaden. Under den analyserade perioden har Bilprovningen även öppnat nya stationer som numera tillhör Opus Prodox eller den sydvästra gruppen. På länsnivå kan således en öppning av en ny närliggande station synas som en plötslig negativ nivåförändring eller en kortvarig spik vars effekt avtar stegvis efter några perioder. Tabell 3.3 Totalt antal störningar per månad och år samt fördelning per kvartal År Jan Feb Mar Apr Maj Jun Jul Aug Sep Okt Nov Dec Totalt Tot Kv

36 Överblick av olika prognosmodeller per län och per station Utan outliers får 16 utav 20 län en enkel säsongsbetingad exponentiell utjämningsmetod och de övriga fyra länen får Winters additiva utjämningsmetod som modellval. När extrema värden tas hänsyn i modellvalet ändras den föreslagna modellen i totalt 14 län till någon typ av ARIMA modell som det bästa alternativet. En sammanställning av de olika modellerna för olika län och stationer redovisas i tabell D.2 i bilaga D. Även om flera län/station utgår från samma basmodell, har varje län och station sin en egen specifik modell. Modellparametrarna är unika för varje station/län samt vissa har en konstant i den linjära modellen medan andra kan bäst anpassas utan konstant. Jämförelsevis kan man konstatera att identifikation av störningar ändrar modellvalet för majoriteten av länen. Samma fenomen naturligtvis händer på stationsnivå. Figur 3.3 visar schematiskt hur fördelning på olika modeller ändras när extrema värden tillåts i modellvalet. Figur 3.3 Med tanke på de faktorer som påverkar såväl volymutvecklingen på besiktningsmarknaden som dynamiken mellan olika stationer och regioner kan extrema värden ge värdefull information och därför bör medtas i modellvalet. En prognosmodell skall vara robust i sin grundkonstruktion men samtidigt tillräcklig känslig för att identifiera de interna och externa störningarna som ändrar processen på något sätt. I nästa kapitel diskuteras vidare hur väl de valda modellerna passar till prognos av kommande observationer samt hur modellens prestanda kan utvärderas med olika statistiska mätmetoder. Fördelning mellan olika modellval med outlier identifikation som en diskriminerande faktor 31
37 4. Prognos och utvärdering av modellparametrar 4.1. Allmänt om prognosfel Prognosfel är en viktig del i utvärdering av modellens prestanda. På detta sätt får man fram avvikelsen eller residualen mellan den aktuella och den skattade tidserien. Modellens prestanda kan utvärderas genom ett-steg-framåt prognosfel, vilket kan skrivas med hjälp av lead operatör enligt formel 4-1: Formel 4-1 där står för prognosvärde för som gjordes perioden innan (Montgomery, Jennings, & Kulachi, 2008). Standardiserade mätmetoder avseende prognosfel är bland annat: Medelprognosfelet (Mean error, ME) Absoluta medelprognosfelet (Mean absolute deviation, MAD, även MAE) Medelkvadratfelet (Mean squared error, MSE) Procentuella medelprognosfelet (Mean percentage error, MPE) Procentuella absoluta medelprognosfelet (Mean absolute percentage error, MAPE) Roten ur medelkvadratfelet (Root-mean-squared error, RMSE) Första tre mätmetoder är skalenliga och anger prognosfelet i samma enhet som observationer medan de procentuella avvikelserna är relativa nyckeltal. Vidare skall nämnas att t.ex. MSE är känslig för eventuella extrema värden i dataserien. En ideal prognosmodell har ett lågt prognosfel med väntevärde nära 0, dvs., vilket också leder till att man kan undersöka om prognosfelet följer normalfördelningen med hjälp av P-P plottdiagram (normal probability plot). Ett test med anknytning till normalfördelning av residualerna är Anderson-Darlings test. Testet grundar sig på nollhypotes (H 0) att slumptermerna är normalfördelade genom att jämföra normalfördelningens teoretiska kvantiler mot residualernas kvantiler. Ett 32
38 p-värde som faller inom ramen av 95 % signifikansnivå leder till att nollhypotes inte kan förkastas och vi kan dra slutsatsen att residualerna är normalfördelade Modellens förklaringsgrad Förklaringsgrad,, används flitigt i olika regressionsmodeller för att bedöma hur väl beroende variabler förklarar den oberoende variabeln. Normalt sett får absolutvärde mellan 0 och 1, dvs. och är kvoten mellan summan av kvadrerade avvikelser mellan anpassade värden och seriens medelvärde och summan av totala kvadrerade avvikelser från seriens medelvärde (se formel 4-2). Formel 4-2 där,,. Ju närmare ett man kommer, desto bättre anses modellen förklara den aktuella tidserien, eftersom regressionen görs på tidseriens laggade värden och/eller feltermer. SPSS anger två olika värden, en för den ordinarie respektive den stationära tidserien. Det stationära värdet är ett bättre mått av modellens passform när tidserien har en trend eller visar en säsongsvariation. I vissa sammanhang kan värdet variera mellan den negativa oändligheten och ett. Vid förekomsten av ett negativt värde på, skall resultat tolkas som att den undersökta modellen är sämre än basmodellen medan ett positivt värde indikerar det motsatta Goodness-of-fit mått SPSS redovisar även normaliserad BIC värde (Normalized Bayesian Information Criterion). Detta är ett allmänt GFI (goodness-of-fit) mått, dvs. ett generellt mått som mäter modellens kvalitet och passform, och som även tar hänsyn till modellens komplexitet. Måttet baseras på medelkvadratfelet (MSE) justerad för antal modellparametrar samt seriens längd. I likhet med andra liknande mått som AIC (Akaikes Information Criterion) eller SIC (Schwartz Information Criterion) används 33
39 dessa mått främst för att jämföra konkurrerande modeller och således underlätta valet av den mest optimala modellen. Ju lägre värde på BIC, AIC eller SIC får, desto bättre anses modellens passform vara bland konkurrerande modeller. I denna studie BIC kommer inte att kunna tillämpas eftersom modellvalet görs automatiskt av SPSS Jämförelse av prognosfel med konkurrerande modeller Prognosfel ger en indikation hur väl den valda modellen kan anpassas till data och hur stora avvikelser kan man förvänta sig i prognosen. Ännu viktigare i detta sammanhang är att kunna avgöra om modellen anses vara tillräckligt robust för att användas till prognossyfte. Eftersom Bilprovningen gör kontinuerliga volymprognoser för sina stationer kan dessa användas som valideringsunderlag och jämföras mot modeller som är framtagna genom SPSS. Bilprovningens egna prognoser kallas i detta sammanhang som naiva prognoser med anledning av att dessa är ofta baserade på manuella beräkningar gjorda på historiska värden, men även på subjektiva bedömningar som bygger på den kunskap som Bilprovningen har om marknaden, stationer osv. Den slutgiltiga prognosen är resultat från flera personers medverkan och samtidigt en revidering om volymutvecklingen, stationskapacitet, konkurrenter och andra faktorer som anses påverka antalet kommande kontrollbesiktningar. Slutligen godkänns den föreslagna prognosen av styrelsen innan den används för verksamhetsstyrningen. Bilprovningen har haft avsikt att göra flera prognoser per år. Under 2012 har man tagit fram totalt tre prognoser om utfallet beträffande år Dessa tre prognoser (P1, P2, P3) 13 gemensamt kallas den naiva prognosen och jämförs med de olika utjämningsoch ARIMA modellerna för perioden januari-september Jämförelsen baseras på två nyckeltal, nämligen 1) MAE som är ett skalenligt mått och mäter det absoluta prognosfelet i antal kontrollbesiktningar samt 2) MAPE som anger det absoluta prognosfelet i procentuella termer. 13 P1 avser prognosen för perioden januari-april, P2 för maj-augusti och P3 för september. 34
40 4.2. Allmänt om studiens resultat Resultatet från denna studie visar att nästan alla stationer får en säsongsbetingad utjämningsmetod eller ARIMA modell som modellval. Dessutom behöver 60 utav 74 stationer även någon form av differentiering för att stabilisera serien. Resultatet för olika stationer redovisas härefter enligt de olika modelltyper som förekommer bland de analyserade enheterna. Modellerna har klassificerats i sex olika huvudgrupper enligt tabell 4.1. I vissa grupper förekommer även undergrupper beroende på vilka gemensamma nämnare eller egenskaper finns bland de olika modellerna. En sammanställning vad avser antalet och fördelningen av de olika modellerna i ARIMA termer redovisas även i bilaga D, tabell D.2. Tabell 4.1 Fördelning och gruppering av olika modeller för resultatredovisning Grupp Beskrivning N % fördelning 1 Säsongbetingad enkel exponentiell utjämningsmetod % 2 Winters additiva utjämningsmetod % 3 Säsongbetingad slumpvandringsmodell % 4 SMA modeller % 5 SAR modeller % 6 ARMA och ARIMA modeller 8 11 % Totalt % 4.3. En säsongsbetingad enkel exponentiell utjämningsmodell Majoriteten av stationerna (78 %) får en enkel exponentiell säsongsutjämningsmetod som modellval när inga extrema värden antas förekomma i tidserierna. Identifikation av outliers ändrar modellvalet till en rad olika ARIMA modeller. För en nästan fjärdedel av de analyserade stationerna kvarstår denna utjämningsmetod som den optimala modellen tack vare att dessa stationer inte har några extrema värden i dataserierna. Tidserien utjämnas med två utjämningsparametrar, för nivån och för säsongen. Beräkningsalgoritm för dessa samt för det skattade värdet angavs i formel 2-5. Vad 35
41 avser de analyserade stationerna kan man konstatera att nivåparameter varierar mellan 0,1-0,5, vilket även överensstämmer med den generella rekommendationen angående alfavärdet. Säsongsparameter vanligen är mycket liten, närmare noll, vilket är normalt eftersom den största utjämningseffekten på säsongsdelen fås med. De övergipande nyckeltal för modellens prestanda angående prognosfel redovisas i tabell E.1, bilaga E. Generellt kan man säga om resultatet i denna grupp att såväl de stationära som ordinarie värdena är relativt höga, 0,707 respektive 0,767 i genomsnitt. Medelprognosfelet i absoluta tal (MAE) varierar mellan 9 och 244 kontrollbesiktningar och ligger på 98 i genomsnitt för hela gruppen. Även procentuella absoluta medelprognosfelet (MAPE) varierar från 7,8 % som lägsta och 18,8 % som högsta värdet inom gruppen. Det procentuella absoluta medelprognosfelet är 10,2 % i genomsnitt. De olika statistiska standardmåtten och även Ljung-Box testvärden indikerar att enkel exponentiell utjämningsmetod med säsong kan vara en mycket bra basmetod för prognossyfte, speciellt om man utgår ifrån antagandet att inga värden skall betraktas som extrema. Hur väl denna metod klarar sig i jämförelse med den naiva prognosen är avgörande i utvärderingen av modellens faktiska prestanda Exponentiella utjämningsmetoder i jämförelse I figur 4.1 visas de absoluta medelprognosfelen för denna grupp i antal kontrollbesiktningar (MAE) samt som procentuella avvikelser (MAPE) jämfört med utfallet och gentemot den naiva prognosen för perioden januari-september Oavsett om man jämför resultatet per station, per månad eller på totalnivå, en enkel exponentiell utjämningsmetod med säsong genererar ett betydligt lägre prognosfel än vad som den naiva prognosen uppnår. Den naiva prognosen genererar ett nästan tre gånger större medelprognosfel i absoluta tal, dvs. 232 vs. 85 i genomsnitt i MAE bland de 17 stationer som ingick i denna grupp. Samma gäller naturligtvis det relativa nyckeltalet, MAPE. Resultatet visar att det absoluta procentuella medelfelet är 26,6 % vs. 9,9 % för den naiva prognosen respektive utjämningsmetoden. Det råder således ingen tvekan att användning av denna utjämningsmetod - även utan hänsynstagande till extrema värden - skulle generera ett lägre prognosfel i genomsnitt än vad som den manuella metoden kan 36

42 åstadkomma. Intressant också notera att de största skillnader mellan dessa två konkurrerande metoder förekommer mellan januari och april månaderna samt i september, dvs. de månaderna där volymen är betydligt högre än under sommarmånaderna från maj till augusti. Figur 4.1 Jämförelse mellan den naiva prognosen och den exponentiella utjämningsmetoden för grupp Winters additiva modell Winters additiva utjämningsmetod blev modellvalet för 15 (20 %) respektive 10 (14 %) stationer beroende på hantering av störningar. Tidserien som antas innehålla en linjär trend och nivåoberoende säsongsvariation utjämnas med hjälp av tre utjämningsparametrar, en för nivå, en för trend och den tredje för säsongsvariationen. Framåtskrivning av värden sker genom att summera ihop de framtagna nivå-, trend och säsongsskattningarna. Nyckeltal angående prognosfel redovisas i tabell E.2 i bilaga E för grupp 2. Den stationära förklaringsgraden är hög för samtliga stationer och varierar mellan 0,726 och 0,840. Ljung-Box testvärden varierar mellan 7,9 och 40 och sannolikhet att 37
43 det kvarstår autokorrelation i residualerna är lägre än 0,05 för sex stationer. Detta kan även ses i ACF/PACF korrelogram eftersom några stationer fortfarande har några signifikanta spikar som utjämningen inte har lyckats avlägsna. För övrigt visar de statistiska måtten relativt bra resultat för denna grupp. MAE varierar mellan 23 och 146 och ligger på 77 i genomsnitt i absoluta tal i grupp 2. MAPE är 8,2 % i genomsnitt och station med det högsta procentuella medelprognosfelet ligger på 10,2 %. Slutligen kan konstateras att även denna metod överträffar den naiva prognosmetoden för de samtliga 10 stationerna som analyserades i denna grupp. Medelprognosfelet är 73 vs. 225 i absoluta tal (MAE) och i procentuella termer 7,7 % vs. 21,7 % (MAPE) i genomsnitt till fördel för Winters additiva utjämningsmetod En säsongsbetingad slumpvandringsmodell utan drift I grupp 3 ingår sammanlagt 12 stationer, varav elva stationer (14,7%) behöver endast säsongrensas, dvs.. Dessa stationer följer således ARIMA (0,0,0)(0,1,0) 12 schema. En station behöver differentiering både den ordinarie- och säsongsdelen för att serien skall bli stationär. Den linjära modellen för denna station kan beskrivas med hjälp av bakåtoperator som B B. För de övriga 11 stationerna beskrivs den säsongsbetingade slumpvandringsmodellen matematiskt som B eftersom säsongslängden är 12 månader och ingen av stationerna har en driftparameter (konstant) med i modellen. För tio av tolv stationer varierar Ljung-Box testvärden mellan 10,6 och 20, vilket indikerar att det finns mycket hög sannolikhet att någon autokorrelation inte finns kvar i residualerna. En station avviker kraftigt Figur 4.2 Residual ACF/PACF korrelogram från övriga i denna grupp. En tänkbar förklaring är att en säsongsanpassad modell kräver flera säsonger för att kunna modelleras korrekt. Tidsserien blir därmed för kort för analysen, vilket kan påverka pålitligheten av modellvalet för denna station. Även om den stationära förklaringsgraden är relativt hög, kvarstår några signifikanta spikar i ACF/PACF 38
44 vad avser residualerna (se figur 4.2). Även P-P diagram avslöjar att säsongsrensning inte har lyckats avlägsna all autokorrelation från de slumpmässiga feltermerna. Även den station som har differentierats både i den ordinarie- och säsongsdelen har en hög stationär. Däremot visar stationens Ljung-Box testvärde att sannolikheten att det kvarstår autokorrelation i residualerna är mindre än 0,05. Generellt varierar den stationära mellan 0,128 och 0,810, vilket tyder på en stor spridning mellan stationer beträffande hur väl säsongsrensad data kan approximera kommande observationer. I genomsnitt ligger det absoluta medelprognosfelet (MAE) på 122 med lägsta värde på 19,9 och högsta värde på 392,5. I procentuella jämförelse är MAPE i genomsnitt 12,5 % med spridning från 4 % upp till 27 %. I grupp 3 tillhör några relativt stora stationer, vissa med en stark lokal konkurrens. Statistik angående modellens prestanda för grupp 3 anges i tabell E.3 i bilaga E. I en slumpvandringsmodell finns det inga andra komponenter att ta hänsyn till, vilket samtidigt innebär att utvärdering huruvida modellparametrarna är signifikanta bortfaller i denna modell. En prognos, dvs. framskrivning av värden för kommande perioder görs med hjälp av första differensen på säsongslängden. Vi kan således skapa en estimat för kommande värden enligt formel 4-3. Formel 4-3 B där är så kallad lead operatör och anger hur många perioder framåt skall skattningen göras. Feltermen är en slumpmässig variation vid tidpunkt Jämförelse mellan differentierade serier och den naiva prognosen Sammantaget visar resultatet från jämförelsen för 11 utav 12 stationer i grupp 3 att medelprognosfelet i såväl absoluta som procentuella termer är lägre med en ARIMA metod. I denna grupp är resultatet speciellt intressant, eftersom med undantag för en station var tidserierna endast säsongsrensade, dvs. dessa följer ARIMA (0,0,0)(0,1,0) 12 schema. Även stationen med ett kraftigt avvikande LB testvärde hade ett lägre prognosfel än vad som den naiva prognosen genererade. Totalt sett blev gruppens 39
45 medelprognosfel 152 i genomsnitt i antal kontrollbesiktningar, vilket är lägre jämfört med resultatet från den naiva prognosen där MAE var 233 i genomsnitt. Även MAPE var flera procentenheter högre i den naiva prognosen, 24,4 % jämfört med ARIMAs 11%. I grupp 3 hittades en station där den naiva prognosen utklassade ARIMA modellen. Denna station var den enda stationen som var differentierad både i den ordinarie- och säsongsdelen. Även denna station har relativt hög medelvolym per månad med en tuff konkurrens både inom länet samt i den kommunen som stationen tillhör. Medelprognosfelet var 347 i absoluta tal och 10,7 % i procentuella termer i den naiva prognosen. Dessa kan jämföras med den differentierade seriens 463 (MAE) och 14 % (MAPE). Data ger ingen direkt förklaring varför en manuell metod är bättre för denna station. Man kan se från avvikelserna per månad att båda metoder har kontinuerligt relativt kraftiga avvikelser mot det aktuella utfallet. En tänkbar förklaring är att trots dubbla differentieringen är modellen fortfarande inte optimal eftersom LB testvärdet indikerar att det eventuellt kvarstår signifikant autokorrelation i residualerna. Trots att det finns ett antal frågetecken i denna grupp vad gäller några låga testvärden i Ljung-Box testet och huruvida residualerna för några stationer är, de facto, vitt brus efter differentiering, visar den totala bilden ändå att säsongsrensningen räcker för de flesta stationerna att generera ett lägre prognosfel än vad som kan uppnås med den naiva prognosen Säsongsrensade MA modeller Grupp 4 består totalt av 12 stationer som är uppdelad på två undergrupper. För sju stationer (9,5 %) blev modellvalet en säsongsrensad modell som även finjusteras med en SMA(1) term, dvs. dessa stationer anpassas bäst med ett ARIMA (0,0,0)(0,1,1) 12 schema (grupp 4a). Förklaringsgraden för de stationära serierna varierar mellan 0,298 och 0,552. Ljung- Box testvärden samt ACF/ PACF korrelogram på residualerna visar att det inte kvarstår någon signifikant autokorrelation i restvärdena. Resultat för MAE och MAPE visas i figur 4.4 i form av histogram (grupp 4a) och övriga nyckeltal redovisas i tabell E.4 i bilaga E. 40

46 Figur 4.3 Histogram för grupp 4a angående MAE och MAPE Två stationer har en konstant i modellen och de övriga stationerna har endast varsin specifik utjämningsparameter för den glidande medelvärdestermen. Modellen kan presenteras med hjälp av bakåtoperator eller som en linjär regressionsmodell (formel 4-4). Formel 4-4 B B där står för konstanten i modellen och är koefficienten för den säsongsutjämnade slumptermen. En estimat för de skattade värdena görs med hjälp av regressionsmodellen. Som ett exempel visas en station i denna grupp vars exakta modell ser ut enligt följande: Ytterligare 5 stationer (6,8%, grupp 4b) får en egen variant av en säsongsdifferentierad modell med ett varierande antal utjämnade feltermer antingen i den ordinarie och/eller i säsongsdelen. De fem olika SMA modellerna anges i tabell 4.2 härefter och beskrivs även med hjälp av bakåtoperator. De modellerna där en konstant ingår anges med. Tabell 4.2 Modellbeskrivning för de individuella SMA modellerna ARIMA notation N Modellbeskrivning med bakåtoperatör SMA(0,0,3)(0,1,0) 12, 1 B θ B θ B θ B SMA(0,0,3)(0,1,1) 12 1 B θ B θ B θ B B SMA(0,0,1)(0,1,1) 12 1 B θ B B SMA(0,0,1)(0,1,0) 12 1 B θ B SMA(0,0,2)(0,1,0) 12 1 B θ B θ B 41
47 Samtliga av dessa fem stationer hade relativt bra testvärden såväl i Ljung-Box testet som i förhållande till de stationära värden som varierade mellan 0,367 och 0,762. Även MAE och MAPE ligger på en rimlig nivå Jämförelse mellan olika SMA modeller och den naiva prognosen För grupp 4a visar resultatet samma mönster som redan har redovisats i tidigare jämförelser. En SMA modell (0,0,0)(0,1,1) kan skatta värdena med ett betydligt lägre prognosfel än vad som kan åstadkommas med den naiva metoden. För SMA modeller ligger MAE på 116 i genomsnitt medan den naiva prognosen genererar ett genomsnittligt prognosfel på 360 i grupp 4a. I procentuella termer ligger medelprognosfelet på 7,0 % mot 20,2% i den naiva prognosen. Liknande resultat får de fem stationer som fick varsin variant av en SMA modell (grupp 4b). I denna grupp är MAE 64, vilket kan jämföras med en medelavvikelse på 214 från den naiva prognosen. I procentuella termer blir avvikelsen 8,7 % i genomsnitt medan den naiva prognosen genererar ett absolut procentuellt prognosfel på 26,9 % i grupp 4b Olika autoregressiva modeller - AR, SAR, ISAR Sammanlagt får 15 utav 74 stationer någon form av en autoregressiv modell och dessa stationer ingår i grupp 5. De olika variationer som förekommer i denna grupp beskrivs närmare i tabell 4.3. Två stationer följer en ren process, de övriga stationerna däremot en process med eller utan differentiering. Tabell 4.3 Olika SAR modeller som förekommer bland stationerna ARIMA notation N Modellbeskrivning med bakåtoperatör Grupp SAR(0,0,0)(1,0,0) 12 6 B 5a SAR(1,0,0)(1,0,0) 12 1 B B 5b AR (1,0,0) 2 B 5b ISAR(0,0,0)(1,1,0) 12 3 B B 5c ISAR(1,0,0)(0,1,0) 12 2 B B 5c ISAR(1,0,0)(1,1,0) 12 1 B B B 5c 42
48 Grupp 5a består av sex stationer (8,1 %) som har samma grundmodell och som bygger på den ordinarie tidserien. Ingen differentiering behövs för att åstadkomma stationäritet men däremot en autoregressiv term på säsongsdelen för bättre anpassning till data. Förklaringsgraden för dessa stationer varierar mellan 0,516 och 0,739, vilket tyder på att en säsongslaggad AR term förklarar ganska väl mönstret i dataserierna. Ljung-Box testvärden varierar från 9,3 till 17,4, vilket betyder att sannolikheten är minst 0,432 eller mer för samtliga stationer enligt chitvåfördelningen att det inte kvarstår signifikant autokorrelation i residualerna. Samtliga stationer får en konstant i modellen och alla modellparametrarna är signifikanta. Grupp 5b med tre stationer får också en ren modell utan differentiering. MAE i detta kluster är 124 i absoluta termer och MAPE närmare 30 % i genomsnitt. Orsaken till detta är en station som har mycket liten volym. Varje avvikelse på denna station påverkar stort på det procentuella medelprognosfelet för gruppen, även om dessa avvikelser inte är betydande i absoluta tal. För den största stationen i denna grupp kan modellen beskrivas med hjälp av bakåtoperator enligt formel 4-5. Formel 4-5 B B där modellparametrarna är för den laggade AR termen, säsongstermen samt för konstanten. Feltermet betecknar den slumpmässiga variationen vid tidpunkt. Denna station är ett intressant exempel på en AR process, eftersom stationen är relativt stor och ligger i Stockholms län med betydande konkurrens inom länet och även inom den kommun som stationen tillhör. Alla modellparametrarna är signifikanta enligt t-testet och förklaringsgraden är 0,664, vilket är relativt hög. B med 16 frihetsgrader indikerar att det inte kvarstår signifikant autokorrelation i restvärdena även om signifikansnivån ligger strax över den kritiska gränsen på 0,05. Det absoluta medelprognosfelet ligger på 330 i genomsnitt och i procentuella termer är MAPE 12,2% för denna station. I grupp 5c ingår 6 stationer med tre olika variationer av en ISAR modell, dvs. en differentierad modell med en AR term i ordinarie och/eller säsongsdelen. Vad avser 43
49 de viktigaste nyckeltalen, varierar mellan 0,319 och 0,645 och LB testvärden ligger under 22 för samtliga stationer, vilket innebär att signifikant autokorrelation inte kvarstår i residualerna. Även modellparametrarna är signifikanta och endast en station får en ISAR modell med en konstant. I grupp 5 c hittar man en station där den naiva prognosen ger något lägre prognosfel än vad som ISAR modell approximerar. Skillnaden mellan dessa konkurrerande modeller är ändå väldig liten 14, vilket beror på att medelprognosfelet i absoluta procentuella termer är lägre än genomsnittet i den naiva prognosen medan däremot är det betydligt högre än genomsnittet i ARIMA modellen (över 20 %) jämfört med de övriga stationerna Jämförelse mellan SAR /ISAR modeller och den naiva prognosen Oavsett om modellen bygger på autoregressiva termer eller utjämnade feltermer så verkar en statistiskt byggd prognosmodell ha en bättre träffsäkerhet jämfört med den naiva prognosen. För grupper 5a och 5b vars modeller byggs utifrån en säsongslaggad AR term på den ordinarie tidserien ligger medelprognosfelet på 86 i absoluta tal (MAE) respektive 13,7% (MAPE) i procentuella termer medan motsvarande siffror för den naiva prognosen är betydligt högre, 235 i absoluta tal respektive 141,3% i procentuella termer. En station med en obetydlig volym orsakar att det procentuella medelprognosfelet för dessa grupper skenar iväg. En mer rättvis bild fås när denna station utesluts från jämförelsen. Då ligger MAPE på 9,2 % för SAR modellen mot 22,7% i den naiva prognosen, vilket är i linje med resultatet bland övriga grupper. För grupp 5c som består av 6 stationer och som även de har en SAR term på en säsongsrensad serie, genererar modellen bättre träffsäkerhet jämfört med den naiva prognosmetoden. För ISAR modell respektive den naiva prognosen blir MAE 89 vs. 217 i absoluta tal och MAPE 15 11,8 % vs. 18,9% i procentuella termer i grupp 5c. 14 I MAE är skillnaden 2 i absoluta antal och i MAPE 1 procentenhet. 15 I MAPE beräkningen har återigen en station uteslutits eftersom denna station har också en mycket låg volym och därmed påverkar allt för mycket på den realistiska bilden mellan dessa konkurrerande modeller. 44
50 4.8. Olika ARMA och ARIMA modeller I grupp 6 finns det åtta stationer totalt som har både en AR och en MA komponent i modellen, dvs. dessa följer en ARMA process. För fem stationer (grupp 6a) är processen en ren ARMA process, dvs. dessa serier behöver inte differentieras för stationäritet. De övriga tre stationerna (grupp 6b) är säsongsrensade och dessutom har två av dessa första ordningars differens på modellen. De olika kombinationerna av ARMA processer beskrivs i tabell 4.4 Tabell 4.4 Stationer med ARMA & ARIMA modeller ARIMA notation N Modellbeskrivning med bakåtoperatör Grupp ARMA(0,0,1)(1,0,0) 12 4 B θ B 6a ARMA(0,0,2)(1,0,0) 12 1 B θ B θ B 6a ARIMA(1,0,0)(0,1,1) 12 1 B B θ B 6b ARIMA (0,1,1)(1,1,0) 12 1 B B θ B 6b ARIMA (0,1,1)(1,0,0) 12 1 B B θ B 6b Samtliga stationer i grupp 6a visar bra och signifikanta testvärden såväl i (0,703 i genomsnitt) som i Ljung-Box testet. Även modellparametrarna är signifikanta inklusive konstanten som finns i samtliga fem modeller. Medelprognosfelet är 248 i absoluta tal och 12 % i procentuella termer i grupp 6a. Tre stationer behöver differentieras för stationäritet innan man kan lägga till en ARMA process för att få bäst anpassning till data. Stationerna i grupp 6b följer därmed ett ARIMA schema. Den genomsnittliga förklaringsgraden,, för de stationära serierna är 0,595, vilket kan anses kunna förklara dessa modeller relativt väl. Även Ljung-Box testet samt ACF och PACF korrelogram på residualerna bekräftar att det inte finns signifikant autokorrelation i restvärdena. Medelprognosfelet i absoluta tal ligger på 193 i genomsnitt och 9,3 % mätt i procentuella termer. Alla modellparametrarna är signifikanta och ingen av dessa tre stationer har en konstant i modellen. Samtliga nyckeltal för grupp 6 redovisas i tabell E.6 i bilaga E. 45
51 ARMA/ARIMA modeller jämfört med den naiva prognosen Även i de modeller som byggs kring en ARMA eller ARIMA process (grupp 6a & 6b) är det signifikanta skillnader i absoluta medelprognosfelet jämfört med den naiva prognosen. I absoluta tal ligger ARMA modellernas medelprognosfel på 138 och i ARIMA modeller på 165 i genomsnitt. Motsvarande siffror (MAE) i den naiva prognosen är 353 respektive 535 för dessa stationer. Det relativa måttet (MAPE) visar att det absoluta procentuella medelprognosfelet är 7,5 % för ARMA stationer och 8,8% för ARIMA stationer i genomsnitt. Dessa siffror kan jämföras med den naiva prognosen som genererar ett absolut procentuellt prognosfel på 21,3 % (grupp 6a) respektive 25,9 % (grupp 6b) Reflektioner angående prognosfelet Den övergripande bilden från resultatredovisningen och jämförelsen mot den naiva prognosen är att nästan samtliga stationer får en bättre träffsäkerhet såväl med de utjämningsmetoderna och med ARIMA modellerna. Resultatet är naturligtvis glädjande eftersom det inte lämnar någon tvivel att den naiva prognosen under speciella omständigheter eller påverkan av vissa faktorer skulle överträffa en systematisk och statistiskt säkerställd prognosmetodik. Samtidigt är resultatet förvånande ur det perspektivet att även en enkel modell kan utklassa den enorma kunskapen och erfarenheten som Bilprovningen har om sina stationer, besiktningsmarknaden och andra faktorer som påverkar volymen. Kanske det faktum att en modell bygger på historiska värden över en längre period samt att tidserien bryts ner i mer hanterbara beståndsdelar är de viktigaste faktorerna varför medelprognosfelet blir väsentligt lägre i exponentiella utjämningsmetoder och Box- Jenkins metodik. En sammanställning från jämförelsen mellan de konkurrerande metoderna visas i tabell 4.5. På totalnivå är det absoluta medelprognosfelet från utjämningsmetoder och ARIMA modeller 2,5 gånger mindre jämfört med den naiva prognosen. I procentuella termer är det absoluta medelprognosfelet mindre än 10 % medan den naiva prognosen genererar över fyra gånger större prognosfel på totalnivå. 46
52 Tabell 4.5 Sammanställning av prognosfel i MAE och MAPE mellan de skattade värdena från ARIMA modeller och den naiva prognosen. Prognosfel (januari-september 2012) Volym ARIMA Naiv prognos Grupp /modell N % andel MAE MAPE MAE MAPE 1 Enkel exponentiell utjämning m. säsong 17 18,5% 85 9,9 % ,6 % 2- Winters additiva 10 11,2% 73 7,7 % ,7 % 3- Slumpvandringsmodeller 12 14,4% ,0 % ,4 % 4a- SMA (0,0,0)(0,1,1) 7 12,0% 116 7,0 % ,2 % 4b- Individuella SMA modeller 5 5,6 % 64 8,7 % ,9 % 5a- SAR 6 7,8 % 92 8,5 % ,3 % 5b- SAR 3 3,0 % 75 24,2% ,7% 5c- ISAR 6 5,6 % 89 12,3% ,3% 6a- ARMA 4 9,3 % 138 8,8 % ,3 % 6b- ARIMA 4 6,6 % 165 7,5 % ,9 % Totalt % 103 9,9 % ,8 % Det absoluta medelprognosfelet ger viktig information hur avvikelserna varierar under den analyserade perioden och huruvida den valda modellen ligger kontinuerligt under eller över det aktuella utfallet. En systematisk uppföljning av prognosfelet möjliggör att modellen kan finslipas ytterligare och man kan snabbare reagera när datagenereringsprocessen ändras på något sätt. Intressant är naturligtvis även kontrollera hur prognosfelet ser ut på totalnivå, dvs. under den analyserade perioden mellan januari-september Den totala volymen som de analyserade enheterna står för är 94 % av det aktuella utfallet på drygt kontrollbesiktningar. Det finns en stor variation mellan stationer vad avser periodens totalvolym. Den lägsta volymen ligger på 209 medan den största volymen är drygt genomförda kontrollbesiktningar. En genomsnittlig volym per station ligger på närmare besiktningar och cirka 38 % av de analyserade enheterna hade en högre totalvolym än genomsnittet. Först kan man konstatera att såväl den naiva prognosen som ARIMA modeller tenderar överskatta resultatet på totalnivå. Den naiva prognosen ger en skattning som är 20,5% över och SPSS framtagna modeller ger en skattning som är 5 % över det aktuella utfallet för den analyserade perioden i genomsnitt. Endast en station i den naiva prognosen blev totalvolymen underskattat med 10,3% jämfört med det aktuella 47
53 % avvikelse mellan skattning och aktuella utfallet utfallet för perioden. Vad avser de olika utjämnings- och ARIMA modellerna så underskattades totalvolymen vid 22 och överskattades vid 52 tillfällen. Med hjälp av ett punktdiagram (se figur 4.5) kan man se hur de procentuella avvikelserna jämfört med de aktuella utfallen varierar i förhållande till prognosmetod samt till stationens storlek. Med få undantag håller sig ARIMA skattningar under 6 % i absoluta termer med något större spridning bland stationer med totalvolym lägre än kontrollbesiktningar. Även i den naiva prognosmetoden kan man se något större spridning i totalprognosfelet ju mindre stationen är, speciellt om man jämför stationer i grupper med totalvolym under och därefter i varje 5000 intervall upp till kontrollbesiktningar. Endast fåtal stationer i den naiva prognosen har ett lika lågt procentuellt prognosfel som faller inom räckvidden för de ARIMA Figur 4.4 Jämförelse på totalprognosfel i förhållande till stationsvolym för perioden januariseptember 2012 Total prognosfel i förhållande till totalvolym per station ,0% 20,0% 10,0% 0,0% -10,0% -20,0% -30,0% -40,0% Naiv prognos ARIMA prognos skattningarna. Fem stationer (markerade med vitt triangel i figur 4.5) får ett lägre procentuellt prognosfel på totalnivå i den naiva prognosen jämfört med motsvarande ARIMA skattningen och vis-à-vis det aktuella utfallet. Stationerna finns i olika storleksgrupper, vilket tyder på att det inte finns någon direkt koppling på själva volymnivån. Modellvalet eller standardiserade statistiska mått ger inte heller någon entydig förklaring till det att ARIMA skattningen ger högre prognosfel totalt sett 48
54 jämfört med den naiva prognosen. Viktigt också att poängtera att fyra utav dessa fem stationer emellertid hade ett lägre medelprognosfel (MAE, MAPE) med ARIMA modellen än vad den naiva prognosen genererade Uppföljning av modellens prestanda En modell med bra passform och ett lågt prognosfel är naturligtvis utgångspunkten för en bra prognosprocess men ingen garanti om modellens robusthet även framöver. Montgomery m.fl. skriver om olika typer av kontrollmetoder som kan användas i uppföljning av modellens prestanda. Shewhart control charts, CUSUM och EWMA är olika typer av diagram som används bl.a. i kvalitetskontroll av olika processer (Montgomery, Jennings, & Kulachi, 2008). En del av uppföljningsrutinen borde således vara att upprätta någon typ av kontrollmetod för att säkerställa att prognosfelet ligger inom de uppsatta övre (UCL) och nedre (LCL) kvalitetsgränserna Regionala skillnader finns dem? Tabell 4.6 MAPE i genomsnitt i olika län samt procentuella avvikelser från medelvärdet på respektive prognosmetod. Län Naiv Arima Norrbotten 30,9 % 8,1 % 10,1 % 1,2 % Västerbotten 38,3 % 15,5 % 14,3 % 5,4 % Jämtland 25,0 % 2,2 % 15,6 % 6,7 % Västernorrland 20,9 % -1,9 % 7,3 % -1,6 % Gävleborg 24,6 % 1,8 % 11,0 % 2,1 % Dalarna 27,2 % 4,4 % 8,6 % -0,3 % Västmanland 21,4 % -1,4 % 6,6 % -2,3 % Örebro 24,2 % 1,4 % 8,9 % -0,1 % Värmland 23,4 % 0,5 % 8,9 % 0,0 % Västra Götaland 22,0 % -0,8 % 8,9 % 0,0 % Halland 21,5 % -1,3 % 6,9 % -2,0 % Skåne 18,8 % -4,0 % 10,6 % 1,7 % Blekinge 30,4 % 7,5 % 10,0 % 1,1 % Gotland 12,7 % -10,1 % 5,2 % -3,7 % Kalmar 23,8 % 0,9 % 9,0 % 0,1 % Kronoberg 21,5 % -1,4 % 9,4 % 0,5 % Jönköping 17,4 % -5,5 % 5,1 % -3,9 % Östergötland 21,1 % -1,7 % 10,7 % 1,7 % Södermanland 21,1 % -1,7 % 5,5 % -3,4 % Uppsala 20,0 % -2,8 % 7,3 % -1,6 % Stockholm 13,2 % -9,7 % 7,3 % -1,6 % 22,8% 0,0 % 8,9% 0,0 % I denna studie användes länsindelning främst för att undersöka om de olika modellerna eller resultatet indikerar att det finns geografiska skillnader mellan olika regioner. Några definitiva slutsatser kan inte dras i denna studie eftersom de analyserade enheterna står enbart för cirka tredjedel av besiktningsmarknaden. I tabell 4.6 anges det absoluta procentuella medelprognosfelet (MAPE) i genomsnitt för varje län från den naiva prognosen och ARIMA modellen. De stationer som hör till de två mobilenheterna och 49
55 två andra stationer med mycket låg volym har inte räknats med i medelprognosfelet per län. Den regionala jämförelsen indikerar att stationer i norra Sverige är något svårare att prognostisera jämfört med län med stora volymer som Västra Götaland eller Stockholm. Detta kan bero på att det är generellt sett svårare att anpassa en prognosmodell för stationer i glesbygden med låg volym och mer oregelbundna mönster i säsongsvariationen. I vissa län är avvikelserna från medelvärdet likartade såväl i den naiva prognosen som i ARIMA modellen. T.ex. i Västernorrlands, Gävleborgs och Jönköpings län har båda prognosmetoder samma typ och magnitud i avvikelsen från medelvärdet. I vissa län, bl.a. Skåne och Dalarna är däremot avvikelserna av motsatta tecken. 50
56 5. Diskussion 5.1. Studiens slutsatser Ordet prognos härstammar från de grekiska orden pro (förut) och gnosis (kunskap), med andra ord att skaffa sig kunskap om framtida händelser i förväg. Resultatet från denna studie visar att kontrollbesiktningar av personbilar kan prognostiseras med relativt enkla medel, såväl med hjälp av exponentiella utjämningsmetoder som säsongsbetingade ARIMA modeller. Utan outliers en enkel exponentiell utjämningsmetod med säsong fungerar bäst för 78 % av stationerna. Endast de stationer som visar trend utöver säsongsvariation kan volym av kontrollbesiktningar anpassas bäst med hjälp av Winters additiva utjämningsmetod. När störningar tilläts i modellvalet kan de flesta stationerna prognostiseras med någon form av säsongsbetingade ARIMA modeller. Inkludering av outliers kan minska det informationstappet som det nya konkurrensläget orsakar. Genom att analysera förekomsten av störningar/extrema värden, deras egenskaper och vilken effekt de har på tidserien kan man samtidigt få insikter om marknadsutvecklingen i ett geografiskt område. Störningar kan naturligtvis förekomma på grund av extraordinära händelser. Bilprovningen togs ut i strejk i maj 2012, vilket orsakade ett produktionsstopp som varade två dagar. Tack vare att strejken blåstes över relativt snabbt, orsakade detta inte någon effekt på dataserier som analyserades i denna studie. En annan extraordinär händelse var ett större datakrasch som inträffade i slutet av november Under en vecka låg hela IT systemet nere och samtliga kontrollbesiktningar registrerades på påföljande vecka som råkade vara första veckan i december. Denna händelse kan ha samband med de tre störningarna som identifierades på länsnivå (se tabell 3.2). En viktig del av utvärdering av modellens prestanda är de standardiserade statistiska mätmetoderna som presenterades i kapitel 4. Dessa ger en bra övergripande bild hur stort prognosfel kan man förvänta sig och hur väl modellen kan anpassas till dataserien. En svaghet hos dessa statistiska mått är att det är svårt att dra några 51
57 definitiva slutsatser från dessa beträffande modellens prestanda utan att ha referenspunkt till något annat alternativ eller konkurrerande metod. Av denna anledning har det varit mycket värdefullt att kunna jämföra SPSS framtagna modeller med den naiva prognosen, dvs. den befintliga prognosmetoden som Bilprovningen använder i nuläget. Även en till synes dåligt anpassad modell kan ändå vara ett bättre alternativ om den utklassar den befintliga prognosmetoden. Denna studie visar att såväl exponentiella utjämningsmetoder och ARIMA modeller genererar nästan uteslutande ett betydligt lägre prognosfel, med andra ord en bättre träffsäkerhet, än vad som kan åstadkommas med den naiva prognosen. Även det faktum att resultatet var konsekvent till fördel av de SPSS framtagna modellerna tyder på att användning av en systematisk prognosmetod hjälper till att få en bättre träffsäkerhet i prognosen. Framför allt tvingar det företaget att tänka prognosen i förhållande till felmarginalen av skattningarna. Alla skattningar är normalt behäftade med fel men med vetskap om felmarginalen kan man ändå skapa en bild om det mest troliga scenariot för framtiden. På det sättet kan man fortfarande använda även den mest felaktiga prognosen. Om prognosen däremot används t.ex. för att optimera produktionsplaneringen eller för att höja kostnadseffektiviteten bör man även sätta krav på prognosens kvalitet, bl.a. genom att sätta mål för prognosens träffsäkerhet och kontinuerligt mäta och följa upp modellens prestanda. I ett prognosarbete är det naturligtvis väsentligt även att tänka på vilka kostnader detta medför. Bilprovningens prognoser är baserade på manuella beräkningar utan ett särskilt analysverktyg och därmed kostnaderna från prognosarbete är främst förknippade med de resurser och den arbetstid som ägnas åt detta. Samtidigt finns det en ambition att kunna skapa tätare prognoser för att kunna göra finansiella beräkningar om bolagets resultat och hålla ledningsgruppen, styrelsen och andra intressenter informerade om verksamheten. Som nämndes i början av denna studie, kontrollbesiktningar av personbilar är den viktigaste produkten (tjänsten) som Bilprovningen erbjuder och samtidigt är det mest konkurrensutsatta segmentet. En tätare prognosintervall innebär att mer tid måste läggas på framtagning av prognosen än vad som kan ägnas på uppföljningen. I en manuell och ad hoc metod är det svårt att hinna med en utvärdering eller kvalitetsåtgärder för att förbättra prognosmetoden eller processen. Samtidigt blir det svårt att uppnå en bra träffsäkerhet i prognosen, vilket är den mest grundläggande idén bakom en prognos. Om det inte läggs några 52
58 krav på den kunskap som man vill skaffa sig om framtida händelser, måste man också ifrågasätta syftet för en prognos. SAS, SPSS, EViews, Minitab med flera är Business Intelligence (BI) analysverktyg som kan användas för en rad olika typer av analyser, bland annat data mining och bearbetning av undersökningsresultat och naturligtvis för tidserieanalyser. I denna studie analyserades endast en produkt. I verkligheten omfattar en prognos hela Bilprovningens produktportfölj, vilket innebär ett analysarbete för mer än 300 produkter totalt. En totalprognos för samtliga stationer och månader består således av mer än volymskattningar. Ett analysverktyg kan spara tid i framtagning av prognoser så att mer tid kan läggas på uppföljning och analys av prognosmetodens och modellernas prestanda. Ett bättre beslutsunderlag leder till mer informerade beslut om verksamheten. Eftersom utfallet kan läggas in systemet så fort man har data för den aktuella perioden, kan en prognos i principen skapas hur ofta företaget själv vill. En kortare prognosintervall resulterar ofta en bättre träffsäkerhet. Dessutom ju längre tidserier man använder desto robustare modellen blir. Detta är speciellt viktig i säsongsanpassade modeller, eftersom en tidserie som innehåller minst 4-5 säsonger avslöjar bättre mönstret i säsongsvariationen och de olika trendkomponenterna Det makroekonomiska perspektivet på fordonskontroller Tidserieanalyser och studier som publicerats om volymutvecklingen på obligatoriska kontrollbesiktningar är få trots att dessa är en del av trafiksäkerhetsåtgärder och för att bidra till bättre miljö. Dessa kunde ge intressanta infallsvinklar om sambandet mellan kontrollbesiktningar och trafiksäkerheten. Till exempel kan en föryngring i fordonsbeståndet leda till en negativ volymutveckling i kontrollbesiktningar eftersom personbilarna besiktigas för första gången cirka 34 månader efter fordonet togs i bruk. Yngre bilar har generellt sett mindre antal fordonstekniska fel och är vanligen bättre utrustade ur trafiksäkerhetssynpunkt. 16 Detta i sin tur borde leda till ett minskat antal dödade eller skadade i trafiken eftersom dödsolycksrisken minskar i fordonsbeståndet. 16 Ett sätt att mäta fordonets trafiksäkerhet är antal stjärnor bilen har enligt Euro NCAP. I slutet av 2011 hade 78 % av alla sålda nya bilar den högsta säkerhetsbetyg (5 stjärnor) i Euro NCAP. Ett delmål i det svenska trafiksäkerhetsprogrammet är att samtliga nya bilar sålda i Sverige har högsta säkerhetsbetyg år 2020 (Trafikverket, 2012) 53
59 Annan intressant volymaspekt är hur antal fordon som har körförbud på grund av utebliven kontrollbesiktning påverkar trafiksäkerheten. Att fordonet inte besiktigas enligt gällande föreskrifter är knappast fråga på priset av själva kontrollbesiktningen. Reparationskostnader kan bli väldigt dyra och orsakar en större ekonomisk belastning för bilägaren att åtgärda felen på fordonet. Om gapet mellan antal besiktade och antal fordon i trafik med körförbud ökar, borde också den teoretiska dödsolycksrisken öka i fordonsparken på grund av ett ökat antal fordonsfel. Dessutom betyder detta förlorade intäkter till bilbesiktningsföretag. För varje obesiktigade personbilar går bilbesiktningsföretagen miste på ungefär 3,2 MSEK 17 i form av kontrollavgifter. Avgörande ur trafiksäkerhetssynpunkt är ändå det hur stor andel av fordon med körförbud finns i trafiken. Enligt Ynnors körförbudsrapport 18 hade lätta fordon (personbilar, lastbilar), varav 90 % var privatägda, körförbud i augusti Att fordonet föreläggs med körförbud har inga direkta ekonomiska konsekvenser för bilägaren, endast om man fastnar i en poliskontroll. Företeelsen innebär böter på kr, vilket rent ekonomiskt är ofta ett billigare alternativt jämfört med eventuella reparationskostnaderna. Under 2011 bötfälldes bilägare, vilket motsvarar cirka 2,2 % av fordonsbeståndet. Antalet bötfällda har fördubblats sedan 2009 och till om med augusti 2012 hade bilägare blivit botfällda på grund av körförbud. Vid skada eller olycka riskerar bilägaren få en sänkt ersättning från försäkringsbolaget förutsatt att bilen har någon form av försäkring utöver den obligatoriska trafikförsäkringen 19. Trafikverket följer trafiksäkerhetsutvecklingen med hjälp av olika indikatorer, till exempel hur användning av bilbälte eller nykterhet påverkar utfallet i en trafikolycka (Trafikverket, 2012). Däremot görs ingen kontinuerlig uppföljning eller koppling mellan fordonets skick och utfallet i en trafikolycka. VTI 20 forskar kontinuerligt och gör djupstudier hur en mängd olika fordonstekniska och även makroekonomiska 21 aspekter påverkar trafiksäkerheten. Det vore därför intressant att undersöka hur även besiktningsvolymen samt utfallet av besiktningar samverkar i olika trafikolyckor. 17 Beräknad enligt Bilprovningens listpris för kontrollbesiktning av lätta personbilar á 320 kr per förrättning hämtad den 25/09/ ibid 20 Statens väg- och transportforskningsinstitut 21 VTI har gjort en studie bland annat hur konjunkturläget påverkar trafiksäkerheten, se VTI Rapport 704,
60 Litteraturförteckning Box, G. E., Jenkins, G. M., & Reinsel, G. C. (2008). Time Series Analysis - Forecasting and Control (4. uppl.). Hoboken, New Jersey, USA: Jonh Wiley & Sons Inc. Caiado, J., & Crato, N. (2005). Discrimination between deterministic trend and stochastic trend processes. Proceedings of the XIth International Conference on Applied Stochastic Models and Data Analysis, (ss. pp ). Bretagne. Eriksson, M. (2011). Avreglera mera - och bättre. Författaren och Timbro. Fomby, T. B. (June 2008). Exponential Smoothing Models. Hämtat från den Gurajati, D. N., & Porter, D. C. (2009). Basic Econometrics, International Edition (5th Edition uppl.). Singapore: Mc Graw Hill. Janacek, G., & Swift, L. (1993). Time Series - Forecasting, Simulation, Applications. Chichester, West Sussex, UK: Ellis Horwood Ltd. Kaiser, R., & Maravall, A. Seasonal Outliers in Time Series. Banco de España. Mills, T. M. (2011). The Foundations of Modern Time Series Analysis. Hampshire, United Kingdom: Palgrave Macmillan. Montgomery, D. C., Jennings, C. L., & Kulachi, M. (2008). Introduction to Time Series Analysis and Forecasting. Hoboken: John Wiley & Sons, Inc. Nilsson, G., Andersson, G., Brüde, U., Larsson, J., & Thulin, H. (2002). Trafiksäkerhetsutvecklingen i Sverige fram till år Väg- och Transportforskningsinstitutet. Regeringens Proposition :32 om Fordonsbesiktning. (u.d.). SFS 2009:211. (u.d.). Fordonsförordning. Stockhammar, P. (2002). Utveckling av prognosmodeller på Carlsberg Sverige. Uppsala universitet, Teknisk-naturvetenskapliga vetenskapsområdet, Matematisk-datavetenskapliga sektionen, Matematiska institutionen. Uppsala: Uppsala Universitet. Trafikverket. (2012). Analys av trafiksäkerhetsutvecklingen 2011, Målstyrning av trafiksäkerhetsarbetet mot etappmålen Trafikverket. Tsay, R. S. (1988). Outliers, Level Shifts, and Variance Changes. Journal of Forecasting, 7 (1), Yaffee, R. A., & McGee, M. (2000). Introduction to Time Series Analysis and Forecasting. San Diego, California, USA: Academic Press. 55

61 A. Bilprovningens ägare samt fordonsparkens utveckling Figur A.1 Andel av kapitalet bland Bilprovningens ägare Figur A.2 Fordonsparkens utveckling mellan januari 2006 och augusti

62 B. Tidserieplottar per län - ursprungliga dataserier per månad 57
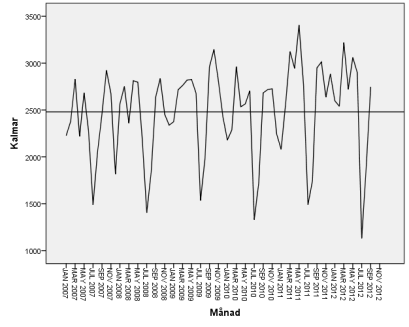
63 58

64 C. Plottdiagram samt ACF/PACF per län på säsongsrensade serier 59
65 60
66 61
67 62
Vad Betyder måtten MAPE, MAD och MSD?
 Vad Betyder måtten MAPE, MAD och MSD? Alla tre är mått på hur bra anpassningen är och kan användas för att jämföra olika modeller. Den modell som har lägst MAPE, MAD och/eller MSD har bäst anpassning.
Vad Betyder måtten MAPE, MAD och MSD? Alla tre är mått på hur bra anpassningen är och kan användas för att jämföra olika modeller. Den modell som har lägst MAPE, MAD och/eller MSD har bäst anpassning.
Stokastiska Processer och ARIMA. Patrik Zetterberg. 19 december 2012
 Föreläsning 7 Stokastiska Processer och ARIMA Patrik Zetterberg 19 december 2012 1 / 22 Stokastiska processer Stokastiska processer är ett samlingsnamn för Sannolikhetsmodeller för olika tidsförlopp. Stokastisk=slumpmässig
Föreläsning 7 Stokastiska Processer och ARIMA Patrik Zetterberg 19 december 2012 1 / 22 Stokastiska processer Stokastiska processer är ett samlingsnamn för Sannolikhetsmodeller för olika tidsförlopp. Stokastisk=slumpmässig
Stokastiska processer med diskret tid
 Stokastiska processer med diskret tid Vi tänker oss en följd av stokastiska variabler X 1, X 2, X 3,.... Talen 1, 2, 3,... räknar upp tidpunkter som förflutit från startpunkten 1. De stokastiska variablerna
Stokastiska processer med diskret tid Vi tänker oss en följd av stokastiska variabler X 1, X 2, X 3,.... Talen 1, 2, 3,... räknar upp tidpunkter som förflutit från startpunkten 1. De stokastiska variablerna
732G71 Statistik B. Föreläsning 9. Bertil Wegmann. December 1, IDA, Linköpings universitet
 732G71 Statistik B Föreläsning 9 Bertil Wegmann IDA, Linköpings universitet December 1, 2016 Bertil Wegmann (IDA, LiU) 732G71, Statistik B December 1, 2016 1 / 20 Metoder för att analysera tidsserier Tidsserieregression
732G71 Statistik B Föreläsning 9 Bertil Wegmann IDA, Linköpings universitet December 1, 2016 Bertil Wegmann (IDA, LiU) 732G71, Statistik B December 1, 2016 1 / 20 Metoder för att analysera tidsserier Tidsserieregression
Sveriges bruttonationalprodukt Årsdata. En kraftig trend.
 Vad är tidsserier? En tidsserie är en mängd av observationer y t, där var och en har registrerats vid en specifik tidpunkt t. Vanligen görs mätningarna vid vissa tidpunkter och med samma avstånd mellan
Vad är tidsserier? En tidsserie är en mängd av observationer y t, där var och en har registrerats vid en specifik tidpunkt t. Vanligen görs mätningarna vid vissa tidpunkter och med samma avstånd mellan
ARIMA del 2. Patrik Zetterberg. 19 december 2012
 Föreläsning 8 ARIMA del 2 Patrik Zetterberg 19 december 2012 1 / 28 Undersöker funktionerna ρ k och ρ kk Hittills har vi bara sett hur autokorrelationen och partiella autokorrelationen ser ut matematiskt
Föreläsning 8 ARIMA del 2 Patrik Zetterberg 19 december 2012 1 / 28 Undersöker funktionerna ρ k och ρ kk Hittills har vi bara sett hur autokorrelationen och partiella autokorrelationen ser ut matematiskt
Sveriges bruttonationalprodukt Årsdata. En kraftig trend.
 Vad är tidsserier? En tidsserie är en mängd av observationer y t, där var och en har registrerats vid en specifik tidpunkt t. Vanligen görs mätningarna vid vissa tidpunkter och med samma avstånd mellan
Vad är tidsserier? En tidsserie är en mängd av observationer y t, där var och en har registrerats vid en specifik tidpunkt t. Vanligen görs mätningarna vid vissa tidpunkter och med samma avstånd mellan
Finansiell statistik
 Finansiell statistik Föreläsning 5 Tidsserier 4 maj 2011 14:26 Vad är tidsserier? En tidsserie är en mängd av observationer y t, där var och en har registrerats vid en specifik tidpunkt t. Vanligen görs
Finansiell statistik Föreläsning 5 Tidsserier 4 maj 2011 14:26 Vad är tidsserier? En tidsserie är en mängd av observationer y t, där var och en har registrerats vid en specifik tidpunkt t. Vanligen görs
Tillämpad statistik (A5), HT15 Föreläsning 24: Tidsserieanalys III
, HT15 Föreläsning 24: Tidsserieanalys III") Tillämpad statistik (A5), HT15 Föreläsning 24: Tidsserieanalys III Sebastian Andersson Statistiska institutionen Senast uppdaterad: 16 december 2015 är en prognosmetod vi kan använda för serier med en
Tillämpad statistik (A5), HT15 Föreläsning 24: Tidsserieanalys III Sebastian Andersson Statistiska institutionen Senast uppdaterad: 16 december 2015 är en prognosmetod vi kan använda för serier med en
Stokastiska processer med diskret tid
 Stokastiska processer med diskret tid Vi tänker oss en följd av stokastiska variabler X 1, X 2, X 3,.... Talen 1, 2, 3,... räknar upp tidpunkter som förflutit från startpunkten 1. De stokastiska variablerna
Stokastiska processer med diskret tid Vi tänker oss en följd av stokastiska variabler X 1, X 2, X 3,.... Talen 1, 2, 3,... räknar upp tidpunkter som förflutit från startpunkten 1. De stokastiska variablerna
Skriftlig Tentamen i Finansiell Statistik Grundnivå 7.5 hp, HT2012
 Statistiska Institutionen Patrik Zetterberg Skriftlig Tentamen i Finansiell Statistik Grundnivå 7.5 hp, HT2012 2013-01-18 Skrivtid: 9.00-14.00 Hjälpmedel: Godkänd miniräknare utan lagrade formler eller
Statistiska Institutionen Patrik Zetterberg Skriftlig Tentamen i Finansiell Statistik Grundnivå 7.5 hp, HT2012 2013-01-18 Skrivtid: 9.00-14.00 Hjälpmedel: Godkänd miniräknare utan lagrade formler eller
Laboration 4: Stora talens lag, Centrala gränsvärdessatsen och enkla punktskattningar
 LUNDS TEKNISKA HÖGSKOLA MATEMATIKCENTRUM MATEMATISK STATISTIK DATORLABORATION 4 MATEMATISK STATISTIK, FÖR I/PI, FMS 121/2, HT-3 Laboration 4: Stora talens lag, Centrala gränsvärdessatsen och enkla punktskattningar
LUNDS TEKNISKA HÖGSKOLA MATEMATIKCENTRUM MATEMATISK STATISTIK DATORLABORATION 4 MATEMATISK STATISTIK, FÖR I/PI, FMS 121/2, HT-3 Laboration 4: Stora talens lag, Centrala gränsvärdessatsen och enkla punktskattningar
DEN FRAMTIDA VERKSAMHETSVOLYMEN I RÄTTSKEDJAN - CENTRALA PROGNOSER FÖR PERIODEN : RESULTATBILAGA
 DEN FRAMTIDA VERKSAMHETSVOLYMEN I RÄTTSKEDJAN - CENTRALA PROGNOSER FÖR PERIODEN 2016-2019: RESULTATBILAGA I denna bilaga beskrivs de prognosmodeller som ligger till grund för prognoserna. Tanken är att
DEN FRAMTIDA VERKSAMHETSVOLYMEN I RÄTTSKEDJAN - CENTRALA PROGNOSER FÖR PERIODEN 2016-2019: RESULTATBILAGA I denna bilaga beskrivs de prognosmodeller som ligger till grund för prognoserna. Tanken är att
Prognoser. ekonomisk-teoretisk synvinkel. Sunt förnuft i kombination med effektiv matematik ger i regel de bästa prognoserna.
 Prognoser Prognoser i tidsserier: Gissa ett framtida värde i tidsserien killnad gentemot prognoser i regression: Det framtida värdet tillhör inte dataområdet. ftet med en prognosmodell är att göra prognos,
Prognoser Prognoser i tidsserier: Gissa ett framtida värde i tidsserien killnad gentemot prognoser i regression: Det framtida värdet tillhör inte dataområdet. ftet med en prognosmodell är att göra prognos,
Prognostisering med exponentiell utjämning
 Handbok i materialstyrning - Del F Prognostisering F 23 Prognostisering med exponentiell utjämning Det som karakteriserar lagerstyrda verksamheter är att leveranstiden till kund är kortare än leveranstiden
Handbok i materialstyrning - Del F Prognostisering F 23 Prognostisering med exponentiell utjämning Det som karakteriserar lagerstyrda verksamheter är att leveranstiden till kund är kortare än leveranstiden
Den framtida verksamhetsvolymen i rättskedjan - Centrala prognoser för perioden : Resultatbilaga
 RESULTATBILAGA I resultatbilagan beskrivs de modeller som ligger till grund för prognoserna i rapporten. Tanken är att redovisningen ska öka transparensen i rapporten. Med utgångspunkt i nedstående specificering
RESULTATBILAGA I resultatbilagan beskrivs de modeller som ligger till grund för prognoserna i rapporten. Tanken är att redovisningen ska öka transparensen i rapporten. Med utgångspunkt i nedstående specificering
Prognostisering av växelkursindexet KIX En jämförande studie. Forecasting the exchange rate index KIX A comparative study
 Kandidatuppsats Statistiska institutionen Bachelor thesis, Department of Statistics Nr 2013:14 Prognostisering av växelkursindexet KIX En jämförande studie Forecasting the exchange rate index KIX A comparative
Kandidatuppsats Statistiska institutionen Bachelor thesis, Department of Statistics Nr 2013:14 Prognostisering av växelkursindexet KIX En jämförande studie Forecasting the exchange rate index KIX A comparative
Modellskattningen har gjorts med hjälp av minsta kvadratmetoden (OLS).
.") MODELLSKATTNINGAR Modeller med bäst anpassning ger inte alltid de bästa prognoserna. Grundantaganden, till exempel vilka modeller som testas, påverkar i viss grad prognosutfallet. Modellerna har, i de
MODELLSKATTNINGAR Modeller med bäst anpassning ger inte alltid de bästa prognoserna. Grundantaganden, till exempel vilka modeller som testas, påverkar i viss grad prognosutfallet. Modellerna har, i de
732G71 Statistik B. Föreläsning 8. Bertil Wegmann. IDA, Linköpings universitet. Bertil Wegmann (IDA, LiU) 732G71, Statistik B 1 / 23
 732G71, Statistik B 1 / 23") 732G71 Statistik B Föreläsning 8 Bertil Wegmann IDA, Linköpings universitet Bertil Wegmann (IDA, LiU) 732G71, Statistik B 1 / 23 Klassisk komponentuppdelning Klassisk komponentuppdelning bygger på en intuitiv
732G71 Statistik B Föreläsning 8 Bertil Wegmann IDA, Linköpings universitet Bertil Wegmann (IDA, LiU) 732G71, Statistik B 1 / 23 Klassisk komponentuppdelning Klassisk komponentuppdelning bygger på en intuitiv
Något om val mellan olika metoder
 Något om val mellan olika metoder Givet är en observerad tidsserie: y 1 y 2 y n Säsonger? Ja Nej Trend? Tidsserieregression Nej ARMA-modeller Enkel exponentiell utjämning Tidsserieregression ARIMA-modeller
Något om val mellan olika metoder Givet är en observerad tidsserie: y 1 y 2 y n Säsonger? Ja Nej Trend? Tidsserieregression Nej ARMA-modeller Enkel exponentiell utjämning Tidsserieregression ARIMA-modeller
Regressions- och Tidsserieanalys - F8
 Regressions- och Tidsserieanalys - F8 Klassisk komponentuppdelning, kap 7.1.-7.2. Linda Wänström Linköpings universitet November 26 Wänström (Linköpings universitet) F8 November 26 1 / 23 Klassisk komponentuppdelning
Regressions- och Tidsserieanalys - F8 Klassisk komponentuppdelning, kap 7.1.-7.2. Linda Wänström Linköpings universitet November 26 Wänström (Linköpings universitet) F8 November 26 1 / 23 Klassisk komponentuppdelning
Autokorrelation och Durbin-Watson testet. Patrik Zetterberg. 17 december 2012
 Föreläsning 6 Autokorrelation och Durbin-Watson testet Patrik Zetterberg 17 december 2012 1 / 14 Korrelation och autokorrelation På tidigare föreläsningar har vi analyserat korrelationer för stickprov
Föreläsning 6 Autokorrelation och Durbin-Watson testet Patrik Zetterberg 17 december 2012 1 / 14 Korrelation och autokorrelation På tidigare föreläsningar har vi analyserat korrelationer för stickprov
Tentamensgenomgång och återlämning: Måndagen 9/6 kl12.00 i B413. Därefter kan skrivningarna hämtas på studentexpeditionen, plan 7 i B-huset.
 Statistiska institutionen Nicklas Pettersson Skriftlig tentamen i Finansiell Statistik Grundnivå 7.5hp, VT2014 2014-05-26 Skrivtid: 9.00-14.00 Hjälpmedel: Godkänd miniräknare utan lagrade formler eller
Statistiska institutionen Nicklas Pettersson Skriftlig tentamen i Finansiell Statistik Grundnivå 7.5hp, VT2014 2014-05-26 Skrivtid: 9.00-14.00 Hjälpmedel: Godkänd miniräknare utan lagrade formler eller
Räkneövning 4. Om uppgifterna. 1 Uppgift 1. Statistiska institutionen Uppsala universitet. 14 december 2016
 Räkneövning 4 Statistiska institutionen Uppsala universitet 14 december 2016 Om uppgifterna Uppgift 2 kan med fördel göras med Minitab. I de fall en gur för tidsserien efterfrågas kan du antingen göra
Räkneövning 4 Statistiska institutionen Uppsala universitet 14 december 2016 Om uppgifterna Uppgift 2 kan med fördel göras med Minitab. I de fall en gur för tidsserien efterfrågas kan du antingen göra
STOCKHOLMS UNIVERSITET HT 2008 Statistiska institutionen Linda Wänström. Omtentamen i Regressionsanalys
 STOCKHOLMS UNIVERSITET HT 2008 Statistiska institutionen Linda Wänström Omtentamen i Regressionsanalys 2009-01-08 Skrivtid: 9.00-14.00 Godkända hjälpmedel: Miniräknare utan lagrade formler. Tentamen består
STOCKHOLMS UNIVERSITET HT 2008 Statistiska institutionen Linda Wänström Omtentamen i Regressionsanalys 2009-01-08 Skrivtid: 9.00-14.00 Godkända hjälpmedel: Miniräknare utan lagrade formler. Tentamen består
Utvärdering av Transportstyrelsens flygtrafiksmodeller
 Kandidatuppsats i Statistik Utvärdering av Transportstyrelsens flygtrafiksmodeller Arvid Odencrants & Dennis Dahl Abstract The Swedish Transport Agency has for a long time collected data on a monthly
Kandidatuppsats i Statistik Utvärdering av Transportstyrelsens flygtrafiksmodeller Arvid Odencrants & Dennis Dahl Abstract The Swedish Transport Agency has for a long time collected data on a monthly
Korrelation och autokorrelation
 Korrelation och autokorrelation Låt oss begrunda uttrycket r = i=1 (x i x) (y i y) n i=1 (x i x) 2 n. i=1 (y i y) 2 De kvadratsummor kring de aritmetiska medelvärdena som står i nämnaren är alltid positiva.
Korrelation och autokorrelation Låt oss begrunda uttrycket r = i=1 (x i x) (y i y) n i=1 (x i x) 2 n. i=1 (y i y) 2 De kvadratsummor kring de aritmetiska medelvärdena som står i nämnaren är alltid positiva.
Laboration 5: Regressionsanalys. 1 Förberedelseuppgifter. 2 Enkel linjär regression DATORLABORATION 5 MATEMATISK STATISTIK FÖR I, FMS 012, HT-08
 LUNDS TEKNISKA HÖGSKOLA MATEMATIKCENTRUM MATEMATISK STATISTIK Laboration 5: Regressionsanalys DATORLABORATION 5 MATEMATISK STATISTIK FÖR I, FMS 012, HT-08 Syftet med den här laborationen är att du skall
LUNDS TEKNISKA HÖGSKOLA MATEMATIKCENTRUM MATEMATISK STATISTIK Laboration 5: Regressionsanalys DATORLABORATION 5 MATEMATISK STATISTIK FÖR I, FMS 012, HT-08 Syftet med den här laborationen är att du skall
Säsongrensning i tidsserier.
 Senast ändrad 200-03-23. Säsongrensning i tidsserier. Kompletterande text till kapitel.5 i Tamhane och Dunlop. Inledning. Syftet med säsongrensning är att dela upp en tidsserie i en trend u t, en säsongkomponent
Senast ändrad 200-03-23. Säsongrensning i tidsserier. Kompletterande text till kapitel.5 i Tamhane och Dunlop. Inledning. Syftet med säsongrensning är att dela upp en tidsserie i en trend u t, en säsongkomponent
Räkneövning 5. Sebastian Andersson Statistiska institutionen Uppsala universitet 7 januari För Uppgift 2 kan man med fördel ta hjälp av Minitab.
 Räkneövning 5 Sebastian Andersson Statistiska institutionen Uppsala universitet 7 januari 016 1 Om uppgifterna För Uppgift kan man med fördel ta hjälp av Minitab. I de fall en figur för tidsserien efterfrågas
Räkneövning 5 Sebastian Andersson Statistiska institutionen Uppsala universitet 7 januari 016 1 Om uppgifterna För Uppgift kan man med fördel ta hjälp av Minitab. I de fall en figur för tidsserien efterfrågas
Lektionsanteckningar 11-12: Normalfördelningen
 Lektionsanteckningar 11-12: Normalfördelningen När utfallsrummet för en slumpvariabel kan anta vilket värde som helst i ett givet intervall är variabeln kontinuerlig. Det är väsentligt att utfallsrummet
Lektionsanteckningar 11-12: Normalfördelningen När utfallsrummet för en slumpvariabel kan anta vilket värde som helst i ett givet intervall är variabeln kontinuerlig. Det är väsentligt att utfallsrummet
ÖVNINGSUPPGIFTER KAPITEL 7
 ÖVNINGSUPPGIFTER KAPITEL 7 TIDSSERIEDIAGRAM OCH UTJÄMNING 1. En omdebatterad utveckling under 90-talet gäller den snabba ökningen i VDlöner. Tabellen nedan visar genomsnittlig kompensation för direktörer
ÖVNINGSUPPGIFTER KAPITEL 7 TIDSSERIEDIAGRAM OCH UTJÄMNING 1. En omdebatterad utveckling under 90-talet gäller den snabba ökningen i VDlöner. Tabellen nedan visar genomsnittlig kompensation för direktörer
Laboration 4: Stora talens lag, Centrala gränsvärdessatsen och enkla punktskattningar
 LUNDS TEKNISKA HÖGSKOLA MATEMATIKCENTRUM MATEMATISK STATISTIK DATORLABORATION 4 MATEMATISK STATISTIK, AK FÖR I, FMS 120, HT-00 Laboration 4: Stora talens lag, Centrala gränsvärdessatsen och enkla punktskattningar
LUNDS TEKNISKA HÖGSKOLA MATEMATIKCENTRUM MATEMATISK STATISTIK DATORLABORATION 4 MATEMATISK STATISTIK, AK FÖR I, FMS 120, HT-00 Laboration 4: Stora talens lag, Centrala gränsvärdessatsen och enkla punktskattningar
Mer om slumpvariabler
 1/20 Mer om slumpvariabler Måns Thulin Uppsala universitet thulin@math.uu.se Statistik för ingenjörer 4/2 2013 2/20 Dagens föreläsning Diskreta slumpvariabler Vilket kretskort ska man välja? Väntevärde
1/20 Mer om slumpvariabler Måns Thulin Uppsala universitet thulin@math.uu.se Statistik för ingenjörer 4/2 2013 2/20 Dagens föreläsning Diskreta slumpvariabler Vilket kretskort ska man välja? Väntevärde
Tentamensgenomgång och återlämning: Måndagen 24/2 kl16.00 i B497. Därefter kan skrivningarna hämtas på studentexpeditionen, plan 7 i B-huset.
 Statistiska institutionen Nicklas Pettersson Skriftlig tentamen i Finansiell Statistik Grundnivå 7.5hp, HT2013 2014-02-07 Skrivtid: 13.00-18.00 Hjälpmedel: Godkänd miniräknare utan lagrade formler eller
Statistiska institutionen Nicklas Pettersson Skriftlig tentamen i Finansiell Statistik Grundnivå 7.5hp, HT2013 2014-02-07 Skrivtid: 13.00-18.00 Hjälpmedel: Godkänd miniräknare utan lagrade formler eller
Ledtidsanpassa standardavvikelser för efterfrågevariationer
 Handbok i materialstyrning - Del B Parametrar och variabler B 43 Ledtidsanpassa standardavvikelser för efterfrågevariationer I affärssystem brukar standardavvikelser för efterfrågevariationer eller prognosfel
Handbok i materialstyrning - Del B Parametrar och variabler B 43 Ledtidsanpassa standardavvikelser för efterfrågevariationer I affärssystem brukar standardavvikelser för efterfrågevariationer eller prognosfel
Multipel Regressionsmodellen
 Multipel Regressionsmodellen Koefficienterna i multipel regression skattas från ett stickprov enligt: Multipel Regressionsmodell med k förklarande variabler: Skattad (predicerad) Värde på y y ˆ = b + b
Multipel Regressionsmodellen Koefficienterna i multipel regression skattas från ett stickprov enligt: Multipel Regressionsmodell med k förklarande variabler: Skattad (predicerad) Värde på y y ˆ = b + b
Reducering av svinnet i fa rskvaruhandeln genom fo rba ttrade efterfra geprognoser
 Reducering av svinnet i fa rskvaruhandeln genom fo rba ttrade efterfra geprognoser Andreas Hellborg, Martin Mellvé och Martin Strandberg Institutionen för Produktionsekonomi Lunds Tekniska Högskola Bakgrund
Reducering av svinnet i fa rskvaruhandeln genom fo rba ttrade efterfra geprognoser Andreas Hellborg, Martin Mellvé och Martin Strandberg Institutionen för Produktionsekonomi Lunds Tekniska Högskola Bakgrund
Summakonsistent säsongrensning
 Summakonsistent säsongrensning Presentation av projektarbete på SCB av Suad Elezović Statistiska institutionen,stockholms universitet 14 Oktober 2009 2009-10-14 Suad Elezović PCA/MFFM-S 1 Säsongrensning
Summakonsistent säsongrensning Presentation av projektarbete på SCB av Suad Elezović Statistiska institutionen,stockholms universitet 14 Oktober 2009 2009-10-14 Suad Elezović PCA/MFFM-S 1 Säsongrensning
Vilka indikatorer kan prognostisera BNP?
 Konjunkturbarometern april 2016 15 FÖRDJUPNING Vilka indikatorer kan prognostisera BNP? Data från Konjunkturbarometern används ofta som underlag till prognoser för svensk ekonomi. I denna fördjupning redogörs
Konjunkturbarometern april 2016 15 FÖRDJUPNING Vilka indikatorer kan prognostisera BNP? Data från Konjunkturbarometern används ofta som underlag till prognoser för svensk ekonomi. I denna fördjupning redogörs
PROGRAMFÖRKLARING I. Statistik för modellval och prediktion. Ett exempel: vågriktning och våghöjd
 Statistik för modellval och prediktion att beskriva, förklara och förutsäga Georg Lindgren PROGRAMFÖRKLARING I Matematisk statistik, Lunds universitet stik för modellval och prediktion p.1/4 Statistik
Statistik för modellval och prediktion att beskriva, förklara och förutsäga Georg Lindgren PROGRAMFÖRKLARING I Matematisk statistik, Lunds universitet stik för modellval och prediktion p.1/4 Statistik
För logitmodellen ges G (=F) av den logistiska funktionen: (= exp(z)/(1+ exp(z))
 av den logistiska funktionen: (= exp(z)/(1+ exp(z))") Logitmodellen För logitmodellen ges G (=F) av den logistiska funktionen: F(z) = e z /(1 + e z ) (= exp(z)/(1+ exp(z)) Funktionen motsvarar den kumulativa fördelningsfunktionen för en standardiserad logistiskt
Logitmodellen För logitmodellen ges G (=F) av den logistiska funktionen: F(z) = e z /(1 + e z ) (= exp(z)/(1+ exp(z)) Funktionen motsvarar den kumulativa fördelningsfunktionen för en standardiserad logistiskt
Föreläsning 1. Repetition av sannolikhetsteori. Patrik Zetterberg. 6 december 2012
 Föreläsning 1 Repetition av sannolikhetsteori Patrik Zetterberg 6 december 2012 1 / 28 Viktiga statistiska begrepp För att kunna förstå mer avancerade koncept under kursens gång är det viktigt att vi förstår
Föreläsning 1 Repetition av sannolikhetsteori Patrik Zetterberg 6 december 2012 1 / 28 Viktiga statistiska begrepp För att kunna förstå mer avancerade koncept under kursens gång är det viktigt att vi förstår
Prognostisering med glidande medelvärde
 Handbok i materialstyrning - Del F Prognostisering F 21 Prognostisering med glidande medelvärde Det som karakteriserar lagerstyrda verksamheter är att leveranstiden till kund är kortare än leveranstiden
Handbok i materialstyrning - Del F Prognostisering F 21 Prognostisering med glidande medelvärde Det som karakteriserar lagerstyrda verksamheter är att leveranstiden till kund är kortare än leveranstiden
Rättningstiden är i normalfall 15 arbetsdagar, till detta tillkommer upp till 5 arbetsdagar för administration, annars är det detta datum som gäller:
 Matematisk Statistik Provmoment: Ladokkod: Tentamen ges för: Tentamen 6.5 hp AT1MS1 DTEIN16h 7,5 högskolepoäng TentamensKod: Tentamensdatum: 1 juni 2017 Tid: 14-18 Hjälpmedel: Miniräknare Totalt antal
Matematisk Statistik Provmoment: Ladokkod: Tentamen ges för: Tentamen 6.5 hp AT1MS1 DTEIN16h 7,5 högskolepoäng TentamensKod: Tentamensdatum: 1 juni 2017 Tid: 14-18 Hjälpmedel: Miniräknare Totalt antal
Hemuppgift 2 ARMA-modeller
 Lunds Universitet Ekonomihögskolan Statistiska Institutionen STAB 13 VT11 Hemuppgift 2 ARMA-modeller 1 Inledning Denna hemuppgift är uppdelad i två delar. I den första ska ni med hjälp av olika simuleringar
Lunds Universitet Ekonomihögskolan Statistiska Institutionen STAB 13 VT11 Hemuppgift 2 ARMA-modeller 1 Inledning Denna hemuppgift är uppdelad i två delar. I den första ska ni med hjälp av olika simuleringar
Bild 1. Bild 2 Sammanfattning Statistik I. Bild 3 Hypotesprövning. Medicinsk statistik II
 Bild 1 Medicinsk statistik II Läkarprogrammet T5 HT 2014 Anna Jöud Arbets- och miljömedicin, Lunds universitet ERC Syd, Skånes Universitetssjukhus anna.joud@med.lu.se Bild 2 Sammanfattning Statistik I
Bild 1 Medicinsk statistik II Läkarprogrammet T5 HT 2014 Anna Jöud Arbets- och miljömedicin, Lunds universitet ERC Syd, Skånes Universitetssjukhus anna.joud@med.lu.se Bild 2 Sammanfattning Statistik I
F11. Kvantitativa prognostekniker
 F11 Kvantitativa prognostekniker samt repetition av kursen Kvantitativa prognostekniker Vi har gjort flera prognoser under kursen Prognoser baseras på antagandet att historien upprepar sig Trenden följer
F11 Kvantitativa prognostekniker samt repetition av kursen Kvantitativa prognostekniker Vi har gjort flera prognoser under kursen Prognoser baseras på antagandet att historien upprepar sig Trenden följer
Planering av flygplatser
 Fö 2: Prognostisering Tobias Andersson Källor Delar av materialet till denna föreläsning är hämtat från: Kap 7 av Airport Planning av Lynn S. Bezilla Edlund, Högberg, Leonardz: Beslutsmodeller redskap
Fö 2: Prognostisering Tobias Andersson Källor Delar av materialet till denna föreläsning är hämtat från: Kap 7 av Airport Planning av Lynn S. Bezilla Edlund, Högberg, Leonardz: Beslutsmodeller redskap
Föreläsning 2. Kap 3,7-3,8 4,1-4,6 5,2 5,3
 Föreläsning Kap 3,7-3,8 4,1-4,6 5, 5,3 1 Kap 3,7 och 3,8 Hur bra är modellen som vi har anpassat? Vi bedömer modellen med hjälp av ett antal kriterier: visuell bedömning, om möjligt F-test, signifikanstest
Föreläsning Kap 3,7-3,8 4,1-4,6 5, 5,3 1 Kap 3,7 och 3,8 Hur bra är modellen som vi har anpassat? Vi bedömer modellen med hjälp av ett antal kriterier: visuell bedömning, om möjligt F-test, signifikanstest
Grundläggande matematisk statistik
 Grundläggande matematisk statistik Kontinuerliga fördelningar Uwe Menzel, 8 www.matstat.de Begrepp fördelning Hur beter sig en variabel slumpmässigt? En slumpvariabel (s.v.) har en viss fördelning, d.v.s.
Grundläggande matematisk statistik Kontinuerliga fördelningar Uwe Menzel, 8 www.matstat.de Begrepp fördelning Hur beter sig en variabel slumpmässigt? En slumpvariabel (s.v.) har en viss fördelning, d.v.s.
Föreläsning 3. Prognostisering: Prognosprocess, efterfrågemodeller, prognosmodeller och prognosverktyg
 Föreläsning 3 Prognostisering: Prognosprocess, efterfrågemodeller, prognosmodeller och prognosverktyg Kursstruktur Innehåll Föreläsning Lektion Laboration Introduktion, produktionsekonomiska Fö 1 grunder,
Föreläsning 3 Prognostisering: Prognosprocess, efterfrågemodeller, prognosmodeller och prognosverktyg Kursstruktur Innehåll Föreläsning Lektion Laboration Introduktion, produktionsekonomiska Fö 1 grunder,
Samhällsmedicin, Region Gävleborg: Rapport 2015:4, Befolkningsprognos 2015.
 1 Inledning Befolkningsprognosen är framtagen av Statistiska Centralbyrån (SCB) och sträcker sig från år 2015 till år 2050. Prognosen är framtagen för Gävleborgs län som helhet, samt för länets samtliga
1 Inledning Befolkningsprognosen är framtagen av Statistiska Centralbyrån (SCB) och sträcker sig från år 2015 till år 2050. Prognosen är framtagen för Gävleborgs län som helhet, samt för länets samtliga
F8 Skattningar. Måns Thulin. Uppsala universitet Statistik för ingenjörer 14/ /17
 1/17 F8 Skattningar Måns Thulin Uppsala universitet thulin@math.uu.se Statistik för ingenjörer 14/2 2013 Inledande exempel: kullager Antag att diametern på kullager av en viss typ är normalfördelad N(µ,
1/17 F8 Skattningar Måns Thulin Uppsala universitet thulin@math.uu.se Statistik för ingenjörer 14/2 2013 Inledande exempel: kullager Antag att diametern på kullager av en viss typ är normalfördelad N(µ,
Hotellmarknadens konjunkturbarometer Augusti Stark hotellmarknad trots svagare konjunktur
 Hotellmarknadens konjunkturbarometer Augusti 19 Stark hotellmarknad trots svagare konjunktur 1 INNEHÅLL Sammanfattning / 3 Hotellföretagens förväntningar på efterfrågan / 4 De positiva förväntningarna
Hotellmarknadens konjunkturbarometer Augusti 19 Stark hotellmarknad trots svagare konjunktur 1 INNEHÅLL Sammanfattning / 3 Hotellföretagens förväntningar på efterfrågan / 4 De positiva förväntningarna
Blandade problem från elektro- och datateknik
 Blandade problem från elektro- och datateknik Sannolikhetsteori (Kapitel 1-10) E1. En viss typ av elektroniska komponenter anses ha exponentialfördelade livslängder. Efter 3000 timmar brukar 90 % av komponenterna
Blandade problem från elektro- och datateknik Sannolikhetsteori (Kapitel 1-10) E1. En viss typ av elektroniska komponenter anses ha exponentialfördelade livslängder. Efter 3000 timmar brukar 90 % av komponenterna
Statistiska Institutionen Gebrenegus Ghilagaber (docent)
") Statistiska Institutionen Gebrenegus Ghilagaber (docent) Lösningsförslag till skriftlig tentamen i FINANSIELL STATISTIK, grundnivå, 7,5 hp, VT09. Onsdagen 3 juni 2009-1 Sannolkhetslära Mobiltelefoner tillverkas
Statistiska Institutionen Gebrenegus Ghilagaber (docent) Lösningsförslag till skriftlig tentamen i FINANSIELL STATISTIK, grundnivå, 7,5 hp, VT09. Onsdagen 3 juni 2009-1 Sannolkhetslära Mobiltelefoner tillverkas
Tillämpad statistik (A5), HT15 Föreläsning 22: Tidsserieanalys I
, HT15 Föreläsning 22: Tidsserieanalys I") Tillämpad statistik (A5), HT15 Föreläsning 22: Tidsserieanalys I Sebastian Andersson Statistiska institutionen Senast uppdaterad: 15 december 2015 Data kan generellt sett delas in i tre kategorier: 1 Tvärsnittsdata:
Tillämpad statistik (A5), HT15 Föreläsning 22: Tidsserieanalys I Sebastian Andersson Statistiska institutionen Senast uppdaterad: 15 december 2015 Data kan generellt sett delas in i tre kategorier: 1 Tvärsnittsdata:
Introduktion. Konfidensintervall. Parade observationer Sammanfattning Minitab. Oberoende stickprov. Konfidensintervall. Minitab
 Uppfödning av kyckling och fiskleveroljor Statistiska jämförelser: parvisa observationer och oberoende stickprov Matematik och statistik för biologer, 10 hp Fredrik Jonsson vt 2012 Fiskleverolja tillsätts
Uppfödning av kyckling och fiskleveroljor Statistiska jämförelser: parvisa observationer och oberoende stickprov Matematik och statistik för biologer, 10 hp Fredrik Jonsson vt 2012 Fiskleverolja tillsätts
Tidsserier. Data. Vi har tittat på två typer av data
 F9 Tidsserier Data Vi har tittat på två typer av data Tvärsnittsdata: data som härrör från en bestämd tidpunkt eller tidsperiod Tidsseriedata: data som insamlats under en följd av tidpunkter eller tidsperioder
F9 Tidsserier Data Vi har tittat på två typer av data Tvärsnittsdata: data som härrör från en bestämd tidpunkt eller tidsperiod Tidsseriedata: data som insamlats under en följd av tidpunkter eller tidsperioder
LÖSNINGSFÖRSLAG TILL TENTAMEN I MATEMATISK STATISTIK 2007-08-29
 UMEÅ UNIVERSITET Institutionen för matematik och matematisk statistik Statistik för Teknologer, 5 poäng (TNK, ET, BTG) Peter Anton, Per Arnqvist Anton Grafström TENTAMEN 7-8-9 LÖSNINGSFÖRSLAG TILL TENTAMEN
UMEÅ UNIVERSITET Institutionen för matematik och matematisk statistik Statistik för Teknologer, 5 poäng (TNK, ET, BTG) Peter Anton, Per Arnqvist Anton Grafström TENTAMEN 7-8-9 LÖSNINGSFÖRSLAG TILL TENTAMEN
Välja prognosmetod En översikt
 Handbok i materialstyrning - Del F Prognostisering F 01 Välja prognosmetod En översikt All materialstyrning med avseende på att bestämma när nya inleveranser till lager skall planeras in och hur stora
Handbok i materialstyrning - Del F Prognostisering F 01 Välja prognosmetod En översikt All materialstyrning med avseende på att bestämma när nya inleveranser till lager skall planeras in och hur stora
Avsnitt 2. Modell: intuitiv statistisk
 Avsnitt 2. Modell: intuitiv statistisk En prognos är en utsaga om en framtida händelse. Vi kommer mest att syssla med numeriska prognoser. Med det menar vanligen ett tal på en intervallskala. Exempel:
Avsnitt 2. Modell: intuitiv statistisk En prognos är en utsaga om en framtida händelse. Vi kommer mest att syssla med numeriska prognoser. Med det menar vanligen ett tal på en intervallskala. Exempel:
MVE051/MSG Föreläsning 7
 MVE051/MSG810 2016 Föreläsning 7 Petter Mostad Chalmers November 23, 2016 Överblick Deskriptiv statistik Grafiska sammanfattningar. Numeriska sammanfattningar. Estimering (skattning) Teori Några exempel
MVE051/MSG810 2016 Föreläsning 7 Petter Mostad Chalmers November 23, 2016 Överblick Deskriptiv statistik Grafiska sammanfattningar. Numeriska sammanfattningar. Estimering (skattning) Teori Några exempel
OBS! Vi har nya rutiner.
 KOD: Kurskod: PM2315 Kursnamn: Psykologprogrammet, kurs 15, Metoder för psykologisk forskning (15 hp) Ansvarig lärare: Jan Johansson Hanse Tentamensdatum: 14 januari 2012 Tillåtna hjälpmedel: miniräknare
KOD: Kurskod: PM2315 Kursnamn: Psykologprogrammet, kurs 15, Metoder för psykologisk forskning (15 hp) Ansvarig lärare: Jan Johansson Hanse Tentamensdatum: 14 januari 2012 Tillåtna hjälpmedel: miniräknare
Ett A4-blad med egna handskrivna anteckningar (båda sidor) samt räknedosa.
 samt räknedosa.") Tentamen Linköpings universitet, Institutionen för datavetenskap, Statistik Kurskod och namn: Datum och tid: Jourhavande lärare: Tillåtna hjälpmedel: 732G71 Statistik B 2016-12-13, 8-12 Bertil Wegmann
Tentamen Linköpings universitet, Institutionen för datavetenskap, Statistik Kurskod och namn: Datum och tid: Jourhavande lärare: Tillåtna hjälpmedel: 732G71 Statistik B 2016-12-13, 8-12 Bertil Wegmann
Föreläsning 12: Regression
 Föreläsning 12: Regression Matematisk statistik David Bolin Chalmers University of Technology Maj 15, 2014 Binomialfördelningen Låt X Bin(n, p). Vi observerar x och vill ha information om p. p = x/n är
Föreläsning 12: Regression Matematisk statistik David Bolin Chalmers University of Technology Maj 15, 2014 Binomialfördelningen Låt X Bin(n, p). Vi observerar x och vill ha information om p. p = x/n är
Matematikcentrum 1(4) Matematisk Statistik Lunds Universitet MASB11 HT10. Laboration. Regressionsanalys (Sambandsanalys)
 Matematisk Statistik Lunds Universitet MASB11 HT10. Laboration. Regressionsanalys (Sambandsanalys)") Matematikcentrum 1(4) Matematisk Statistik Lunds Universitet MASB11 HT10 Laboration Regressionsanalys (Sambandsanalys) Grupp A: 2010-11-24, 13.15 15.00 Grupp B: 2010-11-24, 15.15 17.00 Grupp C: 2010-11-25,
Matematikcentrum 1(4) Matematisk Statistik Lunds Universitet MASB11 HT10 Laboration Regressionsanalys (Sambandsanalys) Grupp A: 2010-11-24, 13.15 15.00 Grupp B: 2010-11-24, 15.15 17.00 Grupp C: 2010-11-25,
STOCKHOLMS UNIVERSITET HT 2008 Statistiska institutionen Johan Andersson
 1 STOCKHOLMS UNIVERSITET HT 2008 Statistiska institutionen Johan Andersson Skriftlig tentamen på momentet Statistisk dataanalys III (SDA III), 3 högskolepoäng ingående i kursen Undersökningsmetodik och
1 STOCKHOLMS UNIVERSITET HT 2008 Statistiska institutionen Johan Andersson Skriftlig tentamen på momentet Statistisk dataanalys III (SDA III), 3 högskolepoäng ingående i kursen Undersökningsmetodik och
Stokastiska vektorer och multivariat normalfördelning
 Stokastiska vektorer och multivariat normalfördelning Johan Thim johanthim@liuse 3 november 08 Repetition Definition Låt X och Y vara stokastiska variabler med EX µ X, V X σx, EY µ Y samt V Y σy Kovariansen
Stokastiska vektorer och multivariat normalfördelning Johan Thim johanthim@liuse 3 november 08 Repetition Definition Låt X och Y vara stokastiska variabler med EX µ X, V X σx, EY µ Y samt V Y σy Kovariansen
Föreläsning 7: Punktskattningar
 Föreläsning 7: Punktskattningar Matematisk statistik Chalmers University of Technology September 21, 2015 Tvådimensionella fördelningar Definition En två dimensionell slumpvariabel (X, Y ) tillordnar två
Föreläsning 7: Punktskattningar Matematisk statistik Chalmers University of Technology September 21, 2015 Tvådimensionella fördelningar Definition En två dimensionell slumpvariabel (X, Y ) tillordnar två
1/31 REGRESSIONSANALYS. Statistiska institutionen, Stockholms universitet
 1/31 REGRESSIONSANALYS F1 Linda Wänström Statistiska institutionen, Stockholms universitet 2/31 Kap 4: Introduktion till regressionsanalys. Introduktion Regressionsanalys är en statistisk teknik för att
1/31 REGRESSIONSANALYS F1 Linda Wänström Statistiska institutionen, Stockholms universitet 2/31 Kap 4: Introduktion till regressionsanalys. Introduktion Regressionsanalys är en statistisk teknik för att
Full fart på den svenska hotellmarknaden
 Full fart på den svenska hotellmarknaden Utveckling första tertialet 2015 Box 3546, 103 69 Stockholm T +46 8 762 74 00 Box 404, 401 26 Göteborg T +46 31 62 94 00 Box 186, 201 21 Malmö T +46 40 35 25 00
Full fart på den svenska hotellmarknaden Utveckling första tertialet 2015 Box 3546, 103 69 Stockholm T +46 8 762 74 00 Box 404, 401 26 Göteborg T +46 31 62 94 00 Box 186, 201 21 Malmö T +46 40 35 25 00
Homework Three. Farid Bonawiede Samer Haddad Michael Litton Alexandre Messo. 28 november Time series analysis
 Homework Three Time series analysis Farid Bonawiede Samer Haddad Michael Litton Alexandre Messo 28 november 25 1 Vi ska här analysera en datamängd som består av medeltemperaturen månadsvis i New York mellan
Homework Three Time series analysis Farid Bonawiede Samer Haddad Michael Litton Alexandre Messo 28 november 25 1 Vi ska här analysera en datamängd som består av medeltemperaturen månadsvis i New York mellan
Skattning av matchningseffektiviteten. arbetsmarknaden FÖRDJUPNING
 Lönebildningsrapporten 9 FÖRDJUPNING Skattning av matchningseffektiviteten på den svenska arbetsmarknaden I denna fördjupning analyseras hur matchningseffektiviteten på den svenska arbetsmarknaden har
Lönebildningsrapporten 9 FÖRDJUPNING Skattning av matchningseffektiviteten på den svenska arbetsmarknaden I denna fördjupning analyseras hur matchningseffektiviteten på den svenska arbetsmarknaden har
Grundläggande matematisk statistik
 Grundläggande matematisk statistik Linjär Regression Uwe Menzel, 2018 uwe.menzel@slu.se; uwe.menzel@matstat.de www.matstat.de Linjär Regression y i y 5 y 3 mätvärden x i, y i y 1 x 1 x 2 x 3 x 4 x 6 x
Grundläggande matematisk statistik Linjär Regression Uwe Menzel, 2018 uwe.menzel@slu.se; uwe.menzel@matstat.de www.matstat.de Linjär Regression y i y 5 y 3 mätvärden x i, y i y 1 x 1 x 2 x 3 x 4 x 6 x
Ett A4-blad med egna handskrivna anteckningar (båda sidor) samt räknedosa.
 samt räknedosa.") Tentamen Linköpings Universitet, Institutionen för datavetenskap, Statistik Kurskod och namn: Datum och tid: Jourhavande lärare: Tillåtna hjälpmedel: 732G71 Statistik B 2015-02-06, 8-12 Bertil Wegmann
Tentamen Linköpings Universitet, Institutionen för datavetenskap, Statistik Kurskod och namn: Datum och tid: Jourhavande lärare: Tillåtna hjälpmedel: 732G71 Statistik B 2015-02-06, 8-12 Bertil Wegmann
Kapitel 17: HETEROSKEDASTICITET, ROBUSTA STANDARDFEL OCH VIKTNING
 Kapitel 17: HETEROSKEDASTICITET, ROBUSTA STANDARDFEL OCH VIKTNING När vi gör en regressionsanalys så bygger denna på vissa antaganden: Vi antar att vi dragit ett slumpmässigt sampel från en population
Kapitel 17: HETEROSKEDASTICITET, ROBUSTA STANDARDFEL OCH VIKTNING När vi gör en regressionsanalys så bygger denna på vissa antaganden: Vi antar att vi dragit ett slumpmässigt sampel från en population
Rättningstiden är i normalfall 15 arbetsdagar, annars är det detta datum som gäller:
 Statistik 2 Provmoment: Ladokkod: Tentamen ges för: TentamensKod: Tentamen SST021 ACEKO16h, ACIVE16h 7,5 högskolepoäng Tentamensdatum: 2018-05-31 Tid: 14.00-19.00 Hjälpmedel: Valfri miniräknare Linjal
Statistik 2 Provmoment: Ladokkod: Tentamen ges för: TentamensKod: Tentamen SST021 ACEKO16h, ACIVE16h 7,5 högskolepoäng Tentamensdatum: 2018-05-31 Tid: 14.00-19.00 Hjälpmedel: Valfri miniräknare Linjal
F3 Introduktion Stickprov
 Utrotningshotad tandnoting i arktiska vatten Inferens om väntevärde baserat på medelvärde och standardavvikelse Matematik och statistik för biologer, 10 hp Tandnoting är en torskliknande fisk som lever
Utrotningshotad tandnoting i arktiska vatten Inferens om väntevärde baserat på medelvärde och standardavvikelse Matematik och statistik för biologer, 10 hp Tandnoting är en torskliknande fisk som lever
Upprepade mätningar och tidsberoende analyser. Stefan Franzén Statistiker Registercentrum Västra Götaland
 Upprepade mätningar och tidsberoende analyser Stefan Franzén Statistiker Registercentrum Västra Götaland Innehåll Stort område Simpsons paradox En mätning per individ Flera mätningar per individ Flera
Upprepade mätningar och tidsberoende analyser Stefan Franzén Statistiker Registercentrum Västra Götaland Innehåll Stort område Simpsons paradox En mätning per individ Flera mätningar per individ Flera
Sammanfattning till Extremregn i nuvarande och framtida klimat
 Sammanfattning till Extremregn i nuvarande och framtida klimat SAMMANFATTNING till Klimatologirapport nr 47, 2017, Extremregn i nuvarande och framtida klimat Tre huvudsakliga resultat från rapporten är:
Sammanfattning till Extremregn i nuvarande och framtida klimat SAMMANFATTNING till Klimatologirapport nr 47, 2017, Extremregn i nuvarande och framtida klimat Tre huvudsakliga resultat från rapporten är:
Tentamen för kursen. Linjära statistiska modeller. 22 augusti
 STOCKHOLMS UNIVERSITET MATEMATISK STATISTIK Tentamen för kursen Linjära statistiska modeller 22 augusti 2008 9 14 Examinator: Anders Björkström, tel. 16 45 54, bjorks@math.su.se Återlämning: Rum 312, hus
STOCKHOLMS UNIVERSITET MATEMATISK STATISTIK Tentamen för kursen Linjära statistiska modeller 22 augusti 2008 9 14 Examinator: Anders Björkström, tel. 16 45 54, bjorks@math.su.se Återlämning: Rum 312, hus
Finansiell Statistik (GN, 7,5 hp,, HT 2008) Föreläsning 3
 Föreläsning 3") Finansiell Statistik (GN, 7,5 hp,, HT 2008) Föreläsning 3 Kontinuerliga sannolikhetsfördelningar (LLL Kap 7 & 9) Department of Statistics (Gebrenegus Ghilagaber, PhD, Associate Professor) Financial Statistics
Finansiell Statistik (GN, 7,5 hp,, HT 2008) Föreläsning 3 Kontinuerliga sannolikhetsfördelningar (LLL Kap 7 & 9) Department of Statistics (Gebrenegus Ghilagaber, PhD, Associate Professor) Financial Statistics
På väg mot ett rekordår på den svenska hotellmarknaden
 På väg mot ett rekordår på den svenska hotellmarknaden Utveckling 1-2:a tertialet 2015 Box 3546, 103 69 Stockholm T +46 8 762 74 00 Box 404, 401 26 Göteborg T +46 31 62 94 00 Box 186, 201 21 Malmö T +46
På väg mot ett rekordår på den svenska hotellmarknaden Utveckling 1-2:a tertialet 2015 Box 3546, 103 69 Stockholm T +46 8 762 74 00 Box 404, 401 26 Göteborg T +46 31 62 94 00 Box 186, 201 21 Malmö T +46
Introduktion till statistik för statsvetare
 "Det finns inget så praktiskt som en bra teori" November 2011 Repetition Vad vi gjort hitills Vi har börjat med att studera olika typer av mätningar och sedan successivt tagit fram olika beskrivande mått
"Det finns inget så praktiskt som en bra teori" November 2011 Repetition Vad vi gjort hitills Vi har börjat med att studera olika typer av mätningar och sedan successivt tagit fram olika beskrivande mått
STOCKHOLMS UNIVERSITET VT 2007 Statistiska institutionen Johan Andersson
 1 STOCKHOLMS UNIVERSITET VT 2007 Statistiska institutionen Johan Andersson Skriftlig omtentamen på momentet Statistiska metoder SDA III, 2 poäng ingående i kurserna Grundkurs i statistik 20 p samt Undersökningsmetodik
1 STOCKHOLMS UNIVERSITET VT 2007 Statistiska institutionen Johan Andersson Skriftlig omtentamen på momentet Statistiska metoder SDA III, 2 poäng ingående i kurserna Grundkurs i statistik 20 p samt Undersökningsmetodik
Första sidan är ett försättsblad (laddas ned från kurshemsidan) Alla frågor som nns i uppgiftstexten är besvarade
 Alla frågor som nns i uppgiftstexten är besvarade") HT 2011 Inlämningsuppgift 1 Statistisk teori med tillämpningar Instruktioner Ett av problemen A, B eller C tilldelas gruppen vid första övningstillfället. Rapporten ska lämnas in senast 29/9 kl 16.30.
HT 2011 Inlämningsuppgift 1 Statistisk teori med tillämpningar Instruktioner Ett av problemen A, B eller C tilldelas gruppen vid första övningstillfället. Rapporten ska lämnas in senast 29/9 kl 16.30.
Tidsserier, forts från F16 F17. Tidsserier Säsongrensning
 Tidsserier Säsongrensning F7 Tidsserier forts från F6 Vi har en variabel som varierar över tiden Ex folkmängd omsättning antal anställda (beroende variabeln/undersökningsvariabeln) Vi studerar den varje
Tidsserier Säsongrensning F7 Tidsserier forts från F6 Vi har en variabel som varierar över tiden Ex folkmängd omsättning antal anställda (beroende variabeln/undersökningsvariabeln) Vi studerar den varje
Provmoment: Tentamen 6,5 hp Ladokkod: A144TG Tentamen ges för: TGMAI17h, Maskiningenjör - Produktutveckling. Tentamensdatum: 28 maj 2018 Tid: 9-13
 Matematisk Statistik 7,5 högskolepoäng Provmoment: Tentamen 6,5 hp Ladokkod: A144TG Tentamen ges för: TGMAI17h, Maskiningenjör - Produktutveckling Tentamensdatum: 28 maj 2018 Tid: 9-13 Hjälpmedel: Miniräknare
Matematisk Statistik 7,5 högskolepoäng Provmoment: Tentamen 6,5 hp Ladokkod: A144TG Tentamen ges för: TGMAI17h, Maskiningenjör - Produktutveckling Tentamensdatum: 28 maj 2018 Tid: 9-13 Hjälpmedel: Miniräknare
Kapitel 12: TEST GÄLLANDE EN GRUPP KOEFFICIENTER - ANOVA
 Kapitel 12: TEST GÄLLANDE EN GRUPP KOEFFICIENTER - ANOVA 12.1 ANOVA I EN MULTIPEL REGRESSION Exempel: Tjänar man mer som egenföretagare? Nedan visas ett utdrag ur ett dataset som innehåller information
Kapitel 12: TEST GÄLLANDE EN GRUPP KOEFFICIENTER - ANOVA 12.1 ANOVA I EN MULTIPEL REGRESSION Exempel: Tjänar man mer som egenföretagare? Nedan visas ett utdrag ur ett dataset som innehåller information
Stockholms Univ., Statistiska Inst. Finansiell Statistik, GN, 7,5 hp, HT2008 Inlämningsuppgift (1,5hp)
") Stockholms Univ., Statistiska Inst. Finansiell Statistik, GN, 7,5 hp, HT2008 Inlämningsuppgift (1,5hp) Nicklas Pettersson 1 Anvisningar och hålltider Uppgiften löses i grupper om 2-3 personer och godkänt
Stockholms Univ., Statistiska Inst. Finansiell Statistik, GN, 7,5 hp, HT2008 Inlämningsuppgift (1,5hp) Nicklas Pettersson 1 Anvisningar och hålltider Uppgiften löses i grupper om 2-3 personer och godkänt
Diskussionsproblem för Statistik för ingenjörer
 Diskussionsproblem för Statistik för ingenjörer Måns Thulin thulin@math.uu.se Senast uppdaterad 20 februari 2013 Diskussionsproblem till Lektion 3 1. En projektledare i ett byggföretaget ska undersöka
Diskussionsproblem för Statistik för ingenjörer Måns Thulin thulin@math.uu.se Senast uppdaterad 20 februari 2013 Diskussionsproblem till Lektion 3 1. En projektledare i ett byggföretaget ska undersöka
Ett A4-blad med egna handskrivna anteckningar (båda sidor) samt räknedosa.
 samt räknedosa.") Tentamen Linköpings Universitet, Institutionen för datavetenskap, Statistik Kurskod och namn: Datum och tid: Jourhavande lärare: Tillåtna hjälpmedel: 732G71 Statistik B 2015-12-09, 8-12 Bertil Wegmann
Tentamen Linköpings Universitet, Institutionen för datavetenskap, Statistik Kurskod och namn: Datum och tid: Jourhavande lärare: Tillåtna hjälpmedel: 732G71 Statistik B 2015-12-09, 8-12 Bertil Wegmann
Nedan redovisas resultatet med hjälp av ett antal olika diagram (pkt 1-6):
:") EM-fotboll 2012 några grafer Sport är en verksamhet som genererar mängder av numerisk information som följs med stort intresse EM i fotboll är inget undantag och detta dokument visar några grafer med kommentarer
EM-fotboll 2012 några grafer Sport är en verksamhet som genererar mängder av numerisk information som följs med stort intresse EM i fotboll är inget undantag och detta dokument visar några grafer med kommentarer
ÖVNINGSUPPGIFTER KAPITEL 9
 ÖVNINGSUPPGIFTER KAPITEL 9 STOKASTISKA VARIABLER 1. Ange om följande stokastiska variabler är diskreta eller kontinuerliga: a. X = En slumpmässigt utvald person ur populationen är arbetslös, där x antar
ÖVNINGSUPPGIFTER KAPITEL 9 STOKASTISKA VARIABLER 1. Ange om följande stokastiska variabler är diskreta eller kontinuerliga: a. X = En slumpmässigt utvald person ur populationen är arbetslös, där x antar
Instuderingsfrågor till avsnittet om statistik, kursen Statistik och Metod, Psykologprogrammet på KI, T8
 1 Instuderingsfrågor till avsnittet om statistik, kursen Statistik och Metod, Psykologprogrammet på KI, T8 Dessa instuderingsfrågor är främst tänkta att stämma överens med innehållet i föreläsningarna,
1 Instuderingsfrågor till avsnittet om statistik, kursen Statistik och Metod, Psykologprogrammet på KI, T8 Dessa instuderingsfrågor är främst tänkta att stämma överens med innehållet i föreläsningarna,
Föreläsning 7: Punktskattningar
 Föreläsning 7: Punktskattningar Matematisk statistik Chalmers University of Technology April 27, 2015 Tvådimensionella fördelningar Definition En två dimensionell slumpvariabel (X, Y ) tillordnar två numeriska
Föreläsning 7: Punktskattningar Matematisk statistik Chalmers University of Technology April 27, 2015 Tvådimensionella fördelningar Definition En två dimensionell slumpvariabel (X, Y ) tillordnar två numeriska
3 Maximum Likelihoodestimering
 Lund Universitet med Lund Tekniska Högskola Finansiell Statistik Matematikcentrum, Matematisk Statistik VT 2006 Parameterestimation och linjär tidsserieanalys Denna laborationen ger en introduktion till
Lund Universitet med Lund Tekniska Högskola Finansiell Statistik Matematikcentrum, Matematisk Statistik VT 2006 Parameterestimation och linjär tidsserieanalys Denna laborationen ger en introduktion till
STOCKHOLMS UNIVERSITET HT 2007 Statistiska institutionen Johan Andersson
 1 STOCKHOLMS UNIVERSITET HT 2007 Statistiska institutionen Johan Andersson Skriftlig tentamen på momentet Statistisk dataanalys III (SDA III, statistiska metoder) 3 högskolepoäng, ingående i kursen Undersökningsmetodik
1 STOCKHOLMS UNIVERSITET HT 2007 Statistiska institutionen Johan Andersson Skriftlig tentamen på momentet Statistisk dataanalys III (SDA III, statistiska metoder) 3 högskolepoäng, ingående i kursen Undersökningsmetodik