Föreläsning 7 och 8: Regressionsanalys
|
|
|
- Rebecka Dahlberg
- för 8 år sedan
- Visningar:
Transkript
1 Föreläsning 7 och 8: Pär Nyman par.nyman@statsvet.uu.se 12 september

2 Vårt viktigaste verktyg för kvantitativa studier. Kan användas till det mesta, men svarar oftast på frågor om kausala samband. På kursen lär vi ut de viktigaste grunderna. Viktigt även för dem som inte själva vill använda det! - 2 -

3 Disposition för hela dagen 1 Repetition och passningsmått 2 från urval till population 3 Att läsa stabeller 4 Spuriösa samband Indirekta samband 5 6 Några saker att se upp för 7-3 -

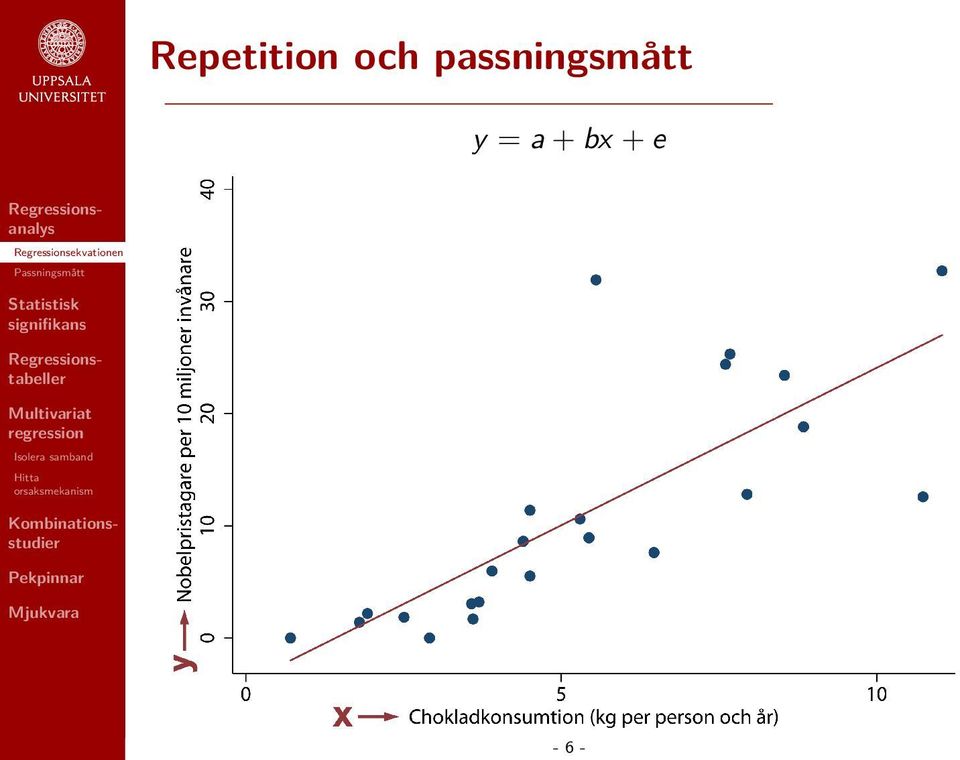
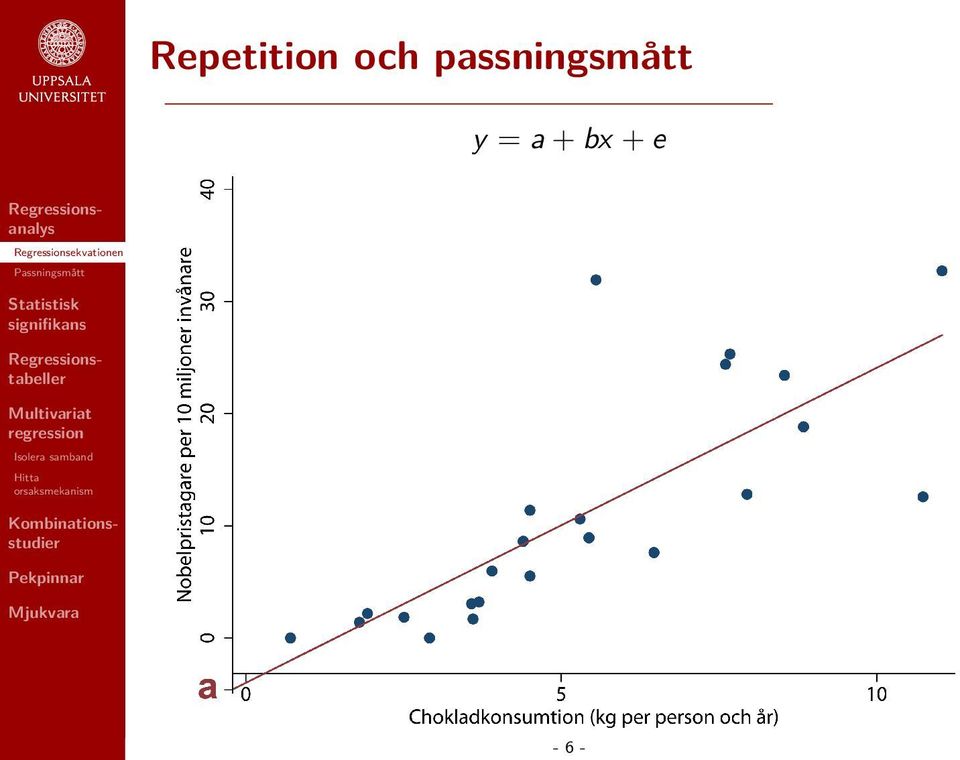
4 Repetition och passningsmått (bivariat) y = Beroende variabel a = Konstant eller intercept b = Regressionskoefficient x = Oberoende variabel e = Felterm eller residual y = a + bx + e - 4 -

5 Repetition och passningsmått Regressionsekvation med indexsiffror y i = a + bx i + e i y = Beroende variabel a = Konstant eller intercept b = Regressionskoefficient x = Oberoende variabel e = Felterm eller residual i = Indexsiffra från observation 1 till observation n - 4 -

6 Repetition och passningsmått Regressionsekvation för förväntade värden ŷ = a + bx ŷ = Förväntat värde på den beroende variabel a = Konstant eller intercept b = Regressionskoefficient x = Oberoende variabel - 4 -

7 Repetition och passningsmått sekvation 1 y = Beroende variabel a = Konstant eller intercept b 1 = Regressionskoefficient 1 b 1 = Regressionskoefficient 2 x = Oberoende variabel 1 z = Oberoende variabel 2 e = Felterm eller residual y = a + b 1 x + b 2 z + e - 4 -

8 Repetition och passningsmått sekvation 2 y = Beroende variabel a = Konstant eller intercept b 1 = Regressionskoefficient 1 b 1 = Regressionskoefficient 2 x 1 = Oberoende variabel 1 x 2 = Oberoende variabel 2 e = Felterm eller residual y = a + b 1 x 1 + b 2 x 2 + e - 4 -

9 Repetition och passningsmått sekvation 3 Inkomst = a + b 1 Utbildning + b 2 Kvinna + e y = Beroende variabel a = Konstant eller intercept b 1 = Regressionskoefficient 1 b 1 = Regressionskoefficient 2 Utbildning = Oberoende variabel 1 Kvinna = Oberoende variabel 2 e = Felterm eller residual - 4 -

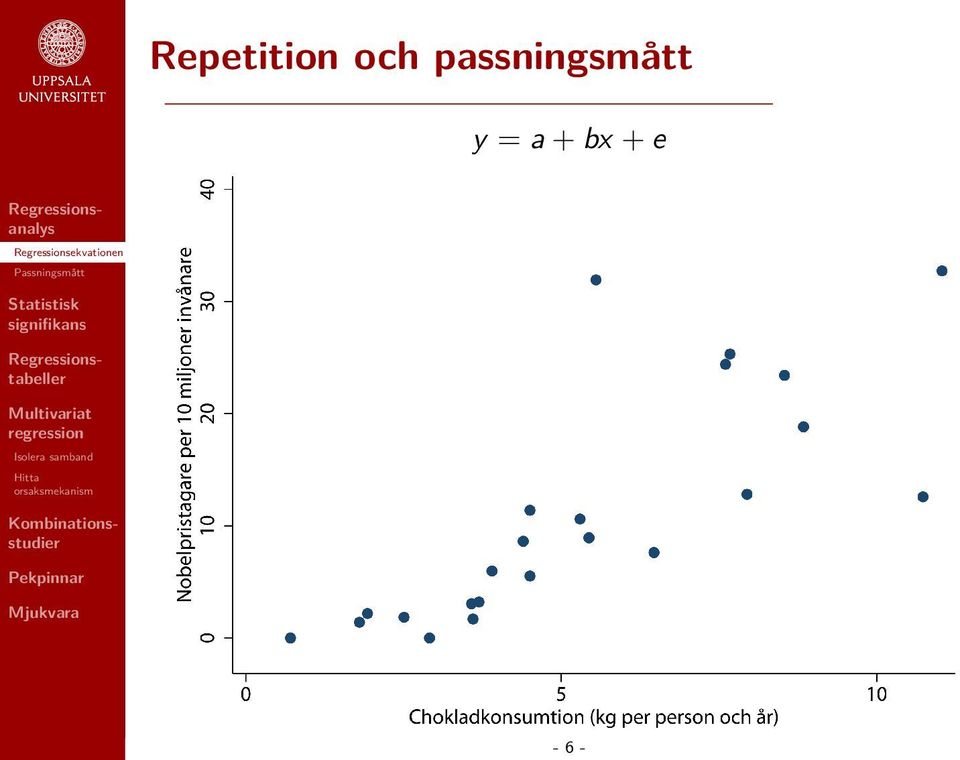
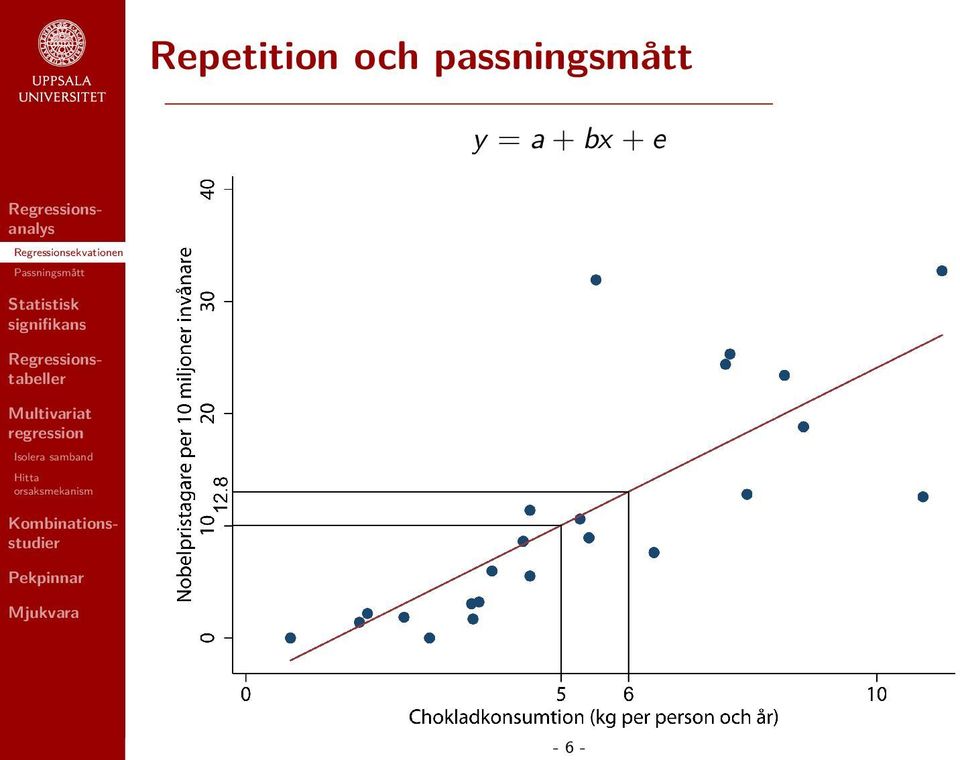
10 Repetition och passningsmått Exempel från British Journal of Medicine: Vad förklarar variationen i länders vetenskapliga framgångar? Rimligtvis beror vetenskaplig framgång i någon mån på kognitiv förmåga. Kognitiv förmåga kan eventuellt förbättras genom kost rik på flavonoler. Det finns mycket flavonoler i choklad. Alltså bör andelen Nobelpristagare vara större i länder där man äter mycket choklad? - 5 -

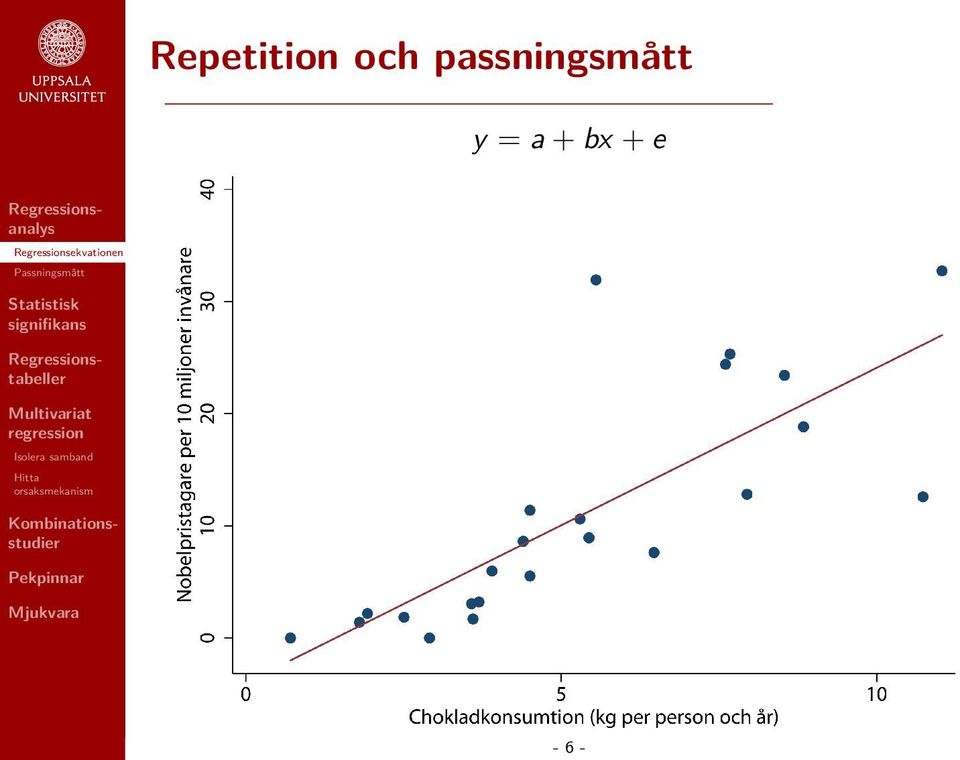
11 Repetition och passningsmått y = a + bx + e - 6 -
12 Repetition och passningsmått y = a + bx + e - 6 -
13 Repetition och passningsmått y = a + bx + e - 6 -
14 Repetition och passningsmått y = a + bx + e - 6 -
15 Repetition och passningsmått y = a + bx + e - 6 -
16 Repetition och passningsmått y = a + bx + e - 6 -
17 Repetition och passningsmått y = a + bx + e - 6 -

18 Repetition och passningsmått y = a + bx + e - 6 -

19 Repetition och passningsmått y = a + bx + e - 6 -
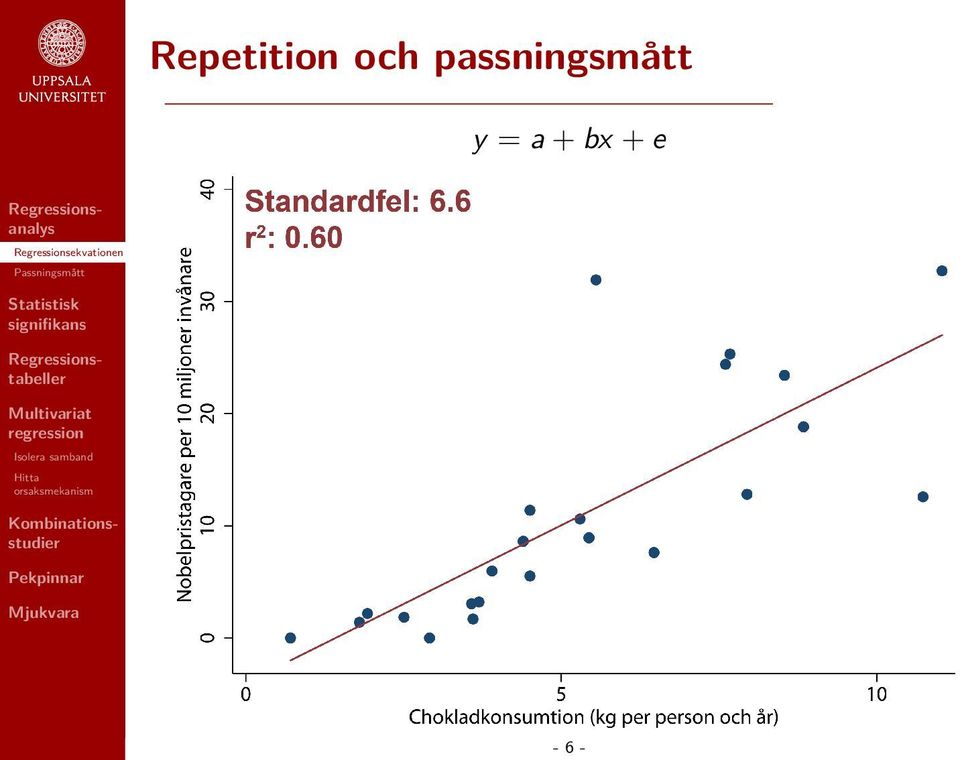
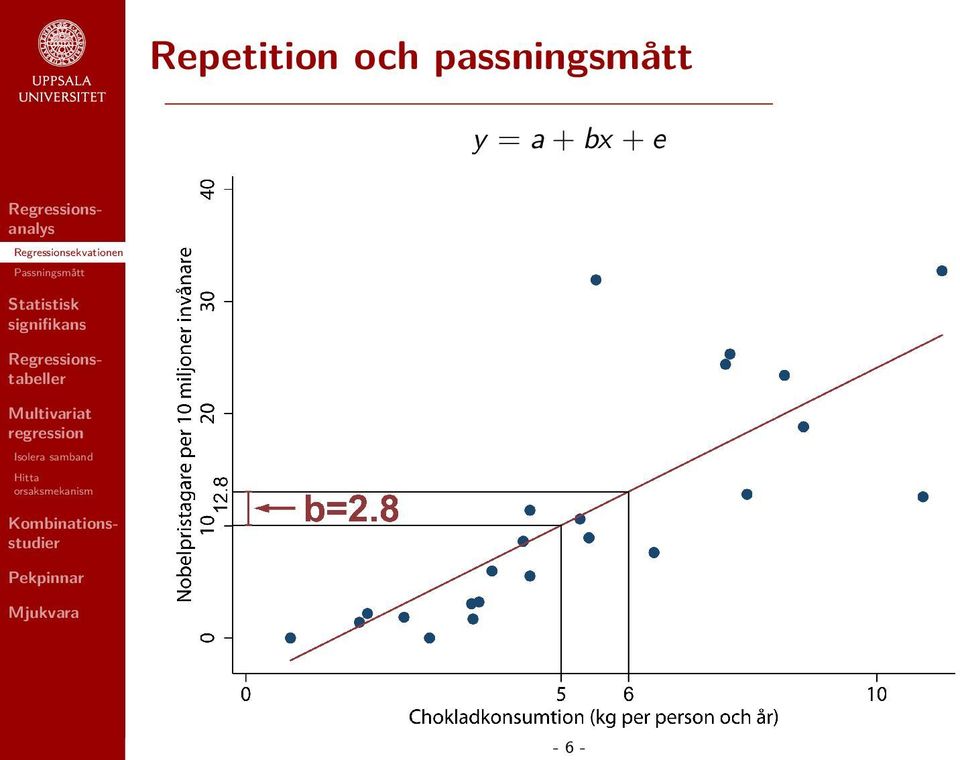
20 Repetition och passningsmått beskriver hur väl vår modell beskriver den data vi har observerat. De två viktigaste är ens standardfel och R 2. Båda passningsmåtten utgår ifrån storleken på residualerna, men sätter den i relation till olika saker

21 Repetition och passningsmått Regressionens standardfel ~Den genomsnittliga avvikelsen från slinjen. Uttrycks i samma enheter som den beroende variabeln. Exempel: De observerade värdena avviker i genomsnitt från modellens prediktioner med 6,6 Nobelpristagare per 10 milj. invånare
22 Repetition och passningsmått Regressionens standardfel ~Den genomsnittliga avvikelsen från slinjen. Uttrycks i samma enheter som den beroende variabeln. Exempel: De observerade värdena avviker i genomsnitt från modellens prediktioner med 6,6 Nobelpristagare per 10 milj. invånare. Överkurs Standardfel = RSS n 1 k = (e 2 (yi i ) n 1 k = ŷ i ) 2 n 1 k RSS = Summan av de kvadrerade feltermerna (Residual Sum of Squares) k = Antalet oberoende variabler - 8 -
23 Repetition och passningsmått R 2 Andelen förklarad variation i den beroende variabeln. Antar värden mellan 0 (vår modell förklarar ingenting) och 1 (vår modell förklarar 100 procent av variationen i den beroende variabeln). Exempel: Skillnader i chokladkonsumtion kan förklara 60 procent av variationen mellan länder i antalet Nobelpristagare
24 Repetition och passningsmått R 2 Andelen förklarad variation i den beroende variabeln. Antar värden mellan 0 (vår modell förklarar ingenting) och 1 (vår modell förklarar 100 procent av variationen i den beroende variabeln). Exempel: Skillnader i chokladkonsumtion kan förklara 60 procent av variationen mellan länder i antalet Nobelpristagare. Överkurs R 2 = 1 RSS TSS = 1 (yi ŷ i ) 2 (yi ȳ i ) 2 RSS = Summan av de kvadrerade feltermerna (Residual Sum of Squares) TSS = Summan av avvikelserna från medelvärdet (Total Sum of Squares) - 9 -
25 Repetition och passningsmått I grunden mäter båda måtten samma sak. Givet en viss variation i den beroende variabeln, så ökar R 2 när standardfelet sjunker, och vice versa. Om variationen i den beroende variabeln är stor, kan standardfelet vara stort trots lågt R 2, och vice versa
26 Repetition och passningsmått Litet standardfel, lågt R2 Stort standardfel, högt R2-11 -
27 Repetition och passningsmått Justerat R 2 När man adderar en variabel till en smodell kommer R 2 alltid att öka, även om den inte har något med den beroende variabeln att göra. För att korrigera för detta bör man i regel använda ett mått som kallas för justerat R 2 när man gör en multivariat. Det är vanligt (och ok för er) att även justerat R 2 uttrycks som andel av variationen i den beroende variabeln som modellen förklarar. Mer korrekt: justerat för antalet frihetsgrader
28 Repetition och passningsmått Allmänt om passningsmått Vad som är högt och lågt beror som alltid på vad vi har att jämföra med. Studenter har ofta orimligt höga förväntningar på vad våra modeller kan åstadkomma. Stirra er inte blinda på passningsmåtten. Vårt mål är sällan att göra de bästa prediktionerna. Vanligare att vi är intresserade av ett kausalt samband. Då är det viktigare hur stor effekten är samt huruvida den är statistiskt signifikant, alltså om samvariationen i vårt urval kan bero på slumpen
29 Korrelation är inte kausalitet I grunden finns det fyra olika skäl till att observera en samvariation mellan två variabler x och y. 1 Sambandet är kausalt, så att x har en effekt på y
30 Korrelation är inte kausalitet I grunden finns det fyra olika skäl till att observera en samvariation mellan två variabler x och y. 1 Sambandet är kausalt, så att x har en effekt på y. 2 Det observerade sambandet beror på en tillfällighet
31 Korrelation är inte kausalitet I grunden finns det fyra olika skäl till att observera en samvariation mellan två variabler x och y. 1 Sambandet är kausalt, så att x har en effekt på y. 2 Det observerade sambandet beror på en tillfällighet. 3 Omvänd orsaksriktning: det är y som påverkar x
32 Korrelation är inte kausalitet I grunden finns det fyra olika skäl till att observera en samvariation mellan två variabler x och y. 1 Sambandet är kausalt, så att x har en effekt på y. 2 Det observerade sambandet beror på en tillfällighet. 3 Omvänd orsaksriktning: det är y som påverkar x. 4 Sambandet är spuriöst och beror på att en tredje variabel påverkar både x och y
33 Korrelation är inte kausalitet I grunden finns det fyra olika skäl till att observera en samvariation mellan två variabler x och y. 1 Sambandet är kausalt, så att x har en effekt på y. 2 Det observerade sambandet beror på en tillfällighet. 3 Omvänd orsaksriktning: det är y som påverkar x. 4 Sambandet är spuriöst och beror på att en tredje variabel påverkar både x och y
34 Signifikans och generaliseringar Samma logik som när vi beräknade konfidensintervall runt proportioner. Kan vi generalisera resultaten till hela populationen? Kan sambandet bero på slumpen eller är den risken försumbar? I regel lika relevant vid totalundersökningar och oklara populationer
35 Signifikans och generaliseringar Som jag ser det handlar våra hypoteser om den process som har skapat den data vi observerar. Huruvida män tjänar mer än kvinnor i ett urval är inte lika intressant som huruvida skillnaden beror på slumpen eller på om det finns ett kausalt samband sådant att män i genomsnitt får högre lön. Inkomst = a + βkvinna
36 Signifikans och generaliseringar Vi använder β för populationens skoefficient för att skilja den från b som vi har använt för vår urvalskoefficient
37 Signifikans och generaliseringar Vi använder β för populationens skoefficient för att skilja den från b som vi har använt för vår urvalskoefficient. Om β är 0 finns det inget samband i populationen. Formellt kan vi ställa upp det såhär: H 0 : β = 0 (1) H 1 : β 0 (2)
38 Signifikans och generaliseringar Vi använder β för populationens skoefficient för att skilja den från b som vi har använt för vår urvalskoefficient. Om β är 0 finns det inget samband i populationen. Formellt kan vi ställa upp det såhär: H 0 : β = 0 (1) H 1 : β 0 (2) Vi kan aldrig observera β. Därför testar vi hypoteserna genom att beräkna konfidensintervall runt b
39 Signifikans och generaliseringar Vi använder β för populationens skoefficient för att skilja den från b som vi har använt för vår urvalskoefficient. Om β är 0 finns det inget samband i populationen. Formellt kan vi ställa upp det såhär: H 0 : β = 0 (1) H 1 : β 0 (2) Vi kan aldrig observera β. Därför testar vi hypoteserna genom att beräkna konfidensintervall runt b. Om konfidensintervallet inte täcker in 0 kan vi förkasta nollhypotesen. Vi vågar då dra slutsatsen att det finns ett samband även i populationen och vi kallar detta för att sambandet är statistiskt signifikant
40 Signifikans och generaliseringar Vi beräknar felmarginal och konfidensintervall på ungefär samma sätt som för proportioner. Konfidensintervall = b ± t kv se(b) (3)
41 Signifikans och generaliseringar Vi beräknar felmarginal och konfidensintervall på ungefär samma sätt som för proportioner. Konfidensintervall = b ± t kv se(b) (3) Statistikprogrammen beräknar ett testvärde (t-värde). t = b se(b) (4)
42 Signifikans och generaliseringar Vi beräknar felmarginal och konfidensintervall på ungefär samma sätt som för proportioner. Konfidensintervall = b ± t kv se(b) (3) Statistikprogrammen beräknar ett testvärde (t-värde). t = b se(b) (4) Detta t-värde anger vid vilket kritiskt värde som vårt samband upphör att vara signifikant (då den ena änden av konfidensintervallet tangerar 0)
43 Signifikans och generaliseringar Vi beräknar felmarginal och konfidensintervall på ungefär samma sätt som för proportioner. Konfidensintervall = b ± t kv se(b) (3) Statistikprogrammen beräknar ett testvärde (t-värde). t = b se(b) (4) Detta t-värde anger vid vilket kritiskt värde som vårt samband upphör att vara signifikant (då den ena änden av konfidensintervallet tangerar 0). Vid stora urval är det kritiska värdena t 90, t 95 och t 99 1,65, 1,96 och 2,58, precis som de z-värden vi tidigare använt, men vid små urval är de något större
44 Signifikans och generaliseringar Vi beräknar felmarginal och konfidensintervall på ungefär samma sätt som för proportioner. Konfidensintervall = b ± t kv se(b) (3) Statistikprogrammen beräknar ett testvärde (t-värde). t = b se(b) (4) Detta t-värde anger vid vilket kritiskt värde som vårt samband upphör att vara signifikant (då den ena änden av konfidensintervallet tangerar 0). Vid stora urval är det kritiska värdena t 90, t 95 och t 99 1,65, 1,96 och 2,58, precis som de z-värden vi tidigare använt, men vid små urval är de något större. Enkel tumregel: Sambandet är signifikant vid 95 procents säkerhetsnivå om skoefficienten är minst dubbelt så stor som dess standardavvikelse (t kv 2, 00)
45 Signifikans och generaliseringar
46 Signifikans och generaliseringar För att testa om ett resultat är signifikant kan vi därför jämföra detta t-värde med det kritiska värdet för den säkerhetsnivå vi har valt. Om testvärdet ligger utanför intervallet mellan t kv och t kv säger vi att sambandet är signifikant
47 Signifikans och generaliseringar För att testa om ett resultat är signifikant kan vi därför jämföra detta t-värde med det kritiska värdet för den säkerhetsnivå vi har valt. Om testvärdet ligger utanför intervallet mellan t kv och t kv säger vi att sambandet är signifikant. Vi ska göra det på tre exempel från förra föreläsningen:
48 Signifikans och generaliseringar För att testa om ett resultat är signifikant kan vi därför jämföra detta t-värde med det kritiska värdet för den säkerhetsnivå vi har valt. Om testvärdet ligger utanför intervallet mellan t kv och t kv säger vi att sambandet är signifikant. Vi ska göra det på tre exempel från förra föreläsningen: 1 Sambandet mellan placering på vänster-högerskalan och inställning till jämställdhet
49 Signifikans och generaliseringar För att testa om ett resultat är signifikant kan vi därför jämföra detta t-värde med det kritiska värdet för den säkerhetsnivå vi har valt. Om testvärdet ligger utanför intervallet mellan t kv och t kv säger vi att sambandet är signifikant. Vi ska göra det på tre exempel från förra föreläsningen: 1 Sambandet mellan placering på vänster-högerskalan och inställning till jämställdhet. 2 Sambandet mellan utbildning och inställning till EU
50 Signifikans och generaliseringar För att testa om ett resultat är signifikant kan vi därför jämföra detta t-värde med det kritiska värdet för den säkerhetsnivå vi har valt. Om testvärdet ligger utanför intervallet mellan t kv och t kv säger vi att sambandet är signifikant. Vi ska göra det på tre exempel från förra föreläsningen: 1 Sambandet mellan placering på vänster-högerskalan och inställning till jämställdhet. 2 Sambandet mellan utbildning och inställning till EU. 3 Sambandet mellan regeringssätt och korruption
51 Signifikans och generaliseringar Variabel Kön Utbildning Inkomst Vänster-högerskala Ökad jämställdhet Inställning till EU Regeringssätt Korruption Brittisk koloni Kodning 0 (man) eller 1 (kvinna) Antal år Månadslön i tusentals kr 0 (mkt långt t. höger) - 10 (mkt långt t. vänster) 0 (mycket litet behov) - 10 (mycket stort behov) 0 (mycket negativ) - 10 (mycket positiv) 0 (parlamentarism) eller 1 (presidentialism) 0 (ingen korruption) - 10 (mycket korruption) 1 (brittisk koloni) eller 0 (ej brittisk koloni) Tips: Döp gärna dikotoma variabler efter hur de är kodade. Kvinna, presidentialism och brittisk koloni har en underförstådd kodning medan kön, regeringssätt och kolonial bakgrund kan vara kodade hur som helst
52 Signifikans och generaliseringar Exempel 1: Placering på vänster höger-skalan och inställning till jämställdhet När vi genomför den bivariata sanalysen erhåller vi följande värden: b = 0,48 se(b) = 0,16 t = 3 (0,48/0,16)
53 Signifikans och generaliseringar Exempel 1: Placering på vänster höger-skalan och inställning till jämställdhet När vi genomför den bivariata sanalysen erhåller vi följande värden: b = 0,48 se(b) = 0,16 t = 3 (0,48/0,16) Det kritiska t-värdet på 95 procents säkerhetsnivå är här 1,96 (n=2000). Eftersom t-värdet ligger utanför det kritiska intervallet kan vi förkasta nollhypotesen (3 är större än 1,96)
54 Signifikans och generaliseringar Exempel 1: Placering på vänster höger-skalan och inställning till jämställdhet När vi genomför den bivariata sanalysen erhåller vi följande värden: b = 0,48 se(b) = 0,16 t = 3 (0,48/0,16) Det kritiska t-värdet på 95 procents säkerhetsnivå är här 1,96 (n=2000). Eftersom t-värdet ligger utanför det kritiska intervallet kan vi förkasta nollhypotesen (3 är större än 1,96). Effekten av ideologisk placering på inställningen till behovet av ökad jämställdhet mellan könen är således statistiskt signifikant på 95-procents säkerhetsnivå
55 Signifikans och generaliseringar Exempel 2: Utbildning och inställning till EU När vi genomför den bivariata sanalysen erhåller vi följande värden: b = 0,25, se(b) = 0,11 t = 2,27 (0,25/0,11)
56 Signifikans och generaliseringar Exempel 2: Utbildning och inställning till EU När vi genomför den bivariata sanalysen erhåller vi följande värden: b = 0,25, se(b) = 0,11 t = 2,27 (0,25/0,11) Det kritiska t-värdet på 95 procents säkerhetsnivå är här 1,96 (n=2000). Då t-värdet ligger utanför det kritiska intervallet kan vi förkasta nollhypotesen (2,27 är större än 1,96)
57 Signifikans och generaliseringar Exempel 2: Utbildning och inställning till EU När vi genomför den bivariata sanalysen erhåller vi följande värden: b = 0,25, se(b) = 0,11 t = 2,27 (0,25/0,11) Det kritiska t-värdet på 95 procents säkerhetsnivå är här 1,96 (n=2000). Då t-värdet ligger utanför det kritiska intervallet kan vi förkasta nollhypotesen (2,27 är större än 1,96). Det kritiska t-värdet på 95 procents säkerhetsnivå är här 2,58. Om vi höjer säkerhetsnivån till 99 procent är sambandet inte längre signifikant eftersom t-värdet då ligger inom det kritiska intervallet (2,27 < 2,58)
58 Signifikans och generaliseringar Exempel 3: Regeringssätt och korruption När vi genomför den bivariata sanalysen erhåller vi följande värden: b =-1,15 se(b) = 0,98 t = -1,17 (-1,15/0,98)
59 Signifikans och generaliseringar Exempel 3: Regeringssätt och korruption När vi genomför den bivariata sanalysen erhåller vi följande värden: b =-1,15 se(b) = 0,98 t = -1,17 (-1,15/0,98) Det kritiska t-värdet på 95 procents säkerhetsnivå är här 2,00 (n=60). Vi finner därmed att vi inte kan förkasta nollhypotesen att det inte finns något samband i populationen då t-värdet (-1,17) ligger inom det kritiska intervallet (-1,17 är större än -2 men mindre än 2)
60 Signifikans och generaliseringar Exempel 3: Regeringssätt och korruption När vi genomför den bivariata sanalysen erhåller vi följande värden: b =-1,15 se(b) = 0,98 t = -1,17 (-1,15/0,98) Det kritiska t-värdet på 95 procents säkerhetsnivå är här 2,00 (n=60). Vi finner därmed att vi inte kan förkasta nollhypotesen att det inte finns något samband i populationen då t-värdet (-1,17) ligger inom det kritiska intervallet (-1,17 är större än -2 men mindre än 2). Effekten av regeringssätt på korruptionsgraden är således inte statistisk signifikant
61 Signifikans och generaliseringar Fem ekvivalenta metoder. Sambandet är signifikant om: T-värdet är högre än det kritiska t-värdet
62 Signifikans och generaliseringar Fem ekvivalenta metoder. Sambandet är signifikant om: T-värdet är högre än det kritiska t-värdet. Regressionskoefficienten är mer än t kv gånger så stor som koefficientens standardfel. Givet approximationen t kv = 2, är det samma sak som att koefficienten är minst dubbelt så stor som dess standardfel
63 Signifikans och generaliseringar Fem ekvivalenta metoder. Sambandet är signifikant om: T-värdet är högre än det kritiska t-värdet. Regressionskoefficienten är mer än t kv gånger så stor som koefficientens standardfel. Givet approximationen t kv = 2, är det samma sak som att koefficienten är minst dubbelt så stor som dess standardfel. Konfidensintervallet runt koefficienten omsluter inte värdet
64 Signifikans och generaliseringar Fem ekvivalenta metoder. Sambandet är signifikant om: T-värdet är högre än det kritiska t-värdet. Regressionskoefficienten är mer än t kv gånger så stor som koefficientens standardfel. Givet approximationen t kv = 2, är det samma sak som att koefficienten är minst dubbelt så stor som dess standardfel. Konfidensintervallet runt koefficienten omsluter inte värdet 0. Det står asterisker efter efter skoefficienten. Läs under tabellen för att se vilken säkerhetsnivå de motsvarar. Det är den vanligaste metoden när man läser en stabell
65 Signifikans och generaliseringar Fem ekvivalenta metoder. Sambandet är signifikant om: T-värdet är högre än det kritiska t-värdet. Regressionskoefficienten är mer än t kv gånger så stor som koefficientens standardfel. Givet approximationen t kv = 2, är det samma sak som att koefficienten är minst dubbelt så stor som dess standardfel. Konfidensintervallet runt koefficienten omsluter inte värdet 0. Det står asterisker efter efter skoefficienten. Läs under tabellen för att se vilken säkerhetsnivå de motsvarar. Det är den vanligaste metoden när man läser en stabell. P-värdet är mindre än risknivån (risk = 1 - säkerhetsnivå). Det är den vanligaste metoden när man tolkar output från ett statistikprogram. Heter Significance i PSPP
66 Signifikans och generaliseringar Många signifikanta samband beror på slumpen Eftersom vi inte använder 100 procents säkerhetsnivå finns det alltid en risk att vi förkastar en sann nollhypotes
67 Signifikans och generaliseringar Många signifikanta samband beror på slumpen Eftersom vi inte använder 100 procents säkerhetsnivå finns det alltid en risk att vi förkastar en sann nollhypotes. Den risken ökar om vi planlöst letar efter signifikanta samband i stället för att styras av teoretiskt motiverade hypoteser
68 Signifikans och generaliseringar Exempel: sambandet mellan ostkonsumtion och hur många som årligen avlider efter att ha fastnat i lakanen. Antal dödsfall Kg ost per person och år
69 (1) (2) Choklad 2,81 2,28 (0,50) (0,64) BNP/capita 0,20 (0,16) Konstant 3,99 8,42 (3,00) (4,58) Observationer Standardfel 6,60 6,51 R 2 0,60 0,63 Standardfel i parenteser. p=10, p=05, p=01. En kolumn per smodell
70 (1) (2) Variabler Choklad 2,81 2,28 (0,50) (0,64) BNP/capita 0,20 (0,16) Konstant 3,99 8,42 (3,00) (4,58) Observationer Standardfel 6,60 6,51 R 2 0,60 0,63 Standardfel i parenteser. p=10, p=05, p=
71 (1) (2) Choklad 2,81 2,28 (0,50) (0,64) BNP/capita 0,20 (0,16) Konstant 3,99 8,42 (3,00) (4,58) Observationer Standardfel 6,60 6,51 R 2 0,60 0,63 Standardfel i parenteser. p=10, p=05, p=01. Regressionskoefficienter i den första en
72 (1) (2) Choklad 2,81 2,28 (0,50) (0,64) BNP/capita 0,20 (0,16) Konstant 3,99 8,42 (3,00) (4,58) Observationer Standardfel 6,60 6,51 R 2 0,60 0,63 Standardfel i parenteser. p=10, p=05, p=01. Intercept i den första en
73 (1) (2) Choklad 2,81 2,28 (0,50) (0,64) BNP/capita 0,20 (0,16) Konstant 3,99 8,42 (3,00) (4,58) Observationer Standardfel 6,60 6,51 R 2 0,60 0,63 Standardfel i parenteser. p=10, p=05, p=01. Regressionskoefficienter i den andra en
74 (1) (2) Choklad 2,81 2,28 (0,50) (0,64) BNP/capita 0,20 (0,16) Konstant 3,99 8,42 (3,00) (4,58) Observationer Standardfel 6,60 6,51 R 2 0,60 0,63 Standardfel i parenteser. p=10, p=05, p=01. Intercept i den andra en
75 (1) (2) Choklad 2,81 2,28 (0,50) (0,64) BNP/capita 0,20 (0,16) Konstant 3,99 8,42 (3,00) (4,58) Observationer Standardfel 6,60 6,51 R 2 0,60 0,63 Standardfel i parenteser. p=10, p=05, p=01. Koefficienternas standardfel
76 (1) (2) Choklad 2,81 2,28 (0,50) (0,64) BNP/capita 0,20 (0,16) Konstant 3,99 8,42 (3,00) (4,58) Observationer Standardfel 6,60 6,51 R 2 0,60 0,63 Standardfel i parenteser. p=10, p=05, p=01. i de båda erna
77 Hur gör man? Ni behöver inte kunna räkna ut några skoefficienter. Vi öppnar ett dataset och berättar för programmet vilken ekvation vi vill anpassa till vår data. Nu ska vi titta på Excel, Stata och PSPP
78 /V A RIA BLES= chocolate gdp /DEPEN DEN T= nobel Output /STA TISTICS=COEFF från PSPP R A N OV A. Model Summary R R S quare Adjuste d R S quare S td. Error of the Estimate A N OV A S um of S quare s df Me an S quare F S ignificance Re gre ssion Re sidual Total Coefficients B S td. Error Be ta t S ignificance (Constant) chocolate gdp
79 Fram tills nu har vi bara studerat samband mellan två variabler (bivariat ). innebär att vi har fler än två variabler. Det finns tre huvudsakliga skäl för att använda fler än en oberoende variabel: 1 Förbättra förklaringen 2 et
80 Kom ihåg orsakskriterierna! Samvariation (kontrafaktiska samband) har vi visat på redan i den bivariata analysen. Klarlägga tidsordning är inte de kvantitativa metodernas styrka (det finns emellertid mer avancerade smodeller som försöker göra detta). Men genom att addera fler variabler till modellen kan vi både isolera sambandet från alternativa förklaringar samt hitta variabler som fungerar som er
81 1 Förbättra förklaringen med fler variabler Få samhällsfenomen kan förklaras av en enda variabel. Såhär kan vi skriva en modell med två oberoende variabler: y = a + b 1 x 1 + b 2 x 2 + e (5) Om även x 2 har ett samband med y kommer vi med denna modell att kunna förklara en större del av variationen i y och göra bättre prediktioner. Avgörande för att förbättra passningen. Vi kan fortsätta att addera fler och fler variabler, men i regel väljer vi variabler som är viktiga för att isolera sambandet eller hitta en
82 2 et från bakomliggande variabler Att ett samband mellan två variabler är statistiskt signifikant betyder inte att det måste föreligga ett kausalt samband mellan variablerna. En annan möjlighet är att samvariationen mellan de två variablerna beror på en tredje, bakomliggande variabel som påverkar de båda. Exempelvis kanske vi kan tänka oss att rika länder både har råd med mycket choklad och lägger mycket pengar på spetsforskning. Det skulle i så fall kunna förklara varför länder med hög chokladkonsumtion har fått fler Nobelpris. Vi skulle då kalla det ursprungliga sambandet för spuriöst eller skenbart
83 Korrelation är inte kausalitet I grunden finns det fyra olika skäl till att observera en samvariation mellan två variabler x och y. 1 Sambandet är kausalt, så att x har en effekt på y. 2 Det observerade sambandet beror på en tillfällighet. 3 Omvänd orsaksriktning: det är y som påverkar x. 4 Sambandet är spuriöst och beror på att en tredje variabel påverkar både x och y
84 Korrelation är inte kausalitet I grunden finns det fyra olika skäl till att observera en samvariation mellan två variabler x och y. 1 Sambandet är kausalt, så att x har en effekt på y. 2 Det observerade sambandet beror på en tillfällighet. 3 Omvänd orsaksriktning: det är y som påverkar x. 4 Sambandet är spuriöst och beror på att en tredje variabel påverkar både x och y
85 Korrelation är inte kausalitet I grunden finns det fyra olika skäl till att observera en samvariation mellan två variabler x och y. 1 Sambandet är kausalt, så att x har en effekt på y. 2 Det observerade sambandet beror på en tillfällighet. 3 Omvänd orsaksriktning: det är y som påverkar x. 4 Sambandet är spuriöst och beror på att en tredje variabel påverkar både x och y
86 Ett bivariat samband... Choklad Nobelpris
87 ...som i själva verket är spuriöst? Choklad Nobelpris BNP per capita
88 Vad händer med det bivariata sambandet mellan ideologisk position och inställning till jämställdhet när vi kontrollerar för kön?
89 Beroende variabel: Inställning till jämställdhet (1) (2) Vänster-höger 0,48 0,03 (3,00) (0,78) Kön 1,78 (3,18) Konstant 2,97 5,14 Observationer t-värden i parenteser
90 Beroende variabel: Inställning till jämställdhet (1) (2) Vänster-höger 0,48 0,03 (3,00) (0,78) Kön 1,78 (3,18) Konstant 2,97 5,14 Observationer t-värden i parenteser. p < 0.10, p < 0.05, p <
91 Ett bivariat samband... Vänster höger 0.48 Jämställdhet
92 ...som var spuriöst. Vänster höger 0.03 Jämställdhet? 1.78 Kön
93 Beroende variabel: Placering på vänster höger-skalan (1) Kön 1,27 (2,94) Konstant 4,14 Observationer 2000 t-värden i parenteser
94 Vi kan nu ange effekten för varje orsakspil. Vänster höger 0.03 Jämställdhet Kön
95 Precis som i det bivariata fallet kan vi beräkna förväntade värden för multivariata sekvationer. Anta att ni blir tillfrågade om vilken inställning till jämställdhet ni tror att en kvinna med ideologisk placering 5 har. ŷ = a + b 1 x 1 + b 2 x 2 (5) Jamstalldhet = 5, , , 78 1 = 7, 07 (6) Om en effekt har visat sig vara insignifikant kan man inte bara utesluta den ur ekvationen. Antingen låter man den vara kvar (best guess) eller skattar man ett bivariat samband mellan de kvarvarande variablerna och använder dessa värden
96 Vad händer med det bivariata sambandet mellan utbildning och inställning till EU när vi kontrollerar för kön?
97 Beroende variabel: Inställning till EU (1) (2) Utbildning 0,25 0,24 (2,27) (2,28) Kön 0,85 ( 2,25) Konstant 2,02 2,14 Observationer t-värden i parenteser
98 Ett bivariat samband... Utbildning 0.25 Inställning EU
99 ...som kvarstår vid kontroll för kön. Utbildning 0.24 Inställning EU? 0.85 Kön
100 Vad händer med det bivariata sambandet mellan presidentialism (regeringssätt) och korruption när vi kontrollerar för om landet har varit en brittisk koloni?
101 Beroende variabel: Korruption (1) (2) Presidentialism 1,15 1,89 (0,98) (0,72) Brittisk koloni 1,10 ( 0,43) Konstant 7,18 8,10 Observationer Standardfel i parenteser
102 Ett bivariat samband... Presidentialism 1.15 Korruption
103 ...som förstärks när vi adderar en tredje variabel.. Presidentialism 1.89 Korruption? 1.10 Brittisk koloni
104 Kontrollvariabler som stärker sambandet kallas för suppressorvariabler. T&S skriver om detta på s
105 Kontrollvariabler som stärker sambandet kallas för suppressorvariabler. T&S skriver om detta på s Order suppressor kommer förmodligen från att variabeln trycker tillbaka eller konstanthåller en del av variationen i den huvudsakliga förklaringsvariabeln som har en motsatt eller svagare effekt på den beroende variabeln
106 Kontrollvariabler som stärker sambandet kallas för suppressorvariabler. T&S skriver om detta på s Order suppressor kommer förmodligen från att variabeln trycker tillbaka eller konstanthåller en del av variationen i den huvudsakliga förklaringsvariabeln som har en motsatt eller svagare effekt på den beroende variabeln. Tidigare brittiska kolonier har i regel parlamentariska system men har tack vare sin bakgrund andra institutioner som motverkar korruption. När vi kontrollerar för brittisk kolonialbakgrund försvinner denna del från sambandet mellan presidentialism och korruption
107 3 en En variabel som påverkas av den oberoende variabeln samt påverkar den beroende variabeln kallas för mellanliggande variabel
108 3 en En variabel som påverkas av den oberoende variabeln samt påverkar den beroende variabeln kallas för mellanliggande variabel. Den kan peka på hur eller varför den oberoende variabeln påverkar den beroende variabeln. Kallas därför ofta för
109 3 en En variabel som påverkas av den oberoende variabeln samt påverkar den beroende variabeln kallas för mellanliggande variabel. Den kan peka på hur eller varför den oberoende variabeln påverkar den beroende variabeln. Kallas därför ofta för. Det ursprungliga sambandet mellan den oberoende och beroende variabeln är fortfarande kausalt, men indirekt
110 3 en En variabel som påverkas av den oberoende variabeln samt påverkar den beroende variabeln kallas för mellanliggande variabel. Den kan peka på hur eller varför den oberoende variabeln påverkar den beroende variabeln. Kallas därför ofta för. Det ursprungliga sambandet mellan den oberoende och beroende variabeln är fortfarande kausalt, men indirekt. Att hitta mekanismer stärker trovärdigheten för våra resultat
111 Vad händer med det bivariata sambandet mellan kön och ideologisk position när vi adderar inkomst till modellen? Hint: Det är inte sannolikt att kön påverkas av en bakomliggande variabel. Vi är alltså inte ute efter att isolera sambandet, utan att hitta en. Varför står kvinnor till vänster om män?
112 Beroende variabel: Placering på vänster höger-skalan (1) (2) Kön 1,27 0,05 (2,94) ( 0,83) Inkomst 0,23 ( 4,27) Konstant 4,14 8,14 Observationer t-värden i parenteser
113 Ett bivariat samband... Kön 1.27 Vänster höger
114 ...som visar sig vara indirekt. Kön 0.05 Vänster höger? 0.23 Inkomst
115 Hur kan vi ta reda på styrkan i sambandet mellan kön och inkomst? Ett sätt är förstås att göra en bivariat analys med inkomst som beroende variabel och kön som oberoende. Den andra metoden är lite knepigare och inte nödvändigt för er att kunna, men bidrar förhoppningsvis till en djupare förståelse. Utgångspunkten är att systemet är slutet. Den totala effekten av kön på ideologisk placering består av den direkta effekten samt den del av sambandet som går via inkomst
116 Överkurs Total effekt = Direkt effekt + Indirekt effekt (7)
117 Överkurs Total effekt = Direkt effekt + Indirekt effekt (7) Den indirekta effekten är samma sak som effekten av kön på inkomst multiplicerat med effekten av inkomst på vänster höger-placering. Vi känner till allt förutom effekten av kön på inkomst (b). 1, 27 = 0, 05 + b 0, 23 (8)
118 Överkurs Total effekt = Direkt effekt + Indirekt effekt (7) Den indirekta effekten är samma sak som effekten av kön på inkomst multiplicerat med effekten av inkomst på vänster höger-placering. Vi känner till allt förutom effekten av kön på inkomst (b). 1, 27 = 0, 05 + b 0, 23 (8) Om vi adderar 0,05 till båda sidorna... 1, 32 = b 0, 23 (9)
119 Överkurs Total effekt = Direkt effekt + Indirekt effekt (7) Den indirekta effekten är samma sak som effekten av kön på inkomst multiplicerat med effekten av inkomst på vänster höger-placering. Vi känner till allt förutom effekten av kön på inkomst (b). 1, 27 = 0, 05 + b 0, 23 (8) Om vi adderar 0,05 till båda sidorna......och dividerar med -0,23 kan vi lösa ut b. 1, 32 = b 0, 23 (9) b = 5, 74 (10)
120 Vi kan nu ange effekten för samtliga orsakspilar. Kön 0.05 Vänster höger Inkomst
121 Vi fann tidigare att sambandet mellan utbildning och inställning till EU var signifikant även när vi kontrollerade för den bakomliggande variabeln kön. Men vad kan förklara att högutbildade är mer positiva till EU än högutbildade? Vi testar att lägga till inkomst respektive ideologisk position till modellen
122 Beroende variabel: Inställning till EU (1) (2) (3) Utbildning 0,25 0,20 0,08 (0,11) (0,10) (0,09) Inkomst 0,11 (0,06) Vänster-höger 1,14 ( 0,27) Konstant 2,02 2,14 8,14 Observationer Standardfel i parenteser
123 Ett bivariat samband... Utbildning 0.25 Inställning EU
124 Utbildning 0.20 Inställning EU Inkomst
125 Utbildning 0.08 Inställning EU Vänster höger
126 Om det ursprungliga sambandet är signifikant även efter att vi kontrollerat för en tredje variabel har vi isolerat sambandet (från den variabeln)
127 Om det ursprungliga sambandet är signifikant även efter att vi kontrollerat för en tredje variabel har vi isolerat sambandet (från den variabeln). Om det ursprungliga sambandet försvann eller försvagades efter att vi kontrollerat för en mellanliggande variabel var det indirekt. Vi har specificerat en och hypotesen får stöd
128 Om det ursprungliga sambandet är signifikant även efter att vi kontrollerat för en tredje variabel har vi isolerat sambandet (från den variabeln). Om det ursprungliga sambandet försvann eller försvagades efter att vi kontrollerat för en mellanliggande variabel var det indirekt. Vi har specificerat en och hypotesen får stöd. Om det ursprungliga sambandet försvann eller försvagades efter att vi kontrollerat för en bakomliggande variabel var det ett skensamband och spuriöst. Hypotesen får ej stöd
129 Om det ursprungliga sambandet är signifikant även efter att vi kontrollerat för en tredje variabel har vi isolerat sambandet (från den variabeln). Om det ursprungliga sambandet försvann eller försvagades efter att vi kontrollerat för en mellanliggande variabel var det indirekt. Vi har specificerat en och hypotesen får stöd. Om det ursprungliga sambandet försvann eller försvagades efter att vi kontrollerat för en bakomliggande variabel var det ett skensamband och spuriöst. Hypotesen får ej stöd. Om en variabel är bakomliggande eller mellanliggande, alltså orsaksriktningen på ett samband, är ofta svårare att avgöra än i dagens exempel
130 Idag har vi av pedagogiska skäl bara tittat på bivariata och trivariata er. I praktiken använder vi oftast fler variabler än så, men vi tolkar resultaten på samma sätt. Att ändra uppsättningen variabler mellan modeller är en vanlig metod, men det behöver inte ske en variabel i taget
131 Det förs ständigt en diskussionen om kvantitativa respektive kvalitativa metoders användningsområden och begränsningar
132 Det förs ständigt en diskussionen om kvantitativa respektive kvalitativa metoders användningsområden och begränsningar. De flesta är nog överens om att uppdelningen kvantare och kvallare är lite olycklig, särskilt som den leder till onödiga positioneringar och begränsar forskarens möjliga angreppssätt
133 Det förs ständigt en diskussionen om kvantitativa respektive kvalitativa metoders användningsområden och begränsningar. De flesta är nog överens om att uppdelningen kvantare och kvallare är lite olycklig, särskilt som den leder till onödiga positioneringar och begränsar forskarens möjliga angreppssätt. Många framhäver intensiva och extensiva studier som komplementära och kombinationen av dem är idag ett populärt ideal
134 Styrkor och svagheter i intensiva och extensiva studier Det är svårt att visa på samvariation och isolera orsakssamband i en intensiv studie. Men i gengäld kan det i dessa studier ofta vara enklare att finna belägg för tidsordning och
135 Styrkor och svagheter i intensiva och extensiva studier Det är svårt att visa på samvariation och isolera orsakssamband i en intensiv studie. Men i gengäld kan det i dessa studier ofta vara enklare att finna belägg för tidsordning och. - På motsatt vis är extensiva studier bra på samvariation och isolering men brister ofta i att belägga tidsordning och spåra er
136 Kontrafaktisk skillnad och isolering Method of Agreement innebär att vi väljer fall som har samma (likartade) utfall på den beroende variabeln men är så olika som möjligt i alla andra relevanta avseenden. Fortfarande inget belägg för kontrafaktisk skillnad!
137 Kontrafaktisk skillnad och isolering Method of Agreement innebär att vi väljer fall som har samma (likartade) utfall på den beroende variabeln men är så olika som möjligt i alla andra relevanta avseenden. Fortfarande inget belägg för kontrafaktisk skillnad! Endast i Method of Difference har vi belägg för kontrafaktisk skillnad, men de intensiva metodernas akilleshäl kvarstår: Vi vet fortfarande inte om sambandet är systematiskt eller slumpartat
138 Kontrafaktisk skillnad och isolering Method of Agreement innebär att vi väljer fall som har samma (likartade) utfall på den beroende variabeln men är så olika som möjligt i alla andra relevanta avseenden. Fortfarande inget belägg för kontrafaktisk skillnad! Endast i Method of Difference har vi belägg för kontrafaktisk skillnad, men de intensiva metodernas akilleshäl kvarstår: Vi vet fortfarande inte om sambandet är systematiskt eller slumpartat. Extensiva upplägg är därför bättre på att ge belägg för samvariation eller kontrafaktisk skillnad samt isolera andra förklaringar. De har också fördelen att de kan hantera probabilistiska samband bättre än fåfallsstudier (se Teorell & Svensson s.241)
139 Tidsordning och Hela dagen har vi gjort antaganden om orsaksriktningar. Det brukar vara mer problematiskt än vad det har varit i våra exempel
140 Tidsordning och Hela dagen har vi gjort antaganden om orsaksriktningar. Det brukar vara mer problematiskt än vad det har varit i våra exempel. De kvantitativa metoder som finns för att belägga orsaksriktning kräver bra data med tidsvariation samt ofta andra antaganden, exempelvis om effektens fördröjning
141 Tidsordning och Hela dagen har vi gjort antaganden om orsaksriktningar. Det brukar vara mer problematiskt än vad det har varit i våra exempel. De kvantitativa metoder som finns för att belägga orsaksriktning kräver bra data med tidsvariation samt ofta andra antaganden, exempelvis om effektens fördröjning. Även om extensiva studier kan visa på en kan de inte följa en process lika nära som en intensiv studie kan göra
142 Tidsordning och Hela dagen har vi gjort antaganden om orsaksriktningar. Det brukar vara mer problematiskt än vad det har varit i våra exempel. De kvantitativa metoder som finns för att belägga orsaksriktning kräver bra data med tidsvariation samt ofta andra antaganden, exempelvis om effektens fördröjning. Även om extensiva studier kan visa på en kan de inte följa en process lika nära som en intensiv studie kan göra. Utöver detta fyller intensiva studier även viktiga teoriutvecklande eller hypotesgenererande funktioner
143 : Det bästa av två världar? Vill vi hitta belägg för alla orsakskriterier bör vi således kombinera extensiva och intensiva ansatser. De är komplementära snarare än att stå i konflikt med varandra. Allt behöver inte göras i samma studie eller av samma forskare!
144 De vanligaste ansatserna är förmodligen att att välja fall på basis av en extensiv studie
145 De vanligaste ansatserna är förmodligen att att välja fall på basis av en extensiv studie. Om syftet är att belägga orsaksriktning och/eller bör vi välja fall som passar in i huvudmönstret, det vill säga som är representativa för det samband som vi har funnit
146 De vanligaste ansatserna är förmodligen att att välja fall på basis av en extensiv studie. Om syftet är att belägga orsaksriktning och/eller bör vi välja fall som passar in i huvudmönstret, det vill säga som är representativa för det samband som vi har funnit. En annan möjlighet är att använda den intensiva studien till att generera nya (konkurrerande eller komplemetterande) hypoteser om vad som kan förklara ett visst fenomen. Vi väljer då länder som ligger långt ifrån slinjen
147 Typiska fall Fall som är representativa med avseende på ett givet samband. Små residualer. Ligger på linjen
148 Typiska fall Fall som är representativa med avseende på ett givet samband. Små residualer. Ligger på linjen. Behöver inte vara representativa i de enskilda variablerna (kan ha extrema värden på de oberoende eller beroende variablerna)
149 Typiska fall Fall som är representativa med avseende på ett givet samband. Små residualer. Ligger på linjen. Behöver inte vara representativa i de enskilda variablerna (kan ha extrema värden på de oberoende eller beroende variablerna). Hypotesprövande. Utforska kausala mekanismer. Utesluta omvänd orsaksriktning och spuriösa samband
150 Typiska fall Fall som är representativa med avseende på ett givet samband. Små residualer. Ligger på linjen. Behöver inte vara representativa i de enskilda variablerna (kan ha extrema värden på de oberoende eller beroende variablerna). Hypotesprövande. Utforska kausala mekanismer. Utesluta omvänd orsaksriktning och spuriösa samband. Kallas även illustrativa fall eftersom de kan ge en djupare eller mer konkret förståelse för ett samband
151 Typiska fall Fall som är representativa med avseende på ett givet samband. Små residualer. Ligger på linjen. Behöver inte vara representativa i de enskilda variablerna (kan ha extrema värden på de oberoende eller beroende variablerna). Hypotesprövande. Utforska kausala mekanismer. Utesluta omvänd orsaksriktning och spuriösa samband. Kallas även illustrativa fall eftersom de kan ge en djupare eller mer konkret förståelse för ett samband. Ibland används begreppet även om det vi har kallat för representativa fall. Då skiljer man på typiskt för en univariat fördelning eller typiskt för ett samband
152 Avvikande fall Avviker från vad vi skulle förvänta oss utifrån ett visst samband. Förklaras inte av modellen
153 Avvikande fall Avviker från vad vi skulle förvänta oss utifrån ett visst samband. Förklaras inte av modellen. Stora residualer. Långt ifrån slinjen
154 Avvikande fall Avviker från vad vi skulle förvänta oss utifrån ett visst samband. Förklaras inte av modellen. Stora residualer. Långt ifrån slinjen. Hypotesgenererande. Letar efter variabler som förklarar det avvikande fallet. Dessa förklaringar ska helst kunna appliceras även på andra fall
155 Avvikande fall Avviker från vad vi skulle förvänta oss utifrån ett visst samband. Förklaras inte av modellen. Stora residualer. Långt ifrån slinjen. Hypotesgenererande. Letar efter variabler som förklarar det avvikande fallet. Dessa förklaringar ska helst kunna appliceras även på andra fall. r vi nya möjliga förklaringar kan vi addera dem till våra modeller och göra nya sanalyser där fallen förhoppningsvis ligger närmare linjen
156 - 58 -
157 - 58 -
158 - 58 -
159 Några saker att vara uppmärksam på Det är svårt att jämföra koefficienter Variabler är ofta mätta på olika skalor
160 Några saker att vara uppmärksam på Det är svårt att jämföra koefficienter Variabler är ofta mätta på olika skalor. Även om de är mätta på samma skala, kan spridningen skilja sig åt
161 Några saker att vara uppmärksam på Det är svårt att jämföra koefficienter Variabler är ofta mätta på olika skalor. Även om de är mätta på samma skala, kan spridningen skilja sig åt. Oavsett skala och spridning är det aldrig okomplicerat att jämföra effekter av vitt skilda saker
162 Några saker att vara uppmärksam på Det är svårt att jämföra koefficienter Variabler är ofta mätta på olika skalor. Även om de är mätta på samma skala, kan spridningen skilja sig åt. Oavsett skala och spridning är det aldrig okomplicerat att jämföra effekter av vitt skilda saker. Det betyder inte att vi ska låta bli att jämföra!
163 Några saker att vara uppmärksam på en testar inte orsaksriktningen Inom samhällsvetenskapen är det ofta långt ifrån självklart i vilken riktning som ett samband går
164 Några saker att vara uppmärksam på en testar inte orsaksriktningen Inom samhällsvetenskapen är det ofta långt ifrån självklart i vilken riktning som ett samband går. När vi gör våra er antar vi en orsaksriktning, men att sambandet är signifikant betyder inte att antagandet var korrekt
165 Några saker att vara uppmärksam på en testar inte orsaksriktningen Inom samhällsvetenskapen är det ofta långt ifrån självklart i vilken riktning som ett samband går. När vi gör våra er antar vi en orsaksriktning, men att sambandet är signifikant betyder inte att antagandet var korrekt. Fallstudier, teoretiska resonemang och experiment kan hjälpa oss att reda ut orsaksriktningen
166 Några saker att vara uppmärksam på Har vi observationer från olika tidpunkter? När vi använder data från olika tidpunkter skapar det både möjligheter och problem
167 Några saker att vara uppmärksam på Har vi observationer från olika tidpunkter? När vi använder data från olika tidpunkter skapar det både möjligheter och problem. Å ena sidan ger det oss vissa möjligheter att studera orsaksriktningen (vad kommer först?)
168 Några saker att vara uppmärksam på Har vi observationer från olika tidpunkter? När vi använder data från olika tidpunkter skapar det både möjligheter och problem. Å ena sidan ger det oss vissa möjligheter att studera orsaksriktningen (vad kommer först?). Vi kan också välja att endast studera variation över tid (t.ex. genom en dummyvariabel per land)
169 Några saker att vara uppmärksam på Har vi observationer från olika tidpunkter? När vi använder data från olika tidpunkter skapar det både möjligheter och problem. Å ena sidan ger det oss vissa möjligheter att studera orsaksriktningen (vad kommer först?). Vi kan också välja att endast studera variation över tid (t.ex. genom en dummyvariabel per land). Å andra sidan framstår icke-signifikanta samband ofta som signifikanta om vi inte tar hänsyn till att Sverige 2012 och Sverige 2011 knappast är oberoende av varandra
170 Några saker att vara uppmärksam på Är den beroende variabeln dikotom? Vanlig linjär är dåligt lämpad för variabler som bara kan anta värdena 0 eller
171 Några saker att vara uppmärksam på Är den beroende variabeln dikotom? Vanlig linjär är dåligt lämpad för variabler som bara kan anta värdena 0 eller 1. Kan ge orimliga prediktioner (ŷ < 0 eller ŷ > 1) samt bryter mot en del andra antaganden (t.ex. homoskedasticitet)
172 Några saker att vara uppmärksam på Är den beroende variabeln dikotom? Vanlig linjär är dåligt lämpad för variabler som bara kan anta värdena 0 eller 1. Kan ge orimliga prediktioner (ŷ < 0 eller ŷ > 1) samt bryter mot en del andra antaganden (t.ex. homoskedasticitet). Det vanligaste sättet att hantera detta är genom logistisk
173 Några saker att vara uppmärksam på Det är svårt att isolera för alla tänkbara förklaringar Vi vet inte vilka alla de möjliga bakomliggande förklaringarna är
174 Några saker att vara uppmärksam på Det är svårt att isolera för alla tänkbara förklaringar Vi vet inte vilka alla de möjliga bakomliggande förklaringarna är. Även om vi visste det, är det inte självklart hur vi ska mäta dem eller att det är praktiskt möjligt
175 Några saker att vara uppmärksam på Det är svårt att isolera för alla tänkbara förklaringar Vi vet inte vilka alla de möjliga bakomliggande förklaringarna är. Även om vi visste det, är det inte självklart hur vi ska mäta dem eller att det är praktiskt möjligt. Även om vi kände till och kunde mäta alla bakomliggande variabler, vet vi inte hur vi ska kontrollera för dem. Den linjära och additiva sekvationen är bara en möjlighet
176 De flesta på institutionen använder Stata. Det är stort i forskarvärlden men inte lika vanligt utanför akademin
177 De flesta på institutionen använder Stata. Det är stort i forskarvärlden men inte lika vanligt utanför akademin. R är ett avancerat gratisprogram som växer snabbt
178 De flesta på institutionen använder Stata. Det är stort i forskarvärlden men inte lika vanligt utanför akademin. R är ett avancerat gratisprogram som växer snabbt. Vi tror att SPSS är det vanligaste programmet på svenska myndigheter
179 De flesta på institutionen använder Stata. Det är stort i forskarvärlden men inte lika vanligt utanför akademin. R är ett avancerat gratisprogram som växer snabbt. Vi tror att SPSS är det vanligaste programmet på svenska myndigheter. På kursen använder vi PSPP. Det påminner mycket om SPSS, men är lite mer begränsat
Föreläsning 7 och 8: Regressionsanalys
 Föreläsning 7 och 8: Pär Nyman par.nyman@statsvet.uu.se 3 februari 2014-1 - Vårt viktigaste verktyg för kvantitativa studier. Kan användas till det mesta, men svarar oftast på frågor om kausala samband.
Föreläsning 7 och 8: Pär Nyman par.nyman@statsvet.uu.se 3 februari 2014-1 - Vårt viktigaste verktyg för kvantitativa studier. Kan användas till det mesta, men svarar oftast på frågor om kausala samband.
Föreläsning 8 och 9: Regressionsanalys
 Föreläsning 8 och 9: Pär Nyman par.nyman@statsvet.uu.se 1 februari 2016-1 - Vårt viktigaste verktyg för kvantitativa studier. Kan användas till det mesta, men svarar oftast på frågor om kausala samband.
Föreläsning 8 och 9: Pär Nyman par.nyman@statsvet.uu.se 1 februari 2016-1 - Vårt viktigaste verktyg för kvantitativa studier. Kan användas till det mesta, men svarar oftast på frågor om kausala samband.
Föreläsning 7 och 8: Regressionsanalys
 Föreläsning 7 och 8: Regressionsanalys Pär Nyman 12 september 2014 Det här är anteckningar till föreläsning 7 och 8. Båda föreläsningarna handlar om regressionsanalys, så jag slog ihop dem till ett gemensamt
Föreläsning 7 och 8: Regressionsanalys Pär Nyman 12 september 2014 Det här är anteckningar till föreläsning 7 och 8. Båda föreläsningarna handlar om regressionsanalys, så jag slog ihop dem till ett gemensamt
Föreläsning 7 och 8: Regressionsanalys
 Föreläsning 7 och 8: Regressionsanalys Pär Nyman 3 februari 2014 Det här är anteckningar till föreläsning 7 och 8. Båda föreläsningarna handlar om regressionsanalys, så jag slog ihop dem till ett gemensamt
Föreläsning 7 och 8: Regressionsanalys Pär Nyman 3 februari 2014 Det här är anteckningar till föreläsning 7 och 8. Båda föreläsningarna handlar om regressionsanalys, så jag slog ihop dem till ett gemensamt
Linjär regressionsanalys. Wieland Wermke
 + Linjär regressionsanalys Wieland Wermke + Regressionsanalys n Analys av samband mellan variabler (x,y) n Ökad kunskap om x (oberoende variabel) leder till ökad kunskap om y (beroende variabel) n Utifrån
+ Linjär regressionsanalys Wieland Wermke + Regressionsanalys n Analys av samband mellan variabler (x,y) n Ökad kunskap om x (oberoende variabel) leder till ökad kunskap om y (beroende variabel) n Utifrån
Föreläsning 8 och 9: Regressionsanalys
 Föreläsning 8 och 9: Regressionsanalys Pär Nyman 14 september 2015 Det här är anteckningar till föreläsning 8 och 9. Båda föreläsningarna handlar om regressionsanalys, så jag slog ihop dem till ett gemensamt
Föreläsning 8 och 9: Regressionsanalys Pär Nyman 14 september 2015 Det här är anteckningar till föreläsning 8 och 9. Båda föreläsningarna handlar om regressionsanalys, så jag slog ihop dem till ett gemensamt
Statistik och epidemiologi T5
 Statistik och epidemiologi T5 Anna Axmon Biostatistiker Yrkes- och miljömedicin Dagens föreläsning Fördjupning av hypotesprövning Repetition av p-värde och konfidensintervall Tester för ytterligare situationer
Statistik och epidemiologi T5 Anna Axmon Biostatistiker Yrkes- och miljömedicin Dagens föreläsning Fördjupning av hypotesprövning Repetition av p-värde och konfidensintervall Tester för ytterligare situationer
Uppgift 1. Deskripitiv statistik. Lön
 Uppgift 1 Deskripitiv statistik Lön Variabeln Lön är en kvotvariabel, även om vi knappast kommer att uppleva några negativa värden. Det är sannolikt vår intressantaste variabel i undersökningen, och mot
Uppgift 1 Deskripitiv statistik Lön Variabeln Lön är en kvotvariabel, även om vi knappast kommer att uppleva några negativa värden. Det är sannolikt vår intressantaste variabel i undersökningen, och mot
Multipel regression och Partiella korrelationer
 Multipel regression och Partiella korrelationer Joakim Westerlund Kom ihåg bakomliggande variabelproblemet: Temperatur Jackförsäljning Oljeförbrukning Bakomliggande variabelproblemet kan, som tidigare
Multipel regression och Partiella korrelationer Joakim Westerlund Kom ihåg bakomliggande variabelproblemet: Temperatur Jackförsäljning Oljeförbrukning Bakomliggande variabelproblemet kan, som tidigare
Statistiska analyser C2 Inferensstatistik. Wieland Wermke
 + Statistiska analyser C2 Inferensstatistik Wieland Wermke + Signifikans och Normalfördelning + Problemet med generaliseringen: inferensstatistik n Om vi vill veta ngt. om en population, då kan vi ju fråga
+ Statistiska analyser C2 Inferensstatistik Wieland Wermke + Signifikans och Normalfördelning + Problemet med generaliseringen: inferensstatistik n Om vi vill veta ngt. om en population, då kan vi ju fråga
Tentamen Metod C vid Uppsala universitet, , kl
 Tentamen Metod C vid Uppsala universitet, 170503, kl. 08.00-12.00 Anvisningar Av rättningspraktiska skäl skall var och en av de tre huvudfrågorna besvaras på separata pappersark. Börja alltså på ett nytt
Tentamen Metod C vid Uppsala universitet, 170503, kl. 08.00-12.00 Anvisningar Av rättningspraktiska skäl skall var och en av de tre huvudfrågorna besvaras på separata pappersark. Börja alltså på ett nytt
TENTAMEN KVANTITATIV METOD (100205)
") ÖREBRO UNIVERSITET Hälsoakademin Idrott B, Vetenskaplig metod TENTAMEN KVANTITATIV METOD (205) Examinationen består av 11 frågor, några med tillhörande följdfrågor. Besvara alla frågor i direkt anslutning
ÖREBRO UNIVERSITET Hälsoakademin Idrott B, Vetenskaplig metod TENTAMEN KVANTITATIV METOD (205) Examinationen består av 11 frågor, några med tillhörande följdfrågor. Besvara alla frågor i direkt anslutning
Statistiska analysmetoder, en introduktion. Fördjupad forskningsmetodik, allmän del Våren 2018
 Statistiska analysmetoder, en introduktion Fördjupad forskningsmetodik, allmän del Våren 2018 Vad är statistisk dataanalys? Analys och tolkning av kvantitativa data -> förutsätter numeriskt datamaterial
Statistiska analysmetoder, en introduktion Fördjupad forskningsmetodik, allmän del Våren 2018 Vad är statistisk dataanalys? Analys och tolkning av kvantitativa data -> förutsätter numeriskt datamaterial
Tentamen i Statistik, STA A10 och STA A13 (9 poäng) Onsdag 1 november 2006, Kl 08.15-13.15
 Onsdag 1 november 2006, Kl 08.15-13.15") Tentamen i Statistik, STA A och STA A13 (9 poäng) Onsdag 1 november 00, Kl 0.15-13.15 Tillåtna hjälpmedel: Bifogad formelsamling, approximationsschema och tabellsamling (dessa skall returneras). Egen miniräknare.
Tentamen i Statistik, STA A och STA A13 (9 poäng) Onsdag 1 november 00, Kl 0.15-13.15 Tillåtna hjälpmedel: Bifogad formelsamling, approximationsschema och tabellsamling (dessa skall returneras). Egen miniräknare.
Finansiell Statistik (GN, 7,5 hp,, HT 2008) Föreläsning 7. Multipel regression. (LLL Kap 15) Multipel Regressionsmodellen
 Föreläsning 7. Multipel regression. (LLL Kap 15) Multipel Regressionsmodellen") Finansiell Statistik (GN, 7,5 hp,, HT 8) Föreläsning 7 Multipel regression (LLL Kap 5) Department of Statistics (Gebrenegus Ghilagaber, PhD, Associate Professor) Financial Statistics (Basic-level course,
Finansiell Statistik (GN, 7,5 hp,, HT 8) Föreläsning 7 Multipel regression (LLL Kap 5) Department of Statistics (Gebrenegus Ghilagaber, PhD, Associate Professor) Financial Statistics (Basic-level course,
T-test, Korrelation och Konfidensintervall med SPSS Kimmo Sorjonen
 T-test, Korrelation och Konfidensintervall med SPSS Kimmo Sorjonen 1. One-Sample T-Test 1.1 När? Denna analys kan utföras om man vill ta reda på om en populations medelvärde på en viss variabel kan antas
T-test, Korrelation och Konfidensintervall med SPSS Kimmo Sorjonen 1. One-Sample T-Test 1.1 När? Denna analys kan utföras om man vill ta reda på om en populations medelvärde på en viss variabel kan antas
Multipel Regressionsmodellen
 Multipel Regressionsmodellen Koefficienterna i multipel regression skattas från ett stickprov enligt: Multipel Regressionsmodell med k förklarande variabler: Skattad (predicerad) Värde på y y ˆ = b + b
Multipel Regressionsmodellen Koefficienterna i multipel regression skattas från ett stickprov enligt: Multipel Regressionsmodell med k förklarande variabler: Skattad (predicerad) Värde på y y ˆ = b + b
Tentamen i Statistik, STA A13 Deltentamen 2, 5p 24 januari 2004, kl. 09.00-13.00
 Karlstads universitet Institutionen för informationsteknologi Avdelningen för statistik Tentamen i Statistik, STA A13 Deltentamen, 5p 4 januari 004, kl. 09.00-13.00 Tillåtna hjälpmedel: Ansvarig lärare:
Karlstads universitet Institutionen för informationsteknologi Avdelningen för statistik Tentamen i Statistik, STA A13 Deltentamen, 5p 4 januari 004, kl. 09.00-13.00 Tillåtna hjälpmedel: Ansvarig lärare:
Tillämpad statistik (A5), HT15 Föreläsning 10: Multipel linjär regression 1
, HT15 Föreläsning 10: Multipel linjär regression 1") Tillämpad statistik (A5), HT15 Föreläsning 10: Multipel linjär regression 1 Ronnie Pingel Statistiska institutionen Senast uppdaterad: 2015-11-19 Motivering Vi motiverade enkel linjär regression som ett
Tillämpad statistik (A5), HT15 Föreläsning 10: Multipel linjär regression 1 Ronnie Pingel Statistiska institutionen Senast uppdaterad: 2015-11-19 Motivering Vi motiverade enkel linjär regression som ett
F19, (Multipel linjär regression forts) och F20, Chi-två test.
 och F20, Chi-två test.") Partiella t-test F19, (Multipel linjär regression forts) och F20, Chi-två test. Christian Tallberg Statistiska institutionen Stockholms universitet Då man testar om en enskild variabel X i skall vara med
Partiella t-test F19, (Multipel linjär regression forts) och F20, Chi-två test. Christian Tallberg Statistiska institutionen Stockholms universitet Då man testar om en enskild variabel X i skall vara med
Dekomponering av löneskillnader
 Lönebildningsrapporten 2013 133 FÖRDJUPNING Dekomponering av löneskillnader Den här fördjupningen ger en detaljerad beskrivning av dekomponeringen av skillnader i genomsnittlig lön. Först beskrivs metoden
Lönebildningsrapporten 2013 133 FÖRDJUPNING Dekomponering av löneskillnader Den här fördjupningen ger en detaljerad beskrivning av dekomponeringen av skillnader i genomsnittlig lön. Först beskrivs metoden
Datorlaboration 2 Konfidensintervall & hypotesprövning
 Statistik, 2p PROTOKOLL Namn:...... Grupp:... Datum:... Datorlaboration 2 Konfidensintervall & hypotesprövning Syftet med denna laboration är att ni med hjälp av MS Excel ska fortsätta den statistiska
Statistik, 2p PROTOKOLL Namn:...... Grupp:... Datum:... Datorlaboration 2 Konfidensintervall & hypotesprövning Syftet med denna laboration är att ni med hjälp av MS Excel ska fortsätta den statistiska
34% 34% 13.5% 68% 13.5% 2.35% 95% 2.35% 0.15% 99.7% 0.15% -3 SD -2 SD -1 SD M +1 SD +2 SD +3 SD
 6.4 Att dra slutsatser på basis av statistisk analys en kort inledning - Man har ett stickprov, men man vill med hjälp av det få veta något om hela populationen => för att kunna dra slutsatser som gäller
6.4 Att dra slutsatser på basis av statistisk analys en kort inledning - Man har ett stickprov, men man vill med hjälp av det få veta något om hela populationen => för att kunna dra slutsatser som gäller
a) Vad är sannolikheten att det tar mer än 6 sekunder för programmet att starta?
 Vad är sannolikheten att det tar mer än 6 sekunder för programmet att starta?") Tentamen i Matematisk statistik, S0001M, del 1, 2008-01-18 1. Ett företag som köper enheter från en underleverantör vet av erfarenhet att en viss andel av enheterna kommer att vara felaktiga. Sannolikheten
Tentamen i Matematisk statistik, S0001M, del 1, 2008-01-18 1. Ett företag som köper enheter från en underleverantör vet av erfarenhet att en viss andel av enheterna kommer att vara felaktiga. Sannolikheten
Kapitel 12: TEST GÄLLANDE EN GRUPP KOEFFICIENTER - ANOVA
 Kapitel 12: TEST GÄLLANDE EN GRUPP KOEFFICIENTER - ANOVA 12.1 ANOVA I EN MULTIPEL REGRESSION Exempel: Tjänar man mer som egenföretagare? Nedan visas ett utdrag ur ett dataset som innehåller information
Kapitel 12: TEST GÄLLANDE EN GRUPP KOEFFICIENTER - ANOVA 12.1 ANOVA I EN MULTIPEL REGRESSION Exempel: Tjänar man mer som egenföretagare? Nedan visas ett utdrag ur ett dataset som innehåller information
Tentamen STA A10 och STA A13, 9 poäng 19 januari 2006, kl. 8.15-13.15
 Tentamen STA A10 och STA A13, 9 poäng 19 januari 2006, kl. 8.15-13.15 Tillåtna hjälpmedel: Ansvarig lärare: Räknedosa, bifogade formel- och tabellsamlingar, vilka skall returneras. Christian Tallberg Telnr:
Tentamen STA A10 och STA A13, 9 poäng 19 januari 2006, kl. 8.15-13.15 Tillåtna hjälpmedel: Ansvarig lärare: Räknedosa, bifogade formel- och tabellsamlingar, vilka skall returneras. Christian Tallberg Telnr:
KA RKUNSKAP. Vad vet samhällsvetarna om sin kår? Julius Schmidt, Hannes Jägerstedt, Hanna Johansson, Miro Beríc STAA31 HT14
 KA RKUNSKAP Julius Schmidt, Hannes Jägerstedt, Hanna Johansson, Miro Beríc Vad vet samhällsvetarna om sin kår? STAA31 HT14 Handledare: Peter Gustafsson Ekonomihögskolan, Statistiska institutionen Innehållsförteckning
KA RKUNSKAP Julius Schmidt, Hannes Jägerstedt, Hanna Johansson, Miro Beríc Vad vet samhällsvetarna om sin kår? STAA31 HT14 Handledare: Peter Gustafsson Ekonomihögskolan, Statistiska institutionen Innehållsförteckning
Lösningar till SPSS-övning: Analytisk statistik
 UMEÅ UNIVERSITET Statistiska institutionen 2006--28 Lösningar till SPSS-övning: Analytisk statistik Test av skillnad i medelvärden mellan två grupper Uppgift Testa om det är någon skillnad i medelvikt
UMEÅ UNIVERSITET Statistiska institutionen 2006--28 Lösningar till SPSS-övning: Analytisk statistik Test av skillnad i medelvärden mellan två grupper Uppgift Testa om det är någon skillnad i medelvikt
ÖVNINGSUPPGIFTER KAPITEL 9
 ÖVNINGSUPPGIFTER KAPITEL 9 STOKASTISKA VARIABLER 1. Ange om följande stokastiska variabler är diskreta eller kontinuerliga: a. X = En slumpmässigt utvald person ur populationen är arbetslös, där x antar
ÖVNINGSUPPGIFTER KAPITEL 9 STOKASTISKA VARIABLER 1. Ange om följande stokastiska variabler är diskreta eller kontinuerliga: a. X = En slumpmässigt utvald person ur populationen är arbetslös, där x antar
Tentamen i Matematisk statistik Kurskod S0001M
 Tentamen i Matematisk statistik Kurskod S0001M Poäng totalt för del 1: 25 (8 uppgifter) Tentamensdatum 2012-01-13 Poäng totalt för del 2: 30 (3 uppgifter) Skrivtid 09.00 14.00 Lärare: Adam Jonsson, Ove
Tentamen i Matematisk statistik Kurskod S0001M Poäng totalt för del 1: 25 (8 uppgifter) Tentamensdatum 2012-01-13 Poäng totalt för del 2: 30 (3 uppgifter) Skrivtid 09.00 14.00 Lärare: Adam Jonsson, Ove
MSG830 Statistisk analys och experimentplanering - Lösningar
 MSG830 Statistisk analys och experimentplanering - Lösningar Tentamen 15 Januari 2015, 8:30-12:30 Examinator: Staan Nilsson, telefon 073 5599 736, kommer till tentamenslokalen 9:30 och 11:30 Tillåtna hjälpmedel:
MSG830 Statistisk analys och experimentplanering - Lösningar Tentamen 15 Januari 2015, 8:30-12:30 Examinator: Staan Nilsson, telefon 073 5599 736, kommer till tentamenslokalen 9:30 och 11:30 Tillåtna hjälpmedel:
Vad är kännetecknande för en kvalitativ respektive kvantitativ forskningsansats? Para ihop rätt siffra med rätt ansats (17p)
") Tentamen i forskningsmetodik, arbetsterapi, 2011-09-19 Vad är kännetecknande för en kvalitativ respektive kvantitativ forskningsansats? Para ihop rätt siffra med rätt ansats (17p) 1. Syftar till att uppnå
Tentamen i forskningsmetodik, arbetsterapi, 2011-09-19 Vad är kännetecknande för en kvalitativ respektive kvantitativ forskningsansats? Para ihop rätt siffra med rätt ansats (17p) 1. Syftar till att uppnå
Bild 1. Bild 2 Sammanfattning Statistik I. Bild 3 Hypotesprövning. Medicinsk statistik II
 Bild 1 Medicinsk statistik II Läkarprogrammet T5 HT 2014 Anna Jöud Arbets- och miljömedicin, Lunds universitet ERC Syd, Skånes Universitetssjukhus anna.joud@med.lu.se Bild 2 Sammanfattning Statistik I
Bild 1 Medicinsk statistik II Läkarprogrammet T5 HT 2014 Anna Jöud Arbets- och miljömedicin, Lunds universitet ERC Syd, Skånes Universitetssjukhus anna.joud@med.lu.se Bild 2 Sammanfattning Statistik I
Tentamen i Matematisk statistik Kurskod S0001M
 Tentamen i Matematisk statistik Kurskod S0001M Poäng totalt för del 1: 25 (10 uppgifter) Tentamensdatum 2013-01-18 Poäng totalt för del 2: 30 (3 uppgifter) Skrivtid 09.00 14.00 Lärare: Adam Jonsson, Ove
Tentamen i Matematisk statistik Kurskod S0001M Poäng totalt för del 1: 25 (10 uppgifter) Tentamensdatum 2013-01-18 Poäng totalt för del 2: 30 (3 uppgifter) Skrivtid 09.00 14.00 Lärare: Adam Jonsson, Ove
F14 Repetition. Måns Thulin. Uppsala universitet thulin@math.uu.se. Statistik för ingenjörer 6/3 2013 1/15
 1/15 F14 Repetition Måns Thulin Uppsala universitet thulin@math.uu.se Statistik för ingenjörer 6/3 2013 2/15 Dagens föreläsning Tentamensinformation Exempel på tentaproblem På kurshemsidan finns sex gamla
1/15 F14 Repetition Måns Thulin Uppsala universitet thulin@math.uu.se Statistik för ingenjörer 6/3 2013 2/15 Dagens föreläsning Tentamensinformation Exempel på tentaproblem På kurshemsidan finns sex gamla
Regressionsanalys. - en fråga om balans. Kimmo Sorjonen Sektionen för Psykologi Karolinska Institutet
 Regressionsanalys - en fråga om balans Kimmo Sorjonen Sektionen för Psykologi Karolinska Institutet Innehåll: 1. Enkel reg.analys 1.1. Data 1.2. Reg.linjen 1.3. Beta (β) 1.4. Signifikansprövning 1.5. Reg.
Regressionsanalys - en fråga om balans Kimmo Sorjonen Sektionen för Psykologi Karolinska Institutet Innehåll: 1. Enkel reg.analys 1.1. Data 1.2. Reg.linjen 1.3. Beta (β) 1.4. Signifikansprövning 1.5. Reg.
Föreläsning G60 Statistiska metoder
 Föreläsning 3 Statistiska metoder 1 Dagens föreläsning o Samband mellan två kvantitativa variabler Matematiska samband Statistiska samband o Korrelation Svaga och starka samband När beräkna korrelation?
Föreläsning 3 Statistiska metoder 1 Dagens föreläsning o Samband mellan två kvantitativa variabler Matematiska samband Statistiska samband o Korrelation Svaga och starka samband När beräkna korrelation?
Resultatet läggs in i ladok senast 13 juni 2014.
 Matematisk statistik Tentamen: 214 6 2 kl 14 19 FMS 35 Matematisk statistik AK för M, 7.5 hp Till Del A skall endast svar lämnas. Samtliga svar skall skrivas på ett och samma papper. Övriga uppgifter fordrar
Matematisk statistik Tentamen: 214 6 2 kl 14 19 FMS 35 Matematisk statistik AK för M, 7.5 hp Till Del A skall endast svar lämnas. Samtliga svar skall skrivas på ett och samma papper. Övriga uppgifter fordrar
Korrelation kausalitet. ˆ Y =bx +a KAPITEL 6: LINEAR REGRESSION: PREDICTION
 KAPITEL 6: LINEAR REGRESSION: PREDICTION Prediktion att estimera "poäng" på en variabel (Y), kriteriet, på basis av kunskap om "poäng" på en annan variabel (X), prediktorn. Prediktion heter med ett annat
KAPITEL 6: LINEAR REGRESSION: PREDICTION Prediktion att estimera "poäng" på en variabel (Y), kriteriet, på basis av kunskap om "poäng" på en annan variabel (X), prediktorn. Prediktion heter med ett annat
Hypotesprövning. Andrew Hooker. Division of Pharmacokinetics and Drug Therapy Department of Pharmaceutical Biosciences Uppsala University
 Hypotesprövning Andrew Hooker Division of Pharmacokinetics and Drug Therapy Department of Pharmaceutical Biosciences Uppsala University Hypotesprövning Liksom konfidensintervall ett hjälpmedel för att
Hypotesprövning Andrew Hooker Division of Pharmacokinetics and Drug Therapy Department of Pharmaceutical Biosciences Uppsala University Hypotesprövning Liksom konfidensintervall ett hjälpmedel för att
LULEÅ TEKNISKA UNIVERSITET Ämneskod S0006M Institutionen för matematik Datum 2009-12-17 Skrivtid 0900 1400
 LULEÅ TEKNISKA UNIVERSITET Ämneskod S0006M Institutionen för matematik Datum 2009-12-17 Skrivtid 0900 1400 Tentamen i: Statistik 1, 7.5 hp Antal uppgifter: 5 Krav för G: 11 Lärare: Robert Lundqvist, tel
LULEÅ TEKNISKA UNIVERSITET Ämneskod S0006M Institutionen för matematik Datum 2009-12-17 Skrivtid 0900 1400 Tentamen i: Statistik 1, 7.5 hp Antal uppgifter: 5 Krav för G: 11 Lärare: Robert Lundqvist, tel
Under denna laboration kommer regression i olika former att tas upp. Laborationen består av fyra större deluppgifter.
 Laboration 5 Under denna laboration kommer regression i olika former att tas upp. Laborationen består av fyra större deluppgifter. Deluppgift 1: Enkel linjär regression Övning Under denna uppgift ska enkel
Laboration 5 Under denna laboration kommer regression i olika former att tas upp. Laborationen består av fyra större deluppgifter. Deluppgift 1: Enkel linjär regression Övning Under denna uppgift ska enkel
36 poäng. Lägsta poäng för Godkänd 70 % av totalpoängen vilket motsvarar 25 poäng. Varje fråga är värd 2 poäng inga halva poäng delas ut.
 Vetenskaplig teori och metod Provmoment: Tentamen 3 Ladokkod: VVT012 Tentamen ges för: SSK05 VHB 7,5 högskolepoäng TentamensKod: Tentamensdatum: 2012-04-27 Tid: 09.00-11.00 Hjälpmedel: Inga hjälpmedel
Vetenskaplig teori och metod Provmoment: Tentamen 3 Ladokkod: VVT012 Tentamen ges för: SSK05 VHB 7,5 högskolepoäng TentamensKod: Tentamensdatum: 2012-04-27 Tid: 09.00-11.00 Hjälpmedel: Inga hjälpmedel
PM NÄTAVGIFTER Sammanfattning.
 PM NÄTAVGIFTER Uppdragsansvarig Anna Werner Mobil +46 (0)768184915 Fax +46 105050010 anna.werner@afconsult.com Datum Referens 2013-12-10 587822-2 (2a) Villaägarna Jakob Eliasson jakob.eliasson@villaagarna.se
PM NÄTAVGIFTER Uppdragsansvarig Anna Werner Mobil +46 (0)768184915 Fax +46 105050010 anna.werner@afconsult.com Datum Referens 2013-12-10 587822-2 (2a) Villaägarna Jakob Eliasson jakob.eliasson@villaagarna.se
Tentamen'i'TMA321'Matematisk'Statistik,'Chalmers'Tekniska'Högskola.''
 Tentamen'i'TMA321'Matematisk'Statistik,'Chalmers'Tekniska'Högskola.'' Hjälpmedel:'Valfri'räknare,'egenhändigt'handskriven'formelsamling'(4''A4Esidor'på'2'blad)' och'till'skrivningen'medhörande'tabeller.''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''
Tentamen'i'TMA321'Matematisk'Statistik,'Chalmers'Tekniska'Högskola.'' Hjälpmedel:'Valfri'räknare,'egenhändigt'handskriven'formelsamling'(4''A4Esidor'på'2'blad)' och'till'skrivningen'medhörande'tabeller.''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''
EXAMINATION KVANTITATIV METOD vt-11 (110204)
") ÖREBRO UNIVERSITET Hälsoakademin Idrott B Vetenskaplig metod EXAMINATION KVANTITATIV METOD vt-11 (110204) Examinationen består av 11 frågor, flera med tillhörande följdfrågor. Besvara alla frågor i direkt
ÖREBRO UNIVERSITET Hälsoakademin Idrott B Vetenskaplig metod EXAMINATION KVANTITATIV METOD vt-11 (110204) Examinationen består av 11 frågor, flera med tillhörande följdfrågor. Besvara alla frågor i direkt
BIOSTATISTISK GRUNDKURS, MASB11 ÖVNING 8 (2016-05-02) OCH INFÖR ÖVNING 9 (2016-05-09)
 OCH INFÖR ÖVNING 9 (2016-05-09)") LUNDS UNIVERSITET, MATEMATIKCENTRUM, MATEMATISK STATISTIK BIOSTATISTISK GRUNDKURS, MASB11 ÖVNING 8 (2016-05-02) OCH INFÖR ÖVNING 9 (2016-05-09) Aktuella avsnitt i boken är Kapitel 7. Lektionens mål: Du
LUNDS UNIVERSITET, MATEMATIKCENTRUM, MATEMATISK STATISTIK BIOSTATISTISK GRUNDKURS, MASB11 ÖVNING 8 (2016-05-02) OCH INFÖR ÖVNING 9 (2016-05-09) Aktuella avsnitt i boken är Kapitel 7. Lektionens mål: Du
Analytisk statistik. Tony Pansell, optiker Universitetslektor
 Analytisk statistik Tony Pansell, optiker Universitetslektor Analytisk statistik Att dra slutsatser från det insamlade materialet. Två metoder: 1. att generalisera från en mindre grupp mot en större grupp
Analytisk statistik Tony Pansell, optiker Universitetslektor Analytisk statistik Att dra slutsatser från det insamlade materialet. Två metoder: 1. att generalisera från en mindre grupp mot en större grupp
LTH: Fastighetsekonomi 23-24 sep 2008. Enkel och multipel linjär regressionsanalys HYPOTESPRÖVNING
 LTH: Fastighetsekonomi 23-24 sep 2008 Enkel och multipel linjär regressionsanalys HYPOTESPRÖVNING Hypotesprövning (statistisk inferensteori) Statistisk hypotesprövning innebär att man med hjälp av slumpmässiga
LTH: Fastighetsekonomi 23-24 sep 2008 Enkel och multipel linjär regressionsanalys HYPOTESPRÖVNING Hypotesprövning (statistisk inferensteori) Statistisk hypotesprövning innebär att man med hjälp av slumpmässiga
Kunskap = sann, berättigad tro (Platon) Om en person P s har en bit kunskap K så måste alltså: Lite kunskaps- och vetenskapsteori
 Om en person P s har en bit kunskap K så måste alltså: Lite kunskaps- och vetenskapsteori") Lite kunskaps- och vetenskapsteori Empiriska metoder: kvalitativa och kvantitativa Experiment och fältstudier Människor och etik 1 Kunskap = sann, berättigad tro (Platon) Om en person P s har en bit kunskap
Lite kunskaps- och vetenskapsteori Empiriska metoder: kvalitativa och kvantitativa Experiment och fältstudier Människor och etik 1 Kunskap = sann, berättigad tro (Platon) Om en person P s har en bit kunskap
Medicinsk statistik II
 Medicinsk statistik II Läkarprogrammet termin 5 VT 2013 Susanna Lövdahl, Msc, doktorand Klinisk koagulationsforskning, Lunds universitet E-post: susanna.lovdahl@med.lu.se Dagens föreläsning Fördjupning
Medicinsk statistik II Läkarprogrammet termin 5 VT 2013 Susanna Lövdahl, Msc, doktorand Klinisk koagulationsforskning, Lunds universitet E-post: susanna.lovdahl@med.lu.se Dagens föreläsning Fördjupning
Instuderingsfrågor till avsnittet om statistik, kursen Statistik och Metod, Psykologprogrammet på KI, T8
 1 Instuderingsfrågor till avsnittet om statistik, kursen Statistik och Metod, Psykologprogrammet på KI, T8 Dessa instuderingsfrågor är främst tänkta att stämma överens med innehållet i föreläsningarna,
1 Instuderingsfrågor till avsnittet om statistik, kursen Statistik och Metod, Psykologprogrammet på KI, T8 Dessa instuderingsfrågor är främst tänkta att stämma överens med innehållet i föreläsningarna,
Ur boken Självkänsla Bortom populärpsykologi och enkla sanningar
 Ur boken Bortom populärpsykologi och enkla sanningar av Magnus Lindwall, Göteborgs universitet Begreppet självkänsla har under de senaste åren fått stor uppmärksamhet i populärvetenskapliga böcker. Innehållet
Ur boken Bortom populärpsykologi och enkla sanningar av Magnus Lindwall, Göteborgs universitet Begreppet självkänsla har under de senaste åren fått stor uppmärksamhet i populärvetenskapliga böcker. Innehållet
Restid och resebeteende
 Lunds universitet Ht 2010 Nationalekonomiska institutionen Handledare: Jerker Holm Restid och resebeteende - Hur en minskning av tågets restid kan få flygresenärer att övergå till tåget. Författare: Max
Lunds universitet Ht 2010 Nationalekonomiska institutionen Handledare: Jerker Holm Restid och resebeteende - Hur en minskning av tågets restid kan få flygresenärer att övergå till tåget. Författare: Max
a) Anpassa en trinomial responsmodell med övriga relevanta variabler som (icketransformerade)
 Anpassa en trinomial responsmodell med övriga relevanta variabler som (icketransformerade)") 5:1 Studien ifråga, High School and beyond, går ut på att hitta ett samband mellan vilken typ av program generellt, praktiskt eller akademiskt som studenter väljer baserat på olika faktorer kön, ras, socioekonomisk
5:1 Studien ifråga, High School and beyond, går ut på att hitta ett samband mellan vilken typ av program generellt, praktiskt eller akademiskt som studenter väljer baserat på olika faktorer kön, ras, socioekonomisk
Övningshäfte till kursen Regressionsanalys och tidsserieanalys
 Övningshäfte till kursen Regressionsanalys och tidsserieanalys Linda Wänström October 31, 2010 1 Enkel linjär regressionsanalys (baserad på uppgift 2.3 i Andersson, Jorner, Ågren (2009)) Antag att följande
Övningshäfte till kursen Regressionsanalys och tidsserieanalys Linda Wänström October 31, 2010 1 Enkel linjär regressionsanalys (baserad på uppgift 2.3 i Andersson, Jorner, Ågren (2009)) Antag att följande
Statistik B Regressions- och tidsserieanalys Föreläsning 1
 Statistik B Regressions- och tidsserieanalys Föreläsning Kurskod: 732G7, 8 hp Lärare och examinator: Ann-Charlotte (Lotta) Hallberg Lärare och lektionsledare: Isak Hietala Labassistenter Kap 3,-3,6. Läs
Statistik B Regressions- och tidsserieanalys Föreläsning Kurskod: 732G7, 8 hp Lärare och examinator: Ann-Charlotte (Lotta) Hallberg Lärare och lektionsledare: Isak Hietala Labassistenter Kap 3,-3,6. Läs
F18 MULTIPEL LINJÄR REGRESSION, FORTS. (NCT
 Stat. teori gk, ht 006, JW F18 MULTIPEL LINJÄR REGRESSION, FORTS. (NCT 1.1, 13.1-13.6, 13.8-13.9) Modell för multipel linjär regression Modellantaganden: 1) x-värdena är fixa. ) Varje y i (i = 1,, n) är
Stat. teori gk, ht 006, JW F18 MULTIPEL LINJÄR REGRESSION, FORTS. (NCT 1.1, 13.1-13.6, 13.8-13.9) Modell för multipel linjär regression Modellantaganden: 1) x-värdena är fixa. ) Varje y i (i = 1,, n) är
Föreläsning 9. NDAB01 Statistik; teori och tillämpning i biologi
 Föreläsning 9 Statistik; teori och tillämpning i biologi 1 (kap. 20) Introduktion I föregående föreläsning diskuterades enkel linjär regression, där en oberoende variabel X förklarar variationen hos en
Föreläsning 9 Statistik; teori och tillämpning i biologi 1 (kap. 20) Introduktion I föregående föreläsning diskuterades enkel linjär regression, där en oberoende variabel X förklarar variationen hos en
Ex post facto forskning Systematisk, empirisk undersökning. om rökning så cancer?
 Metod2 Experimentell och icke experimentell forskning Ex post facto forskning Laboratorie - och fältexperiment Fältstudier Etnografiska studier Forskningsetiska aspekter 1 Ex post facto forskning Systematisk,
Metod2 Experimentell och icke experimentell forskning Ex post facto forskning Laboratorie - och fältexperiment Fältstudier Etnografiska studier Forskningsetiska aspekter 1 Ex post facto forskning Systematisk,
Tentamen i Statistik, STA A10 och STA A13 (9 poäng) 23 februari 2004, klockan 8.15-13.15
 23 februari 2004, klockan 8.15-13.15") Karlstads universitet Institutionen för informationsteknologi Avdelningen för Statistik Tentamen i Statistik, STA A och STA A3 (9 poäng) 3 februari 4, klockan 85-35 Tillåtna hjälpmedel: Bifogad formelsamling
Karlstads universitet Institutionen för informationsteknologi Avdelningen för Statistik Tentamen i Statistik, STA A och STA A3 (9 poäng) 3 februari 4, klockan 85-35 Tillåtna hjälpmedel: Bifogad formelsamling
Statistik Lars Valter
 Lars Valter LARC (Linköping Academic Research Centre) Enheten för hälsoanalys, Centrum för hälso- och vårdutveckling Statistics, the most important science in the whole world: for upon it depends the applications
Lars Valter LARC (Linköping Academic Research Centre) Enheten för hälsoanalys, Centrum för hälso- och vårdutveckling Statistics, the most important science in the whole world: for upon it depends the applications
Föreläsning 5: Att generalisera
 Föreläsning 5: Att generalisera Pär Nyman par.nyman@statsvet.uu.se 25 januari 2016-1 - Generaliseringar Generalisering innebär att vi drar slutsatser om någonting annat än det vi har studerat. Vi använder
Föreläsning 5: Att generalisera Pär Nyman par.nyman@statsvet.uu.se 25 januari 2016-1 - Generaliseringar Generalisering innebär att vi drar slutsatser om någonting annat än det vi har studerat. Vi använder
import totalt, mkr index 85,23 100,00 107,36 103,76
 1. a) F1 Kvotskala (riktiga siffror. Skillnaden mellan 3 och 5 månader är lika som skillnaden mellan 5 och 7 månader. 0 betyder att man inte haft kontakt med innovations Stockholm.) F2 Nominalskala (ingen
1. a) F1 Kvotskala (riktiga siffror. Skillnaden mellan 3 och 5 månader är lika som skillnaden mellan 5 och 7 månader. 0 betyder att man inte haft kontakt med innovations Stockholm.) F2 Nominalskala (ingen
Structural Equation Modeling med Amos Kimmo Sorjonen (2012-01-24)
") 1 Structural Equation Modeling med Amos Kimmo Sorjonen (2012-01-24) 1. Variabler och tänkt modell Data simulerar de som använts i följande studie (se Appendix A): Hull, J. G., & Mendolia, M. (1991). Modeling
1 Structural Equation Modeling med Amos Kimmo Sorjonen (2012-01-24) 1. Variabler och tänkt modell Data simulerar de som använts i följande studie (se Appendix A): Hull, J. G., & Mendolia, M. (1991). Modeling
Är sjukvården jämställd och går det åt rätt håll?
 Inledning Som titeln antyder är syftet med den här undersökningen att ta reda på om svensk hälso- och sjukvård är jämställd. Det är en fråga som kan analyseras utifrån olika perspektiv, vilka i huvudsak
Inledning Som titeln antyder är syftet med den här undersökningen att ta reda på om svensk hälso- och sjukvård är jämställd. Det är en fråga som kan analyseras utifrån olika perspektiv, vilka i huvudsak
Att lära av Pisa-undersökningen
 Att lära av Pisa-undersökningen (Lars Brandell 2008-08-02) I början av december 2007 presenterade OECD resultaten av PISA 2006, d.v.s. den internationella undersökningen av kunskapsnivån hos 15-åringar
Att lära av Pisa-undersökningen (Lars Brandell 2008-08-02) I början av december 2007 presenterade OECD resultaten av PISA 2006, d.v.s. den internationella undersökningen av kunskapsnivån hos 15-åringar
Steg 4. Lika arbeten. 10 Diskrimineringslagen
 Steg 4. Lika arbeten 10 Diskrimineringslagen [ ] Arbetsgivaren ska bedöma om förekommande löneskillnader har direkt eller indirekt samband med kön. Bedömningen ska särskilt avse skillnader mellan - Kvinnor
Steg 4. Lika arbeten 10 Diskrimineringslagen [ ] Arbetsgivaren ska bedöma om förekommande löneskillnader har direkt eller indirekt samband med kön. Bedömningen ska särskilt avse skillnader mellan - Kvinnor
Tentamen i Sannolikhetslära och statistik (lärarprogrammet) 12 februari 2011
 12 februari 2011") STOCKHOLMS UNIVERSITET MATEMATISK STATISTIK Louise af Klintberg Lösningar Tentamen i Sannolikhetslära och statistik (lärarprogrammet) 12 februari 2011 Uppgift 1 a) För att få hög validitet borde mätningarna
STOCKHOLMS UNIVERSITET MATEMATISK STATISTIK Louise af Klintberg Lösningar Tentamen i Sannolikhetslära och statistik (lärarprogrammet) 12 februari 2011 Uppgift 1 a) För att få hög validitet borde mätningarna
OBS! Vi har nya rutiner.
 KOD: Kurskod: PM2315 Kursnamn: Psykologprogrammet, kurs 15, Metoder för psykologisk forskning (15 hp) Ansvarig lärare: Jan Johansson Hanse Tentamensdatum: 14 januari 2012 Tillåtna hjälpmedel: miniräknare
KOD: Kurskod: PM2315 Kursnamn: Psykologprogrammet, kurs 15, Metoder för psykologisk forskning (15 hp) Ansvarig lärare: Jan Johansson Hanse Tentamensdatum: 14 januari 2012 Tillåtna hjälpmedel: miniräknare
k x om 0 x 1, f X (x) = 0 annars. Om Du inte klarar (i)-delen, så får konstanten k ingå i svaret. (5 p)
 = 0 annars. Om Du inte klarar (i)-delen, så får konstanten k ingå i svaret. (5 p)") Avd. Matematisk statistik TENTAMEN I SF1901 SANNOLIKHETSLÄRA OCH STATISTIK MÅNDAGEN DEN 17 AUGUSTI 2009 KL 08.00 13.00. Examinator: Gunnar Englund, tel. 790 74 16. Tillåtna hjälpmedel: Formel- och tabellsamling
Avd. Matematisk statistik TENTAMEN I SF1901 SANNOLIKHETSLÄRA OCH STATISTIK MÅNDAGEN DEN 17 AUGUSTI 2009 KL 08.00 13.00. Examinator: Gunnar Englund, tel. 790 74 16. Tillåtna hjälpmedel: Formel- och tabellsamling
Övningshäfte till kursen Regressionsanalys och tidsserieanalys
 Övningshäfte till kursen Regressionsanalys och tidsserieanalys Linda Wänström April 8, 2011 1 Enkel linjär regressionsanalys (baserad på uppgift 2.3 i Andersson, Jorner, Ågren (2009)) Antag att följande
Övningshäfte till kursen Regressionsanalys och tidsserieanalys Linda Wänström April 8, 2011 1 Enkel linjär regressionsanalys (baserad på uppgift 2.3 i Andersson, Jorner, Ågren (2009)) Antag att följande
Möjligheter och begränsningar med olika metodval
 Möjligheter och begränsningar med olika metodval Pär Nyman par.nyman@statsvet.uu.se Statskontoret 5 maj 2014-1 - Vi ska inte säga hur undersökningarna borde ha utförts. Har inte tillräcklig kännedom om
Möjligheter och begränsningar med olika metodval Pär Nyman par.nyman@statsvet.uu.se Statskontoret 5 maj 2014-1 - Vi ska inte säga hur undersökningarna borde ha utförts. Har inte tillräcklig kännedom om
Matematisk statistik allmän kurs, MASA01:B, HT-14 Laboration 2
 Lunds universitet Matematikcentrum Matematisk statistik Matematisk statistik allmän kurs, MASA01:B, HT-14 Laboration 2 Rapporten till den här laborationen skall lämnas in senast den 19e December 2014.
Lunds universitet Matematikcentrum Matematisk statistik Matematisk statistik allmän kurs, MASA01:B, HT-14 Laboration 2 Rapporten till den här laborationen skall lämnas in senast den 19e December 2014.
Föreläsning 8. NDAB02 Statistik; teori och tillämpning i biologi
 Föreläsning 8 Statistik; teori och tillämpning i biologi 1 Dagens föreläsning o Enkel linjär regression (kap 17.1 17.5) o Skatta regressionslinje (kap 17.2) o Signifikant lutning? (kap 17.3, 17.5a) o Förklaringsgrad
Föreläsning 8 Statistik; teori och tillämpning i biologi 1 Dagens föreläsning o Enkel linjär regression (kap 17.1 17.5) o Skatta regressionslinje (kap 17.2) o Signifikant lutning? (kap 17.3, 17.5a) o Förklaringsgrad
Bonusmaterial till Lära och undervisa matematik från förskoleklass till åk 6. Ledning för att lösa problemen i Övningar för kapitel 5, sid 138-144
 Bonusmaterial till Lära och undervisa matematik från förskoleklass till åk 6 Ledning för att lösa problemen i Övningar för kapitel 5, sid 138-144 Avsikten med de ledtrådar som ges nedan är att peka på
Bonusmaterial till Lära och undervisa matematik från förskoleklass till åk 6 Ledning för att lösa problemen i Övningar för kapitel 5, sid 138-144 Avsikten med de ledtrådar som ges nedan är att peka på
RödGrön-spelet Av: Jonas Hall. Högstadiet. Tid: 40-120 minuter beroende på variant Material: TI-82/83/84 samt tärningar
 Aktivitetsbeskrivning Denna aktivitet är utformat som ett spel som spelas av en grupp elever. En elev i taget agerar Gömmare och de andra är Gissare. Den som är gömmare lagrar (gömmer) tal i några av räknarens
Aktivitetsbeskrivning Denna aktivitet är utformat som ett spel som spelas av en grupp elever. En elev i taget agerar Gömmare och de andra är Gissare. Den som är gömmare lagrar (gömmer) tal i några av räknarens
Föreläsning 3 Kap 3.4, 3.6, 4.2. 732G71 Statistik B
 Föreläsning 3 Kap 3.4, 3.6, 4.2 732G71 Statistik B Exempel 150 slumpmässigt utvalda fastigheter till salu i USA Pris (y) Bostadsyta Tomtyta Antal rum Antal badrum 179000 3060 0.75 8 2 285000 2516 8.1 7
Föreläsning 3 Kap 3.4, 3.6, 4.2 732G71 Statistik B Exempel 150 slumpmässigt utvalda fastigheter till salu i USA Pris (y) Bostadsyta Tomtyta Antal rum Antal badrum 179000 3060 0.75 8 2 285000 2516 8.1 7
Främlingsfientliga attityder på arbetsmarknaden
 Umeå Universitet Institutionen för Sociologi Sociologi Främlingsfientliga attityder på arbetsmarknaden Risker för diskriminering i form av chefers attityder Elena Aronsson Kandidatuppsats 15 Hp Vårterminen
Umeå Universitet Institutionen för Sociologi Sociologi Främlingsfientliga attityder på arbetsmarknaden Risker för diskriminering i form av chefers attityder Elena Aronsson Kandidatuppsats 15 Hp Vårterminen
Statistiska analyser C2 Bivariat analys. Wieland Wermke
 + Statistiska analyser C2 Bivariat analys Wieland Wermke + Bivariat analys n Mål: Vi vill veta något om ett samband mellan två fenomen n à inom kvantitativa strategier kan man undersöka detta genom att
+ Statistiska analyser C2 Bivariat analys Wieland Wermke + Bivariat analys n Mål: Vi vill veta något om ett samband mellan två fenomen n à inom kvantitativa strategier kan man undersöka detta genom att
Vad tycker de närstående om omvårdnaden på särskilt boende?
 Omvårdnad Gävle Vad tycker de närstående om omvårdnaden på särskilt boende? November 2015 Markör AB 1 (19) Uppdrag: Beställare: Närstående särskilt boende Omvårdnad Gävle Kontaktperson beställaren: Patrik
Omvårdnad Gävle Vad tycker de närstående om omvårdnaden på särskilt boende? November 2015 Markör AB 1 (19) Uppdrag: Beställare: Närstående särskilt boende Omvårdnad Gävle Kontaktperson beställaren: Patrik
Avd. Matematisk statistik
 Avd. Matematisk statistik TENTAMEN I SF1902 SANNOLIKHETSTEORI OCH STATISTIK, TORSDAGEN DEN 23:E MAJ 2013 KL 14.00 19.00. Kursledare och examinator : Björn-Olof Skytt Tillåtna hjälpmedel: miniräknare, lathund
Avd. Matematisk statistik TENTAMEN I SF1902 SANNOLIKHETSTEORI OCH STATISTIK, TORSDAGEN DEN 23:E MAJ 2013 KL 14.00 19.00. Kursledare och examinator : Björn-Olof Skytt Tillåtna hjälpmedel: miniräknare, lathund
FÖRELÄSNINGSMATERIAL. diff SE. SE x x. Grundläggande statistik 2: KORRELATION OCH HYPOTESTESTNING. Påbyggnadskurs T1. Odontologisk profylaktik
 Grundläggande statistik Påbyggnadskurs T1 Odontologisk profylaktik FÖRELÄSNINGSMATERIAL : KORRELATION OCH HYPOTESTESTNING t diff SE x 1 diff SE x x 1 x. Analytisk statistik Regression & Korrelation Oberoende
Grundläggande statistik Påbyggnadskurs T1 Odontologisk profylaktik FÖRELÄSNINGSMATERIAL : KORRELATION OCH HYPOTESTESTNING t diff SE x 1 diff SE x x 1 x. Analytisk statistik Regression & Korrelation Oberoende
Lärare 2. Lärare 1 Binomial och normalfördelning Fel i statistiska undersökningar Att tolka undersökningar Falska samband Jämföra i tid och rum
 Lärare 2 Lärare 1 Binomial och normalfördelning Fel i statistiska undersökningar Att tolka undersökningar Falska samband Jämföra i tid och rum Lärare 2 Att utföra undersökningar Sneda statistiska underlag
Lärare 2 Lärare 1 Binomial och normalfördelning Fel i statistiska undersökningar Att tolka undersökningar Falska samband Jämföra i tid och rum Lärare 2 Att utföra undersökningar Sneda statistiska underlag
a), c), e) och g) är olikheter. Av dem har c) och g) sanningsvärdet 1.
, c), e) och g) är olikheter. Av dem har c) och g) sanningsvärdet 1.") PASS 9. OLIKHETER 9. Grundbegrepp om olikheter Vi får olikheter av ekvationer om vi byter ut likhetstecknet mot något av tecknen > (större än), (större än eller lika med), < (mindre än) eller (mindre än
PASS 9. OLIKHETER 9. Grundbegrepp om olikheter Vi får olikheter av ekvationer om vi byter ut likhetstecknet mot något av tecknen > (större än), (större än eller lika med), < (mindre än) eller (mindre än
Regressionsanalys av huspriser i Vaxholm
 Regressionsanalys av huspriser i Vaxholm Rasmus Parkinson Kandidatuppsats i matematisk statistik Bachelor Thesis in Mathematical Statistics Kandidatuppsats 2015:19 Matematisk statistik Juni 2015 www.math.su.se
Regressionsanalys av huspriser i Vaxholm Rasmus Parkinson Kandidatuppsats i matematisk statistik Bachelor Thesis in Mathematical Statistics Kandidatuppsats 2015:19 Matematisk statistik Juni 2015 www.math.su.se
Sidor i boken 110-113, 68-69 2, 3, 5, 7, 11,13,17 19, 23. Ett andragradspolynom Ett tiogradspolynom Ett tredjegradspolynom
 Sidor i boken 110-113, 68-69 Räkning med polynom Faktorisering av heltal. Att primtalsfaktorisera ett heltal innebär att uppdela heltalet i faktorer, där varje faktor är ett primtal. Ett primtal är ett
Sidor i boken 110-113, 68-69 Räkning med polynom Faktorisering av heltal. Att primtalsfaktorisera ett heltal innebär att uppdela heltalet i faktorer, där varje faktor är ett primtal. Ett primtal är ett
Utvecklingen av löneskillnader mellan statsanställda kvinnor och män åren 2000 2014
 Utvecklingen av löneskillnader mellan statsanställda kvinnor och män åren 2000 2014 Rapportserie 2015:3 Arbetsgivarverket Utvecklingen av löneskillnader mellan statsanställda kvinnor och män åren 2000
Utvecklingen av löneskillnader mellan statsanställda kvinnor och män åren 2000 2014 Rapportserie 2015:3 Arbetsgivarverket Utvecklingen av löneskillnader mellan statsanställda kvinnor och män åren 2000
Tentamen i Matematisk statistik Kurskod S0001M
 Tentamen i Matematisk statistik Kurskod S0001M Poäng totalt för del 1: 25 (9 uppgifter) Tentamensdatum 2011-10-25 Poäng totalt för del 2: 30 (3 uppgifter) Skrivtid 09.00 14.00 Lärare: Adam Jonsson, Lennart
Tentamen i Matematisk statistik Kurskod S0001M Poäng totalt för del 1: 25 (9 uppgifter) Tentamensdatum 2011-10-25 Poäng totalt för del 2: 30 (3 uppgifter) Skrivtid 09.00 14.00 Lärare: Adam Jonsson, Lennart
Variansanalys med SPSS Kimmo Sorjonen (2012-01-19)
") 1 Variansanalys med SPSS Kimmo Sorjonen (2012-01-19) 1. Envägs ANOVA för oberoende mätningar 1.1 Variabler Data simulerar det som använts i följande undersökning (se Appendix A): Petty, R. E., & Cacioppo,
1 Variansanalys med SPSS Kimmo Sorjonen (2012-01-19) 1. Envägs ANOVA för oberoende mätningar 1.1 Variabler Data simulerar det som använts i följande undersökning (se Appendix A): Petty, R. E., & Cacioppo,
Kapitel 15: INTERAKTIONER, STANDARDISERADE SKALOR OCH ICKE-LINJÄRA EFFEKTER
 Kapitel 15: INTERAKTIONER, STANDARDISERADE SKALOR OCH ICKE-LINJÄRA EFFEKTER När vi mäter en effekt i data så vill vi ofta se om denna skiljer sig mellan olika delgrupper. Vi kanske testar effekten av ett
Kapitel 15: INTERAKTIONER, STANDARDISERADE SKALOR OCH ICKE-LINJÄRA EFFEKTER När vi mäter en effekt i data så vill vi ofta se om denna skiljer sig mellan olika delgrupper. Vi kanske testar effekten av ett
Blandade problem från väg- och vattenbyggnad
 Blandade problem från väg- och vattenbyggnad Sannolikhetsteori (Kapitel 1 7) V1. Vid en undersökning av bostadsförhållanden finner man att av 300 lägenheter har 240 bad (och dusch) medan 60 har enbart
Blandade problem från väg- och vattenbyggnad Sannolikhetsteori (Kapitel 1 7) V1. Vid en undersökning av bostadsförhållanden finner man att av 300 lägenheter har 240 bad (och dusch) medan 60 har enbart
Att välja statistisk metod
 Att välja statistisk metod en översikt anpassad till kursen: Statistik och kvantitativa undersökningar 15 HP Vårterminen 2018 Lars Bohlin Innehåll Val av statistisk metod.... 2 1. Undersökning av en variabel...
Att välja statistisk metod en översikt anpassad till kursen: Statistik och kvantitativa undersökningar 15 HP Vårterminen 2018 Lars Bohlin Innehåll Val av statistisk metod.... 2 1. Undersökning av en variabel...
InStat Exempel 4 Korrelation och Regression
 InStat Exempel 4 Korrelation och Regression Vi ska analysera ett datamaterial som innehåller information om kön, längd och vikt för 2000 personer. Materialet är jämnt fördelat mellan könen (1000 män och
InStat Exempel 4 Korrelation och Regression Vi ska analysera ett datamaterial som innehåller information om kön, längd och vikt för 2000 personer. Materialet är jämnt fördelat mellan könen (1000 män och
Syftet med den här laborationen är att du skall bli mer förtrogen med följande viktiga områden inom matematisk statistik
 LUNDS TEKNISKA HÖGSKOLA MATEMATIKCENTRUM MATEMATISK STATISTIK DATORLABORATION 4 MATEMATISK STATISTIK, AK FÖR I, FMS 01, HT-07 Laboration 4: Stora talens lag, Centrala gränsvärdessatsen, enkla punktskattningar
LUNDS TEKNISKA HÖGSKOLA MATEMATIKCENTRUM MATEMATISK STATISTIK DATORLABORATION 4 MATEMATISK STATISTIK, AK FÖR I, FMS 01, HT-07 Laboration 4: Stora talens lag, Centrala gränsvärdessatsen, enkla punktskattningar
Handisam. Beräkningsunderlag för undersökningspanel
 Beräkningsunderlag för undersökningspanel Kund Mottagare Ann Dahlberg Författare Johan Bring Granskare Gösta Forsman STATISTICON AB Östra Ågatan 31 753 22 UPPSALA Wallingatan 38 111 24 STOCKHOLM vxl: 08-402
Beräkningsunderlag för undersökningspanel Kund Mottagare Ann Dahlberg Författare Johan Bring Granskare Gösta Forsman STATISTICON AB Östra Ågatan 31 753 22 UPPSALA Wallingatan 38 111 24 STOCKHOLM vxl: 08-402
Konsekvenser av indelningar i områden för redovisning av försök i svensk sortprovning. Johannes Forkman, Saeid Amiri and Dietrich von Rosen
 Konsekvenser av indelningar i områden för redovisning av försök i svensk sortprovning Johannes Forkman, Saeid Amiri and Dietrich von Rosen Swedish University of Agricultural Sciences (SLU) Department of
Konsekvenser av indelningar i områden för redovisning av försök i svensk sortprovning Johannes Forkman, Saeid Amiri and Dietrich von Rosen Swedish University of Agricultural Sciences (SLU) Department of
Bilaga 4.1 Uppskattning av antalet erforderliga provpunkter och analyser vid detaljundersökningen. Bakgrund. Metod. Konfidensintervallens utveckling
 1 (17) Bilaga 4.1 Uppskattning av antalet erforderliga provpunkter och analyser vid detaljundersökningen Nedanstående material utgick från resultatet av förundersökningen och har legat till grund för dimensioneringen
1 (17) Bilaga 4.1 Uppskattning av antalet erforderliga provpunkter och analyser vid detaljundersökningen Nedanstående material utgick från resultatet av förundersökningen och har legat till grund för dimensioneringen
Uppgift 1. Produktmomentkorrelationskoefficienten
 Uppgift 1 Produktmomentkorrelationskoefficienten Både Vikt och Längd är variabler på kvotskalan och således kvantitativa variabler. Det innebär att vi inte har så stor nytta av korstabeller om vi vill
Uppgift 1 Produktmomentkorrelationskoefficienten Både Vikt och Längd är variabler på kvotskalan och således kvantitativa variabler. Det innebär att vi inte har så stor nytta av korstabeller om vi vill
Repetitionsuppgifter i Matematik inför Basår. Matematiska institutionen Linköpings universitet 2014
 Repetitionsuppgifter i Matematik inför Basår Matematiska institutionen Linköpings universitet 04 Innehåll De fyra räknesätten Potenser och rötter 7 Algebra 0 4 Funktioner 7 Logaritmer 9 6 Facit 0 Repetitionsuppgifter
Repetitionsuppgifter i Matematik inför Basår Matematiska institutionen Linköpings universitet 04 Innehåll De fyra räknesätten Potenser och rötter 7 Algebra 0 4 Funktioner 7 Logaritmer 9 6 Facit 0 Repetitionsuppgifter