TDDD02 Språkteknologi för informationssökning (2016) Textklassificering. Marco Kuhlmann Institutionen för datavetenskap
|
|
|
- Lennart Blomqvist
- för 7 år sedan
- Visningar:
Transkript
1 TDDD02 Språkteknologi för informationssökning (2016) Textklassificering Marco Kuhlmann Institutionen för datavetenskap
2 Textklassificering
3 Skräppostfiltrering spam ham



4 Författaridentifiering Alexander Hamilton James Madison
5 Attitydpredicering The gorgeously elaborate continuation of The Lord of the Rings trilogy is so huge that a column of words cannot adequately describe co-writer/director Peter Jackson s expanded vision of J.R.R. Tolkien s Middle-earth. positiv is a sour little movie at its core; an exploration of the emptiness that underlay the relentless gaiety of the 1920 s, as if to stop would hasten the economic and global political turmoil that was to come. negativ
6 Kategorisering av nyheter UK China Elections Sports congestion London Olympics Beijing recount votes diamond baseball Parliament Big Ben tourism Great Wall seat run-off forward soccer Windsor The Queen Mao Communist TV-ads campaign team captain
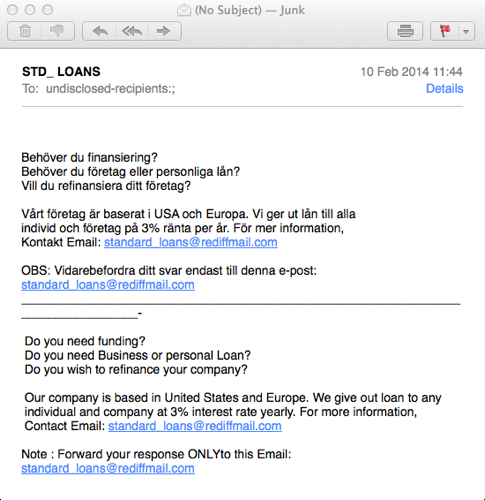
7 Handskrivna regler Vi kan tilldela ett dokument en klass genom handskrivna regler. om anonyma mottagare och texten innehåller ditt konto kommer att raderas då sortera som skräp Handskrivna regler kan ha hög träffsäkerhet, men att utveckla och underhålla dem är kostsamt. utgör ändå state-of-the-art i många domäner
8 Klassificering som övervakad inlärning congestion London A B C Olympics Beijing recount votes Parliament Big Ben A tourism Great Wall B seat run-off C Windsor The Queen A Mao Communist B TV-ads campaign C
9 Klassificering som övervakad inlärning träningsmängd träning congestion London A B C Olympics Beijing recount votes Parliament Big Ben A tourism Great Wall B seat run-off C testmängd utvärdering Windsor The Queen A Mao Communist B TV-ads campaign C
10 Utvärdering av textklassificerare
11 Utvärdering För att utvärdera en klassificerare jämför vi de predicerade klasserna med de korrekta klasser enligt guldstandarden. Systemets resultat på den hittills okända testmängden ger oss en idé om hur bra det kommer att vara på helt nya texter. Det är viktigt att vi inte tränar på testmängden! Om systemet får träna på testmängden blir utvärderingen missvisande.
12 Utvärderingsmått: Korrekthet Korrekthet (eng. accuracy) mäter andelen av alla dokument i testmängden för vilka systemet har predicerat korrekt klass. Hur ofta var den predicerade klassen identisk med guldstandardklassen? Korrekthet är ett enkelt och överskådligt mått, men kan ibland vara missvisande.
13 Problem med korrekthetsmåttet Ett system för textklassificering analyserar texter skrivna av patienter på en geriatrimottagning och predicerar om patienterna har eller inte har en ovanlig neurologisk sjukdom. Systemet utvärderas på en testmängd bestående av texter, 10 skrivna av patienter med sjukdomen och skrivna av patienter utan denna sjukdom. Systemet predicerar alltid att patienten inte har sjukdomen. Vad är systemets korrekthet?
14 Korrekthet klassificerare positiv klassificerare negativ guldstandard positiv sanna positiva falska negativa guldstandard negativ falska positiva sanna negativa
15 Utvärderingsmått: Precision och täckning Precision och täckning (eng. recall) zoomar in på hur bra systemet är på att identifiera dokument av en specifik klass K. Hur bra är systemet på att detektera sjukdomen? Precision är andelen korrekt klassificerade dokument bland alla dokument som systemet predicerat tillhöra klass K. Om systemet predicerar sjukdomen, hur ofta har patienten verkligen den? Täckning är andelen korrekt klassificerade dokument bland alla dokument som enligt guldstandarden har klass K. Om patienten har sjukdomen, hur ofta predicerar klassificeraren detta?
16 Precision klassificerare positiv klassificerare negativ guldstandard positiv sanna positiva falska negativa guldstandard negativ falska positiva sanna negativa
17 Täckning (recall) klassificerare positiv klassificerare negativ guldstandard positiv sanna positiva falska negativa guldstandard negativ falska positiva sanna negativa
18 Precision och täckning fn fp guldstandard G sp K klassificerare precision = G K K täckning = G K G
19 Korrekthet med tre klasser A B C A B C
20 Precision med avseende på klass B A B C A B C
21 Recall (täckning) med avseende på klass B A B C A B C
22 F1-måttet Ett bra system bör balansera precision och täckning. F1-måttet är det harmoniska medelvärdet mellan båda två: F1 = 2 precision täckning precision + täckning
23 Baseline Absoluta värden för korrekthet, precision och täckning säger egentligen inte särskilt mycket. 80% täckning bra eller dåligt? Istället så bör man fråga efter korrekthet, precision och täckning relativt till en referensmetod, en baseline. En vanlig baseline för klassificering är Most Frequent Class: predicera alltid den mest frekventa dokumentklassen.
24 Textklassificering med Naive Bayes
25 Naive Bayes Naive Bayes är en enkel men förvånansvärt effektiv metod för textklassificering som bygger på Bayes regel. Den utgår ifrån en representation av textdokument som bags of words, dvs. den tar ingen hänsyn till ordföljd.
26 Bag-of-words-representationen The gorgeously elaborate continuation of The Lord of the Rings trilogy is so huge that a column of words cannot adequately describe co-writer/director Peter Jackson s expanded vision of J.R.R. Tolkien s Middle-earth. positiv is a sour little movie at its core; an exploration of the emptiness that underlay the relentless gaiety of the 1920 s, as if to stop would hasten the economic and global political turmoil that was to come. negativ
27 Bag-of-words-representationen a adequately cannot co-writer column continuation describe director elaborate expanded gorgeously huge is J.R.R. Jackson Lord Middle-earth of of of of Peter Rings so that The The the Tolkien trilogy vision words positiv 1920 s a an and as at come core economic emptiness exploration gaiety global hasten if is its little movie of of political relentless sour stop that that the the the the to to turmoil underlay was would negativ
28 Bag-of-words-representationen ord frekvens ord frekvens of 4 the 4 The 2 to 2 words 1 that 2 vision 1 of 2 trilogy 1 would 1 positiv negativ
29 Generativ modell ingen information om texten P(S) P(N) S N P(Sthlm S) P(Oslo S) P(Sthlm N) P(Oslo N) Sthlm Oslo Sthlm Oslo
30 Bayes regel För klassificering vill vi veta P(klass text). P(diagnos symptom) I en Naive Bayes-modell representeras istället P(text klass). P(symptom diagnos) Bayes regel kan användas för att konvertera mellan dessa.
 Thomas Bayes (1702")
31 Bayes regel P(B A)P(A) P(A B) = P(B) Thomas Bayes ( )
32 Naive Bayes-metoden En Naive Bayes-modell utgår ifrån en mängd klasser och en mängd ord som vi tror är relevanta för klassificeringen. Den inkluderar sannolikheter som anger hur troligt det är att se ett ord w i ett dokument, givet att det dokumentet har en klass c. P(w c), P(Sthlm S) För att klassificera ett dokument går man genom alla ord i det, multiplicerar de relevanta ordsannolikheterna klassvist, och väljer sedan den klass för vilken man har fått det högsta värdet.
33 Ingredienserna i en Naive Bayes-modell C V en mängd möjliga klasser en mängd möjliga ord; modellens vokabulär P(c) en sannolikhet som anger hur troligt det är att ett givet dokument har klass c (ett värde för varje klass) P(w c) en sannolikhet som anger hur troligt det är att ett givet dokument innehåller ordet w, givet att vi redan vet att det har klass c (ett värde för varje par klass ord)
34 Att klassificera med en Naive Bayes-modell För att predicera klassen för ett givet dokument d: Låt w 1,, w n beteckna listan av alla ordförekomster i d. Räkna ut ett värde score(c) för varje möjlig klass c enligt formeln score(c) = P(c) P(w 1 c) P(w n c) Välj den klass c för vilken värdet score(c) är maximalt.
35 Naive Bayes: Klassificeringsregeln välj den klass c som ger det högsta värdet till höger om argmaxet predicerad klass hur ofta förekommer ordet w
36 Två praktiska problem Problem 1: stor vokabulär Lösning: loopa över orden i dokumentet, inte i vokabulären Problem 2: okända ord (ord som inte förekommer i vokabulären) Lösning: hoppa över okända ord Problem 3: flyttalsbottning (då man multiplicerar sannolikheter) Lösning: räkna om sannolikheter till den logaritmiska skalan
37 Logaritmer av sannolikheter För att förebygga flyttalsbottning räknar man om sannolikheter till den logaritmiska skalan (eng. log probabilities). P(w c) blir till log P(w c) Istället för att multiplicera sannolikheter måste man då summera deras logaritmer.
38 Log-sannolikheter 0-0,75 log p -1,5-2, ,25 0,5 0,75 1 p
39 Skattning av Naive Bayes-modeller
40 Skattning av ordsannolikheter sannolikhet värde sannolikhet värde?? P(hasten pos)? P(hasten neg)? P(huge pos)? P(huge neg)? P(if pos)? P(if neg)? P(its pos)? P(its neg)? positiv negativ
41 Maximum Likelihood-skattning För att skatta sannolikheterna P(c): Räkna ut andelen av dokument som har klass c bland alla dokument i träningsmängden. För att skatta sannolikheterna P(w c): Räkna ut andelen av förekomster av ordet w bland alla ordförekomster i dokument med klass c.
42 Maximum Likelihood-skattning f(c) f(w, c) antalet dokument med guldstandardklass c antalet förekomster av ordet w i dokument med klass c
43 Skattning av ordsannolikheter The gorgeously elaborate continuation of The Lord of the Rings trilogy is so huge that a column of words cannot adequately describe co-writer/director Peter Jackson s expanded vision of J.R.R. Tolkien s Middle-earth. positiv is a sour little movie at its core; an exploration of the emptiness that underlay the relentless gaiety of the 1920 s, as if to stop would hasten the economic and global political turmoil that was to come. negativ 31 ordförekomster 37 ordförekomster
44 Skattning av ordsannolikheter ord frekvens ord frekvens of 4 the 4 The 2 to 2 words 1 that 2 vision 1 of 2 trilogy 1 would 1 positiv negativ
45 Skattning av ordsannolikheter sannolikhet relativ frekvens sannolikhet relativ frekvens P(of pos) 4/31 P(the neg) 4/37 P(The pos) 2/31 P(to neg) 2/37 P(words pos) 1/31 P(that neg) 2/37 P(vision pos) 1/31 P(of neg) 2/37 P(trilogy pos) 1/31 P(would neg) 1/37 positiv negativ
46 Utjämning Om man skattar ordsannolikheter med hjälp av relativa frekvenser kommer många sannolikheter vara noll. Detta är ett problem eftersom klassificeringsregeln för Naive Bayes multiplicerar sannolikheter. Slogan: Nollsannolikheter förstör information. För att undvika nollsannolikheter kan man använda tekniker för utjämning av sannolikhetsfördelningar (eng. smoothing).
47 Additiv utjämning En enkel metod är addera-ett-utjämning: addera 1 på alla (absoluta) frekvenser innan ML-skattningen. eng. add one-smoothing, Laplace smoothing Istället för att hallucinera 1 extra förekomst av varje ord kan vi hallucinera k extra förekomster: additiv utjämning. eng. additive smoothing
48 ML-skattning med addera-ett-utjämning f(c) f(w, c) antalet dokument med guldstandardklass c antalet förekomster av ordet w i dokument med klass c ingen utjämning
49 Skattning med utjämning The gorgeously elaborate continuation of The Lord of the Rings trilogy is so huge that a column of words cannot adequately describe co-writer/director Peter Jackson s expanded vision of J.R.R. Tolkien s Middle-earth. positiv is a sour little movie at its core; an exploration of the emptiness that underlay the relentless gaiety of the 1920 s, as if to stop would hasten the economic and global political turmoil that was to come. negativ 31 ordförekomster 37 ordförekomster
50 Skattning med utjämning 1920 s J.R.R. Jackson s Lord Middle-earth Peter Rings The Tolkien s a adequately an and as at cannot co-writer/director column come continuation core describe economic elaborate emptiness expanded exploration gaiety global gorgeously hasten huge if is its little movie of political relentless so sour stop that the to trilogy turmoil underlay vision was words would 53 unika ord (= vokabulär)
51 Skattning med utjämning ord ändrad frekvens ord ändrad frekvens of of The The words words vision vision trilogy trilogy positiv negativ
52 Skattning med utjämning sannolikhet skattning sannolikhet skattning P(of pos) (4 + 1)/( ) P(of neg) (2 + 1)/( ) P(The pos) (2 + 1)/( ) P(The neg) (0 + 1)/( ) P(words pos) (1 + 1)/( ) P(words neg) (0 + 1)/( ) P(vision pos) (1 + 1)/( ) P(vision neg) (0 + 1)/( ) P(trilogy pos) (1 + 1)/( ) P(trilogy neg) (0 + 1)/( ) positiv negativ
53 Sammanfattning Textklassificering träningsmängd, testmängd, korrekthet, precision, täckning Naive Bayes: Modell klassannolikheter, ordsannolikheter, klassificeringsregel Naive Bayes: Skattning Maximum Likelihood-skattning, additiv utjämning Läsanvisningar: JM kapitel 1 2, 3.1, Textklassificering med Naive Bayes 1 2
54 Textklassificering: Övningsuppgifter
55 Övningsuppgift Ett namnigenkänningssystem utvärderades på en samling testdata innehållande 800 namn. Av dessa bestod 500 av ett ord, 250 av två ord och 50 av tre ord. Tabellen nedan anger systemets resultat. rätt fel ettordsnamn tvåordsnamn treordsnamn Ställ upp bråk för följande: täckning på ettordsnamn precision på tvåordsnamn täckning på alla namn
56 Övningsuppgift Ett Naive Bayes-system ska skilja mellan nyhetstexter som handlar om Kina (K) och texter som handlar om Japan (J). Ange formler för hur systemet räknar ut score(k) och score(j) då det ska predicera klassen för dokumentet Chinese Chinese Chinese Tokyo Japan
57 Övningsuppgift Skatta sannolikheterna för en Naive Bayes-modell utifrån följande data. Antag att vokabulären består av alla förekommande ord. dokument klass Chinese Beijing Chinese K Chinese Chinese Shanghai K Chinese Macao K Tokyo Japan Chinese J
58 Övningsuppgift Gör om skattningen från föregående uppgift med addera-ettutjämning. Antag att vokabulären består av alla förekommande ord. dokument klass Chinese Beijing Chinese K Chinese Chinese Shanghai K Chinese Macao K Tokyo Japan Chinese J
TDDD02 Språkteknologi för informationssökning / 2015. Textklassificering. Marco Kuhlmann Institutionen för datavetenskap
 TDDD02 Språkteknologi för informationssökning / 2015 Textklassificering Marco Kuhlmann Institutionen för datavetenskap Textklassificering UK China Elections Sports congestion London Olympics Beijing recount
TDDD02 Språkteknologi för informationssökning / 2015 Textklassificering Marco Kuhlmann Institutionen för datavetenskap Textklassificering UK China Elections Sports congestion London Olympics Beijing recount
729G17 Språkteknologi / Introduktion. Marco Kuhlmann Institutionen för datavetenskap
 729G17 Språkteknologi / 2016 Introduktion Marco Kuhlmann Institutionen för datavetenskap Vad är språkteknologi? Vad är språkteknologi? Språkteknologi är all teknologi som skapas för att förstå eller generera
729G17 Språkteknologi / 2016 Introduktion Marco Kuhlmann Institutionen för datavetenskap Vad är språkteknologi? Vad är språkteknologi? Språkteknologi är all teknologi som skapas för att förstå eller generera
SPRÅKTEKNOLOGI. Marco Kuhlmann Institutionen för datavetenskap
 SPRÅKTEKNOLOGI Marco Kuhlmann Institutionen för datavetenskap Vad är språkteknologi? Vad är språkteknologi? all teknologi som hanterar mänskligt språk Exempel: analys, förståelse, produktion ett tvärvetenskapligt
SPRÅKTEKNOLOGI Marco Kuhlmann Institutionen för datavetenskap Vad är språkteknologi? Vad är språkteknologi? all teknologi som hanterar mänskligt språk Exempel: analys, förståelse, produktion ett tvärvetenskapligt
Tentamen 2016-01-13. Marco Kuhlmann
 TDDD02 Språkteknologi för informationssökning (2015) Tentamen 2016-01-13 Marco Kuhlmann Denna tentamen består av 10 frågor. Frågorna 8 10 ligger på en högre kunskapsnivå än de övriga och kräver utförliga
TDDD02 Språkteknologi för informationssökning (2015) Tentamen 2016-01-13 Marco Kuhlmann Denna tentamen består av 10 frågor. Frågorna 8 10 ligger på en högre kunskapsnivå än de övriga och kräver utförliga
TDDD02 Språkteknologi för informationssökning (2016) Ordpredicering. Marco Kuhlmann Institutionen för datavetenskap
 Ordpredicering. Marco Kuhlmann Institutionen för datavetenskap") TDDD02 Språkteknologi för informationssökning (2016) Ordpredicering Marco Kuhlmann Institutionen för datavetenskap Ordpredicering Ordpredicering innebär att föreslå eller välja ord i en given kontext.
TDDD02 Språkteknologi för informationssökning (2016) Ordpredicering Marco Kuhlmann Institutionen för datavetenskap Ordpredicering Ordpredicering innebär att föreslå eller välja ord i en given kontext.
Probabilistisk logik 1
 729G43 Artificiell intelligens / 2016 Probabilistisk logik 1 Marco Kuhlmann Institutionen för datavetenskap Osäkerhet 1.01 Osäkerhet Agenter måste kunna hantera osäkerhet. Agentens miljö är ofta endast
729G43 Artificiell intelligens / 2016 Probabilistisk logik 1 Marco Kuhlmann Institutionen för datavetenskap Osäkerhet 1.01 Osäkerhet Agenter måste kunna hantera osäkerhet. Agentens miljö är ofta endast
Tentamen Del A. Marco Kuhlmann
 TDDD01 Språkteknologi (2016) Tentamen 2016-03-16 Marco Kuhlmann Tentamen består två delar, A och B. Varje del omfattar ett antal frågor à 3 poäng. Del A omfattar 8 frågor som kan besvaras kortfattat. Det
TDDD01 Språkteknologi (2016) Tentamen 2016-03-16 Marco Kuhlmann Tentamen består två delar, A och B. Varje del omfattar ett antal frågor à 3 poäng. Del A omfattar 8 frågor som kan besvaras kortfattat. Det
ORDKLASSTAGGNING. Marco Kuhlmann Institutionen för datavetenskap
 ORDKLASSTAGGNING Marco Kuhlmann Institutionen för datavetenskap Ordpredicering n-gram-modeller (definition, skattning) den brusiga kanalen: P(R F) = P(F R) P(R) redigeringsavstånd, Levenshtein-avstånd
ORDKLASSTAGGNING Marco Kuhlmann Institutionen för datavetenskap Ordpredicering n-gram-modeller (definition, skattning) den brusiga kanalen: P(R F) = P(F R) P(R) redigeringsavstånd, Levenshtein-avstånd
TDDD02 Språkteknologi för informationssökning (2016) Ordklasstaggning. Marco Kuhlmann Institutionen för datavetenskap
 Ordklasstaggning. Marco Kuhlmann Institutionen för datavetenskap") TDDD02 Språkteknologi för informationssökning (2016) Ordklasstaggning Marco Kuhlmann Institutionen för datavetenskap Ordklasstaggning Tagga varje ord i en sekvens av ord (oftast en mening) med dess korrekta
TDDD02 Språkteknologi för informationssökning (2016) Ordklasstaggning Marco Kuhlmann Institutionen för datavetenskap Ordklasstaggning Tagga varje ord i en sekvens av ord (oftast en mening) med dess korrekta
Marco Kuhlmann, Institutionen för datavetenskap, Linköpings universitet 17 mars 2014
 Tentamen Marco Kuhlmann, Institutionen för datavetenskap, Linköpings universitet marco.kuhlmann@liu.se 17 mars 2014 Inga hjälpmedel är tillåtna. Maximal poäng finns angiven för varje fråga. Maximal poäng
Tentamen Marco Kuhlmann, Institutionen för datavetenskap, Linköpings universitet marco.kuhlmann@liu.se 17 mars 2014 Inga hjälpmedel är tillåtna. Maximal poäng finns angiven för varje fråga. Maximal poäng
TDDD02 Språkteknologi för informationssökning / Ordpredicering. Marco Kuhlmann Institutionen för datavetenskap
 TDDD02 Språkteknologi för informationssökning / 2015 Ordpredicering Marco Kuhlmann Institutionen för datavetenskap Ordpredicering Ordpredicering innebär att föreslå eller välja ord i en given kontext.
TDDD02 Språkteknologi för informationssökning / 2015 Ordpredicering Marco Kuhlmann Institutionen för datavetenskap Ordpredicering Ordpredicering innebär att föreslå eller välja ord i en given kontext.
Anna: Bertil: Cecilia:
 Marco Kuhlmann 1 Osäkerhet 1.01 1.02 1.03 1.04 1.05 Intelligenta agenter måste kunna hantera osäkerhet. Världen är endast delvist observerbar och stokastisk. (Jmf. Russell och Norvig, 2014, avsnitt 2.3.2.)
Marco Kuhlmann 1 Osäkerhet 1.01 1.02 1.03 1.04 1.05 Intelligenta agenter måste kunna hantera osäkerhet. Världen är endast delvist observerbar och stokastisk. (Jmf. Russell och Norvig, 2014, avsnitt 2.3.2.)
ARTIFICIELLA NEURALA NÄT. MARCO KUHLMANN Institutionen för datavetenskap
 ARTIFICIELLA NEURALA NÄT MARCO KUHLMANN Institutionen för datavetenskap Example Alt Bar Fri Hun Pat Price Rain Res Type Est WillWait 1 Yes No No Yes Some $$$ No Yes French 0 10 Yes 2 Yes No No Yes Full
ARTIFICIELLA NEURALA NÄT MARCO KUHLMANN Institutionen för datavetenskap Example Alt Bar Fri Hun Pat Price Rain Res Type Est WillWait 1 Yes No No Yes Some $$$ No Yes French 0 10 Yes 2 Yes No No Yes Full
Kombinatorik och sannolikhetslära
 Grunder i matematik och logik (2018) Kombinatorik och sannolikhetslära Marco Kuhlmann Sannolikhetslära Detta avsnitt är för det mesta en kompakt sammanfattning av momentet sannolikhetslära som ingår i
Grunder i matematik och logik (2018) Kombinatorik och sannolikhetslära Marco Kuhlmann Sannolikhetslära Detta avsnitt är för det mesta en kompakt sammanfattning av momentet sannolikhetslära som ingår i
poäng i del B Lycka till!
 TDDD02 Språkteknologi för informationssökning (2016) Tentamen 2017-01-11 Examinator: Marco Kuhlmann Denna tentamen består av två delar: 1. Del A består av 5 uppgifter som prövar din förståelse av de grundläggande
TDDD02 Språkteknologi för informationssökning (2016) Tentamen 2017-01-11 Examinator: Marco Kuhlmann Denna tentamen består av två delar: 1. Del A består av 5 uppgifter som prövar din förståelse av de grundläggande
TDDD02 Föreläsning 4 HT Klassificering av ord och dokument Lars Ahrenberg
 TDDD02 Föreläsning 4 HT-2013 Klassificering av ord och dokument Lars Ahrenberg Översikt Ø Avslutning om ngram-modeller Dokumentrepresentation Ø Klassificering med Naive Bayes ett typexempel generell metod
TDDD02 Föreläsning 4 HT-2013 Klassificering av ord och dokument Lars Ahrenberg Översikt Ø Avslutning om ngram-modeller Dokumentrepresentation Ø Klassificering med Naive Bayes ett typexempel generell metod
Bayes statistik - utan förkunskaper - utan tårar
 Bayes statistik - utan förkunskaper - utan tårar Lars Olsson Geostatistik AB 14-11-21 Bayes 1 1 Webbinariekurs Introduktionskurs för geotekniker Webbinarium 1. Fredagen den 21 nov 2014 kl 15:00 15:30 Vad
Bayes statistik - utan förkunskaper - utan tårar Lars Olsson Geostatistik AB 14-11-21 Bayes 1 1 Webbinariekurs Introduktionskurs för geotekniker Webbinarium 1. Fredagen den 21 nov 2014 kl 15:00 15:30 Vad
Institutionen för lingvistik och filologi VT 2014 (Marco Kuhlmann 2013, tillägg och redaktion Mats Dahllöf 2014).
.") UPPSALA UNIVERSITET Matematik för språkteknologer (5LN445) Institutionen för lingvistik och filologi VT 2014 (Marco Kuhlmann 2013, tillägg och redaktion Mats Dahllöf 2014). 9 Sannolikhet Detta kapitel
UPPSALA UNIVERSITET Matematik för språkteknologer (5LN445) Institutionen för lingvistik och filologi VT 2014 (Marco Kuhlmann 2013, tillägg och redaktion Mats Dahllöf 2014). 9 Sannolikhet Detta kapitel
TDDD02 Språkteknologi för informationssökning (2016) Introduktion. Marco Kuhlmann Institutionen för datavetenskap
 Introduktion. Marco Kuhlmann Institutionen för datavetenskap") TDDD02 Språkteknologi för informationssökning (2016) Introduktion Marco Kuhlmann Institutionen för datavetenskap Vad är språkteknologi? Vad är språkteknologi? Språkteknologi är all teknologi som skapas
TDDD02 Språkteknologi för informationssökning (2016) Introduktion Marco Kuhlmann Institutionen för datavetenskap Vad är språkteknologi? Vad är språkteknologi? Språkteknologi är all teknologi som skapas
Sannolikhetslära. 1 Enkel sannolikhet. Grunder i matematik och logik (2015) 1.1 Sannolikhet och relativ frekvens. Marco Kuhlmann
 1.1 Sannolikhet och relativ frekvens. Marco Kuhlmann") Marco Kuhlmann Detta kapitel behandlar grundläggande begrepp i sannolikhetsteori: enkel sannolikhet, betingad sannolikhet, lagen om total sannolikhet och Bayes lag. 1 Enkel sannolikhet Den klassiska sannolikhetsteorin,
Marco Kuhlmann Detta kapitel behandlar grundläggande begrepp i sannolikhetsteori: enkel sannolikhet, betingad sannolikhet, lagen om total sannolikhet och Bayes lag. 1 Enkel sannolikhet Den klassiska sannolikhetsteorin,
TDDD02 Språkteknologi för informationssökning / Textsammanfattning. Marco Kuhlmann Institutionen för datavetenskap
 TDDD02 Språkteknologi för informationssökning / 2015 Textsammanfattning Marco Kuhlmann Institutionen för datavetenskap Textsammanfattning Textsammanfattning går ut på att extrahera den mest relevanta informationen
TDDD02 Språkteknologi för informationssökning / 2015 Textsammanfattning Marco Kuhlmann Institutionen för datavetenskap Textsammanfattning Textsammanfattning går ut på att extrahera den mest relevanta informationen
729G43 Artificiell intelligens (2016) Maskininlärning 3. Marco Kuhlmann Institutionen för datavetenskap
 Maskininlärning 3. Marco Kuhlmann Institutionen för datavetenskap") 729G43 Artificiell intelligens (2016) Maskininlärning 3 Marco Kuhlmann Institutionen för datavetenskap Modell med vektornotation parametervektor särdragsvektor Perceptron kombinerar linjär regression med
729G43 Artificiell intelligens (2016) Maskininlärning 3 Marco Kuhlmann Institutionen för datavetenskap Modell med vektornotation parametervektor särdragsvektor Perceptron kombinerar linjär regression med
Maskininlärning. Regler eller ML?
 Maskininlärning Field of study that gives computers the ability to learn without being explicitly programmed (Samuel, 1959) DD2418 Språkteknologi, Johan Boye Regler eller ML? System som bygger på handskrivna
Maskininlärning Field of study that gives computers the ability to learn without being explicitly programmed (Samuel, 1959) DD2418 Språkteknologi, Johan Boye Regler eller ML? System som bygger på handskrivna
Probabilistisk logik 2
 729G43 Artificiell intelligens / 2016 Probabilistisk logik 2 Marco Kuhlmann Institutionen för datavetenskap Översikt Probabilistiska modeller Probabilistisk inferens 1: Betingad sannolikhet Probabilistisk
729G43 Artificiell intelligens / 2016 Probabilistisk logik 2 Marco Kuhlmann Institutionen för datavetenskap Översikt Probabilistiska modeller Probabilistisk inferens 1: Betingad sannolikhet Probabilistisk
Sannolikhetslära. 1 Grundläggande begrepp. 2 Likformiga sannolikhetsfördelningar. Marco Kuhlmann
 Marco Kuhlmann Detta är en kompakt sammanfattning av momentet sannolikhetslära som ingår i kurserna Matematik 1b och 1c på gymnasiet. I slutet av dokumentet hittar du uppgifter med vilka du kan testa om
Marco Kuhlmann Detta är en kompakt sammanfattning av momentet sannolikhetslära som ingår i kurserna Matematik 1b och 1c på gymnasiet. I slutet av dokumentet hittar du uppgifter med vilka du kan testa om
Differentiell psykologi
 Differentiell psykologi Måndagen den 19/9 2011 Sensitivitet och specificitet Version 1.1 Dagens agenda Validering av kriterietolkningar Diagnostiska studier Exempel på diagnostisk studie av MDI Olika prövningar
Differentiell psykologi Måndagen den 19/9 2011 Sensitivitet och specificitet Version 1.1 Dagens agenda Validering av kriterietolkningar Diagnostiska studier Exempel på diagnostisk studie av MDI Olika prövningar
STA101, Statistik och kvantitativa undersökningar, A 15 p Vårterminen 2017
 MÄLARDALENS HÖGSKOLA Akademin för ekonomi, samhälle och teknik STA101, Statistik och kvantitativa undersökningar, A 15 p Vårterminen 2017 Räknestuga 2 Förberedelser: Lyssna på föreläsningarna F4, F5 och
MÄLARDALENS HÖGSKOLA Akademin för ekonomi, samhälle och teknik STA101, Statistik och kvantitativa undersökningar, A 15 p Vårterminen 2017 Räknestuga 2 Förberedelser: Lyssna på föreläsningarna F4, F5 och
Klassificering av homonymer Inlämningsuppgift språkteknologi
 Klassificering av homonymer Inlämningsuppgift språkteknologi 2013-01-10 Kurskod: DD2418 Författare Gustav Ribom 910326-0593 Erik Aalto 861108-0212 Kontaktperson Johan Boye Abstract Ordet fil har flera
Klassificering av homonymer Inlämningsuppgift språkteknologi 2013-01-10 Kurskod: DD2418 Författare Gustav Ribom 910326-0593 Erik Aalto 861108-0212 Kontaktperson Johan Boye Abstract Ordet fil har flera
1 Mätdata och statistik
 Matematikcentrum Matematik NF Mätdata och statistik Betrakta frågeställningen Hur mycket väger en nyfödd bebis?. Frågan verkar naturlig, men samtidigt mycket svår att besvara. För att ge ett fullständigt
Matematikcentrum Matematik NF Mätdata och statistik Betrakta frågeställningen Hur mycket väger en nyfödd bebis?. Frågan verkar naturlig, men samtidigt mycket svår att besvara. För att ge ett fullständigt
Do you Think there is a problem with the car traffic to or from the inner city weekdays ?
 Do you Think there is a problem with the car traffic to or from the inner city weekdays 06.00 18.00? Tycker du att det finns några problem med biltrafiken till/från eller genom innerstaden under vardagar
Do you Think there is a problem with the car traffic to or from the inner city weekdays 06.00 18.00? Tycker du att det finns några problem med biltrafiken till/från eller genom innerstaden under vardagar
Prototypbaserad Inkrementell Diagnos. Anders Holst SICS, Swedish Institute of Computer Science AB
 Prototypbaserad Inkrementell Diagnos Anders Holst SICS, Swedish Institute of Computer Science AB Metoder för Industriell Diagnos Datadrivna metoder Träna in en mappning från symptom till diagnoser. Kräver
Prototypbaserad Inkrementell Diagnos Anders Holst SICS, Swedish Institute of Computer Science AB Metoder för Industriell Diagnos Datadrivna metoder Träna in en mappning från symptom till diagnoser. Kräver
händelsen som alltid inträffar. Den tomma mängden representerar händelsen som aldrig inträffar.
 Marco Kuhlmann Detta är en kompakt sammanfattning av momentet sannolikhetslära som ingår i kurserna Matematik 1b och 1c på gymnasiet. 1 Grundläggande begrepp 1.01 När vi singlar slant eller kastar tärning
Marco Kuhlmann Detta är en kompakt sammanfattning av momentet sannolikhetslära som ingår i kurserna Matematik 1b och 1c på gymnasiet. 1 Grundläggande begrepp 1.01 När vi singlar slant eller kastar tärning
Word2Vec. Högkvalitativa vektorrepresentationer av ord tränat på stora mängder data. Innehåll LINKÖPINGS UNIVERSITET. 1. Inledning...
 LINKÖPINGS UNIVERSITET Innehåll 1. Inledning... 2 2. Terminologi... 3 3. Allmänt om Word2Vec... 3 4. Continous Skip-gram model... 4 Word2Vec Högkvalitativa vektorrepresentationer av ord tränat på stora
LINKÖPINGS UNIVERSITET Innehåll 1. Inledning... 2 2. Terminologi... 3 3. Allmänt om Word2Vec... 3 4. Continous Skip-gram model... 4 Word2Vec Högkvalitativa vektorrepresentationer av ord tränat på stora
För logitmodellen ges G (=F) av den logistiska funktionen: (= exp(z)/(1+ exp(z))
 av den logistiska funktionen: (= exp(z)/(1+ exp(z))") Logitmodellen För logitmodellen ges G (=F) av den logistiska funktionen: F(z) = e z /(1 + e z ) (= exp(z)/(1+ exp(z)) Funktionen motsvarar den kumulativa fördelningsfunktionen för en standardiserad logistiskt
Logitmodellen För logitmodellen ges G (=F) av den logistiska funktionen: F(z) = e z /(1 + e z ) (= exp(z)/(1+ exp(z)) Funktionen motsvarar den kumulativa fördelningsfunktionen för en standardiserad logistiskt
STA101, Statistik och kvantitativa undersökningar, A 15 p Vårterminen 2017
 MÄLARDALENS HÖGSKOLA Akademin för ekonomi, samhälle och teknik STA101, Statistik och kvantitativa undersökningar, A 15 p Vårterminen 2017 Räknestuga 2 Förberedelser: Lyssna på föreläsningarna F4, F5 och
MÄLARDALENS HÖGSKOLA Akademin för ekonomi, samhälle och teknik STA101, Statistik och kvantitativa undersökningar, A 15 p Vårterminen 2017 Räknestuga 2 Förberedelser: Lyssna på föreläsningarna F4, F5 och
Föreläsning 8: Konfidensintervall
 Föreläsning 8: Konfidensintervall Matematisk statistik Chalmers University of Technology Maj 4, 2015 Projektuppgift Projektet går ut på att studera frisättningen av dopamin hos nervceller och de två huvudsakliga
Föreläsning 8: Konfidensintervall Matematisk statistik Chalmers University of Technology Maj 4, 2015 Projektuppgift Projektet går ut på att studera frisättningen av dopamin hos nervceller och de två huvudsakliga
MVE051/MSG Föreläsning 7
 MVE051/MSG810 2016 Föreläsning 7 Petter Mostad Chalmers November 23, 2016 Överblick Deskriptiv statistik Grafiska sammanfattningar. Numeriska sammanfattningar. Estimering (skattning) Teori Några exempel
MVE051/MSG810 2016 Föreläsning 7 Petter Mostad Chalmers November 23, 2016 Överblick Deskriptiv statistik Grafiska sammanfattningar. Numeriska sammanfattningar. Estimering (skattning) Teori Några exempel
Finns det över huvud taget anledning att förvänta sig något speciellt? Finns det en generell fördelning som beskriver en mätning?
 När vi nu lärt oss olika sätt att karaktärisera en fördelning av mätvärden, kan vi börja fundera över vad vi förväntar oss t ex för fördelningen av mätdata när vi mätte längden av en parkeringsficka. Finns
När vi nu lärt oss olika sätt att karaktärisera en fördelning av mätvärden, kan vi börja fundera över vad vi förväntar oss t ex för fördelningen av mätdata när vi mätte längden av en parkeringsficka. Finns
Innehåll: 3.4 Parametriskt eller ej 3.5 Life Table 3.6 Kaplan Meier 4. Cox Regression 4.1 Hazard Function 4.2 Estimering (PL)
") Innehåll: 1. Risk & Odds 1.1 Risk Ratio 1.2 Odds Ratio 2. Logistisk Regression 2.1 Ln Odds 2.2 SPSS Output 2.3 Estimering (ML) 2.4 Multipel 3. Survival Analys 3.1 vs. Logistisk 3.2 Censurerade data 3.3
Innehåll: 1. Risk & Odds 1.1 Risk Ratio 1.2 Odds Ratio 2. Logistisk Regression 2.1 Ln Odds 2.2 SPSS Output 2.3 Estimering (ML) 2.4 Multipel 3. Survival Analys 3.1 vs. Logistisk 3.2 Censurerade data 3.3
Tekniker för storskalig parsning
 Tekniker för storskalig parsning Introduktion till projektet Joakim Nivre Uppsala Universitet Institutionen för lingvistik och filologi joakim.nivre@lingfil.uu.se Tekniker för storskalig parsning 1(17)
Tekniker för storskalig parsning Introduktion till projektet Joakim Nivre Uppsala Universitet Institutionen för lingvistik och filologi joakim.nivre@lingfil.uu.se Tekniker för storskalig parsning 1(17)
Föreläsning 4. NDAB01 Statistik; teori och tillämpning i biologi
 Föreläsning 4 Statistik; teori och tillämpning i biologi 1 Dagens föreläsning o Icke-parametriska test Mann-Whitneys test (kap 8.10 8.11) Wilcoxons test (kap 9.5) o Transformationer (kap 13) o Ev. Andelar
Föreläsning 4 Statistik; teori och tillämpning i biologi 1 Dagens föreläsning o Icke-parametriska test Mann-Whitneys test (kap 8.10 8.11) Wilcoxons test (kap 9.5) o Transformationer (kap 13) o Ev. Andelar
Sammanfattningar Matematikboken Y
 Sammanfattningar Matematikboken Y KAPitel 1 TAL OCH RÄKNING Numeriska uttryck När man beräknar ett numeriskt uttryck utförs multiplikation och division före addition och subtraktion. Om uttrycket innehåller
Sammanfattningar Matematikboken Y KAPitel 1 TAL OCH RÄKNING Numeriska uttryck När man beräknar ett numeriskt uttryck utförs multiplikation och division före addition och subtraktion. Om uttrycket innehåller
För logitmodellen ges G (=F) av den logistiska funktionen: (= exp(z)/(1+ exp(z))
 av den logistiska funktionen: (= exp(z)/(1+ exp(z))") Logitmodellen För logitmodellen ges G (=F) av den logistiska funktionen: F(z) = e z /(1 + e z ) (= exp(z)/(1+ exp(z)) Funktionen motsvarar den kumulativa fördelningsfunktionen för en standardiserad logistiskt
Logitmodellen För logitmodellen ges G (=F) av den logistiska funktionen: F(z) = e z /(1 + e z ) (= exp(z)/(1+ exp(z)) Funktionen motsvarar den kumulativa fördelningsfunktionen för en standardiserad logistiskt
Bootstrapping för substantivtaggning
 Kungliga Tekniska Högskolan NADA Bootstrapping för substantivtaggning -Djur eller icke djur Hösten 2004 Kurs: Språkteknologi 2D1418 Jonathan Johnson j0j0@kth.se Mikael Melin mime@kth.se Handledare: Jonas
Kungliga Tekniska Högskolan NADA Bootstrapping för substantivtaggning -Djur eller icke djur Hösten 2004 Kurs: Språkteknologi 2D1418 Jonathan Johnson j0j0@kth.se Mikael Melin mime@kth.se Handledare: Jonas
SF1901: Sannolikhetslära och statistik. Statistik: Intervallskattning (konfidensintervall)
") SF1901: Sannolikhetslära och statistik Föreläsning 9. Statistik: Intervallskattning (konfidensintervall) Jan Grandell & Timo Koski 21.02.2012 Jan Grandell & Timo Koski () Matematisk statistik 21.02.2012
SF1901: Sannolikhetslära och statistik Föreläsning 9. Statistik: Intervallskattning (konfidensintervall) Jan Grandell & Timo Koski 21.02.2012 Jan Grandell & Timo Koski () Matematisk statistik 21.02.2012
Optimala koder. Övre gräns för optimala koder. Gränser. Övre gräns för optimala koder, forts.
 Datakompression fö 3 p.3 Datakompression fö 3 p.4 Optimala koder Övre gräns för optimala koder En prefixkod kallas optimal om det inte existerar någon annan kod (för samma alfabet och sannolikhetsfördelning)
Datakompression fö 3 p.3 Datakompression fö 3 p.4 Optimala koder Övre gräns för optimala koder En prefixkod kallas optimal om det inte existerar någon annan kod (för samma alfabet och sannolikhetsfördelning)
Optimala koder. Det existerar förstås flera koder som har samma kodordsmedellängd. Enklaste fallet är att bara byta 0:or mot 1:or.
 Datakompression fö 3 p.1 Optimala koder En prefixkod kallas optimal om det inte existerar någon annan kod (för samma alfabet och sannolikhetsfördelning) som har lägre kodordsmedellängd. Det existerar förstås
Datakompression fö 3 p.1 Optimala koder En prefixkod kallas optimal om det inte existerar någon annan kod (för samma alfabet och sannolikhetsfördelning) som har lägre kodordsmedellängd. Det existerar förstås
Arbetsdokument Nationella riktlinjer för rörelseorganens sjukdomar
 Arbetsdokument Nationella riktlinjer för rörelseorganens sjukdomar Detta arbetsdokument är resultatet av en litteratursökning utifrån ett tillstånds och åtgärdspar. Dokumentet har använts som underlag
Arbetsdokument Nationella riktlinjer för rörelseorganens sjukdomar Detta arbetsdokument är resultatet av en litteratursökning utifrån ett tillstånds och åtgärdspar. Dokumentet har använts som underlag
Inkvarteringsstatistik. Göteborg & Co
 Inkvarteringsstatistik Göteborg & Co Mars 2012 FoU/ Marknad & Försäljning Gästnätter storstadsregioner Mars 2012, hotell och vandrarhem Gästnattsutveckling storstadsregioner Mars 2012, hotell och vandrarhem
Inkvarteringsstatistik Göteborg & Co Mars 2012 FoU/ Marknad & Försäljning Gästnätter storstadsregioner Mars 2012, hotell och vandrarhem Gästnattsutveckling storstadsregioner Mars 2012, hotell och vandrarhem
BIOSTATISTISK GRUNDKURS, MASB11, VT-16, VT2 ÖVNING 1, OCH ÖVNING 2, SAMT INFÖR ÖVNING 3
 LUNDS UNIVERSITET, MATEMATIKCENTRUM, MATEMATISK STATISTIK BIOSTATISTISK GRUNDKURS, MASB11, VT-16, VT2 ÖVNING 1, 2016-04-01 OCH ÖVNING 2, 2016-04-04 SAMT INFÖR ÖVNING 3 Övningarnas mål: Du ska förstå grundläggande
LUNDS UNIVERSITET, MATEMATIKCENTRUM, MATEMATISK STATISTIK BIOSTATISTISK GRUNDKURS, MASB11, VT-16, VT2 ÖVNING 1, 2016-04-01 OCH ÖVNING 2, 2016-04-04 SAMT INFÖR ÖVNING 3 Övningarnas mål: Du ska förstå grundläggande
Tentamen i. TDDC67 Funktionell programmering och Lisp
 1 Linköpings tekniska högskola Institutionen för datavetenskap Anders Haraldsson Tentamen i TDDC67 Funktionell programmering och Lisp och äldre kurser TDDC57 Programmering, Lisp och funktionell programmering
1 Linköpings tekniska högskola Institutionen för datavetenskap Anders Haraldsson Tentamen i TDDC67 Funktionell programmering och Lisp och äldre kurser TDDC57 Programmering, Lisp och funktionell programmering
Föreläsning 12: Repetition
 Föreläsning 12: Repetition Marina Axelson-Fisk 25 maj, 2016 GRUNDLÄGGANDE SANNOLIKHETSTEORI Grundläggande sannolikhetsteori Utfall = resultatet av ett försök Utfallsrum S = mängden av alla utfall Händelse
Föreläsning 12: Repetition Marina Axelson-Fisk 25 maj, 2016 GRUNDLÄGGANDE SANNOLIKHETSTEORI Grundläggande sannolikhetsteori Utfall = resultatet av ett försök Utfallsrum S = mängden av alla utfall Händelse
SF1901: Sannolikhetslära och statistik. Statistik: Intervallskattning (konfidensintervall) Jan Grandell & Timo Koski
 Jan Grandell & Timo Koski") SF1901: Sannolikhetslära och statistik Föreläsning 10. Statistik: Intervallskattning (konfidensintervall) Jan Grandell & Timo Koski 18.02.2016 Jan Grandell & Timo Koski Matematisk statistik 18.02.2016
SF1901: Sannolikhetslära och statistik Föreläsning 10. Statistik: Intervallskattning (konfidensintervall) Jan Grandell & Timo Koski 18.02.2016 Jan Grandell & Timo Koski Matematisk statistik 18.02.2016
Taltaggning. Rapport av Daniel Hasselrot 781105-0157, d98-dha@nada.kth.se 13 oktober 2003
 Taltaggning av Daniel Hasselrot 781105-0157, d98-dha@nada.kth.se 13 oktober 2003 Sammanfattning Denna rapport är skriven i kursen Språkteknologi och behandlar taggning av årtal i en text. Metoden som används
Taltaggning av Daniel Hasselrot 781105-0157, d98-dha@nada.kth.se 13 oktober 2003 Sammanfattning Denna rapport är skriven i kursen Språkteknologi och behandlar taggning av årtal i en text. Metoden som används
Föreläsning 13 Innehåll
 Föreläsning 13 Innehåll Exempel på problem där materialet i kursen används Hitta k största bland n element Histogramproblemet Schemaläggning PFK (Föreläsning 13) VT 2013 1 / 15 Hitta k största bland n
Föreläsning 13 Innehåll Exempel på problem där materialet i kursen används Hitta k största bland n element Histogramproblemet Schemaläggning PFK (Föreläsning 13) VT 2013 1 / 15 Hitta k största bland n
Artificial Intelligence
 Omtentamen Artificial Intelligence Datum: 2014-08-27 Tid: 09.00 13.00 Ansvarig: Resultat: Hjälpmedel: Gränser: Anders Gidenstam Redovisas inom tre veckor Inga G 8p, VG 12p, Max 16p Notera: Skriv läsbart!
Omtentamen Artificial Intelligence Datum: 2014-08-27 Tid: 09.00 13.00 Ansvarig: Resultat: Hjälpmedel: Gränser: Anders Gidenstam Redovisas inom tre veckor Inga G 8p, VG 12p, Max 16p Notera: Skriv läsbart!
TMS136: Dataanalys och statistik Tentamen
 TMS136: Dataanalys och statistik Tentamen 013-08-7 Examinator och jour: Mattias Sunden, tel. 0730 79 9 79 Hjälpmedel: Chalmersgodkänd räknare och formelsamling (formelsamling delas ut med tentan). Betygsgränser:
TMS136: Dataanalys och statistik Tentamen 013-08-7 Examinator och jour: Mattias Sunden, tel. 0730 79 9 79 Hjälpmedel: Chalmersgodkänd räknare och formelsamling (formelsamling delas ut med tentan). Betygsgränser:
Tentamentsskrivning: Matematisk Statistik med Metoder MVE490 1
 Tentamentsskrivning: Matematisk Statistik med Metoder MVE490 1 Tentamentsskrivning i Matematisk Statistik med Metoder MVE490 Tid: den 16 augusti, 2017 Examinatorer: Kerstin Wiklander och Erik Broman. Jour:
Tentamentsskrivning: Matematisk Statistik med Metoder MVE490 1 Tentamentsskrivning i Matematisk Statistik med Metoder MVE490 Tid: den 16 augusti, 2017 Examinatorer: Kerstin Wiklander och Erik Broman. Jour:
Föreläsning 5 Innehåll
 Föreläsning 5 Innehåll Algoritmer och effektivitet Att bedöma och jämföra effektivitet för algoritmer Begreppet tidskomplexitet Datavetenskap (LTH) Föreläsning 5 VT 2019 1 / 39 Val av algoritm och datastruktur
Föreläsning 5 Innehåll Algoritmer och effektivitet Att bedöma och jämföra effektivitet för algoritmer Begreppet tidskomplexitet Datavetenskap (LTH) Föreläsning 5 VT 2019 1 / 39 Val av algoritm och datastruktur
TDDD02 Språkteknologi för informationssökning (2016) Semantisk analys. Marco Kuhlmann Institutionen för datavetenskap
 Semantisk analys. Marco Kuhlmann Institutionen för datavetenskap") TDDD02 Språkteknologi för informationssökning (2016) Semantisk analys Marco Kuhlmann Institutionen för datavetenskap Semantik pragmatik semantik analys generering syntax morfologi Denna föreläsning ordbetydelsebestämning
TDDD02 Språkteknologi för informationssökning (2016) Semantisk analys Marco Kuhlmann Institutionen för datavetenskap Semantik pragmatik semantik analys generering syntax morfologi Denna föreläsning ordbetydelsebestämning
729G43 Artificiell intelligens Probabilistisk logik. Arne Jönsson HCS/IDA
 729G43 Artificiell intelligens Probabilistisk logik Arne Jönsson HCS/IDA Probabilistiska resonemang Osäkerhet Grundläggande sannolikhetslära Stokastiska variabler Bayes teorem Bayesianska nätverk Konstruktion
729G43 Artificiell intelligens Probabilistisk logik Arne Jönsson HCS/IDA Probabilistiska resonemang Osäkerhet Grundläggande sannolikhetslära Stokastiska variabler Bayes teorem Bayesianska nätverk Konstruktion
Laboration 2: Styrkefunktion samt Regression
 Lunds Tekniska Högskola Matematikcentrum Matematisk statistik Laboration 2 Styrkefunktion & Regression FMSF70&MASB02, HT19 Laboration 2: Styrkefunktion samt Regression Syfte Styrkefunktion Syftet med dagens
Lunds Tekniska Högskola Matematikcentrum Matematisk statistik Laboration 2 Styrkefunktion & Regression FMSF70&MASB02, HT19 Laboration 2: Styrkefunktion samt Regression Syfte Styrkefunktion Syftet med dagens
Hitta k största bland n element. Föreläsning 13 Innehåll. Histogramproblemet
 Föreläsning 13 Innehåll Algoritm 1: Sortera Exempel på problem där materialet i kursen används Histogramproblemet Schemaläggning Abstrakta datatyper Datastrukturer Att jämföra objekt Om tentamen Skriftlig
Föreläsning 13 Innehåll Algoritm 1: Sortera Exempel på problem där materialet i kursen används Histogramproblemet Schemaläggning Abstrakta datatyper Datastrukturer Att jämföra objekt Om tentamen Skriftlig
Tentamen på. Statistik och kvantitativa undersökningar STA101, 15 hp. Fredagen den 9 e juni Ten 1, 9 hp
 MÄLARDALENS HÖGSKOLA Akademin för ekonomi, samhälle och teknik Statistik Tentamen på Statistik och kvantitativa undersökningar STA101, 15 hp Fredagen den 9 e juni 2017 Ten 1, 9 hp Tillåtna hjälpmedel:
MÄLARDALENS HÖGSKOLA Akademin för ekonomi, samhälle och teknik Statistik Tentamen på Statistik och kvantitativa undersökningar STA101, 15 hp Fredagen den 9 e juni 2017 Ten 1, 9 hp Tillåtna hjälpmedel:
Maskininlärning med boostrapping. Maskininlärningslabb i Språkteknologi
 Maskininlärning med boostrapping Maskininlärningslabb i Språkteknologi Abstrakt Vi undersöker, med hjälp av maskininlärningslabben från denna kurs, hur pass bra resultat bootstrapping ger i samband med
Maskininlärning med boostrapping Maskininlärningslabb i Språkteknologi Abstrakt Vi undersöker, med hjälp av maskininlärningslabben från denna kurs, hur pass bra resultat bootstrapping ger i samband med
I en deterministisk omgivning beror nästa tillstånd bara av agentens handling och nuvarande tillstånd.
 OBS! För flervalsfrågorna gäller att ett, flera eller inget alternativ kan vara korrekt. På flervalsfrågorna ges 1 poäng för korrekt svar och 0,5 poäng om skillnaden mellan antalet korrekta svar och antalet
OBS! För flervalsfrågorna gäller att ett, flera eller inget alternativ kan vara korrekt. På flervalsfrågorna ges 1 poäng för korrekt svar och 0,5 poäng om skillnaden mellan antalet korrekta svar och antalet
Lektionsanteckningar 2: Matematikrepetition, tabeller och diagram
 Lektionsanteckningar 2: Matematikrepetition, tabeller och diagram 2.1 Grundläggande matematik 2.1.1 Potensfunktioner xmxn xm n x x x x 3 4 34 7 x x m n x mn x x 4 3 x4 3 x1 x x n 1 x n x 3 1 x 3 x0 1 1
Lektionsanteckningar 2: Matematikrepetition, tabeller och diagram 2.1 Grundläggande matematik 2.1.1 Potensfunktioner xmxn xm n x x x x 3 4 34 7 x x m n x mn x x 4 3 x4 3 x1 x x n 1 x n x 3 1 x 3 x0 1 1
13.1 Matematisk statistik
 13.1 Matematisk statistik 13.1.1 Grundläggande begrepp I den här föreläsningen kommer vi att definiera och exemplifiera ett antal begrepp som sedan kommer att följa oss genom hela kursen. Det är därför
13.1 Matematisk statistik 13.1.1 Grundläggande begrepp I den här föreläsningen kommer vi att definiera och exemplifiera ett antal begrepp som sedan kommer att följa oss genom hela kursen. Det är därför
Dependensregler - Lathund
 Dependensregler - Lathund INTRODUKTION I textprogrammet TeCST är det möjligt för en skribent att skriva, redigera och klistra in text för att få ut läsbarhetsmått och få förslag på hur texten kan skrivas
Dependensregler - Lathund INTRODUKTION I textprogrammet TeCST är det möjligt för en skribent att skriva, redigera och klistra in text för att få ut läsbarhetsmått och få förslag på hur texten kan skrivas
Vad Betyder måtten MAPE, MAD och MSD?
 Vad Betyder måtten MAPE, MAD och MSD? Alla tre är mått på hur bra anpassningen är och kan användas för att jämföra olika modeller. Den modell som har lägst MAPE, MAD och/eller MSD har bäst anpassning.
Vad Betyder måtten MAPE, MAD och MSD? Alla tre är mått på hur bra anpassningen är och kan användas för att jämföra olika modeller. Den modell som har lägst MAPE, MAD och/eller MSD har bäst anpassning.
Instruktioner - Datortentamen TDDD73 Funktionell och imperativ programmering i Python
 Instruktioner - Datortentamen TDDD73 Funktionell och imperativ programmering i Python Hjälpmedel Följande hjälpmedel är tillåtna: Exakt en valfri bok, t.ex. den rekommenderade kursboken. Boken får ha anteckningar,
Instruktioner - Datortentamen TDDD73 Funktionell och imperativ programmering i Python Hjälpmedel Följande hjälpmedel är tillåtna: Exakt en valfri bok, t.ex. den rekommenderade kursboken. Boken får ha anteckningar,
Tentamen MVE301 Sannolikhet, statistik och risk
 Tentamen MVE30 Sannolikhet, statistik och risk 207-08-5 kl. 8:30-3:30 Examinator: Johan Jonasson, Matematiska vetenskaper, Chalmers Telefonvakt: Olof Elias, telefon: 03-7725325 Hjälpmedel: Valfri miniräknare.
Tentamen MVE30 Sannolikhet, statistik och risk 207-08-5 kl. 8:30-3:30 Examinator: Johan Jonasson, Matematiska vetenskaper, Chalmers Telefonvakt: Olof Elias, telefon: 03-7725325 Hjälpmedel: Valfri miniräknare.
Lösningsförslag till tentamen i Språkteknologi 2D1418,
 Lösningsförslag till tentamen i Språkteknologi 2D1418, 2004-10-18 1. Stavningskontroll utan ordlista (10 poäng) a) Med 29 bokstäver i alfabetet och en specialbokstav för ordbörjan/ordslut så finns det
Lösningsförslag till tentamen i Språkteknologi 2D1418, 2004-10-18 1. Stavningskontroll utan ordlista (10 poäng) a) Med 29 bokstäver i alfabetet och en specialbokstav för ordbörjan/ordslut så finns det
Grundläggande logik och modellteori
 Grundläggande logik och modellteori Kapitel 6: Binära beslutsdiagram (BDD) Henrik Björklund Umeå universitet 22. september, 2014 Binära beslutsdiagram Binära beslutsdiagram (Binary decision diagrams, BDDs)
Grundläggande logik och modellteori Kapitel 6: Binära beslutsdiagram (BDD) Henrik Björklund Umeå universitet 22. september, 2014 Binära beslutsdiagram Binära beslutsdiagram (Binary decision diagrams, BDDs)
Statistik och epidemiologi T5
 Statistik och epidemiologi T5 Anna Axmon Biostatistiker Yrkes- och miljömedicin Dagens föreläsning Fördjupning av hypotesprövning Repetition av p-värde och konfidensintervall Tester för ytterligare situationer
Statistik och epidemiologi T5 Anna Axmon Biostatistiker Yrkes- och miljömedicin Dagens föreläsning Fördjupning av hypotesprövning Repetition av p-värde och konfidensintervall Tester för ytterligare situationer
Statistisk Maskinöversättning eller:
 729G43 Statistisk Maskinöversättning eller: Hur jag slutade ängslas (över fördjupningsuppgiften) och lärde mig hata stoppord. Jonas Hilmersson 2019-04-15 Innehåll 1. Introduktion... 1 2. Datamängden...
729G43 Statistisk Maskinöversättning eller: Hur jag slutade ängslas (över fördjupningsuppgiften) och lärde mig hata stoppord. Jonas Hilmersson 2019-04-15 Innehåll 1. Introduktion... 1 2. Datamängden...
- ett statistiskt fråga-svarsystem
 - ett statistiskt fråga-svarsystem 2010-09-28 Artificiell intelligens II Linnea Wahlberg linwa713 1 Innehåll Introduktion... 1 Grundprinciper för asked!... 2 Retrieval model... 4 Filter model... 6 Komponenter...
- ett statistiskt fråga-svarsystem 2010-09-28 Artificiell intelligens II Linnea Wahlberg linwa713 1 Innehåll Introduktion... 1 Grundprinciper för asked!... 2 Retrieval model... 4 Filter model... 6 Komponenter...
Föreläsning 1. Repetition av sannolikhetsteori. Patrik Zetterberg. 6 december 2012
 Föreläsning 1 Repetition av sannolikhetsteori Patrik Zetterberg 6 december 2012 1 / 28 Viktiga statistiska begrepp För att kunna förstå mer avancerade koncept under kursens gång är det viktigt att vi förstår
Föreläsning 1 Repetition av sannolikhetsteori Patrik Zetterberg 6 december 2012 1 / 28 Viktiga statistiska begrepp För att kunna förstå mer avancerade koncept under kursens gång är det viktigt att vi förstår
Fakta om parkour LÄSFÖRSTÅELSE. Elevmaterial KALLE GÜETTLER SIDAN 1. Namn: Vad är parkour?
 SIDAN 1 Elevmaterial Namn: LÄSFÖRSTÅELSE Vad är parkour? 1. Vad menas med parkour? 2. Vad betyder parkour på svenska? 3. Vad handlar parkour inte om? 4. Det står i texten att man ska ta sig smidigt förbi
SIDAN 1 Elevmaterial Namn: LÄSFÖRSTÅELSE Vad är parkour? 1. Vad menas med parkour? 2. Vad betyder parkour på svenska? 3. Vad handlar parkour inte om? 4. Det står i texten att man ska ta sig smidigt förbi
Sannolikhetsteori. Måns Thulin. Uppsala universitet Statistik för ingenjörer 23/ /14
 1/14 Sannolikhetsteori Måns Thulin Uppsala universitet thulin@math.uu.se Statistik för ingenjörer 23/1 2013 2/14 Dagens föreläsning Relativa frekvenser Matematik för händelser Definition av sannolikhet
1/14 Sannolikhetsteori Måns Thulin Uppsala universitet thulin@math.uu.se Statistik för ingenjörer 23/1 2013 2/14 Dagens föreläsning Relativa frekvenser Matematik för händelser Definition av sannolikhet
Statistiska Institutionen Gebrenegus Ghilagaber (docent)
") Statistiska Institutionen Gebrenegus Ghilagaber (docent) Lösningsförslag till skriftlig tentamen i FINANSIELL STATISTIK, grundnivå, 7,5 hp, VT09. Onsdagen 3 juni 2009-1 Sannolkhetslära Mobiltelefoner tillverkas
Statistiska Institutionen Gebrenegus Ghilagaber (docent) Lösningsförslag till skriftlig tentamen i FINANSIELL STATISTIK, grundnivå, 7,5 hp, VT09. Onsdagen 3 juni 2009-1 Sannolkhetslära Mobiltelefoner tillverkas
Sju dagar före viral exponering med echinacea därefter Efter viral exponering med echinacea därefter Placebo (ingen echinacea) 58 30
 58 30") Avd Matematisk statistik TENTAMEN I SF1911, STATISTIK FÖR BIOTEKNIK Torsdag den femte april 18 14:00-19:00 Examinator: Timo Koski, 072 14861 Kursledare: Timo Koski, 072 14861 Tillåtna hjälpmedel: Formel-
Avd Matematisk statistik TENTAMEN I SF1911, STATISTIK FÖR BIOTEKNIK Torsdag den femte april 18 14:00-19:00 Examinator: Timo Koski, 072 14861 Kursledare: Timo Koski, 072 14861 Tillåtna hjälpmedel: Formel-
Analys av medelvärden. Jenny Selander , plan 3, Norrbacka, ingång via den Samhällsmedicinska kliniken
 Analys av medelvärden Jenny Selander jenny.selander@ki.se 524 800 29, plan 3, Norrbacka, ingång via den Samhällsmedicinska kliniken Jenny Selander, Kvant. metoder, FHV T1 december 20111 Innehåll Normalfördelningen
Analys av medelvärden Jenny Selander jenny.selander@ki.se 524 800 29, plan 3, Norrbacka, ingång via den Samhällsmedicinska kliniken Jenny Selander, Kvant. metoder, FHV T1 december 20111 Innehåll Normalfördelningen
TSRT62 Modellbygge & Simulering
 TSRT62 Modellbygge & Simulering Föreläsning 4 Christian Lyzell Avdelningen för Reglerteknik Institutionen för Systemteknik Linköpings Universitet C. Lyzell (LiTH) TSRT62 Modellbygge & Simulering 2013 1
TSRT62 Modellbygge & Simulering Föreläsning 4 Christian Lyzell Avdelningen för Reglerteknik Institutionen för Systemteknik Linköpings Universitet C. Lyzell (LiTH) TSRT62 Modellbygge & Simulering 2013 1
Ingenjörsmetodik IT & ME 2011 Föreläsning 11
 Ingenjörsmetodik IT & ME 011 Föreläsning 11 Sammansatt fel (Gauss regel) Felanalys och noggrannhetsanalys Mätvärden och mätfel Medelvärde, standardavvikelse och standardosäkerher (statistik) 1 Läsanvisningar
Ingenjörsmetodik IT & ME 011 Föreläsning 11 Sammansatt fel (Gauss regel) Felanalys och noggrannhetsanalys Mätvärden och mätfel Medelvärde, standardavvikelse och standardosäkerher (statistik) 1 Läsanvisningar
Matematisk Statistik och Disktret Matematik, MVE051/MSG810, VT19
 Matematisk Statistik och Disktret Matematik, MVE051/MSG810, VT19 Nancy Abdallah Chalmers - Göteborgs Universitet March 25, 2019 1 / 36 1. Inledning till sannolikhetsteori 2. Sannolikhetslagar 2 / 36 Lärare
Matematisk Statistik och Disktret Matematik, MVE051/MSG810, VT19 Nancy Abdallah Chalmers - Göteborgs Universitet March 25, 2019 1 / 36 1. Inledning till sannolikhetsteori 2. Sannolikhetslagar 2 / 36 Lärare
Statistik 1 för biologer, logopeder och psykologer
 Innehåll 1 Grunderna i sannolikhetslära 2 Innehåll 1 Grunderna i sannolikhetslära 2 Satistik och sannolikhetslära Statistik handlar om att utvinna information från data. I praktiken inhehåller de data
Innehåll 1 Grunderna i sannolikhetslära 2 Innehåll 1 Grunderna i sannolikhetslära 2 Satistik och sannolikhetslära Statistik handlar om att utvinna information från data. I praktiken inhehåller de data
TDDD02 Föreläsning 7 HT-2013
 TDDD02 Föreläsning 7 HT-2013 Textsammanfattning Lars Ahrenberg Litt: Våge et al.170-185; Das & Martins, A Survey on Automatic Text Summarization sid 1-4, 11-14, 23-25. Översikt Textstruktur Problemet textsammanfattning
TDDD02 Föreläsning 7 HT-2013 Textsammanfattning Lars Ahrenberg Litt: Våge et al.170-185; Das & Martins, A Survey on Automatic Text Summarization sid 1-4, 11-14, 23-25. Översikt Textstruktur Problemet textsammanfattning
Föreläsning 5 Innehåll. Val av algoritm och datastruktur. Analys av algoritmer. Tidsåtgång och problemets storlek
 Föreläsning 5 Innehåll Val av algoritm och datastruktur Algoritmer och effektivitet Att bedöma och jämföra effektivitet för algoritmer Begreppet tidskomplexitet Det räcker inte med att en algoritm är korrekt
Föreläsning 5 Innehåll Val av algoritm och datastruktur Algoritmer och effektivitet Att bedöma och jämföra effektivitet för algoritmer Begreppet tidskomplexitet Det räcker inte med att en algoritm är korrekt
Att skatta njurfunktionen! - beskriva hur SBUs expertgrupp arbetat - ge ett sammandrag av rapporten från SBU
 Att skatta njurfunktionen! - beskriva hur SBUs expertgrupp arbetat - ge ett sammandrag av rapporten från SBU Carl-Gustaf Elinder, professor KI, avdelningschef, Hälso- och Sjukvårdsförvaltningen, Sthlm
Att skatta njurfunktionen! - beskriva hur SBUs expertgrupp arbetat - ge ett sammandrag av rapporten från SBU Carl-Gustaf Elinder, professor KI, avdelningschef, Hälso- och Sjukvårdsförvaltningen, Sthlm
Att använda Weka för språkteknologiska problem
 Att använda Weka för språkteknologiska problem Systemet WEKA (Waikato Environment for Knowledge Acquisition) är en verktygslåda med olika maskininlärningsalgoritmer, metoder för att behandla indata, möjligheter
Att använda Weka för språkteknologiska problem Systemet WEKA (Waikato Environment for Knowledge Acquisition) är en verktygslåda med olika maskininlärningsalgoritmer, metoder för att behandla indata, möjligheter
Användning. Fixed & Random. Centrering. Multilevel Modeling (MLM) Var sak på sin nivå
 Var sak på sin nivå") Användning Multilevel Modeling (MLM) Var sak på sin nivå Kimmo Sorjonen Sektionen för Psykologi Karolinska Institutet Kärt barn har många namn: (1) Random coefficient models; (2) Mixed effect models; (3)
Användning Multilevel Modeling (MLM) Var sak på sin nivå Kimmo Sorjonen Sektionen för Psykologi Karolinska Institutet Kärt barn har många namn: (1) Random coefficient models; (2) Mixed effect models; (3)
Användning. Fixed & Random. Centrering. Multilevel Modeling (MLM) Var sak på sin nivå
 Var sak på sin nivå") Användning Multilevel Modeling (MLM) Var sak på sin nivå Kimmo Sorjonen Sektionen för Psykologi Karolinska Institutet Kärt barn har många namn: (1) Random coefficient models; () Mixed effect models; (3)
Användning Multilevel Modeling (MLM) Var sak på sin nivå Kimmo Sorjonen Sektionen för Psykologi Karolinska Institutet Kärt barn har många namn: (1) Random coefficient models; () Mixed effect models; (3)
Unit course plan English class 8C
 Hanna Rüngen Wallner Unit course plan English class 8C Spring term 2018-01-11 w.2-8 forgery safe robbery burglar crime scene Mål och syfte med arbetsområdet Utveckla sin förmåga att: - kommunicera i tal
Hanna Rüngen Wallner Unit course plan English class 8C Spring term 2018-01-11 w.2-8 forgery safe robbery burglar crime scene Mål och syfte med arbetsområdet Utveckla sin förmåga att: - kommunicera i tal
PROGRAMFÖRKLARING I. Statistik för modellval och prediktion. Ett exempel: vågriktning och våghöjd
 Statistik för modellval och prediktion att beskriva, förklara och förutsäga Georg Lindgren PROGRAMFÖRKLARING I Matematisk statistik, Lunds universitet stik för modellval och prediktion p.1/4 Statistik
Statistik för modellval och prediktion att beskriva, förklara och förutsäga Georg Lindgren PROGRAMFÖRKLARING I Matematisk statistik, Lunds universitet stik för modellval och prediktion p.1/4 Statistik
LÖSNINGAR TILL P(A) = P(B) = P(C) = 1 3. (a) Satsen om total sannolikhet ger P(A M) 3. (b) Bayes formel ger
 = P(B) = P(C) = 1 3. (a) Satsen om total sannolikhet ger P(A M) 3. (b) Bayes formel ger") LÖSNINGAR TILL Matematisk statistik Tentamen: 2015 08 18 kl 8 00 13 00 Matematikcentrum FMS 086 Matematisk statistik för B, K, N och BME, 7.5 hp Lunds tekniska högskola MASB02 Matematisk statistik för
LÖSNINGAR TILL Matematisk statistik Tentamen: 2015 08 18 kl 8 00 13 00 Matematikcentrum FMS 086 Matematisk statistik för B, K, N och BME, 7.5 hp Lunds tekniska högskola MASB02 Matematisk statistik för
Artificiell Intelligens Lektion 7
 Laboration 6 Artificiell Intelligens Lektion 7 Neurala nätverk (Lab 6) Probabilistiska resonemang Vad? Mönsterigenkänning Lära ett neuralt nätverk att känna igen siffror Varför? Få ökad förståelse för
Laboration 6 Artificiell Intelligens Lektion 7 Neurala nätverk (Lab 6) Probabilistiska resonemang Vad? Mönsterigenkänning Lära ett neuralt nätverk att känna igen siffror Varför? Få ökad förståelse för
Övningshäfte 2: Induktion och rekursion
 GÖTEBORGS UNIVERSITET MATEMATIK 1, MMG200, HT2017 INLEDANDE ALGEBRA Övningshäfte 2: Induktion och rekursion Övning D Syftet är att öva förmågan att utgående från enkla samband, aritmetiska och geometriska,
GÖTEBORGS UNIVERSITET MATEMATIK 1, MMG200, HT2017 INLEDANDE ALGEBRA Övningshäfte 2: Induktion och rekursion Övning D Syftet är att öva förmågan att utgående från enkla samband, aritmetiska och geometriska,
Till ampad statistik (A5) Förläsning 13: Logistisk regression
 Förläsning 13: Logistisk regression") Till ampad statistik (A5) Förläsning 13: Logistisk regression Ronnie Pingel Statistiska institutionen Senast uppdaterad: 2016-03-08 Exempel 1: NTU2015 Exempel 2: En jobbannons Exempel 3 1 1 Klofstad, C.
Till ampad statistik (A5) Förläsning 13: Logistisk regression Ronnie Pingel Statistiska institutionen Senast uppdaterad: 2016-03-08 Exempel 1: NTU2015 Exempel 2: En jobbannons Exempel 3 1 1 Klofstad, C.
729G43 Artificiell intelligens / Maskininlärning 3. Marco Kuhlmann
 729G43 Artificiell intelligens / 2015 Maskininlärning 3 Marco Kuhlmann Förra gången: Perceptroninlärning Beslutsregel predicerat y-värde Exempel: AND Välj parametrar θ 0, θ 1, θ 2 sådana att perceptronen
729G43 Artificiell intelligens / 2015 Maskininlärning 3 Marco Kuhlmann Förra gången: Perceptroninlärning Beslutsregel predicerat y-värde Exempel: AND Välj parametrar θ 0, θ 1, θ 2 sådana att perceptronen