En Raschanalys för att jämföra två svenska översättningar av en enkät som mäter hälsorelaterad livskvalitet
|
|
|
- Per-Erik Bergman
- för 7 år sedan
- Visningar:
Transkript

1 Linköpings universitet Institutionen för datavetenskap Kandidatuppsats, 15 hp Statistik och dataanalys Vårterminen 2016 LIU-IDA/STAT-G--16/009--SE En Raschanalys för att jämföra två svenska översättningar av en enkät som mäter hälsorelaterad livskvalitet A Rasch analysis to compare two Swedish translations of a Health- Related Quality of Life instrument Martina Kielén Emma Wallentinsson Handledare: Linda Wänström Examinator: Ann-Charlotte Hallberg Linköpings universitet SE Linköping, Sweden ,
2
3 Abstract During the 1980 s the non-profit organisation RAND Corporation conducted the two-year Medical Outcomes Study with the goal of creating a comprehensive medical questionnaire. The resulting 116- item questionnaire measures health related quality of life (HRQoL) topics such as physical, mental and general health. The questionnaire is available as a free resource on their web page. SF-36, which contains 36 of these questions, is distributed for a fee by the US company Quality Metric Inc. The company has translated the questionnaire into several languages, including Swedish, and has also taken license for the translations. Registercentrum sydost has made a new Swedish translation of the same questions as in the SF-36. This survey is called RAND-36 and is license free. Because Quality Metric Inc has taken license for its Swedish translation, the surveys are similar but not identical. This study aims to compare the aforementioned HRQoL-instruments to determine whether it is possible to replace the licensed questionnaire SF-36 with the license free RAND-36. The distribution of items with response options according ordinal scale were compared with Mann- Whitney U-test. The test yielded a significant difference for eight items in the measure PF (physical functioning), MH (mental health), VT (vitality) and GH (general health perceptions). The distribution of items with response options according dichotomous scale were compared with χ! -test. The test yielded significant difference for an item in the measure RE (emotional role functioning). The reliability of questionnaire was compared with ordinal alpha. In the selection the reliability between MH and VT is equivalent. The biggest difference between the surveys is the measure RP (physical role functioning) where the RAND-36 meets the requirement that the measure can be used for reliable conclusions on the individual level, which is a condition that SF-36 can t met. The probability of entering an answer, given the respondent's ability, was compared with Rasch analysis. Wald's test gave DIF between most items within the measures PF, MH, VT and GH.
4
5 Sammanfattning Under 1980-talet utförde den ideella organisationen RAND Corporation den tvååriga studien Medical Outcomes Study (MOS). Studien resulterade i en enkät med 116 frågor som mäter fysisk, psykisk och allmän hälsa. Enkäten finns tillgänglig som en fri resurs på organisationens hemsida. SF-36, som innehåller 36 av dessa frågor, distribueras dock även mot en kostnad av ett det amerikanska företaget QualityMetric Inc. Företaget har översatt enkäten till flera språk, bland annat svenska, och har även tagit licens för översättningarna. Registercentrum sydost har gjort en ny svensk översättning av samma frågor från MOS som finns i SF-36, denna enkät heter RAND-36 och är licens- och kostnadsfri. Eftersom QualityMetric Inc tagit licens för sin svenska översättning så har inte samma ordval gjorts, därmed är enkäterna lika varandra men inte identiska. Syftet med denna studie var att jämföra SF-36 och RAND-36. Frågan var om det går att ersätta den licensbelagda enkäten SF-36 med den nya svenska översättningen RAND-36, som är fri att använda för alla. Fördelningen för items (frågor) med svarsalternativ enligt ordinal skala jämfördes med Mann- Whitneys U-test. Testet gav signifikant skillnad för totalt åtta items inom hälsomått PF (fysisk funktion), MH (psykiskt välbefinnande), VT (vitalitet) och GH (allmän hälsoupplevelse). Fördelningen för items med svarsalternativ enligt dikotom skala jämfördes med χ! -test. Testet gav signifikant skillnad för ett item inom mått RE (emotionell rollfunktion). Reliabiliteten för enkäterna inom varje hälsomått jämfördes med reliabilitetskoefficienten ordinal alpha. Om ordinal alpha är större än 0.9 innebär det att måttet kan användas på individnivå, exempelvis jämföra två patienter. I urvalet är reliabiliteten samma mellan enkäterna för hälsomått MH och VT. Största skillnaden mellan enkäterna är för hälsomått RP (fysisk rollfunktion), där RAND-36 uppfyller kravet för att måttet ska kunna användas för säkra slutsatser på individnivå, vilket inte SF-36 gör. Sannolikheten att ange ett svarsalternativ, givet respondentens förmåga, jämfördes med raschanalys. Walds test gav DIF mellan flertalet items inom hälsomått PF, MH, VT och GH.
6
7 Förord Denna kandidatuppsats är ett examensarbete inom programmet för Statistik och Dataanalys vid Linköpings Universitet. Uppdragsgivare till uppsatsen är Region Östergötland. Ett stort tack till Region Östergötland för att vi fick möjlighet att utföra denna studie. Vi vill speciellt tacka Marika Wenemark och Evalill Nilsson som funnits tillgängliga att svara på frågor och kommit med värdefulla synpunkter. Vi vill även tacka vår handledare Linda Wänström, för givande möten och stöd, och vår opponent Torrin Danner för goda förslag till förbättringar av uppsatsen. Till sist vill vi passa på att tacka alla som bidragit till vår utbildning till statistiker, både kurskamrater och lärare. Linköping, juni 2016 Martina Kielén & Emma Wallentinsson
8
9 Innehåll 1. Inledning Uppdragsgivare Syfte och frågeställningar Bakgrund SF-36 och RAND Etiska och samhälleliga aspekter Tidigare liknande studier Datamaterial Metoder Mann-Whitneys U-test Pearsons χ2-test Ordinal alpha Item response theory Transformation av data Dikotom raschmodell Polytom raschmodell: Rating scale model Polytom raschmodell: Partial credit model Differential item functioning Programpaket i R Resultat och analys Jämförelse av fördelningar Ordinal alpha Raschanalys Dikotom raschmodell Rating scale model Partial credit model Slutsats Diskussion Justering för multipla tester Jämförelse av fördelningar Ordinal alpha Raschanalys Resultat... 39
10 6.6 Alternativa metoder Partiellt bortfall Referenser Bilaga 1 SF Bilaga 2 RAND Bilaga 3 R-kod omkodning data Bilaga 4 Fördelningar för alla items Bilaga 5 Ordinal alpha Bilaga 6 ICC-grafer... 60
11 1. Inledning Så gott som alla människor vill ha en god hälsa. Men vad innebär detta? Världshälsoorganisationen definierade år 1946 hälsa som "ett tillstånd av fullständigt fysiskt, psykiskt och socialt välbefinnande, inte endast frånvaro av sjukdom och funktionsnedsättning (WHO, 1946). Utifrån hälsobegreppet och dess omfattning har det sedan framtagits flertalet instrument med avsikt att kunna mäta hälsa. Ett HRQoL-instrument, Health-related quality of life, är ett instrument som mäter hälsorelaterad livskvalitet. Denna typ av instrument kan antingen vara sjukdomsspecifikt eller generellt. Ett sjukdomsspecifikt HRQoL-instrument kan hitta viktiga aspekter inom en specifik patient- eller sjukdomsgrupp, medan ett generellt HRQoL-instrument ger möjlighet till jämförelser mellan olika grupper. SF-36 och RAND-36 är två generella HRQoL-instrument som speglar WHO:s definition av hälsa. (Registercentrum sydost, 2016) SF-36 och RAND-36 grundar sig i det tvååriga forskningsprojektet Medical Outcomes Study (MOS) som utfördes under 1980-talet, på patienter med kroniska sjukdomar, av den ideella organisationen RAND Corporation i USA. Forskningsprojektet resulterade i en enkät med 116 frågor (items) som mäter fysisk, psykisk och allmän hälsa. (RAND Corporation, 2016) RAND Corporation har valt att ha resultatet av MOS tillgänglig för alla, som en fri resurs på sin webbplats. Organisationen tillåter även fri översättning av enkäten. SF-36, som innehåller 36 av frågorna från MOS, distribueras dock även mot en kostnad av det amerikanska företaget QualityMetric Inc. Företaget har översatt enkäten till flera språk, däribland svenska, och har även tagit licens för översättningarna. (Registercentrum sydost, 2016) RAND-36 är en ny svensk översättning av samma frågor från MOS som finns i SF-36. Enkäten är licens- och kostnadsfri och distribueras av Registercentrum sydost. Eftersom QualityMetric Inc tagit licens för sin svenska översättning har inte samma ordval kunnat göras, därmed är enkäterna lika men inte identiska. (Registercentrum sydost, 2016) I denna studie jämförs SF-36 och RAND-36. Frågan är om det går att ersätta den licensbelagda enkäten SF-36 med den nya svenska översättningen RAND-36, som är fri att använda för alla. 1.1 Uppdragsgivare Uppdragsgivaren till uppsatsen är Region Östergötland, enheten för hälsoanalys. Studien är en del av deras utredning angående skillnader mellan SF-36 och RAND Syfte och frågeställningar Syftet är att jämföra HRQoL-instrumenten SF-36 och RAND-36. Studien har följande frågeställningar: 1. Är fördelningen för varje item från respektive enkät samma? 2. Skiljer sig reliabiliteten mellan enkäterna? 3. Skiljer sig sannolikheten att ange ett svarsalternativ, givet respondentens förmåga, mellan enkäterna? 1.3 Bakgrund RAND Corporation är en non-profit organisation som har som mål att bedriva forskning för att få ett säkrare och tryggare, friskare och mer välmående samhälle. Organisationen bildades 1948 av företaget Douglas Aircraft för att erbjuda forskning och analys åt USA:s militäriska styrkor. Då finansierades 1
12 organisationen bland annat av den amerikanska regeringen. Under årens lopp har RAND Corporation expanderat och idag bedriver organisationen tvärvetenskaplig forskning till förmån för regeringar i fler länder, privata stiftelser och internationella organisationer på en mängd icke-försvarsfrågor. (RAND Corporation, 2016). SF-36 finns översatt till många språk och är sannolikt världens mest använda HRQoL-instrument. Många tror att enkäten är kostnadsfri att använda men så är inte fallet. För att använda instrumentet måste kunden ansöka om licens och kostnaden bestäms beroende på vad SF-36 ska användas till. (Registercentrum sydost, 2016) RAND-36 är utvecklat av Registercentrum sydost och togs fram eftersom det fanns efterfrågan om en svensk översättning som både är kostnadsfri och fri att använda för alla. Denna studie är en del av valideringen av enkäten, därmed är inte enkäten färdigvaliderad under studiens gång men har ändå släppts av Registercentrum sydost på grund av mycket hög efterfrågan. 1.4 SF-36 och RAND-36 I SF-36 och RAND-36 besvarar respondenten 36 flervalsfrågor angående sitt hälsotillstånd under de senaste fyra veckorna. Enkäterna har samma antal svarsalternativ för motsvarande frågor, men precis som frågorna kan dessa kan vara uttryckta på olika sätt. Se exempel på frågor och svarsalternativ i tabell 1. Tabell 1 Exempel på frågor SF-36 RAND-36 Svarsalternativ SF-36 I allmänhet, skulle Du I allmänhet, skulle du vilja säga att Din hälsa säga att din hälsa är? är? Är Du på grund av ditt hälsotillstånd begränsad i dessa aktiviteter nu? Om så är fallet, hur mycket? Gå mer än två kilometer Hur stor del av tiden under de senaste fyra veckorna har Du känt dig så nedstämd att ingenting kunnat muntra upp Dig? Begränsar din nuvarande hälsa dig i dessa aktiviteter? Om ja, hur mycket? Gå mer än ett par kilometer Hur mycket av tiden under de senaste fyra veckorna har du känt dig så nere att ingenting muntrat upp dig? (1) Utmärk (2) Mycket god (3) God (4) Någorlunda (5) Dålig (1) Ja, mycket begränsad (2) Ja, lite begränsad (3) Nej, inte alls begränsad (1) Hela tiden (2) Största delen av tiden (3) En hel del av tiden (4) En del av tiden (5) Lite av tiden (6) Inget av tiden Svarsalternativ RAND-36 (1) Utmärk (2) Mycket god (3) God (4) Någorlunda (5) Dålig (1) Ja, mycket begränsad (2) Ja, lite begränsad (3) Nej, inte alls begränsad (1) Hela tiden (2) Största delen av tiden (3) En stor del av tiden (4) En viss del av tiden (5) En liten del av tiden (6) Inget av tiden Se bilaga 1 för fullständiga SF-36 och bilaga 2 för RAND-36. I studien används SF-36:s beteckningar för frågorna, dessa beteckningar översätts till RAND-36 som i tabell 2. 2
13 Tabell 2 Frågebeteckningar SF-36 och RAND-36 SF-36 RAND a-j a-d a-c a-i a-d Av enkäternas 36 frågor används 35 frågor för att beräkna 8 hälsomått med hjälp av en speciell beräkningsalgoritm. Denna beräkningsalgoritm går ut på att svarsalternativet som innebär på bäst hälsa får högst poäng, det näst bästa svarsalternativet får näst högst poäng och så vidare. Sedan beräknas ett medelvärde inom varje mått. Detta medelvärde blir ett hälsomått som har ett värde mellan 0 och 100, där högt värde innebär god hälsa. Fråga nummer 2, som rör hur respondenten uppfattar sitt hälsotillstånd jämfört med ett år sen, används inte till något av måtten men redovisas ofta separat. Se tabell 3 för hälsomåtten samt vilka frågor som tillhör respektive mått. Tabell 3 Hälsomått Mått Item PF (fysisk funktion) 3a-j RP (rollfunktion-fysisk) 4a-d BP (kroppslig smärta) 7, 8 GH (allmän hälsoupplevelse) 1, 11a-d VT (vitalitet) 9a, e, g, i SF (social funktion) 6, 10 RE (rollfunktion-emotionell) 5a-c MH (psykiskt välbefinnande) 9b, c, d, f, h Varje hälsomått omfattar olika antal frågor med olika antal svarsalternativ. Svarsalternativen är antingen på ordinal eller dikotom skala (ja/nej). I uppsatsen används SF-36 Standard swedish version 1.0 och RAND-36 version 1 från Etiska och samhälleliga aspekter När all forskning genomförs är det viktigt att hålla god forskningssed och därmed ta hänsyn till etiska och samhälleliga aspekter. Vetenskapliga rådet har i sin publikation God forskningssed (Gustafsson, Hemerén & Pettersson, 2005) kommit fram till åtta grundregler: 1. Du ska tala sanning om din forskning 2. Du ska medvetet granska och redovisa utgångspunkterna 3. Du ska öppet redovisa metoder och resultat 4. Du ska öppet redovisa kommersiella intressen och andra bindningar 3
14 5. Du ska inte stjäla forskningsresultat från andra 6. Du ska hålla god ordning i din forskning, bl.a. genom dokumentation och arkivering 7. Du ska sträva efter att bedriva din forskning utan att skada människor, djur eller miljö 8. Du ska vara rättvis i din bedömning av andras forskning Studien genomförs i enlighet med dessa regler. Vidare är datamaterialet som används i studien anonymiserat och det går därmed inte på något sätt att spåra vilka som besvarat enkäterna. Således görs bedömningen att de positiva aspekterna väger tungt över, eventuella, negativa aspekter på både lång och kort sikt. 1.6 Tidigare liknande studier Eftersom denna studie är en del av utredningen angående skillnader mellan de svenska versionerna av SF-36 och RAND-36 så finns det än så länge inga liknande studier av dessa versioner. Däremot finns det studier för de engelska versionerna av enkäterna. Hays, Mazel och Sherbourne (1993) beskriver tidigare utredningar angående skillnader mellan enkäterna. Enligt skribenterna är det skillnad mellan måtten BP (kroppslig smärta) och GH (generell hälsa). Generellt ger RAND-36 ett högre värde för båda måtten vilket beror på att beräkningsalgoritmen för hälsomåtten är viktat på ett annat sätt än för SF-36. Enligt uppdragsgivaren är det skillnad för beräkningsalgoritmerna för BP och GH även för de svenska versionerna och det går att översätta gammal data från SF-36 till RAND-36, men inte tvärt om. I denna uppsats används raschanalys för att jämföra SF-36 och RAND-36. Hagell och Westergren (2011) beskriver hur raschanalys användes för att utvärdera SF-12, vilket är en kortare version av SF- 36 där enkäten är förkortad till två hälsomått; allmän fysisk hälsa och allmän psykisk hälsa. Metoden användes för att undersöka om instrumentet kunde användas för att utvärdera sjukdomsstadiet hos människor diagnostiserade med Parkinsons sjukdom. För att utreda om frågorna i enkäten uppfattas olika beroende på kön och ålder undersöktes om items visade tecken på Differential item functioning (DIF), vilket i detta fall inträffar om sannolikheten att ange ett visst svarsalternativ beror på kön eller ålder. Ingen signifikant DIF påträffades i det aktuella datamaterialet. Raschanalys kan även användas för att reducera antalet items i en enkät. Dorsey, Perkins och Wright (2000) utförde en studie för att utvärdera en enkät vars syfte var att diagnostisera gikt, som är en ledinflammation som kan drabba bland annat fot- och handleder. Med hjälp av raschanalys kunde skribenterna undersöka vilka items som inte tillförde användbar information för att kunna sätta diagnosen. 4



15 2. Datamaterial Datamaterialet består av svar från 4386 respondenter, varav 2051 respondenter har besvarat SF-36 och 2335 har besvarat RAND-36. Urval av respondenter är slumpmässigt, personer i Östergötland som är födda ett visst år har slumpats fram och bjudits in till intervju. Tilldelning av enkät är inte randomiserat. Först användes SF-36 och sedan har man succesivt börjat använda RAND-36. Under en övergångsperiod används båda enkäterna. Någon dokumentation angående det totala bortfallet har inte delgivits studien, datamaterialet används utan att kompensera för detta. Datamaterialet är strukturerat på så sätt att varje rad representerar en respondent och kolumnerna anger svar för enkätens 36 frågor. Det finns uppgifter angående kön och ålder för respondenterna, för tidpunkten då enkäten besvarades. Figur 1 Fördelning ålder Figur 1 visar åldersfördelningen för respondenterna, för respektive enkät. Det är större andel äldre respondenter som besvarat SF-36 jämfört med RAND-36, där fördelningen är mer jämn över åldrarna. Figur 2 Fördelning kön I figur 2 visas könsfördelning för respondenterna, denna fördelning skiljer sig mellan enkäterna. Det är en större andel män än kvinnor som besvarat på SF-36 och tvärtom för RAND-36. 5
16 3. Metoder 3.1 Mann-Whitneys U-test Mann-Whitneys U test kan användas för att jämföra två fördelningar av ordinal mätskala. Testet är icke-parametriskt vilket innebär att datamaterialet inte behöver antas följa någon fördelning. Följande hypotes testas (Wayne, 1990): H! : Urvalen följer samma fördelning H! : Urvalen följer inte samma fördelning Enligt Wayne (1990) behöver följande antaganden vara uppfyllda för att det ska vara möjligt att utföra testet: 1. Urvalen är slumpmässiga 2. Variabeln som studeras är kategorisk 3. Mätskalan är ordinal eller kontinuerlig I denna studie används Mann-Whitneys U-test för att jämföra fördelningar för items med svarsalternativ enligt ordinal skala. Teststatistiskan U beräknas som i Wayne (1990): U = n! n! + n! n! + 1 2!! R!!!!!!! (1) Där n 1 är antal observationer i urval 1, n 2 är antal observationer i urval 2 och R i är rangerna. Rangerna beräknas genom att alla svarsalternativ först sorteras från lägst till högst. Sedan får varje svarsalternativ en rang som går mellan 1 och antal svar. Förekommer ett svarsalternativ flera gånger blir rangen medelvärdet av rangsummorna som hör till dessa. Exempelvis får svarsalternativen (1, 2, 5, 7) rangvärdena (1, 2, 3, 4), och svarsalternativen (1, 2, 2, 3, 3, 3, 5) får rangvärdena (1, 2.5, 2.5, 5, 5, 5, 7). Vidare transformeras U till Z som sedan jämförs med en normalfördelning. När antalet i varje urval är större än 20 kan den centrala gränsvärdessatsen användas, därmed är Z approximativt normalfördelad och beräknas som i Wayne (1990): Z = U n!n! 2 n! n! (n! + n! + 1) 12 (2) 3.2 Pearsons χ 2 test Pearsons χ! -test används för att undersöka om två urval kan antas komma från samma fördelning (Wayne, 1990). I denna studie används χ! -test för att ta reda på om varje item med svarsalternativ enligt dikotom skala, från respektive enkät, kan antas följa samma fördelning. Följande hypotes testas: 6
17 H! : Urvalen följer samma fördelning H! : Urvalen följer inte samma fördelning För att kunna utföra testet hävdar Wayne (1990) att följande antaganden om datamaterialet behöver vara uppfyllda: 1. Urvalen är slumpmässiga 2. Variabeln som studeras är kategorisk 3. Det förväntade värdet i varje cell är minst 5 Vidare menar Wayne (2009) att teststatistikan χ! följer en χ! fördelning med (antal rader 1)*(antal kolumner -1) frihetsgrader. Nollhypotesen förkastas vid orimligt stort värde på teststatistikan. Teststatistikan beräknas genom att den observerade frekvensen på rad r och kolumn k (0 rk ) jämförs med den förväntade frekvensen i motsvarande cell (E rk ). Se exempelvis Wayne (2009): χ! =!!!!!!!! 0!" E!"! E!! (3) 3.3 Ordinal alpha Reliabilitet innebär tillförlitlighet för en mätning. När ett instrument utvecklas eftersträvas hög reliabilitet. Ett sätt att säkerställa detta är att beräkna en reliabilitetskoefficient. Den vanligaste reliabilitetskoefficienten är Cronbach s alpha, som kort sagt är den genomsnittliga korrelationen mellan en uppsättning items som ska mäta samma sak. (Dennick & Tavalkov, 2011) Cronbach s alpha lämpar sig dock bäst för kontinuerlig data. Ett mått som lämpar sig bättre för ordinal eller dikotom data är ordinal alpha, som precis som Cronbach s alpha får ett värde mellan 0 och 1 där högt värde betyder hög reliabilitet. (Gadermann, Guhn & Zumbo, 2012) I studien beräknas ordinal alpha för items inom varje mått för respektive enkät. Ordinal alpha baseras på den polychoriska korrelationen och beräknas som i Gadermann et al. (2012): α = n pc 1 + (n 1)pc (4) Där n är antalet items och pc är medelvärdet för alla parvisa polychoriska korrelationer. Den polychoriska korrelationen är korrelationen mellan två ordinala eller dikotoma variabler. (Gaderman et al., 2012) Nunnally (1978) rekommenderar att ordinal alpha inte bör vara mindre än 0.70 för att instrumentet ska kunna tillämpas för säkra analyser och slutsatser i forskning på gruppnivå. Detta innebär att det går att jämföra medelvärdet för hälsomåttet mellan två grupper, exempelvis cancerpatienter och MSpatienter. Vidare hävdar Nunnally (1978) att ordinal alpha bör vara större än 0.90 för att säkra analyser och slutsatser ska kunna göras på individnivå, exempelvis jämföra två patienter. 7
18 3.4 Item response theory Item response theory (IRT) är en teori som används inom bland annat psykometri för att utveckla och analysera instrument som mäter attityder, förmågor eller egenskaper. Inom IRT antas att respondentens svar beror på en eller flera latenta faktorer och frågans svårighet. IRT kan tillämpas på items med dikotom respons likväl som polytom respons. (Algina & Crocker, 1986) Rasch är en metod inom IRT där man antar att det finns en latent faktor. Metoden grundar sig i att sannolikheten att besvara ett item gynnsamt beror på respondentens förmåga och frågans svårighet. Principen för modellen i det dikotoma fallet kan jämföras med att hoppa höjdhopp; sannolikheten att person a klarar att hoppa över beror på hur mycket vederbörande tränat (förmågan) och hur högt ribban ligger (svårigheten). (Bond & Fox, 2015) Krav för att kunna tillämpa raschanalys är att varje item mäter en, och endast en, latent faktor (förmåga) och för att kunna utföra raschanalys på en uppsättning items måste dessa mäta samma latenta faktor. (Boone, Staver & Yale, 2014) I studien tillämpas metoden därmed på varje hälsomått. Bond och Fox (2015) definierar förmåga och svårighet på följande sätt: Personmått β a (eng. person ability, även kallad förmåga eller latent faktor): Ett mått som beskriver hur bra person a är. I denna studie är personmåttet det samma som respondentens psykiska, fysiska eller allmänna hälsa, beroende på inom vilket hälsomått analysen görs. I det dikotoma fallet är personmåttet det samma som andelen mest gynnsamma svarsalternativ på alla items som person a har angivit. Itemmått δ i (eng. item difficulty, även kallad svårighet): Ett mått som beskriver hur svår item i är. Exempelvis så uppfattas påståendet (1) Jag orkar gå en mil som svårare än (2) Jag orkar gå en kilometer. Det är lättare att hålla med påstående (2) än (1). I det dikotoma fallet är itemmåttet det samma andelen av det minst gynnsamma alternativet som alla respondenter angivit på item i. Personmåttet och itemmåttet transformeras och representeras på en logit-skala. Transformationen gör att måtten hamnar på samma skala och därmed kan personer och items jämföras med varandra. Vidare blir det även möjligt att utföra vanliga test för att jämföra måtten, såsom z-test och konfidensintervall, eftersom dessa får ett värde på en intervallskala. Följande formler används (Boone et al., 2014): b! = logit β! = ln β! 1 β! (5) S! = logit δ! = ln 1 δ! δ! (6) Transformation av data För att kunna utföra raschanalyserna behöver datamaterialet kodas om så att det minst gynnsamma svarsalternativet får värde 0, det näst minst gynnsamma svarsalternativet får värde 1 och så vidare. Se bilaga 3 för R-kod. I tabell 4 visas exempel på svarsalternativ som kodats om. 8
19 Tabell 4 Omkodning data Fråga (SF-36) Svarsalternativ Omkodning svarsalternativ 1. I allmänhet, skulle Du vilja säga att Din hälsa är? 4 (b) Under de senaste fyra veckorna, har Du Uträttat mindre än Du skulle önskat? 9 (a) Hur stor del av tiden under de senaste fyra veckorna har Du känt Dig riktigt pigg och stark? 11 (b) Jag är lika frisk som vem som helst av dem jag känner (1) Utmärkt (2) Mycket god (3) God (4) Någorlunda (5) Dålig (1) Ja (2) Nej (1) Hela tiden (2) Största delen av tiden (3) En hel del av tiden (4) En del av tiden (5) Lite av tiden (6) Inget av tiden (1) Stämmer precis (2) Stämmer ganska bra (3) Osäker (4) Stämmer inte särskilt bra (5) Stämmer inte alls (0) Dålig (1) Någorlunda (2) God (3) Mycket god (4) Utmärkt (0) Ja (1) Nej (0) Inget av tiden (1) Lite av tiden (2) En del av tiden (3) En hel del av tiden (4) Största delen av tiden (5) Hela tiden (0) Stämmer inte alls (1) Stämmer inte särskilt bra (2) Osäker (3) Stämmer ganska bra (4) Stämmer precis Dikotom raschmodell För items med dikotom respons beräknas sannolikheten att ange det mest gynnsamma svarsalternativet (x=1) på item i, givet förmågan b!, med en dikotom raschmodell (RM). Se exempelvis Bond och Fox (2015): P x = 1 b! ) = exp b! S! 1 + exp (b! S! ) (7) Modellen påminner mycket om logistisk regression, men här beaktas frågans svårighet (S i ) och respondentens förmåga (b a ). När sannolikheten plottas mot b! (personmått) fås en Item Characteristic Curve (ICC). Se exempelvis Bond och Fox (2015). Figur 3 ICC dikotom respons 9
20 Figur 3 visar en ICC-plot för ett item med dikotom respons. Sannolikheten att ange det mest gynnsamma alternativet ökar när personmåttet ökar. Därmed är sannolikheten att svara gynnsamt högre för en person med hög förmåga, jämfört med en person med låg förmåga. I denna studie används RM för måtten RP och RE, eftersom alla items inom dessa mått har dikotom respons Polytom raschmodell: Rating scale model Rating scale model (RSM) kan tillämpas på en uppsättning items med polytom respons under förutsättning att alla items har samma antal svarsalternativ. För dessa items fås både en generell svårighet per item (S i ) och en svårighet för varje tröskel (d it ). Tröskel t är personmåttet då sannolikheten för svarsalternativ t-1 och t är samma. En tröskelsvårighet anger därmed hur svårt det är att ange svarsalternativ t jämfört med svarsalternativ t-1. (Lustina, 2004) Sannolikheten att ange svarsalternativ x, på item i med förmågan b! beräknas som i Lustina (2004): P!" b! = exp!!!! b! c!"!! exp b! c!"!!!!!! (8) Där m är antalet trösklar på item i och c it är svårigheten för svarsalternativ t på samma item, även kallad kategorisvårighet. Sannolikheten att ange det näst minst gynnsamma svarsalternativet (c i1 ) är även den generella svårigheten S i för item i (motsvarande S i i formel 7). För t > 1 beräknas kategorisvårigheten genom att motsvarande tröskelsvårighet, d it, adderas till den generella svårigheten, se formel 9: c!" = S! + d!" (9) För t = 0 gäller: b! c!" = 0 (10) Precis som för den dikotoma raschmodellen fås en ICC när sannolikheten plottas mot b!, se exempelvis Bond och Fox (2015). Figur 4 ICC plot Figur 4 visar en ICC-plot för ett item med 3 svarsalternativ. En person med låg förmåga har högst sannolikhet att svara det minst gynnsamma svarsalternativet (0), och tvärtom. För en respondent med 10
21 personmått 0.3 är sannolikheten att svara det minst gynnsamma svarsalternativet samma som för det näst minst gynnsamma (tröskel 1). Vid personmått 3.2 är sannolikheten att svara det mest gynnsamma alternativet samma som det näst mest/minst gynnsamma (tröskel 2). För items med polytom respons går det även med hjälp av erm-paketet i R att visualisera flera items mot förmåga med en Person-item-map (PI-plot). (Hatziner, Mair & Maier, 2015) Figur 5 Person-item-map RSM I PI-plotten (figur 5) visas en uppsättning items som alla har fem svarsalternativ. Trösklarna är markerade med cirklar och den svarta punkten markerar personmåttet där sannolikheten att ange det minst gynnsamma svarsalternativet är samma som för det mest gynnsamma. PI-plotten visar att item 11a är lättast, för detta item krävs det lägst förmåga att svara gynnsamt jämfört med resterande items. Vidare är item 1 svårast, här krävs en högst förmåga för att kunna svara gynnsamt. Den övre delen av grafen visar hur personmåttet (förmågan) fördelar sig över respondenterna, här har de flesta ett personmått mellan 2 och 5. I studien används rating scale model för måtten MH, GH, VT, SF och PF. Inom dessa mått har alla items polytom respons och samma antal svarsalternativ Polytom raschmodell: Partial credit model När en uppsättning items med polytom respons inte har samma antal svarsalternativ fås ingen generell svårighet per item, varpå rating scale model (RSM) inte kan tillämpas. I detta fall används Partial credit model (PCM) som istället endast beaktar tröskelsvårigheterna. (Bond & Fox, 2015) Sannolikheten att ange svarsalternativ x på item i med förmågan b! beräknas som i Lustina (2004): P!" b! =! exp b! d!"!!!!!!!!!!! exp b! d!" (11) 11
22 Där m är antalet trösklar och d!" är svårigheten för tröskel t på item i. Skillnaden mellan PCM och RSM är att svårigheten för svarsalternativ 1 inte kan tolkas som den generella svårigheten för hela item i, därmed används tröskelsvårigheterna och inte kategorisvårigheterna. För t = 0 gäller: b! d!" = 0 (12) Kort sagt går modellen ut på att man beaktar hur många trösklar som behöver passeras. Om ett item har 5 svarsalternativ och sannolikheten för att respondenten ska svara alternativ 5 ska beräknas så behöver vederbörande passera 4 trösklar. När sannolikheten plottas mot b! fås en ICC-plot som tolkas på samma sätt som för RSM. Skillnaden är att svårigheten att besvara svarsalternativ 1 inte kan tolkas som den generella svårigheten, eftersom modellen tillåter olika antal svarsalternativ för de items som analyseras. Precis som för RSM så går det att visualisera flera items mot förmåga med en PI-plot. Figur 6 Person-item-map PCM Liksom figur 5 så visar PI-plotten i figur 6 trösklar och svårighet som är lokaliserade längs med b! (personmått). Denna uppsättning items har olika antal svarsalternativ och därmed olika antal trösklar. Det krävs en högre förmåga för att passera tröskel 1 för item 8 jämfört med item 7, då denna tröskel kräver en högre förmåga (personmått). Plotten visar även att avståndet mellan tröskel 1 och 2 är större för item 7 än item 8. Det är svårare att svara det mest gynnsamma alternativet (5) för item 7. I studien används PCM inom måttet BP eftersom dessa items har olika antal svarsalternativ. 12
23 3.4.5 Differential item functioning Differential item functioning (DIF) inträffar när respondenter med samma förmåga har olika sannolikhet att ange ett svarsalternativ på ett item på grund av att de tillhör en viss grupp, exempelvis ålder eller kön. Detta beror på att ett item har olika svårighet beroende på vilken grupp respondenten tillhör (Bond & Fox, 2015). I denna studie undersöks om det är DIF i raschmodellerna mellan SF-36 och RAND-36. Metoden som används är Walds test. Walds test används för att testa DIF för enskilda items. Testet går ut på att svårigheterna, kategorisvårigheterna respektive tröskelsvårigheterna i raschmodellerna jämförs var för sig mellan grupperna. Testvariabeln är approximativt normalfördelad, se exempelvis Thayer och Zwick (1996): Z = var S! (!) S! (!) S! (!) + var S! (!) (13) Där S! (!) är svårigheten för item i för grupp 1 och S! (!) är svårigheten för motsvarande item för grupp 2, var S! (!) beräknas på motsvarade sätt. den skattade variansen för S! (!). Z-värdet för kategori- och tröskelsvårigheterna 3.5 Programpaket i R I studien används open source-programvaran R som är ett språk och miljö för statistiska beräkningar och grafik, fri att använda för alla. När fördelningar jämförs används det inbyggda paketet stats. (R Core Team, 2015) Vidare används paketet psych (Revelle, 2015) för att beräkna ordinal alpha. Till raschanalyserna används paketet erm (Hatziner, Mair & Maier, 2015). 13
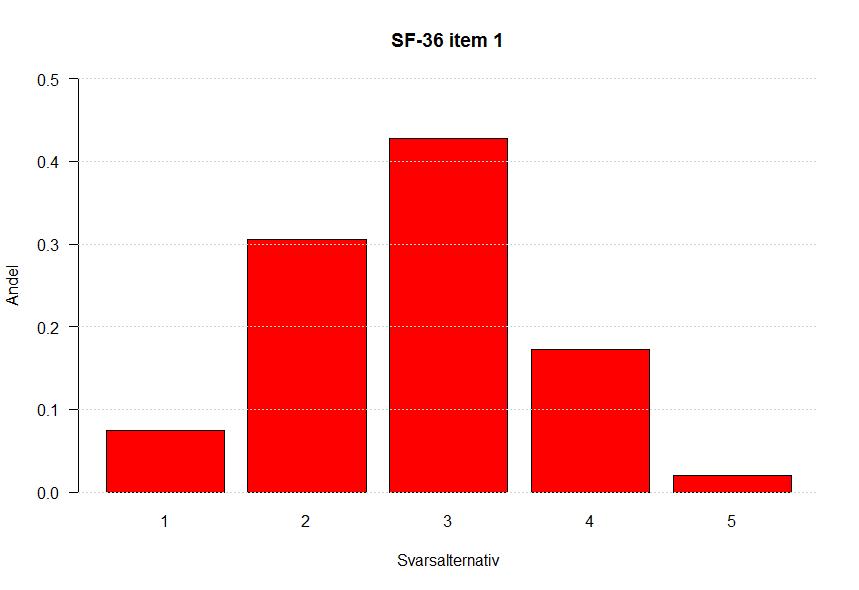
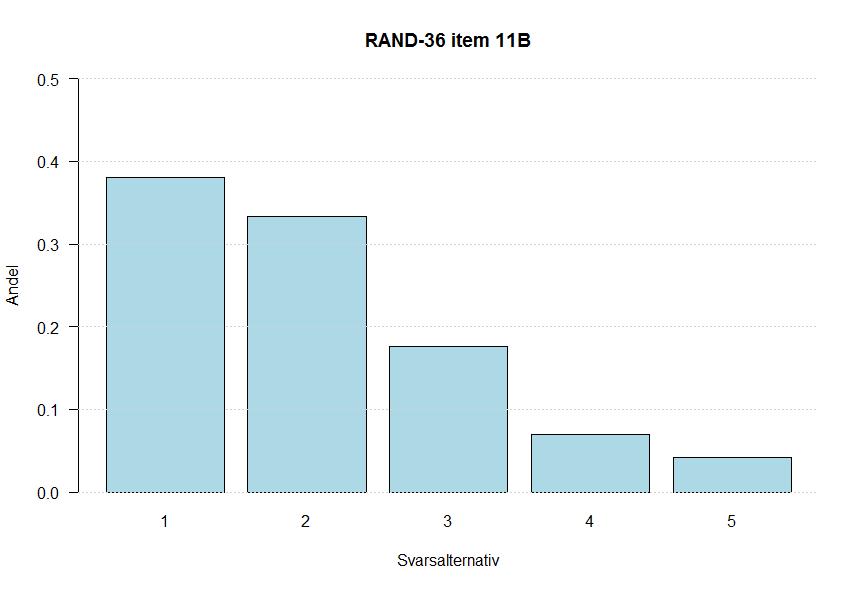
24 4. Resultat och analys I denna del presenteras och analyseras resultatet. Alla test utförs på en signifikansnivå på 5 %. 4.1 Jämförelse av fördelningar Fördelningar för varje item från respektive enkät jämförs parvis för att undersöka om de kan antas följa samma fördelning. För items med svarsalternativ enligt ordinal skala används Mann-Whitneys U- test och för items med svarsalternativ enligt dikotom skala används χ! -test. Det kritiska värdet vid Mann-Whitneys U-test är Z = 1.96, ty den centrala gränsvärdessatsen används. Teststatistikan Z beräknas som i formel 2. Se tabell 5 för resultat av testet. Tabell 5 Mann-Whitneys U-test Item Z-värde P-värde a b c d e f g h i j a b c d e f g h i a b c d Mann-Whitneys U - test ger signifikant skillnad mellan enkäterna i hela populationen för item 3h, 9a, 9b, 9c, 9h, 9i, 11b och 11c. För resterande fördelningar är det ingen signifikant skillnad. Fördelningarna för 9c och 9f visas visuellt. Se bilaga 4 för alla fördelningar. 14
25 Figur 7 Fördelningar för item 9C Figur 7 visar fördelningarna för item 9C för respektive enkät. Andelarna för svarsalternativ 5 och 6 skiljer sig i urvalet mellan enkäterna, vilket syns visuellt. Enligt Mann-Whitneys U-test är det signifikant skillnad mellan enkäterna. Figur 8 Fördelningar för item 9F För item 9F syns ingen tydlig skillnad när fördelningarna studeras visuellt (figur 8). Enligt tabell 5 är det ingen signifikant skillnad mellan enkäterna för detta item. Vidare redovisas resultat för items som jämförts med χ! -test (tabell 6). Utöver enkät så används även! kön som radvariabel. Det kritiska värdet är χ!;!!!.!" = Teststatistikan beräknas som i formel 3. Tabell 6 Chitvå-test Item χ 2 -värde P-värde 4a b c d a b c


26 χ 2 -testet ger signifikant skillnad i hela populationen för item 5b. För resterande items är det ingen signifikant skillnad. Fördelningarna för items 4c och 5b presenteras nedan visuellt. Se bilaga 4 för alla fördelningar. Figur 9 Jämförelse fördelningar för item 4c Fördelningen för item 4c verkar inte skilja sig åt i urvalet (figur 9). Enligt tabell 6 är det ingen signifikant skillnad i hela populationen mellan enkäterna för detta item. Figur 10 Jämförelse fördelningar för item 5b För item 5b syns en liten skillnad i urvalet, en lite större andel har svarat alternativ 2 för SF-36 jämfört med RAND-36 och tvärtom för svarsalternativ 1 (figur 10). χ! -testet i tabell 6 gav även signifikant skillnad mellan enkäterna för detta item. 16
27 4.2 Ordinal alpha Ordinal alpha används för att beräkna reliabiliteten inom varje mått. Ett värde över 0.7 innebär att måttet kan användas för säkra slutsatsen inom forskning på gruppnivå, medan ett värde över 0.9 innebär att det kan användas på individnivå. I tabell 7 visas ordinal alpha för enkäterna som beräknas som i formel 4. Tabell 7 Ordinal alpha Mått SF-36 RAND-36 MH GH 0.88 (0.85) BP PF (0.97) 0.96 RE RP SF VT Enligt tabell 7 är ordinal alpha samma för MH och VT, i urvalet. Den största skillnaden mellan enkäterna är för mått RP, i SF-36 är reliabilitetskoefficienten 0.88 och i RAND-36 är den Därmed uppfyller RP i RAND-36 kravet för att måttet ska kunna tillämpas på individnivå, vilket inte SF-36 gör. Mått GH uppfyller kravet för att måttet ska kunna användas för slutsatser på gruppnivå. Resterande mått kan alla användas för slutsatser på individnivå. För mått GH, RAND-36, samt mått PF, SF-36, gav R varningsmeddelanden (bilaga 5), därmed är dessa reliabilitetskoefficienter inte helt tillförlitliga. Båda varningarna innebär att det är problem med korrelationsmatrisen, determinanten blir negativ vilket inte är tillåtet. Yuan, Wu och Bentler (2011) beskriver detta problem som kan uppstå vid beräkning av den polychoriska korrelationen och menar att detta är vanligt när urvalet är litet är antal items är stort. För att komma runt detta problem så använder R en utjämningsfunktion för att tvinga fram reliabilitetskoefficienten. Till sist hävdar Yuan et al. (2011) att de statistiska konsekvenserna av detta problem inte är helt utrett och är därmed fortfarande okända. 17
28 4.3 Raschanalys Här jämförs de olika raschmodellerna mellan enkäterna. Exempel på ICC-plottar visas för varje mått, se bilaga 6 för samtliga plottar Dikotom raschmodell När en uppsättning items har dikotom respons används den dikotoma raschmodellen (RM) för att med en given förmåga beräkna sannolikheten att ange det mest gynnsamma svarsalternativt (se formel 7). Av enkäternas 8 mått innehåller RP och RE items med svarsalternativ enligt dikotom skala, varpå RM tillämpas. DIF mellan enkäterna testas med Walds test (formel 13). Inledningsvis presenteras resultatet för RP. Se jämförelse av svårigheter i tabell 8. Tabell 8 Jämförelse svårigheter RP Item Svårighet Svårighet Z-värde P-värde SF-36 RAND-36 4a b c d Enligt tabell 8 är item 4b svårast för både SF-36 och RAND-36 i urvalet, svårigheterna är respektive Item 4a har lägst svårighet; för SF-36 och för RAND-36. Därmed krävs en lägre förmåga att svara gynnsamt för item 4a jämfört med resterande items. Walds test gav inga signifikanta skillnader i svårighet mellan enkäterna. Figur 11 ICC item 4a Figur 11 visar ICC-plottarna för item 4a. Sannolikheten att svara gynnsamt ökar när personmåttet ökar. I detta fall innebär det att en respondent med hög fysisk rollfunktion har högre sannolikhet att ange det mest gynnsamma svarsalternativet, jämfört med en respondent med låg fysisk rollfunktion. Det syns inga större skillnader mellan SF-36 och RAND-36, Walds test gav inte heller någon signifikant skillnad mellan enkäterna. 18
29 Figur 12 ICC item 4b Figur 12 visar ICC-plottar för item 4b. Precis som för item 4a (figur 11) ökar sannolikheten att svara det mest gynnsamma alternativet när personmåttet (förmågan) ökar. Enligt tabell 8 är item 4b svårare än item 4a, i urvalet, vilket även syns visuellt då sannolikheten att svara gynnsamt är lägre i början av intervallet för item 4b jämfört med 4a (jämför figur 11 och 12). Det syns ingen skillnad mellan enkäterna för item 4b, enligt Walds test är det inte DIF för detta item. Vidare presenteras resultatet för mått RE. Se tabell 9 för jämförelse av svårigheter. Tabell 9 Jämförelse svårigheter RE Item Svårighet Svårighet Z-värde P-värde SF-36 RAND-36 5a b c Tabell 9 visar att item 5b har högst svårighet och att item 5a har lägst svårighet, i urvalet. Detta gäller för både SF-36 och RAND-36. Walds test gav ingen signifikant skillnad i svårighet mellan enkäterna för något item. Figur 13 ICC item 5a För item 5a ökar sannolikheten att svara gynnsamt när personmåttet ökar, detta samband gäller för båda enkäterna (figur 13). Det syns ingen större skillnad mellan enkäterna för detta item. 19
30 Figur 14 ICC item 5b I figur 14 gäller samma samband som i figur 13; sannolikheten att svara gynnsamt på item 5b ökar när personmåttet ökar. I detta fall innebär det att en person med hög emotionell rollfunktion har högre sannolikhet att ange det mest gynnsamma svarsalternativet, jämfört med en person med låg emotionell rollfunktion. Enligt tabell 9 har item 5b högre svårighet än item 5a, för båda enkäterna. Detta syns i ICC-plottarna eftersom sannolikheten att svara gynnsamt är lägre i början av intervallet för item 5b, jämfört med item 5a (se figur 13 och 14) Rating scale model Rating scale model (RSM) används för att beräkna sannolikheten att ange ett svarsalternativ, givet förmågan, på items med polytom respons under förutsättning att alla items har samma antal svarsalternativ (se formel 8). RSM används därmed för måtten MH, VT, PF, GH och SF. DIF mellan svårigheter och kategorisvårigheter testas med Walds test (formel 13). Inledningsvis presenteras och analyseras resultatet för MH. Detta mått innehåller totalt fem items som alla har sex svarsalternativ, därmed fås fem kategorisvårigheter där svårigheten för kategori 1 är samma som den generella svårigheten för respektive item. Först studeras PI-pottarna för att få en helhetsbild av hur det ser ut inom måttet. 20
31 Figur 15 PI-plot mått MH Figur 15 visar hur svåra frågorna inom MH i SF-36 är i förhållande till varandra. Item 9h är svårast, här krävs det en högre förmåga (personmått) att svara gynnsamt jämfört med resterande items. Item 9c är lättast. Figur 16 PI-plot mått MH Figur 16 visar mått MH för RAND-36. Här råder samma förhållande mellan items som det gör för SF- 36; item 9c är lättast och 9h är svårast. Fördelning över personmåtten ser också lika ut. 21
32 Se tabell 10 för jämförelse av svårigheter med Walds test. Tabell 10 Jämförelse svårigheter MH Item Kategori Svårighet Svårighet Z-värde P-värde SF-36 RAND-36 9b b b b b c c c c c d d d d d f f f f f h h h h h Tabell 10 visar att item 9h är svårast inom MH i urvalet, vilket även syns visuellt i figur 15 och 16. Svårigheten för detta item är för SF-36 och för RAND-36. Item 9c har lägst svårighet för båda enkäterna. För item 9b gav Walds test signifikant skillnad i svårighet för kategori 1 där RAND- 36 är svårare än SF-36. För item 9c gav testet DIF för samtliga kategorisvårigheter, här är SF-36 svårare än RAND-36. Vidare gav Walds test skillnad för kategorisvårigheterna 2-5 för item 9d, där SF-36 är signifikant svårare. För item 9h är det ingen signifikant skillnad för någon kategorisvårighet. Utöver att frågorna är uttryckta på olika sätt inom dessa mått så skiljer sig även formuleringarna för svarsalternativen (se tabell 1 eller bilaga 1 och 2). Exempelvis så har SF-36 formuleringen En del av tiden för alternativ 4, jämfört med En viss del av tiden för motsvarande svarsalternativ i RAND-36. Enligt resultatet i tabell 10 är SF-36:s formulering svårare. 22
33 Figur 17 ICC item 9c Figur 17 visar ICC-plottarna för item 9c. Sannolikheten att svara gynnsamt ökar när personmåttet ökar. I detta fall innebär det att en person med hög mental hälsa har större sannolikhet att svara gynnsamt, jämfört med en person med låg mental hälsa. Enligt Walds test är detta item svårare i SF- 36, vilket även syns då kurvorna ligger lite mer till höger för SF-36 jämfört med RAND-36. Detta innebär att det krävs ett högre personmått (förmåga) att svara gynnsamt för SF-36 än RAND-36. Det syns även lite skillnader för kategori 1-4 mellan enkäterna. Figur 18 ICC item 9h Enligt ICC-plottarna i figur 18 ökar sannolikheten att svara gynnsamt när personmåttet ökar för item 9h, precis som i figur 17. Det syns lite skillnader mellan enkäterna för detta item, bland annat är sannolikheten att ange kategori 1 högre för SF-36 än RAND-36 för motsvarande personmått. Dessa skillnader är inte lika markanta som för item 9c (figur 17), Walds test i tabell 10 gav inte heller någon signifikant skillnad för någon kategorisvårighet för detta item. Vidare presenteras resultatet för mått VT. Detta mått innehåller fyra items med sex svarsalternativ, varpå varje item får fem kategorisvårigheter. Inledningsvis visas PI-plottarna. 23
34 Figur 19 PI-plot mått VT Enligt PI-plotten i figur 19 så är rangordningen från lättast till svårast i mått VT; item 9g, 9i, 9a, 9e. Alltså krävs det högst förmåga att svara gynnsamt på item 9e. Figur 20 PI-plot mått VT 24
35 Figur 20 visar att rangordningen för items inom mått VT är samma för RAND-36 som för SF-36, item 9g är lättast och 9e är svårast. Se tabell 11 för jämförelse av svårigheter för mått VT. Tabell 11 Jämförelse svårigheter mått VT Item Kategori Svårighet SF- Svårighet Z-värde P-värde 36 RAND 36 9a a a a a e e e e e g g g g g i i i i i Enligt tabell 11 har item 9e högst svårighet för båda enkäterna, vilket även kan ses i figur 19 och 20. Därmed krävs det högre vitalitet att svara gynnsamt för detta item jämfört med resterande. Item 9g är lättast. För item 9a gav Walds test signifikant skillnad för den generella svårigheten (kategori 1) samt för kategorisvårighet 4 och 5, där SF-36 har högre generell svårighet medan RAND-36 har högre kategorisvårigheter. Testet gav även signifikant skillnad för samtliga svårigheter för item 9e, där RAND-36 är svårast. För item 9g gav Walds test signifikant skillnad för kategorisvårigheterna 3-5, där RAND-36 är svårast. Till sist gav testet skillnad för samtliga kategorisvårigheter för item 9i, även här är RAND-36 svårast. Precis som för MH så har svarsalternativen för frågorna inom VT olika formuleringar mellan enkäterna. Detta kan förklara varför vissa kategorisvårigheter kan skilja sig, samtidigt som den generella svårigheten inte skiljer sig (se item 9g). 25
36 Figur 21 ICC item 9a ICC-plottarna för item 9a skiljer sig något mellan enkäterna (se figur 21). Exempelvis är sannolikheten att ange kategori 4 högre för SF-36 jämfört med RAND-36, för motsvarande personmått. Enligt Walds test i tabell 11 är kategorisvårighet 4 signifikant svårare för RAND-36, jämfört med SF-36. Detta förhållande gäller även för kategori 5. Figur 22 ICC item 9i Även för item 9i skiljer sig ICC-plottarna mellan enkäterna (figur 22). Tröskel 1 ligger lite mer till höger för RAND-36 ( för SF-36 och för RAND-36), vilket innebär att frågan är svårare i denna enkät. Walds test i tabell 11 visar även att RAND-36 har högre generell svårighet än SF-36. Detta förhållande gäller för samtliga kategorisvårigheter. Vidare presenteras resultatet för PF. Detta mått innehåller 10 items där alla har 3 svarsalternativ. Därmed fås två kategorisvårigheter per item. Först presenteras PI-plottarna. 26
37 Figur 23 PI-plot mått PF PI-plotten för mått PF, SF-36, visar att item 3a är svårast och 3i är lättast. Figur 24 PI-plot mått PF 27
38 Precis som för SF-36 så är item 3a svårast och 3i lättast (se figur 24). Dock skiljer sig rangordning av svårighet för items mellan enkäterna. Exempelvis är item 3e svårare än 3h för SF-36, det omvända gäller för RAND-36. Se tabell 12 för jämförelse av svårigheter med Walds test. Tabell 12 Jämförelse svårigheter PF Item Kategori Svårighet SF- Svårighet Z-värde P-värde 36 RAND-36 3a a b b c c d d e e f f g g h h i i j j Tabell 12 visar att item 3a är svårast inom PF för respektive enkät, svårigheten för SF-36 är och för RAND-36. För detta item krävs det alltså högst fysisk förmåga att svara gynnsamt, jämfört med resterande items. Enligt Walds test är det signifikant skillnad i svårighet för item 3a, för båda kategorierna, där SF-36 har högst svårighet. För item 3b är båda kategorisvårigheterna signifikant svårare i SF-36 än RAND- 36. För item 3c och 3e skiljer sig kategorisvårighet 2, där SF-36 är svårare än RAND-36. Det är även signifikant skillnad mellan båda kategorisvårigheterna för item 3f och 3h, där SF-36 är svårare för 3f och tvärtom 3h. För item 3i är den generella svårigheten signifikant högre för RAND-36. Till sist visar Walds test på signifikant skillnad mellan kategorisvårighet 2, för item 3j, där SF-36 är svårare än RAND
39 Figur 25 ICC item 3a ICC-plottarna i figur 25 visar att tröskel 1 ligger något mer till höger för SF-36 vilket innebär att det krävs en högre förmåga att svara kategori 1 än motsvarande kategori för RAND-36. Walds test gav även signifikant skillnad i svårighet för båda kategorierna. Figur 26 ICC item 3h Figur 26 visar att både tröskel 1 och 2 ligger något mer till höger för RAND-36, det krävs därmed ett högre personmått (förmåga) att svara kategori 1 och 2 jämfört med SF-36. Walds test gav även signifikant skillnad i svårighet för båda kategorierna, där RAND-36 är svårare än SF-36. Figur 27 ICC item 3i Figur 27 visar att tröskel 1 har ett högre personmått i RAND-36 jämfört med SF-36. Skillnaden för tröskel 2 mellan enkäterna är inte lika markant. Walds test gav signifikant skillnad för kategori 1, men inte för kategori 2. 29
40 Resultatet för mått GH presenteras. Måttet innehåller fem items med fem svarsalternativ. Först visas PI-plottarna. Figur 28 PI-plot mått GH Figur 28 visar att items inom mått GH har rangordning 11a, 11b, 11c, 11d och 1, där 11a är lättast och 1 är svårast. Figur 29 PI-plot mått GH 30
41 Figur 29 visar att items inom mått GH för RAND-36 har samma rangordning i svårighet som för SF- 36. Item 11a är lättast och 1 är svårast. Se tabell 13 för jämförelse av svårigheter. Tabell 13 Jämförelse svårigheter GH Item Kategori Svårighet SF-36 Svårighet RAND-36 Z-värde P-värde a a a a b b b b c c c c d d d d Precis som figur 28 och 29 visade så har item 1 högst generell svårighet för båda enkäterna, för SF-36 är den och för RAND-36 är den Walds test gav även signifikant skillnad i svårighet för samtliga kategorisvårigheter för detta item, där SF-36 är svårare än RAND-36. För item 11a gav Walds test signifikant skillnad för den generella svårigheten, där RAND-36 är svårare än SF-36. Det samma gäller för item 11b. Testet gav ingen signifikant skillnad mellan enkäterna för item 11c. För item 11d är samtliga kategorisvårigheter signifikant svårare i SF-36 jämfört med RAND-36. Figur 30 ICC item 1 31
42 Enligt Walds test i tabell 13 så är item 1 svårare i SF-36 jämfört med motsvarande item RAND-36. Detta syns även i figur 30 då tröskel 1 ligger lite mer till höger för SF-36 jämfört med motsvarande tröskel i RAND-36. Detta samband gäller även för resterande trösklar. Figur 31 ICC item 11c Figur 31 visar ICC-plottarna för item 11c. Visuellt går det inte att se några större skillnader mellan sannolikhetskurvorna. Enligt Walds test är det inte heller någon signifikant skillnad mellan någon kategorisvårighet för enkäterna. Till sist presenteras resultatet för SF. Detta mått innehåller två items med fem svarsalternativ. Inledningsvis studeras PI-plottarna. Figur 32 PI-plot mått SF Enligt PI-plotten (figur 32) är item 10 något svårare än item 6, för SF
43 Figur 33 PI-plot mått SF Precis som för SF-36 så är item 10 något svårare än item 6 även i RAND-36. Fördelningen över personmått verkar lika mellan enkäterna (jämför figur 32 och 33). Se tabell 14 för jämförelse av svårigheter. Tabell 14 Jämförelse svårigheter mått SF Item Kategori Svårighet SF- Svårighet Z-värde P-värde 36 RAND Tabell 14 visar att item 10 har högst svårighet i båda enkäterna, vilket bekräftas det figur 32 och 33 visar. Detta innebär att det krävs en högre social funktion att svara gynnsamt för item 6 jämfört med item 10. Walds test visar inte på DIF mellan enkäterna för någon kategorisvårighet. 33
44 Figur 34 ICC item 6 Det syns inga större skillnader mellan sannolikhetskurvorna för item 6 mellan enkäterna (figur 34). Det verkar vara något högre sannolikhet att ange kategori 1 i RAND-36 jämfört med SF-36, för motsvarande personmått. Denna skillnad är dock inte signifikant. Figur 35 ICC item 10 Precis som för item 6 syns ingen större skillnad mellan enkäterna för item 10 (se figur 35). Sannolikheten att ange kategori 1 verkar vara något högre för RAND-36, men Walds test gav ingen signifikant skillnad för denna kategori Partial credit model När en uppsättning items med polytom respons har olika antal svarsalternativ fås ingen generell svårighet, varpå rating scale model inte kan tillämpas. Istället används partial credit model (PCM) som istället beaktar tröskelsvårigheterna (formel 11). I denna studie används PCM för mått BP, eftersom item 7 och 8 har olika antal svarsalternativ. Precis som för RM och RSM undersöks DIF mellan enkäterna med Walds test (formel 13). Inledningsvis visas PI-plottarna. 34
45 Figur 36 PI-plot mått BP PI-plotten i figur 36 visar att kategori 1 är något lättare för item 7 jämfört med item 8, eftersom tröskel 1 har lägre personmått för item 7. Dock har item 7 ett mer svarsalternativ än item 8, vilket innebär att kategorisvårighet 1 inte kan tolkas som den generella svårigheten. Figur 37 PI-plot mått BP Precis som för SF-36 så skiljer sig antalet svarsalternativ mellan item 7 och 8 för RAND-36. Det är svårare att ange det mest gynnsamma alternativet på item 7 jämfört med item 8. Dock syns ingen större skillnad mellan tröskel 1 för RAND-36, vilket det gjorde för SF-36 (jämför figur 36 och 37). 35
46 Tabell 15 Jämförelse svårigheter BP Item Tröskel Svårighet Svårighet Z-värde P-värde SF-36 RAND Enligt Walds test i tabell 15 är det inte DIF mellan enkäterna för någon av tröskelsvårigheterna. Figur 38 ICC item 7 ICC-plottarna i figur 38 visar på vissa skillnader mellan enkäterna. Sannolikheten att ange kategori 1 är större för SF-36 än RAND-36, men enligt Walds test är det ingen signifikant skillnad mellan enkäterna för denna tröskel. Figur 39 ICC item 8 För item 8 syns ingen större skillnad mellan ICC-plottarna (se figur 39). 36
47 5. Slutsats De olika metoderna visar på att det finns skillnader mellan enkäterna för vissa items. Studiens tre frågeställningar besvaras nedan. Är fördelningen för varje item från respektive enkät samma? Mann-Whitneys U-test gav signifikant skillnad mellan enkäterna för item 3h, 9a, 9b, 9c, 9h, 9i, 11b och 11c. Vidare gav χ! -testet signifikant skillnad för item 5b. Skiljer sig reliabiliteten mellan enkäterna? Reliabilitetskoefficienten ordinal alpha är samma i urvalet för MH och VT. Störst skillnad är det för mått RP, där RAND-36 uppfyller kravet för att måttet ska kunna användas på individnivå, vilket inte SF-36 gör. Skiljer sig sannolikheten att ange ett svarsalternativ, givet respondentens förmåga, mellan enkäterna? Sannolikheten att ange ett svarsalternativ beror i det dikotoma fallet på frågans svårighet. För mått RP och RE är det enligt Walds test ingen signifikant skillnad för den generella svårigheten. När en uppsättning items har polytom respons och samma antal svarsalternativ så beror sannolikheten att ange ett svarsalternativ på kategorisvårigheterna. För mått MH gav Walds test DIF för kategorisvårighet 1 på item 9b, samtliga kategorisvårigheter för 9c, kategorisvårighet 2-5 för 9d och 9f. För mått VT är det signifikant skillnad för item 9a kategori 1, 4 och 5, samtliga kategorisvårigheter för 9e och 9i samt kategori 2-5 för item 9g. Vidare gav Walds test skillnad inom mått PF för båda kategorisvårigheterna för item 3a, 3b, 3f och 3h, för kategori 2 i item 3c, 3e och 3j, samt för kategori 1 item 3i. Till sist är det DIF inom mått GH för alla kategorier i item 1 och 11d samt kategorisvårighet 1 för 11a och 11b. Inom mått SF är det inga signifikanta skillnader mellan kategorisvårigheterna. Mått BP innehåller två items med polytom respons som har olika antal svarsalternativ. Därmed användes PCM där sannolikheten att ange ett svarsalternativ beror på tröskelsvårigheterna. Det är ingen signifikant skillnad mellan någon av tröskelsvårigheterna. 37
48 6. Diskussion Val av metoder, studiens resultat och begräsningar samt alternativa metoder diskuteras i denna del. 6.1 Justering för multipla tester I studien utförs flera tester simultant men signifikansnivån har inte justerats för detta. En justering med exempelvis bonferronis metodik minskar risken för typ 1-fel, att nollhypotesen förkastas när nollhypotesen är sann. Dock ökar risken för typ 2-fel, vilket innebär att nollhypotesen godtas när den är falsk. Perneger (1998) resonerar kring denna problematik och statistiska dilemma och menar att en bonferronijustering skapar mer problem än vad den tillför. Bland annat antas vid en justering att alla nollhypoteser är sanna samtidigt, vilket ofta inte är intressant. I studien är det bättre att godta nollhypotesen än att förkasta den, vi vill inte ha signifikant skillnad. Därmed är det viktigare att undvika typ 2-fel än typ 1-fel. 6.2 Jämförelse av fördelningar En av metoderna i studien var att undersöka om fördelningen för respektive item är samma i SF-36 och RAND-36. Detta är ett enkelt sätt att bekanta sig med datamaterialet och identifiera skillnader. Mann-Whitney U-test och Pearsons χ! -test bedöms vara mest lämpliga för att jämföra dessa fördelningar. Vidare skiljer sig fördelning av kön och ålder i urvalen för enkäterna, se figur 1 och 2. Skillnader mellan fördelningen av items kan bero på skillnader i datamaterialet och att tilldelning av enkät inte är randomiserat. I χ! -testet har kön lagts in som radvariabel, vilket innebär att skillnaden i könsfördelning beaktas. Detta är inte möjligt i Mann-Whitneys test, så dessa signifikanta skillnader kan bero på skillnad i kön och ålder. Därmed är resultatet från χ! -testet mer tillförlitligt än resultatet från Mann-Whitneys test. 6.3 Ordinal alpha Ordinal alpha används för att jämföra reliabiliteten mellan enkäterna och därmed besvara studiens andra frågeställning. En vanligare reliabilitetskoefficient är Cronbach s alpha. Detta mått använder sig av kovariansmatrisen och för att ge säkra resultat krävs det att data är kontinuerlig. Trots detta är ett vanligt misstag att Cronbach s alpha även används på ordinal data. Problemet uppstår när svaren är skevt fördelade, då tenderar Cronbach s alpha att underskatta den sanna korrelationen mellan items. Ett bättre mått, som ska ge mer tillförlitliga resultat, är ordinal alpha som till skillnad från Cronbach använder sig av den polychoriska korrelationen. (Gadermann et al., 2012) Vid beräkning av ordinal alpha så genererade R varningsmeddelanden för mått GH i RAND-36 och mått PF i SF-36. Som tidigare nämnts är dessa reliabilitetskoefficienter därmed inte helt tillförlitliga. 6.4 Raschanalys I studien används raschanalys som är en metod inom item response theory. Denna teori ses av många som komplex och det råder delade meningar om komplexiteten väger över de positiva aspekterna eller ej. (Algina & Crocker, 1986) Enligt Boone et al. (2014) är ett vanligt fel att man antar att det råder linjäritet mellan svarsalternativ av ordinal skala. Exempelvis antas ofta felaktigt att det är samma avstånd mellan håller med, håller med delvis och håller inte med. Den enda slutsats som egentligen kan dras är att en person håller med mer eller mindre i ett påstående, men inte hur mycket mer eller mindre. Vidare menar Bond och 38
49 Fox (2015) att många är inramade i tankesättet att statistiska analyser görs på samma tillvägagångssätt oberoende av vad som mäts och hur data ser ut, även dessa författare tar upp att man inte kan anta att alla respondenter tolkar förändringarna i svarsalternativen som samma. Om parametriska tester ändå görs på ordinal data påstår Boone et al. (2014) att antaganden som normalt krävs inte uppnås och följderna av detta kan bli felaktiga slutsatser. När respondenter och items istället omvandlas till ett gemensamt logit-mått (som i formel 5 och 6) som beskriver var de ligger i förhållande till varandra så kan parametriska tester utföras med trovärdiga resultat. Först efter denna transformation går det att jämföra itemmåtten med exempelvis Walds test, som i formel 13. En fördel med raschanalys är att urvalen som jämförs inte behöver ha samma fördelning när det gäller exempelvis ålder och kön. Anledningen till detta är att man antar att respondentens svar beror på sin förmåga och frågans svårighet. Därmed antas det är två respondenter med samma förmåga har samma sannolikhet att ange ett svarsalternativ på ett specifikt item, oavsett exempelvis kön eller ålder. För en uppsättning item med polytom respons finns det två möjliga modeller; rating scale model (RSM) och partial credit model (PCM). När alla items har samma antal svarsalternativ kan både RSM och PCM tillämpas. Detta gäller inte när items har olika antal svarsalternativ, då kan endast PCM användas. Det enklaste vore kanske att då tillämpa PCM på samtliga mått, för att begränsa antalet modeller som används. Bond och Fox (2015) menar dock att RSM alltid ska användas när detta är möjligt. Detta beror på att det är samma avstånd mellan alla trösklar och en generell för varje item fås, vilket ger lättare tolkningar. Därmed ska RSM alltid användas när det är möjligt och PCM ska endast tillämpas i undantagsfall, när kravet för RSM inte är uppfyllt. 6.5 Resultat De olika metoderna gav vissa gemensamma resultat. Mann-Whitneys U-test gav signifikant skillnad för 9a, 9b, 9c, 9h, 9i. Samma items gav Walds test DIF för mellan raschmodellerna, för en eller flera kategorisvårigheter, med undantag för item 9h. För item 9a skiljer sig både frågans och svarsalternativens formulering. I SF-36 är frågan formulerad på följande sätt: Hur stor del av tiden under de senaste fyra veckorna har du känt dig riktigt pigg och stark? Motsvarande fråga i RAND-36 är formulerad på följande sätt: Hur mycket av tiden under de senaste fyra veckorna har du känt dig pigg? Enligt Walds test är frågan i SF-36 svårare att besvara gynnsamt, än den i RAND-36. Detta innebär att det krävs en högre förmåga att vara riktigt pigg och stark jämfört med pigg. Item 9b har följande formulering i båda enkäterna: Har du känt dig mycket nervös? Frågan är alltså formulerad på samma sätt, men här skiljer sig svarsalternativen vilket kan förklara varför den generella svårigheten är signifikant högre för RAND-36. Exempelvis har RAND-36 formuleringen En viss del av tiden samtidigt som SF-36 har formuleringen En del av tiden för samma svarsalternativ, som tidigare nämnts. Inom mått PF gav Walds test skillnad för flertalet items. Exempelvis är item 3g signifikant svårare i RAND-36. Formuleringen i SF-36 är följande: Gå mer än två kilometer 39
50 I RAND-36 formuleras frågan på följande sätt: Gå mer än ett par kilometer Därmed ser det ut som att ett par kilometer uppfattas som en längre sträcka än två kilometer. Flera skillnader som identifierats är små och frågan är om statistiskt signifikanta skillnader även påverkar praktiskt. Detta resonerar Dombrosky, Lyman och Wolverton (2014) kring och menar att väldigt små skillnader kan vara signifikanta på grund av att urvalet är tillräckligt stort. En statistisk signifikant skillnad behöver inte alltid betyda något i praktiken, denna skillnad behöver inte ha någon avgörande effekt. För exempelvis item 9a, kategorisvårighet 1, är skillnaden på 0.2 i svårighet signifikant, men frågan är att denna påverkar praktiskt och har en avgörande effekt. Detta går bara att spekulera i, det är svårt att ge något entydigt och odiskutabelt svar. 6.6 Alternativa metoder Som de flesta studier så finns det alternativa metoder som är möjliga att använda. I denna studie hade enkäternas faktorstrukturer kunnat jämföras genom att testa för mätvarians; om laddningarna, intercepten respektive felvarianser är lika. Istället för raschanalys hade man i det diktoma fallet kunnat använda sig av logistisk regression. Då hade en regression utförts på hela datamaterialet och version av enkät används som förklarande variabel. Om version i en sådan modell varit signifikant hade detta inneburit att det är skillnad mellan enkäterna. På samma sätt hade items med polytom respons analyserats med ordinal logistisk regression. Fördelen med rasch är det alltid fås en förklaring till en signifikant skillnad, vilket i denna studie är att en fråga i SF-36 uppfattas som svårare än motsvarande fråga i RAND-36, eller tvärt om. Dessutom tar rasch hänsyn till respondenternas förmåga och frågan svårighet, vilket gör detta resultat mer tillförlitligt. 6.7 Partiellt bortfall Datamaterialet som används i studien har partiellt bortfall vilket inte har kompenserats för med hjälp av imputering. I R-paketen stats och psych tas rader med partiellt bortfall bort. Eftersom detta bortfall är förhållandevis väldigt litet bedöms det inte påverka resultatet nämnvärt. När det gäller raschanalyserna så finns det inga krav på att en respondent besvarat alla frågor inom måtten. Respondentens förmåga beräknas med avseende på hur respondenten borde svarat givet hur vederbörande besvarat övriga frågor inom måttet, tillsammans med frågans svårighet för vilken det är partiellt bortfall. Det enda erm-paketet kräver är att varje respondent besvarat minst två frågor inom måttet. De rader som inte uppfyller detta har tagits bort. Eftersom detta bortfall är förhållandevis väldigt litet bedöms det inte påverka resultatet nämnvärt. Ett vanligt tillvägagångsätt vid imputering är att ett medelvärde beräknas utifrån totalpoängen från den aktuella respondenten. Sedan imputeras detta medelvärde istället för det saknade värdet. Denna procedur är dock endast rätt att utföra när det kan antas linjäritet mellan svarsalternativen samt att alla items mäter den latenta faktorn på samma sätt. Som det tidigare nämnts så går det inte att anta linjäritet mellan svarsalternativen, dessutom kan items inom varje hälsomått mäta den latenta faktorn (förmågan) ur olika vinklar. Därmed menar Boone et al. (2014) att denna typ av traditionell imputering inte går att utföra vid raschanalyser. 40
51 7. Referenser Algina, J. & Crocker, L. (1986). Introduction to classical and modern test theory. Orlando: Harcourt Brace Jovanovich Bentler, P-M. Wu, R. & Yuan, K-H. (2011). Ridge Structual Equation Modelling with Correlation Matrices for Ordinal and Continuous Data. BR J Math Stat Psychol. DOI: / X Bond, T.G. & Fox C.M. (2015). Applying the Rasch Model (3rd ed.). New York: Routledge Boone, W.J., Staver, J.R. & Yale, M.S. (2014). Rasch Analysis in the Human Sciences. New York: Springer Dennick, R. & Tavakol, M. (2011). Making sense of Cronbach s alpha. Tillgänglig: Dombrosky, J. Lyman, R.L. & Wolverton, S. (2014). Practical Significance: Ordinal Scale Data and Effect Size in Zooarchaeology. Journal of Osteoarchaeology volym(26). DOI /oa.2416 Dorsey, J.K. Perkins, K. & Wright, B.D. (2000). Using Rasch measurment with medical data. Rasch measurment in health sciences. Chicago MESA press Gadermann, M. Guhn, A. & Zumbo, M. (2012). Estimating ordinal reliability for Likert-type and ordinal item response data: A conceptual, empirical, and practical guide. Practical Assessment, Research & Evaluation, volym(17) ISSN Gustafsson, B. Hermerén, G. & Pettersson, B. (2005) God forskningssed, Tillgänglig: Hagell, P. & Westergren, A. (2011). Measurment Properties of the SF-12 Health Survey in Parkinson s Disease, Journal of Parkinson s Disease, , DOI: /JPD
52 Hays, R. Mazel, R. & Sherbourne, DC. (1993). The RAND 36-Item health survey, RAND, Santa Monica, CA USA. Lustina, M.J. (2004). A Comparsion of Andrich s Rating Scale Modeln and Rost s Successive Intervals Model, (Doktorsavhandling, Austin) University of Texas. Tillgänglig: Mair, P. Hatzinger, R. & Maier, M. J. (2015). erm: Extended Rasch Modeling Tillgänglig: Nunnally, J.C. (1978). Psychometric theory (2nd ed.). New York, NY: McGraw-Hill Perneger, T.V (1998). What s wrong with Bonferroni adjustments, Education and debate, volym(316) BMJ 1998;316: RAND Corporation (2016). About RAND Health. tillgänlig: RAND Corporation (2016). Medical Outcoms Study, Measures of Quality of Life Core Survey from RAND Health. Tillgänglig: R Core Team (2015). R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. Tillgänglig: Registercentrum sydost (2016). RAND-36. Tillgänglig: Revelle, W. (2015). psych: Procedures for Personality and Psychological Research, Northwestern University, Evanston, Illinois, USA, Thayer, D.T. & Zwick, R. (1996). Evaluationg the Magnitude of Differential Item Functioning in Polytomous Items, Journal of Educational and Behavioral Statistics, Volym(21). Tillgänglig: 42
53 Wayne, D.W. (1990). Applied nonparametric statistics, Boston: PWS-KENT World Health Organization, (1946). WHO definition of Health Organization, Tillgänglig: 43

54 Bilaga 1 SF-36 44

55 45
56 46
57 Bilaga 2 RAND-36 47
58 48
59 Bilaga 3 R-kod omkodning data Omkodning skalor på item 1, 2, 6, 7, 8, 9a, d, e, h, 11b, d. data2$sf1<-abs((data2$sf1)-6) data2$sf2<-abs((data2$sf2)-6) data2$sf6<-abs((data2$sf6)-6) data2$sf7<-abs((data2$sf7)-7) data2$sf8<-abs((data2$sf8)-6) data2$sf9a<-abs((data2$sf9a)-7) data2$sf9d<-abs((data2$sf9d)-7) data2$sf9e<-abs((data2$sf9e)-7) data2$sf9h<-abs((data2$sf9h)-7) data2$sf11b<-abs((data2$sf11b)-6) data2$sf11d<-abs((data2$sf11d)-6) 49

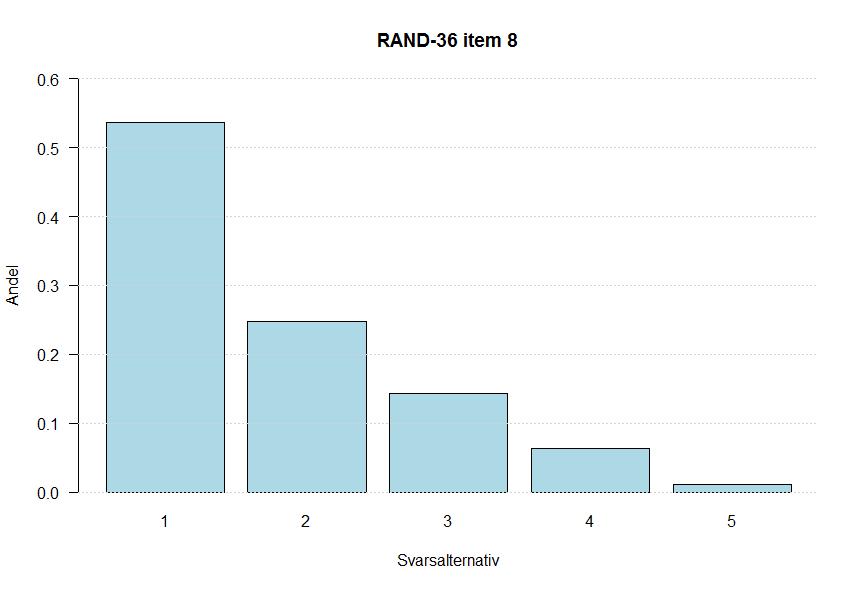
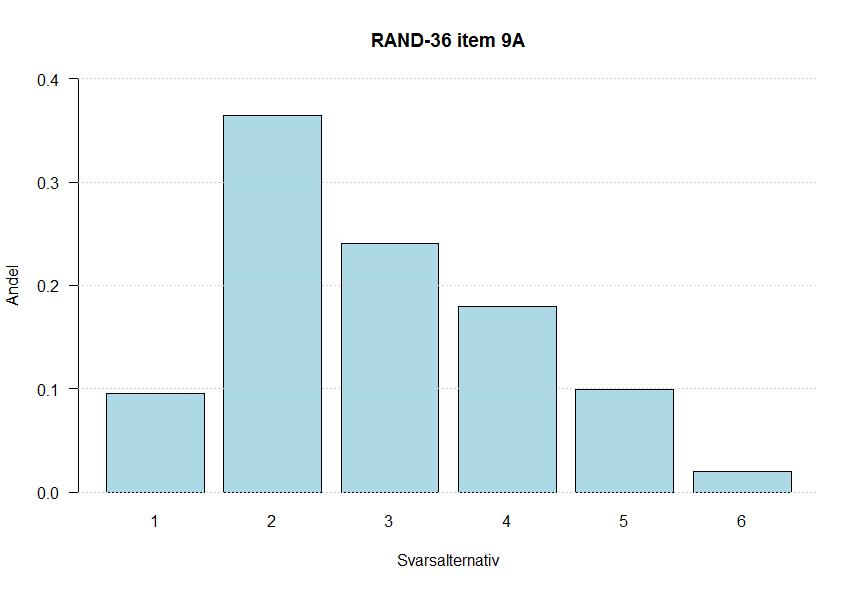
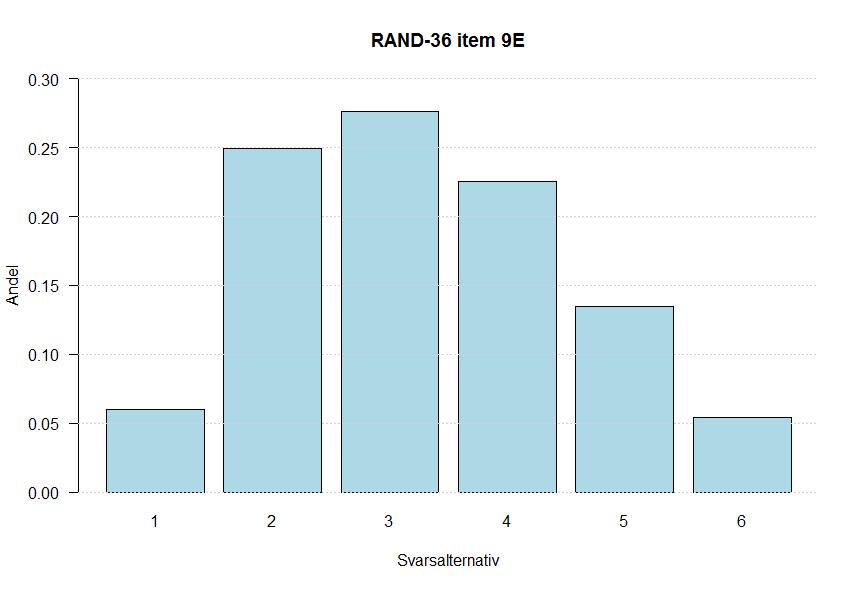
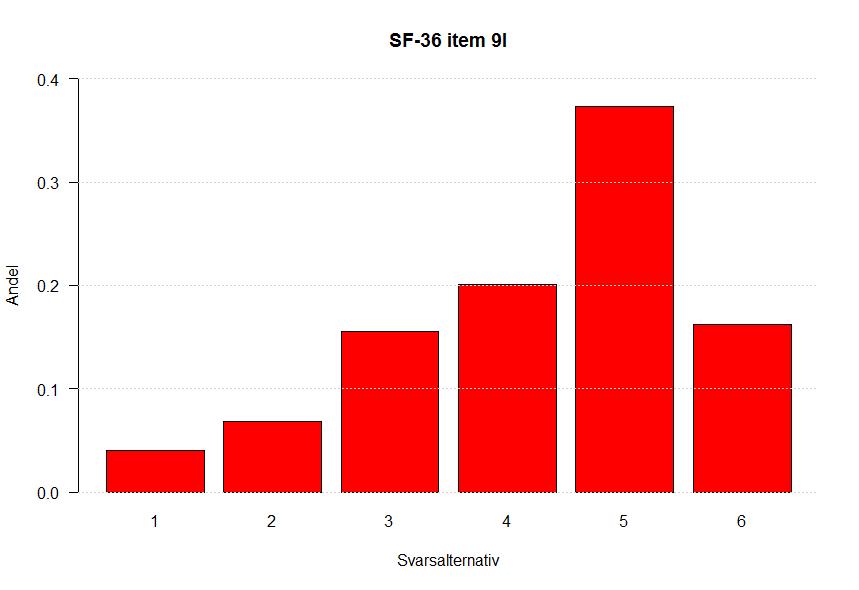
60 Bilaga 4 Fördelningar för alla items 50
61 51
62 52
63 53
64 54
65 55
66 56
67 57

68 58
SF 36 Dimensionerna och tolkning
 SF 36 Dimensionerna och tolkning 2013.08.26 Lotti Orwelius Svenska Intensivvårdsregistret 1 Vilka frågor ingår i respektive dimension? Vad krävs för att generera skalpoäng? Vad står dimensionerna för?
SF 36 Dimensionerna och tolkning 2013.08.26 Lotti Orwelius Svenska Intensivvårdsregistret 1 Vilka frågor ingår i respektive dimension? Vad krävs för att generera skalpoäng? Vad står dimensionerna för?
Patientrapporterade utfallsmått i kvalitetsregister (PROM) - användbara för forskning?
 - användbara för forskning?") Patientrapporterade utfallsmått i kvalitetsregister (PROM) - användbara för forskning? Lotti Orwelius Med Dr, Intensivvårdssjuksköterska Registercentrum sydost (RCSO) /PROMcenter Verksamhetsutvecklare
Patientrapporterade utfallsmått i kvalitetsregister (PROM) - användbara för forskning? Lotti Orwelius Med Dr, Intensivvårdssjuksköterska Registercentrum sydost (RCSO) /PROMcenter Verksamhetsutvecklare
p SF 36, RAND 36, EQ- 5D
 God Vård Socialstyrelsen föreskrift (SOSFS 2005:12) Patientrapporterade mått i vården p SF 36, RAND 36, EQ- 5D kunskapsbaserad och ändamålsenlig hälso- och sjukvård säker hälso- och sjukvård effektiv hälso-
God Vård Socialstyrelsen föreskrift (SOSFS 2005:12) Patientrapporterade mått i vården p SF 36, RAND 36, EQ- 5D kunskapsbaserad och ändamålsenlig hälso- och sjukvård säker hälso- och sjukvård effektiv hälso-
EXAMINATION KVANTITATIV METOD vt-11 (110204)
") ÖREBRO UNIVERSITET Hälsoakademin Idrott B Vetenskaplig metod EXAMINATION KVANTITATIV METOD vt-11 (110204) Examinationen består av 11 frågor, flera med tillhörande följdfrågor. Besvara alla frågor i direkt
ÖREBRO UNIVERSITET Hälsoakademin Idrott B Vetenskaplig metod EXAMINATION KVANTITATIV METOD vt-11 (110204) Examinationen består av 11 frågor, flera med tillhörande följdfrågor. Besvara alla frågor i direkt
IPS-Arbetscoacher. GHQ12 - Självskattad psykisk hälsa och hälsorelaterad livskvalitet Uppföljning av projektdeltagare. Inna Feldman Hälsoekonom, PhD
 IPS-Arbetscoacher GHQ12 - Självskattad psykisk hälsa och hälsorelaterad livskvalitet Uppföljning av projektdeltagare Inna Feldman Hälsoekonom, PhD November 2016 1 Sammanfattning General Health Questionnaire
IPS-Arbetscoacher GHQ12 - Självskattad psykisk hälsa och hälsorelaterad livskvalitet Uppföljning av projektdeltagare Inna Feldman Hälsoekonom, PhD November 2016 1 Sammanfattning General Health Questionnaire
Hypotesprövning. Andrew Hooker. Division of Pharmacokinetics and Drug Therapy Department of Pharmaceutical Biosciences Uppsala University
 Hypotesprövning Andrew Hooker Division of Pharmacokinetics and Drug Therapy Department of Pharmaceutical Biosciences Uppsala University Hypotesprövning Liksom konfidensintervall ett hjälpmedel för att
Hypotesprövning Andrew Hooker Division of Pharmacokinetics and Drug Therapy Department of Pharmaceutical Biosciences Uppsala University Hypotesprövning Liksom konfidensintervall ett hjälpmedel för att
Parade och oparade test
 Parade och oparade test Andrew Hooker Division of Pharmacokinetics and Drug Therapy Department of Pharmaceutical Biosciences Uppsala University Hypotesprövning: möjliga jämförelser Jämförelser mot ett
Parade och oparade test Andrew Hooker Division of Pharmacokinetics and Drug Therapy Department of Pharmaceutical Biosciences Uppsala University Hypotesprövning: möjliga jämförelser Jämförelser mot ett
EXAMINATION KVANTITATIV METOD vt-11 (110319)
") ÖREBRO UNIVERSITET Hälsoakademin Idrott B Vetenskaplig metod EXAMINATION KVANTITATIV METOD vt-11 (110319) Examinationen består av 10 frågor, flera med tillhörande följdfrågor. Besvara alla frågor i direkt
ÖREBRO UNIVERSITET Hälsoakademin Idrott B Vetenskaplig metod EXAMINATION KVANTITATIV METOD vt-11 (110319) Examinationen består av 10 frågor, flera med tillhörande följdfrågor. Besvara alla frågor i direkt
Föreläsning 5. Kapitel 6, sid Inferens om en population
 Föreläsning 5 Kapitel 6, sid 153-185 Inferens om en population 2 Agenda Statistisk inferens om populationsmedelvärde Statistisk inferens om populationsandel Punktskattning Konfidensintervall Hypotesprövning
Föreläsning 5 Kapitel 6, sid 153-185 Inferens om en population 2 Agenda Statistisk inferens om populationsmedelvärde Statistisk inferens om populationsandel Punktskattning Konfidensintervall Hypotesprövning
7.3.3 Nonparametric Mann-Whitney test
 7.3.3 Nonparametric Mann-Whitney test Vi har sett hur man kan testa om två populationer har samma väntevärde (H 0 : μ 1 = μ 2 ) med t-test (two-sample). Vad gör man om data inte är normalfördelat? Om vi
7.3.3 Nonparametric Mann-Whitney test Vi har sett hur man kan testa om två populationer har samma väntevärde (H 0 : μ 1 = μ 2 ) med t-test (two-sample). Vad gör man om data inte är normalfördelat? Om vi
Kursens upplägg. Roller. Läs studiehandledningen!! Examinatorn - extern granskare (se särskilt dokument)
") Kursens upplägg v40 - inledande föreläsningar och börja skriva PM 19/12 - deadline PM till examinatorn 15/1- PM examinationer, grupp 1 18/1 - Forskningsetik, riktlinjer uppsatsarbetet 10/3 - deadline uppsats
Kursens upplägg v40 - inledande föreläsningar och börja skriva PM 19/12 - deadline PM till examinatorn 15/1- PM examinationer, grupp 1 18/1 - Forskningsetik, riktlinjer uppsatsarbetet 10/3 - deadline uppsats
Föreläsning 4. NDAB01 Statistik; teori och tillämpning i biologi
 Föreläsning 4 Statistik; teori och tillämpning i biologi 1 Dagens föreläsning o Icke-parametriska test Mann-Whitneys test (kap 8.10 8.11) Wilcoxons test (kap 9.5) o Transformationer (kap 13) o Ev. Andelar
Föreläsning 4 Statistik; teori och tillämpning i biologi 1 Dagens föreläsning o Icke-parametriska test Mann-Whitneys test (kap 8.10 8.11) Wilcoxons test (kap 9.5) o Transformationer (kap 13) o Ev. Andelar
Regionhabiliteringen i Göteborg
 Regionhabiliteringen i Göteborg Lost in transition Vuxna med myelomeningocele En intervjustudie Magdalena Vu Minh Arnell Leg sjuksköterska/uroterapeut SU/Regionhabiliteringen UroTarmhabiliteringen Drottning
Regionhabiliteringen i Göteborg Lost in transition Vuxna med myelomeningocele En intervjustudie Magdalena Vu Minh Arnell Leg sjuksköterska/uroterapeut SU/Regionhabiliteringen UroTarmhabiliteringen Drottning
Gamla tentor (forts) ( x. x ) ) 2 x1
 ( x. x ) ) 2 x1") 016-10-10 Gamla tentor - 016 1 1 (forts) ( x ) x1 x ) ( 1 x 1 016-10-10. En liten klinisk ministudie genomförs för att undersöka huruvida kostomläggning och ett träningsprogram lyckas sänka blodsockernivån
016-10-10 Gamla tentor - 016 1 1 (forts) ( x ) x1 x ) ( 1 x 1 016-10-10. En liten klinisk ministudie genomförs för att undersöka huruvida kostomläggning och ett träningsprogram lyckas sänka blodsockernivån
Instrument för att mäta generell hälsorelaterad livskvalitet (HRQoL)
") Instrument för att mäta generell hälsorelaterad livskvalitet (HRQoL) Två viktiga generiska (generella) HRQoL-instrument som ofta används i Sverige idag är SF-36 (Short Form-36) och EQ-5D (fd EuroQoL).
Instrument för att mäta generell hälsorelaterad livskvalitet (HRQoL) Två viktiga generiska (generella) HRQoL-instrument som ofta används i Sverige idag är SF-36 (Short Form-36) och EQ-5D (fd EuroQoL).
Hypotestestning och repetition
 Hypotestestning och repetition Statistisk inferens Vid inferens använder man urvalet för att uttala sig om populationen Centralmått Medelvärde: x= Σx i / n Median Typvärde Spridningsmått Används för att
Hypotestestning och repetition Statistisk inferens Vid inferens använder man urvalet för att uttala sig om populationen Centralmått Medelvärde: x= Σx i / n Median Typvärde Spridningsmått Används för att
Kurskod: TAMS28 MATEMATISK STATISTIK Provkod: TEN1 05 June 2017, 14:00-18:00. English Version
 Kurskod: TAMS28 MATEMATISK STATISTIK Provkod: TEN1 5 June 217, 14:-18: Examiner: Zhenxia Liu (Tel: 7 89528). Please answer in ENGLISH if you can. a. You are allowed to use a calculator, the formula and
Kurskod: TAMS28 MATEMATISK STATISTIK Provkod: TEN1 5 June 217, 14:-18: Examiner: Zhenxia Liu (Tel: 7 89528). Please answer in ENGLISH if you can. a. You are allowed to use a calculator, the formula and
HFS Hälsovinstmätningsprojekt
 HFS Hälsovinstmätningsprojekt Evalill Nilsson HFS Nationella konferens Malmö 061026 Vad är hälsovinstmätning? Med hälsovinstmätning menar vi mätning av patienternas självskattade hälsa, före och efter
HFS Hälsovinstmätningsprojekt Evalill Nilsson HFS Nationella konferens Malmö 061026 Vad är hälsovinstmätning? Med hälsovinstmätning menar vi mätning av patienternas självskattade hälsa, före och efter
Regressions- och Tidsserieanalys - F4
 Regressions- och Tidsserieanalys - F4 Modellbygge och residualanalys. Kap 5.1-5.4 (t.o.m. halva s 257), ej C-statistic s 23. Linda Wänström Linköpings universitet Wänström (Linköpings universitet) F4 1
Regressions- och Tidsserieanalys - F4 Modellbygge och residualanalys. Kap 5.1-5.4 (t.o.m. halva s 257), ej C-statistic s 23. Linda Wänström Linköpings universitet Wänström (Linköpings universitet) F4 1
Föreläsning 6. NDAB01 Statistik; teori och tillämpning i biologi
 Föreläsning 6 Statistik; teori och tillämpning i biologi 1 Analysis of Variance (ANOVA) (GB s. 202-218, BB s. 190-206) ANOVA är en metod som används när man ska undersöka skillnader mellan flera olika
Föreläsning 6 Statistik; teori och tillämpning i biologi 1 Analysis of Variance (ANOVA) (GB s. 202-218, BB s. 190-206) ANOVA är en metod som används när man ska undersöka skillnader mellan flera olika
Föreläsning G60 Statistiska metoder
 Föreläsning 8 Statistiska metoder 1 Dagens föreläsning o Chi-två-test Analys av enkla frekvenstabeller Analys av korstabeller (tvåvägs-tabeller) Problem med detta test o Fishers exakta test 2 Analys av
Föreläsning 8 Statistiska metoder 1 Dagens föreläsning o Chi-två-test Analys av enkla frekvenstabeller Analys av korstabeller (tvåvägs-tabeller) Problem med detta test o Fishers exakta test 2 Analys av
Två innebörder av begreppet statistik. Grundläggande tankegångar i statistik. Vad är ett stickprov? Stickprov och urval
 Två innebörder av begreppet statistik Grundläggande tankegångar i statistik Matematik och statistik för biologer, 10 hp Informationshantering. Insamling, ordningsskapande, presentation och grundläggande
Två innebörder av begreppet statistik Grundläggande tankegångar i statistik Matematik och statistik för biologer, 10 hp Informationshantering. Insamling, ordningsskapande, presentation och grundläggande
ST-fredag i Biostatistik & Epidemiologi När ska jag använda vilket test?
 ST-fredag i Biostatistik & Epidemiologi När ska jag använda vilket test? Mikael Eriksson Specialistläkare CIVA Karolinska Universitetssjukhuset, Solna Grund för hypotestestning 1. Definiera noll- och alternativhypotes,
ST-fredag i Biostatistik & Epidemiologi När ska jag använda vilket test? Mikael Eriksson Specialistläkare CIVA Karolinska Universitetssjukhuset, Solna Grund för hypotestestning 1. Definiera noll- och alternativhypotes,
Tentamen på Statistik och kvantitativa undersökningar STA001, 15 hp. Exempeltenta 4
 MÄLARDALENS HÖGSKOLA Akademin för hållbar samhälls- och teknikutveckling Statistik Tentamen på Statistik och kvantitativa undersökningar STA001, 15 hp Tillåtna hjälpmedel: Miniräknare (Formelsamling bifogas
MÄLARDALENS HÖGSKOLA Akademin för hållbar samhälls- och teknikutveckling Statistik Tentamen på Statistik och kvantitativa undersökningar STA001, 15 hp Tillåtna hjälpmedel: Miniräknare (Formelsamling bifogas
Resultatsammanställning
 Resultatsammanställning Samordningsförbundet Östra Östergötland Kvartal 1-3 2016 @Therése Löwgren Sidan 3 Måluppfyllelse kvartal 3 Sidan 13-14 NP-samverkan Sidan 4 Måluppfyllelse kvartal 2 Sidan 15-16
Resultatsammanställning Samordningsförbundet Östra Östergötland Kvartal 1-3 2016 @Therése Löwgren Sidan 3 Måluppfyllelse kvartal 3 Sidan 13-14 NP-samverkan Sidan 4 Måluppfyllelse kvartal 2 Sidan 15-16
Föreläsning 2. NDAB01 Statistik; teori och tillämpning i biologi
 Föreläsning 2 Statistik; teori och tillämpning i biologi 1 Normalfördelning Samplingfördelningar och CGS Fördelning för en stickprovsstatistika (t.ex. medelvärde) kallas samplingfördelning. I teorin är
Föreläsning 2 Statistik; teori och tillämpning i biologi 1 Normalfördelning Samplingfördelningar och CGS Fördelning för en stickprovsstatistika (t.ex. medelvärde) kallas samplingfördelning. I teorin är
Problem med analyser av EQ-5D data. Philippe Wagner Tomasz Czuba Jonas Ranstam
 Problem med analyser av EQ-5D data Philippe Wagner Tomasz Czuba Jonas Ranstam Tänkte prata om Vad är EQ-5D? Hur analyseras EQ-5D data? Kort repetition av t-testet T-testet och EQ-5D data Kort repetition
Problem med analyser av EQ-5D data Philippe Wagner Tomasz Czuba Jonas Ranstam Tänkte prata om Vad är EQ-5D? Hur analyseras EQ-5D data? Kort repetition av t-testet T-testet och EQ-5D data Kort repetition
Uppföljning efter intensivvård Årsrapport 2014
 Uppföljning efter intensivvård Årsrapport 2014 Version för patienter och närstående Uppföljning efter Intensivvård Patientanpassad resultatdata Svenska Intensivvårdsregistret (SIR) presenterar en rapportversion
Uppföljning efter intensivvård Årsrapport 2014 Version för patienter och närstående Uppföljning efter Intensivvård Patientanpassad resultatdata Svenska Intensivvårdsregistret (SIR) presenterar en rapportversion
Föreläsning 3. NDAB02 Statistik; teori och tillämpning i biologi
 Föreläsning 3 Statistik; teori och tillämpning i biologi 1 Dagens föreläsning o Inferens om två populationer (kap 8.1 8.) o Parvisa observationer (kap 9.1 9.) o p-värde (kap 6.3) o Feltyper, styrka, stickprovsstorlek
Föreläsning 3 Statistik; teori och tillämpning i biologi 1 Dagens föreläsning o Inferens om två populationer (kap 8.1 8.) o Parvisa observationer (kap 9.1 9.) o p-värde (kap 6.3) o Feltyper, styrka, stickprovsstorlek
OBS! Vi har nya rutiner.
 KOD: Kurskod: PC1203 och PC1244 Kursnamn: Kognitiv psykologi och metod och Kognitiv psykologi och utvecklingspsykologi Provmoment: Metod Ansvarig lärare: Linda Hassing Tentamensdatum: 2012-11-17 Tillåtna
KOD: Kurskod: PC1203 och PC1244 Kursnamn: Kognitiv psykologi och metod och Kognitiv psykologi och utvecklingspsykologi Provmoment: Metod Ansvarig lärare: Linda Hassing Tentamensdatum: 2012-11-17 Tillåtna
SF1915 Sannolikhetsteori och statistik 6 hp. χ 2 -test
 SF1915 Sannolikhetsteori och statistik 6 hp Föreläsning 12 χ 2 -test Jörgen Säve-Söderbergh Anpassningstest test av given fördelning n oberoende försök med r möjliga olika utfall Händelse A 1 A 2... A
SF1915 Sannolikhetsteori och statistik 6 hp Föreläsning 12 χ 2 -test Jörgen Säve-Söderbergh Anpassningstest test av given fördelning n oberoende försök med r möjliga olika utfall Händelse A 1 A 2... A
732G71 Statistik B. Föreläsning 4. Bertil Wegmann. November 11, IDA, Linköpings universitet
 732G71 Statistik B Föreläsning 4 Bertil Wegmann IDA, Linköpings universitet November 11, 2016 Bertil Wegmann (IDA, LiU) 732G71, Statistik B November 11, 2016 1 / 34 Kap. 5.1, korrelationsmatris En korrelationsmatris
732G71 Statistik B Föreläsning 4 Bertil Wegmann IDA, Linköpings universitet November 11, 2016 Bertil Wegmann (IDA, LiU) 732G71, Statistik B November 11, 2016 1 / 34 Kap. 5.1, korrelationsmatris En korrelationsmatris
Datorövning Power curve 0,0305 0, Kvantiler, kritiska regioner
 . Kvantiler, kritiska regioner Datorövning Räkna ut följande rejection regions (genom att rita täthetsfunktionen i Minitab ):. z-fördelning, tvåsidigt, 5% signifikansnivå. z-fördelning, lower tail, 5%
. Kvantiler, kritiska regioner Datorövning Räkna ut följande rejection regions (genom att rita täthetsfunktionen i Minitab ):. z-fördelning, tvåsidigt, 5% signifikansnivå. z-fördelning, lower tail, 5%
34% 34% 13.5% 68% 13.5% 2.35% 95% 2.35% 0.15% 99.7% 0.15% -3 SD -2 SD -1 SD M +1 SD +2 SD +3 SD
 6.4 Att dra slutsatser på basis av statistisk analys en kort inledning - Man har ett stickprov, men man vill med hjälp av det få veta något om hela populationen => för att kunna dra slutsatser som gäller
6.4 Att dra slutsatser på basis av statistisk analys en kort inledning - Man har ett stickprov, men man vill med hjälp av det få veta något om hela populationen => för att kunna dra slutsatser som gäller
a) Facit till räkneseminarium 3
 Facit till räkneseminarium 3") 3.1 Fig 1. Sammanlagt 30 individer rekryteras till studien. Individerna randomiseras till en av de fyra studiearmarna (1: 500 mg artemisinin i kombination med piperakin, 2: 100 mg AMP1050 i kombination
3.1 Fig 1. Sammanlagt 30 individer rekryteras till studien. Individerna randomiseras till en av de fyra studiearmarna (1: 500 mg artemisinin i kombination med piperakin, 2: 100 mg AMP1050 i kombination
Upphovsrätt - tillgänglighet
 Upphovsrätt - tillgänglighet SF-36 Hälsoenkät är försedd med copyright knuten till Medical Outcomes Trust (MOT), 20 Park Plaza, Suite 1014, Boston, MA 02116-4313 och till Sektionen för vårdforskning, Sahlgrenska
Upphovsrätt - tillgänglighet SF-36 Hälsoenkät är försedd med copyright knuten till Medical Outcomes Trust (MOT), 20 Park Plaza, Suite 1014, Boston, MA 02116-4313 och till Sektionen för vårdforskning, Sahlgrenska
Bilaga 6 till rapport 1 (5)
") till rapport 1 (5) Bilddiagnostik vid misstänkt prostatacancer, rapport UTV2012/49 (2014). Värdet av att undvika en prostatabiopsitagning beskrivning av studien SBU har i samarbete med Centrum för utvärdering
till rapport 1 (5) Bilddiagnostik vid misstänkt prostatacancer, rapport UTV2012/49 (2014). Värdet av att undvika en prostatabiopsitagning beskrivning av studien SBU har i samarbete med Centrum för utvärdering
Uppgift a b c d e Vet inte Poäng 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
 TENTAMEN: Dataanalys och statistik för I, TMS136 Onsdagen den 5 oktober kl. 8.30-13.30 på M. Jour: Jenny Andersson, ankn 5317 Hjälpmedel: Utdelad formelsamling med tabeller, BETA, på kursen använd ordlista
TENTAMEN: Dataanalys och statistik för I, TMS136 Onsdagen den 5 oktober kl. 8.30-13.30 på M. Jour: Jenny Andersson, ankn 5317 Hjälpmedel: Utdelad formelsamling med tabeller, BETA, på kursen använd ordlista
Analys av medelvärden. Jenny Selander , plan 3, Norrbacka, ingång via den Samhällsmedicinska kliniken
 Analys av medelvärden Jenny Selander jenny.selander@ki.se 524 800 29, plan 3, Norrbacka, ingång via den Samhällsmedicinska kliniken Jenny Selander, Kvant. metoder, FHV T1 december 20111 Innehåll Normalfördelningen
Analys av medelvärden Jenny Selander jenny.selander@ki.se 524 800 29, plan 3, Norrbacka, ingång via den Samhällsmedicinska kliniken Jenny Selander, Kvant. metoder, FHV T1 december 20111 Innehåll Normalfördelningen
Hur man tolkar statistiska resultat
 Hur man tolkar statistiska resultat Andrew Hooker Division of Pharmacokinetics and Drug Therapy Department of Pharmaceutical Biosciences Uppsala University Varför använder vi oss av statistiska tester?
Hur man tolkar statistiska resultat Andrew Hooker Division of Pharmacokinetics and Drug Therapy Department of Pharmaceutical Biosciences Uppsala University Varför använder vi oss av statistiska tester?
Matematikcentrum 1(5) Matematisk Statistik Lunds Universitet MASB11 HT Laboration P3-P4. Statistiska test
 Matematisk Statistik Lunds Universitet MASB11 HT Laboration P3-P4. Statistiska test") Matematikcentrum 1(5) Matematisk Statistik Lunds Universitet MASB11 HT-2009 Laboration P3-P4 Statistiska test MH:231 Grupp A: Tisdag 17/11-09, 8.15-10.00 och Måndag 23/11-09, 8.15-10.00 Grupp B: Tisdag
Matematikcentrum 1(5) Matematisk Statistik Lunds Universitet MASB11 HT-2009 Laboration P3-P4 Statistiska test MH:231 Grupp A: Tisdag 17/11-09, 8.15-10.00 och Måndag 23/11-09, 8.15-10.00 Grupp B: Tisdag
F3 Introduktion Stickprov
 Utrotningshotad tandnoting i arktiska vatten Inferens om väntevärde baserat på medelvärde och standardavvikelse Matematik och statistik för biologer, 10 hp Tandnoting är en torskliknande fisk som lever
Utrotningshotad tandnoting i arktiska vatten Inferens om väntevärde baserat på medelvärde och standardavvikelse Matematik och statistik för biologer, 10 hp Tandnoting är en torskliknande fisk som lever
LÖSNINGSFÖRSLAG TILL TENTAMEN I MATEMATISK STATISTIK 2007-08-29
 UMEÅ UNIVERSITET Institutionen för matematik och matematisk statistik Statistik för Teknologer, 5 poäng (TNK, ET, BTG) Peter Anton, Per Arnqvist Anton Grafström TENTAMEN 7-8-9 LÖSNINGSFÖRSLAG TILL TENTAMEN
UMEÅ UNIVERSITET Institutionen för matematik och matematisk statistik Statistik för Teknologer, 5 poäng (TNK, ET, BTG) Peter Anton, Per Arnqvist Anton Grafström TENTAMEN 7-8-9 LÖSNINGSFÖRSLAG TILL TENTAMEN
Självskattad hälsa med hälsoenkäten RAND-36
 Självskattad hälsa med hälsoenkäten RAND-36 Patientrapporterat mått - ett kraftfullt verktyg i personcentrerad vård Agneta Pagels Sjuksköterska, kvalitetssamordnare Njurmedicin, Karolinska Universitetssjukhuset
Självskattad hälsa med hälsoenkäten RAND-36 Patientrapporterat mått - ett kraftfullt verktyg i personcentrerad vård Agneta Pagels Sjuksköterska, kvalitetssamordnare Njurmedicin, Karolinska Universitetssjukhuset
F14 HYPOTESPRÖVNING (NCT 10.2, , 11.5) Hypotesprövning för en proportion. Med hjälp av data från ett stickprov vill vi pröva
 Hypotesprövning för en proportion. Med hjälp av data från ett stickprov vill vi pröva") Stat. teori gk, ht 006, JW F14 HYPOTESPRÖVNING (NCT 10., 10.4-10.5, 11.5) Hypotesprövning för en proportion Med hjälp av data från ett stickprov vill vi pröva H 0 : P = P 0 mot någon av H 1 : P P 0 ; H
Stat. teori gk, ht 006, JW F14 HYPOTESPRÖVNING (NCT 10., 10.4-10.5, 11.5) Hypotesprövning för en proportion Med hjälp av data från ett stickprov vill vi pröva H 0 : P = P 0 mot någon av H 1 : P P 0 ; H
Tentamen i matematisk statistik (9MA241/9MA341, STN2) kl 08-12
 kl 08-12") LINKÖPINGS UNIVERSITET MAI Johan Thim Tentamen i matematisk statistik (9MA21/9MA31, STN2) 212-8-2 kl 8-12 Hjälpmedel är: miniräknare med tömda minnen och formelbladet bifogat. Varje uppgift är värd 6 poäng.
LINKÖPINGS UNIVERSITET MAI Johan Thim Tentamen i matematisk statistik (9MA21/9MA31, STN2) 212-8-2 kl 8-12 Hjälpmedel är: miniräknare med tömda minnen och formelbladet bifogat. Varje uppgift är värd 6 poäng.
Matematikcentrum 1(6) Matematisk Statistik Lunds Universitet MASB11 HT11. Laboration. Statistiska test /16
 Matematisk Statistik Lunds Universitet MASB11 HT11. Laboration. Statistiska test /16") Matematikcentrum 1(6) Matematisk Statistik Lunds Universitet MASB11 HT11 Laboration Statistiska test 2011-11-15/16 2 Syftet med laborationen är att: Ni skall bekanta er med lite av de funktioner som finns
Matematikcentrum 1(6) Matematisk Statistik Lunds Universitet MASB11 HT11 Laboration Statistiska test 2011-11-15/16 2 Syftet med laborationen är att: Ni skall bekanta er med lite av de funktioner som finns
Bestäm med hjälp av en lämplig och välmotiverad approximation P (X > 50). (10 p)
. (10 p)") Avd. Matematisk statistik TENTAMEN I SF1901, SF1905, SANNOLIKHETSTEORI OCH STATISTIK, MÅNDAGEN DEN 17:E AUGUSTI 2015 KL 8.00 13.00. Kursledare: Tatjana Pavlenko, 08-790 84 66 Tillåtna hjälpmedel: Formel-
Avd. Matematisk statistik TENTAMEN I SF1901, SF1905, SANNOLIKHETSTEORI OCH STATISTIK, MÅNDAGEN DEN 17:E AUGUSTI 2015 KL 8.00 13.00. Kursledare: Tatjana Pavlenko, 08-790 84 66 Tillåtna hjälpmedel: Formel-
Medicinsk statistik II
 Medicinsk statistik II Läkarprogrammet termin 5 VT 2013 Susanna Lövdahl, Msc, doktorand Klinisk koagulationsforskning, Lunds universitet E-post: susanna.lovdahl@med.lu.se Dagens föreläsning Fördjupning
Medicinsk statistik II Läkarprogrammet termin 5 VT 2013 Susanna Lövdahl, Msc, doktorand Klinisk koagulationsforskning, Lunds universitet E-post: susanna.lovdahl@med.lu.se Dagens föreläsning Fördjupning
Uppföljning efter intensivvård
 Svenska Intensivvårdsregistret SIR Uppföljning efter intensivvård Årsrapport 2013 Version för patienter och närstående Uppföljning efter intensivvård Patientanpassad resultatdata Svenska Intensivvårdsregistret
Svenska Intensivvårdsregistret SIR Uppföljning efter intensivvård Årsrapport 2013 Version för patienter och närstående Uppföljning efter intensivvård Patientanpassad resultatdata Svenska Intensivvårdsregistret
Hur skriver man statistikavsnittet i en ansökan?
 Hur skriver man statistikavsnittet i en ansökan? Val av metod och stickprovsdimensionering Registercentrum Norr http://www.registercentrumnorr.vll.se/ statistik.rcnorr@vll.se 11 Oktober, 2018 1 / 52 Det
Hur skriver man statistikavsnittet i en ansökan? Val av metod och stickprovsdimensionering Registercentrum Norr http://www.registercentrumnorr.vll.se/ statistik.rcnorr@vll.se 11 Oktober, 2018 1 / 52 Det
7.5 Experiment with a single factor having more than two levels
 7.5 Experiment with a single factor having more than two levels Exempel: Antag att vi vill jämföra dragstyrkan i en syntetisk fiber som blandats ut med bomull. Man vet att inblandningen påverkar dragstyrkan
7.5 Experiment with a single factor having more than two levels Exempel: Antag att vi vill jämföra dragstyrkan i en syntetisk fiber som blandats ut med bomull. Man vet att inblandningen påverkar dragstyrkan
F22, Icke-parametriska metoder.
 Icke-parametriska metoder F22, Icke-parametriska metoder. Christian Tallberg Statistiska institutionen Stockholms universitet Tidigare när vi utfört inferens, dvs utifrån stickprov gjort konfidensintervall
Icke-parametriska metoder F22, Icke-parametriska metoder. Christian Tallberg Statistiska institutionen Stockholms universitet Tidigare när vi utfört inferens, dvs utifrån stickprov gjort konfidensintervall
Bild 1. Bild 2 Sammanfattning Statistik I. Bild 3 Hypotesprövning. Medicinsk statistik II
 Bild 1 Medicinsk statistik II Läkarprogrammet T5 HT 2014 Anna Jöud Arbets- och miljömedicin, Lunds universitet ERC Syd, Skånes Universitetssjukhus anna.joud@med.lu.se Bild 2 Sammanfattning Statistik I
Bild 1 Medicinsk statistik II Läkarprogrammet T5 HT 2014 Anna Jöud Arbets- och miljömedicin, Lunds universitet ERC Syd, Skånes Universitetssjukhus anna.joud@med.lu.se Bild 2 Sammanfattning Statistik I
Uppgift 3 Vid en simuleringsstudie drar man 1200 oberoende slumptal,x i. Varje X i är likformigt fördelat mellan 0 och 1. Dessa tal adderas.
 Avd. Matematisk statistik TENTAMEN I SF1902 SANNOLIKHETSTEORI OCH STATISTIK, MÅNDAGEN DEN 17:E AUGUSTI 2015 KL 8.00 13.00. Kursledare och examinator : Björn-Olof Skytt, tel 790 8649. Tillåtna hjälpmedel:
Avd. Matematisk statistik TENTAMEN I SF1902 SANNOLIKHETSTEORI OCH STATISTIK, MÅNDAGEN DEN 17:E AUGUSTI 2015 KL 8.00 13.00. Kursledare och examinator : Björn-Olof Skytt, tel 790 8649. Tillåtna hjälpmedel:
F5 Introduktion Anpassning Korstabeller Homogenitet Oberoende Sammanfattning Minitab
 Repetition: Gnuer i (o)skyddade områden χ 2 -metoder, med koppling till binomialfördelning och genetik. Matematik och statistik för biologer, 10 hp Fredrik Jonsson Januari 2012 Endast 2 av de 13 observationerna
Repetition: Gnuer i (o)skyddade områden χ 2 -metoder, med koppling till binomialfördelning och genetik. Matematik och statistik för biologer, 10 hp Fredrik Jonsson Januari 2012 Endast 2 av de 13 observationerna
Tentamen på. Statistik och kvantitativa undersökningar STA100, 15 hp. Fredagen den 16 e januari 2015
 MÄLARDALENS HÖGSKOLA Akademin för ekonomi, samhälle och teknik Statistik Tentamen på Statistik och kvantitativa undersökningar STA100, 15 hp Fredagen den 16 e januari 2015 Tillåtna hjälpmedel: Miniräknare
MÄLARDALENS HÖGSKOLA Akademin för ekonomi, samhälle och teknik Statistik Tentamen på Statistik och kvantitativa undersökningar STA100, 15 hp Fredagen den 16 e januari 2015 Tillåtna hjälpmedel: Miniräknare
Tentamen i Tillämpad statistisk analys, GN, 7.5 hp. 23 maj 2013 kl. 9 14
 STOCKHOLMS UNIVERSITET MT4003 MATEMATISKA INSTITUTIONEN LÖSNINGAR Avd. Matematisk statistik 3 maj 013 Lösningar Tentamen i Tillämpad statistisk analys, GN, 7.5 hp 3 maj 013 kl. 9 14 Uppgift 1 a Eftersom
STOCKHOLMS UNIVERSITET MT4003 MATEMATISKA INSTITUTIONEN LÖSNINGAR Avd. Matematisk statistik 3 maj 013 Lösningar Tentamen i Tillämpad statistisk analys, GN, 7.5 hp 3 maj 013 kl. 9 14 Uppgift 1 a Eftersom
Östgötens hälsa Kommunrapport - Hälsa. Rapport 2007:6. Folkhälsovetenskapligt centrum
 Östgötens hälsa 2006 Rapport 2007:6 Kommunrapport - Hälsa Folkhälsovetenskapligt centrum www.lio.se/fhvc November 2007 Helen Axelsson Madeleine Borgstedt-Risberg Elin Eriksson Lars Walter Östgötens hälsa
Östgötens hälsa 2006 Rapport 2007:6 Kommunrapport - Hälsa Folkhälsovetenskapligt centrum www.lio.se/fhvc November 2007 Helen Axelsson Madeleine Borgstedt-Risberg Elin Eriksson Lars Walter Östgötens hälsa
Laboration 2. i 5B1512, Grundkurs i matematisk statistik för ekonomer
 Laboration 2 i 5B52, Grundkurs i matematisk statistik för ekonomer Namn: Elevnummer: Laborationen syftar till ett ge information och träning i Excels rutiner för statistisk slutledning, konfidensintervall,
Laboration 2 i 5B52, Grundkurs i matematisk statistik för ekonomer Namn: Elevnummer: Laborationen syftar till ett ge information och träning i Excels rutiner för statistisk slutledning, konfidensintervall,
Tentan består av 15 frågor, totalt 40 poäng. Det krävs minst 24 poäng för att få godkänt och minst 33 poäng för att få välgodkänt.
 Kurskod: PC1203 och PC1244 Kursnamn: Kognitiv psykologi och metod OCH Kognitiv psykologi och utvecklingspsykologi Provmoment: Metod Ansvarig lärare: Linda Hassing Tentamensdatum: 2010-09-23 kl. 09:00 13:00
Kurskod: PC1203 och PC1244 Kursnamn: Kognitiv psykologi och metod OCH Kognitiv psykologi och utvecklingspsykologi Provmoment: Metod Ansvarig lärare: Linda Hassing Tentamensdatum: 2010-09-23 kl. 09:00 13:00
, s a. , s b. personer från Alingsås och n b
 Skillnader i medelvärden, väntevärden, mellan två populationer I kapitel 8 testades hypoteser typ : µ=µ 0 där µ 0 var något visst intresserant värde Då användes testfunktionen där µ hämtas från, s är populationsstandardavvikelsen
Skillnader i medelvärden, väntevärden, mellan två populationer I kapitel 8 testades hypoteser typ : µ=µ 0 där µ 0 var något visst intresserant värde Då användes testfunktionen där µ hämtas från, s är populationsstandardavvikelsen
Tentan består av 10 frågor, totalt 30 poäng. Det krävs 20 poäng för att få godkänt på tentan, varav 50 % inom respektive moment.
 Kurskod: PM1303 Kursnamn: Vetenskapsteori och grundläggande forskningsmetod Ansvarig lärare: Linda Hassing Tentamensdatum: 2010-04-24 kl. 14:30 18:30 Tillåtna hjälpmedel: Miniräknare Tentan består av 10
Kurskod: PM1303 Kursnamn: Vetenskapsteori och grundläggande forskningsmetod Ansvarig lärare: Linda Hassing Tentamensdatum: 2010-04-24 kl. 14:30 18:30 Tillåtna hjälpmedel: Miniräknare Tentan består av 10
Föreläsning 2. Kap 3,7-3,8 4,1-4,6 5,2 5,3
 Föreläsning Kap 3,7-3,8 4,1-4,6 5, 5,3 1 Kap 3,7 och 3,8 Hur bra är modellen som vi har anpassat? Vi bedömer modellen med hjälp av ett antal kriterier: visuell bedömning, om möjligt F-test, signifikanstest
Föreläsning Kap 3,7-3,8 4,1-4,6 5, 5,3 1 Kap 3,7 och 3,8 Hur bra är modellen som vi har anpassat? Vi bedömer modellen med hjälp av ett antal kriterier: visuell bedömning, om möjligt F-test, signifikanstest
Jesper Rydén. Matematiska institutionen, Uppsala universitet Tillämpad statistik för STS vt 2014
 Föreläsning 7. Jesper Rydén Matematiska institutionen, Uppsala universitet jesper@math.uu.se Tillämpad statistik för STS vt 2014 χ 2 -metoder Några varianter: Test av helt given fördelning [A & B, 8.2.1]
Föreläsning 7. Jesper Rydén Matematiska institutionen, Uppsala universitet jesper@math.uu.se Tillämpad statistik för STS vt 2014 χ 2 -metoder Några varianter: Test av helt given fördelning [A & B, 8.2.1]
Envägs variansanalys (ANOVA) för test av olika väntevärde i flera grupper
 för test av olika väntevärde i flera grupper") Envägs variansanalys (ANOVA) för test av olika väntevärde i flera grupper Tobias Abenius February 21, 2012 Envägs variansanalys (ANOVA) I envägs variansanalys utnyttjas att
Envägs variansanalys (ANOVA) för test av olika väntevärde i flera grupper Tobias Abenius February 21, 2012 Envägs variansanalys (ANOVA) I envägs variansanalys utnyttjas att
GHQ-12 General Health Questionnaire-12
 Beskrivning av instrumentet och dess användningsområde Den ursprungliga versionen av GHQ (General Health Questionnaire) utvecklades som ett instrument för screening av psykiatriska störningar. Den har
Beskrivning av instrumentet och dess användningsområde Den ursprungliga versionen av GHQ (General Health Questionnaire) utvecklades som ett instrument för screening av psykiatriska störningar. Den har
Resultatsammanställning
 Resultatsammanställning Samordningsförbundet Östra Östergötland Helåret 2016 @Therése Löwgren Sidan 3 Måluppfyllelse kvartal 4 Sidan 15-17 NP-samverkan Sidan 4-6 Måluppfyllelse kvartal 1-3 Sidan 18-19
Resultatsammanställning Samordningsförbundet Östra Östergötland Helåret 2016 @Therése Löwgren Sidan 3 Måluppfyllelse kvartal 4 Sidan 15-17 NP-samverkan Sidan 4-6 Måluppfyllelse kvartal 1-3 Sidan 18-19
Tentamen på. Statistik och kvantitativa undersökningar STA100, 15 HP. Ten1 9 HP. 19 e augusti 2015
 MÄLARDALENS HÖGSKOLA Akademin för ekonomi, samhälle och teknik Statistik Tentamen på Statistik och kvantitativa undersökningar STA100, 15 HP Ten1 9 HP 19 e augusti 2015 Tillåtna hjälpmedel: Miniräknare
MÄLARDALENS HÖGSKOLA Akademin för ekonomi, samhälle och teknik Statistik Tentamen på Statistik och kvantitativa undersökningar STA100, 15 HP Ten1 9 HP 19 e augusti 2015 Tillåtna hjälpmedel: Miniräknare
Statistik 1 för biologer, logopeder och psykologer
 Innehåll 1 Hypotesprövning Innehåll Hypotesprövning 1 Hypotesprövning Inledande exempel Hypotesprövning Exempel. Vi är intresserade av en variabel X om vilken vi kan anta att den är (approximativt) normalfördelad
Innehåll 1 Hypotesprövning Innehåll Hypotesprövning 1 Hypotesprövning Inledande exempel Hypotesprövning Exempel. Vi är intresserade av en variabel X om vilken vi kan anta att den är (approximativt) normalfördelad
Svenske erfaringer med kvalitetsudvikling vha. patientrapporterede oplysninger
 Svenske erfaringer med kvalitetsudvikling vha. patientrapporterede oplysninger MATS LUNDSTRÖM PROF. EM. RC SYD/EYENET SWEDEN, BLEKINGESJUKHUSET, KARLSKRONA, SVERIGE Innehåll Varför använda PROM? Krav på
Svenske erfaringer med kvalitetsudvikling vha. patientrapporterede oplysninger MATS LUNDSTRÖM PROF. EM. RC SYD/EYENET SWEDEN, BLEKINGESJUKHUSET, KARLSKRONA, SVERIGE Innehåll Varför använda PROM? Krav på
Lö sningsfö rslag till tentamen i matematisk statistik Statistik öch kvalitetsteknik 7,5 hp
 Sid (7) Lö sningsfö rslag till tentamen i matematisk statistik Statistik öch kvalitetsteknik 7,5 hp Uppgift Nedanstående beräkningar från Minitab är gjorda för en Poissonfördelning med väntevärde λ = 4.
Sid (7) Lö sningsfö rslag till tentamen i matematisk statistik Statistik öch kvalitetsteknik 7,5 hp Uppgift Nedanstående beräkningar från Minitab är gjorda för en Poissonfördelning med väntevärde λ = 4.
Föreläsning G60 Statistiska metoder
 Föreläsning 7 Statistiska metoder 1 Dagens föreläsning o Hypotesprövning för två populationer Populationsandelar Populationsmedelvärden Parvisa observationer Relation mellan hypotesprövning och konfidensintervall
Föreläsning 7 Statistiska metoder 1 Dagens föreläsning o Hypotesprövning för två populationer Populationsandelar Populationsmedelvärden Parvisa observationer Relation mellan hypotesprövning och konfidensintervall
Tentamen i statistik (delkurs C) på kursen MAR103: Marina Undersökningar - redskap och metoder.
 på kursen MAR103: Marina Undersökningar - redskap och metoder.") Tentamen 2014-12-05 i statistik (delkurs C) på kursen MAR103: Marina Undersökningar - redskap och metoder. Tillåtna hjälpmedel: Miniräknare och utdelad formelsamling med tabeller. C1. (6 poäng) Ange för
Tentamen 2014-12-05 i statistik (delkurs C) på kursen MAR103: Marina Undersökningar - redskap och metoder. Tillåtna hjälpmedel: Miniräknare och utdelad formelsamling med tabeller. C1. (6 poäng) Ange för
Jag tycker jag är -2. Beskrivning av instrumentet och dess användningsområde. Översikt. Vilka grupper är instrumentet gjort för?
 Beskrivning av instrumentet och dess användningsområde Jag tycker jag är-2 är ett självskattningsinstrument som syftar till att bedöma barns och ungas självkänsla [1,2]. Formuläret är anpassat för att
Beskrivning av instrumentet och dess användningsområde Jag tycker jag är-2 är ett självskattningsinstrument som syftar till att bedöma barns och ungas självkänsla [1,2]. Formuläret är anpassat för att
FACIT (korrekta svar i röd fetstil)
") v. 2013-01-14 Statistik, 3hp PROTOKOLL FACIT (korrekta svar i röd fetstil) Datorlaboration 2 Konfidensintervall & hypotesprövning Syftet med denna laboration är att ni med hjälp av MS Excel ska fortsätta
v. 2013-01-14 Statistik, 3hp PROTOKOLL FACIT (korrekta svar i röd fetstil) Datorlaboration 2 Konfidensintervall & hypotesprövning Syftet med denna laboration är att ni med hjälp av MS Excel ska fortsätta
Skriv tydligt. Besvara inte frågor med lösryckta ord, utan sammanhängande och tydligt. Visa även dina beräkningar.
 KOD: Kurskod: PM1303 Kursnamn: Vetenskapsteori och grundläggande forskningsmetod Provmoment: Vetenskapsteori och forskningsmetod Ansvarig lärare: Anders Biel Tentamensdatum: 2015-04-10 Tillåtna hjälpmedel:
KOD: Kurskod: PM1303 Kursnamn: Vetenskapsteori och grundläggande forskningsmetod Provmoment: Vetenskapsteori och forskningsmetod Ansvarig lärare: Anders Biel Tentamensdatum: 2015-04-10 Tillåtna hjälpmedel:
Mälardalens Högskola. Formelsamling. Statistik, grundkurs
 Mälardalens Högskola Formelsamling Statistik, grundkurs Höstterminen 2015 Deskriptiv statistik Populationens medelvärde (population mean): μ = X N Urvalets medelvärde (sample mean): X = X n Där N är storleken
Mälardalens Högskola Formelsamling Statistik, grundkurs Höstterminen 2015 Deskriptiv statistik Populationens medelvärde (population mean): μ = X N Urvalets medelvärde (sample mean): X = X n Där N är storleken
F18 MULTIPEL LINJÄR REGRESSION, FORTS. (NCT
 Stat. teori gk, ht 006, JW F18 MULTIPEL LINJÄR REGRESSION, FORTS. (NCT 1.1, 13.1-13.6, 13.8-13.9) Modell för multipel linjär regression Modellantaganden: 1) x-värdena är fixa. ) Varje y i (i = 1,, n) är
Stat. teori gk, ht 006, JW F18 MULTIPEL LINJÄR REGRESSION, FORTS. (NCT 1.1, 13.1-13.6, 13.8-13.9) Modell för multipel linjär regression Modellantaganden: 1) x-värdena är fixa. ) Varje y i (i = 1,, n) är
Tentamentsskrivning: Matematisk Statistik med Metoder MVE490 1
 Tentamentsskrivning: Matematisk Statistik med Metoder MVE490 1 Tentamentsskrivning i Matematisk Statistik med Metoder MVE490 Tid: den 16 augusti, 2017 Examinatorer: Kerstin Wiklander och Erik Broman. Jour:
Tentamentsskrivning: Matematisk Statistik med Metoder MVE490 1 Tentamentsskrivning i Matematisk Statistik med Metoder MVE490 Tid: den 16 augusti, 2017 Examinatorer: Kerstin Wiklander och Erik Broman. Jour:
Syns du, finns du? Examensarbete 15 hp kandidatnivå Medie- och kommunikationsvetenskap
 Examensarbete 15 hp kandidatnivå Medie- och kommunikationsvetenskap Syns du, finns du? - En studie över användningen av SEO, PPC och sociala medier som strategiska kommunikationsverktyg i svenska företag
Examensarbete 15 hp kandidatnivå Medie- och kommunikationsvetenskap Syns du, finns du? - En studie över användningen av SEO, PPC och sociala medier som strategiska kommunikationsverktyg i svenska företag
Cancersmärta ett folkhälsoproblem?
 Cancersmärta ett folkhälsoproblem? Åsa Assmundson Nordiska högskolan för folkhälsovetenskap Master of Public Health MPH 2005:31 Cancersmärta ett folkhälsoproblem? Nordiska högskolan för folkhälsovetenskap
Cancersmärta ett folkhälsoproblem? Åsa Assmundson Nordiska högskolan för folkhälsovetenskap Master of Public Health MPH 2005:31 Cancersmärta ett folkhälsoproblem? Nordiska högskolan för folkhälsovetenskap
π = proportionen plustecken i populationen. Det numeriska värdet på π är okänt.
 Stat. teori gk, vt 006, JW F0 ICKE-PARAMETRISKA TEST (NCT 13.1, 13.3-13.4) Or dlista till NCT Nonparametric Sign test Rank Teckentest Icke-parametrisk Teckentest Rang Teckentestet är formellt ingenting
Stat. teori gk, vt 006, JW F0 ICKE-PARAMETRISKA TEST (NCT 13.1, 13.3-13.4) Or dlista till NCT Nonparametric Sign test Rank Teckentest Icke-parametrisk Teckentest Rang Teckentestet är formellt ingenting
INTERNATIONAL SPINAL CORD INJURY DATA SETS - QUALITY OF LIFE BASIC DATA SET Swedish version
 INTERNATIONAL SPINAL CORD INJURY DATA SETS - QUALITY OF LIFE BASIC DATA SET Swedish version 1.0 2017-12-06 The translation of the Swedish version of the International Spinal Cord Injury Data Set Quality
INTERNATIONAL SPINAL CORD INJURY DATA SETS - QUALITY OF LIFE BASIC DATA SET Swedish version 1.0 2017-12-06 The translation of the Swedish version of the International Spinal Cord Injury Data Set Quality
Tentamen Tillämpad statistik A5 (15hp)
") Uppsala universitet Statistiska institutionen A5 2014-08-26 Tentamen Tillämpad statistik A5 (15hp) 2014-08-26 UPPLYSNINGAR A. Tillåtna hjälpmedel: Miniräknare Formelsamlingar: A4/A8 Tabell- och formelsamling
Uppsala universitet Statistiska institutionen A5 2014-08-26 Tentamen Tillämpad statistik A5 (15hp) 2014-08-26 UPPLYSNINGAR A. Tillåtna hjälpmedel: Miniräknare Formelsamlingar: A4/A8 Tabell- och formelsamling
Lösningsförslag till tentamen på. Statistik och kvantitativa undersökningar STA100, 15 hp. Fredagen den 13 e mars 2015
 MÄLARDALENS HÖGSKOLA Akademin för ekonomi, samhälle och teknik Statistik Lösningsförslag till tentamen på Statistik och kvantitativa undersökningar STA100, 15 hp Fredagen den 13 e mars 015 1 a 13 och 14
MÄLARDALENS HÖGSKOLA Akademin för ekonomi, samhälle och teknik Statistik Lösningsförslag till tentamen på Statistik och kvantitativa undersökningar STA100, 15 hp Fredagen den 13 e mars 015 1 a 13 och 14
Laboration 3 Inferens fo r andelar och korstabeller
 S0005M Statistik2 Lp 4 2016 Laboration 3 Inferens fo r andelar och korstabeller Laborationen behandlar Test av andelar med konfidensintervall och hypotestest Chi två test av oberoende mellan kvalitativa
S0005M Statistik2 Lp 4 2016 Laboration 3 Inferens fo r andelar och korstabeller Laborationen behandlar Test av andelar med konfidensintervall och hypotestest Chi två test av oberoende mellan kvalitativa
Föreläsning 5. NDAB02 Statistik; teori och tillämpning i biologi
 Föreläsning 5 Statistik; teori och tillämpning i biologi 1 Dagens föreläsning o Andelar (kap 24) o Binomialfördelning (kap 24.1) o Test och konfidensintervall för en andel (kap 24.5, 24.6, 24.8) o Test
Föreläsning 5 Statistik; teori och tillämpning i biologi 1 Dagens föreläsning o Andelar (kap 24) o Binomialfördelning (kap 24.1) o Test och konfidensintervall för en andel (kap 24.5, 24.6, 24.8) o Test
Tentamen i Statistik, STA A10 och STA A13 (9 poäng) Måndag 14 maj 2007, Kl
 Måndag 14 maj 2007, Kl") Karlstads universitet Avdelningen för nationalekonomi och statistik Tentamen i Statistik, STA A10 och STA A13 (9 poäng) Måndag 14 maj 2007, Kl 08.15-13.15 Tillåtna hjälpmedel: Bifogad formelsamling, approximationsschema
Karlstads universitet Avdelningen för nationalekonomi och statistik Tentamen i Statistik, STA A10 och STA A13 (9 poäng) Måndag 14 maj 2007, Kl 08.15-13.15 Tillåtna hjälpmedel: Bifogad formelsamling, approximationsschema
Analytisk statistik. Mattias Nilsson Benfatto, PhD.
 Analytisk statistik Mattias Nilsson Benfatto, PhD Mattias.nilsson@ki.se Beskrivande statistik kort repetition Centralmått Spridningsmått Normalfördelning Konfidensintervall Korrelation Analytisk statistik
Analytisk statistik Mattias Nilsson Benfatto, PhD Mattias.nilsson@ki.se Beskrivande statistik kort repetition Centralmått Spridningsmått Normalfördelning Konfidensintervall Korrelation Analytisk statistik
Innehåll. Frekvenstabell. II. Beskrivande statistik, sid 53 i E
 Innehåll I. Grundläggande begrepp II. Deskriptiv statistik (sid 53 i E) III. Statistisk inferens Hypotesprövnig Statistiska analyser Parametriska analyser Icke-parametriska analyser 1 II. Beskrivande statistik,
Innehåll I. Grundläggande begrepp II. Deskriptiv statistik (sid 53 i E) III. Statistisk inferens Hypotesprövnig Statistiska analyser Parametriska analyser Icke-parametriska analyser 1 II. Beskrivande statistik,
Kapitel 12: TEST GÄLLANDE EN GRUPP KOEFFICIENTER - ANOVA
 Kapitel 12: TEST GÄLLANDE EN GRUPP KOEFFICIENTER - ANOVA 12.1 ANOVA I EN MULTIPEL REGRESSION Exempel: Tjänar man mer som egenföretagare? Nedan visas ett utdrag ur ett dataset som innehåller information
Kapitel 12: TEST GÄLLANDE EN GRUPP KOEFFICIENTER - ANOVA 12.1 ANOVA I EN MULTIPEL REGRESSION Exempel: Tjänar man mer som egenföretagare? Nedan visas ett utdrag ur ett dataset som innehåller information
Standardfel (Standard error, SE) SD eller SE. Intervallskattning MSG Staffan Nilsson, Chalmers 1
 SD eller SE. Intervallskattning MSG Staffan Nilsson, Chalmers 1") Standardfel (Standard error, SE) Anta vi har ett stickprov X 1,,X n där varje X i has medel = µ och std.dev = σ. Då är Det sista kalls standardfel (eng:standard error of mean (SEM) eller (SE) och skattas
Standardfel (Standard error, SE) Anta vi har ett stickprov X 1,,X n där varje X i has medel = µ och std.dev = σ. Då är Det sista kalls standardfel (eng:standard error of mean (SEM) eller (SE) och skattas
Skrivning i ekonometri lördagen den 29 mars 2008
 LUNDS UNIVERSITET STATISTISKA INSTITUTIONEN MATS HAGNELL STAB, Ekonometri Skrivning i ekonometri lördagen den 9 mars 8.Vi vill undersöka hur variationen i antal arbetande timmar för gifta kvinnor i Michigan
LUNDS UNIVERSITET STATISTISKA INSTITUTIONEN MATS HAGNELL STAB, Ekonometri Skrivning i ekonometri lördagen den 9 mars 8.Vi vill undersöka hur variationen i antal arbetande timmar för gifta kvinnor i Michigan
Del I. Uppgift 1 För händelserna A och B gäller att P (A) = 1/4, P (B A) = 1/3 och P (B A ) = 1/2. Beräkna P (A B). Svar:...
 = 1/4, P (B A) = 1/3 och P (B A ) = 1/2. Beräkna P (A B). Svar:...") Avd. Matematisk statistik TENTAMEN I SF9/SF94/SF95/SF96 SANNOLIKHETSTEORI OCH STATISTIK, ONSDAGEN DEN 4:E OKTOBER 08 KL 8.00 3.00. Examinator för SF94/SF96: Tatjana Pavlenko, 08-790 84 66 Examinator för
Avd. Matematisk statistik TENTAMEN I SF9/SF94/SF95/SF96 SANNOLIKHETSTEORI OCH STATISTIK, ONSDAGEN DEN 4:E OKTOBER 08 KL 8.00 3.00. Examinator för SF94/SF96: Tatjana Pavlenko, 08-790 84 66 Examinator för
Tentamen på. Statistik och kvantitativa undersökningar STA101, 15 hp. Torsdagen den 23 e mars Ten 1, 9 hp
 MÄLARDALENS HÖGSKOLA Akademin för ekonomi, samhälle och teknik Statistik Tentamen på Statistik och kvantitativa undersökningar STA101, 15 hp Torsdagen den 23 e mars 2017 Ten 1, 9 hp Tillåtna hjälpmedel:
MÄLARDALENS HÖGSKOLA Akademin för ekonomi, samhälle och teknik Statistik Tentamen på Statistik och kvantitativa undersökningar STA101, 15 hp Torsdagen den 23 e mars 2017 Ten 1, 9 hp Tillåtna hjälpmedel:
KOM IHÅG ATT NOTERA DITT TENTAMENSNUMMER NEDAN OCH TA MED DIG TALONGEN INNAN DU LÄMNAR IN TENTAN!!
 Kurskod: PC1203 och PC1244 Kursnamn: Kognitiv psykologi och metod OCH Kognitiv psykologi och utvecklingspsykologi Provmoment: Metod Ansvarig lärare: Linda Hassing Tentamensdatum: 2010-11-13 kl. 14:00 18:00
Kurskod: PC1203 och PC1244 Kursnamn: Kognitiv psykologi och metod OCH Kognitiv psykologi och utvecklingspsykologi Provmoment: Metod Ansvarig lärare: Linda Hassing Tentamensdatum: 2010-11-13 kl. 14:00 18:00
Preliminära lösningar för Tentamen Tillämpad statistik A5 (15hp) Statistiska institutionen, Uppsala universitet
 Statistiska institutionen, Uppsala universitet") Preliminära lösningar för Tentamen Tillämpad statistik A5 (15hp) 2016-01-13 Statistiska institutionen, Uppsala universitet Uppgift 1 (20 poäng) A) (4p) Om kommunens befolkning i den lokala arbetsmarknaden
Preliminära lösningar för Tentamen Tillämpad statistik A5 (15hp) 2016-01-13 Statistiska institutionen, Uppsala universitet Uppgift 1 (20 poäng) A) (4p) Om kommunens befolkning i den lokala arbetsmarknaden
faderns blodgrupp sannolikheten att barnet skall få blodgrupp A0 A0 1/2 AA 1 AB 1/2 Övriga 0
 Avd. Matematisk statistik TENTAMEN I SF1902 SANNOLIKHETSTEORI OCH STATISTIK, TISDAGEN DEN 9:E JUNI 2015 KL 14.00 19.00. Kursledare och examinator : Björn-Olof Skytt, tel 790 8649. Tillåtna hjälpmedel:
Avd. Matematisk statistik TENTAMEN I SF1902 SANNOLIKHETSTEORI OCH STATISTIK, TISDAGEN DEN 9:E JUNI 2015 KL 14.00 19.00. Kursledare och examinator : Björn-Olof Skytt, tel 790 8649. Tillåtna hjälpmedel:
Hälsofrämjande faktorer av betydelse för ett hållbart arbetsliv inom vård, omsorg och socialt arbete
 Hälsofrämjande faktorer av betydelse för ett hållbart arbetsliv inom vård, omsorg och socialt arbete Projektgrupp ViS (Vårdforskning i samverkan): Borås, Göteborg, Halmstad, HHJ, Högskolan väst, Skövde
Hälsofrämjande faktorer av betydelse för ett hållbart arbetsliv inom vård, omsorg och socialt arbete Projektgrupp ViS (Vårdforskning i samverkan): Borås, Göteborg, Halmstad, HHJ, Högskolan väst, Skövde