Pipeline hos ARM Cortex-A53 och ARM Cortex-A73
|
|
|
- Charlotta Gunnarsson
- för 5 år sedan
- Visningar:
Transkript
1 Lunds universitet Pipeline hos ARM Cortex-A53 och ARM Cortex-A73 Kevin Eriksson EITF60 Kursansvarig: Erik Larsson
2 Innehållsförteckning Syfte 2 Sammanfattning 2 Jämförelse 3 Pipelinebredd 3 Out of order exekvering 3 Hopprediktion 5 Slutsats 8 Referenser 9 1
3 Syfte Syftet med denna rapport är att ge en fördjupad kunskap i hur parallellism kan uppnås i processorer samt att undersöka två processorer och jämföra vilka funktioner de två processorerna har för att uppnå parallellism. Sammanfattning Under många års tid har processorer varit en stor del av människans vardag. Processorer hade sitt ursprung i PCs men har genom tiden spridit sig exponentiellt och finns idag i allt från mobiltelefoner och laptops till kylskåp och bilar. I denna rapport skall vi rikta in oss på två specifika RISC-arkitekturer av ARM, nämligen Cortex-A53 och Cortex-A73. Dessa två arkitekturer är byggda av två olika syften där den förstnämnda exempelvis är processorn i den berömda enkortsdatorn Raspberry Pi 3 vars främsta egenskap är sin mångsidighet i förhållande till sitt pris. Cortex-A73 används bland annat av Qualcomm i deras Snapdragon 835. Denna processor används i många av dagens högpresterande mobiltelefoner där kraven på prestanda är hårda. Men vad är det egentligen som skiljer sig under ytan? Vilka funktioner har de två arkitekturerna gentemot varandra? De två områden som kommer behandlas är pipelinebredd, Out-of-Order exekvering samt hopprediktion hos de båda processorerna. 2
4 Jämförelse Pipelinebredd När man använder sig av pipelining för att minska exekveringstiden för ett program är det viktigt att att ha koll på vilka faktorer som spelar roll för att minska programmets exekvering. Pipeline depth är kort beskrivet hur många samtidiga instruktioner processorn kan utföra simultant och beror på hur många steg processorn behöver gå igenom för att exekvera en instruktion. Har man exempelvis en processor med en pipeline som har ett djup på fem innebär det att fem instruktioner kan utföras simultant och att en instruktion består av fem steg. En låg pipeline depth minskar risken för eventuella hasarder men gör också att programmet kommer att ta längre tid att exekvera. En processor med möjlighet till ett stort antal samtidiga instruktioner kommer att exekvera ett program snabbare förutsatt att det inte ökar risken för hasarder. ARM Cortex-A53 använder sig av en 8-stegad pipeline vilket innebär att varje instruktion består av åtta steg och på så sätt kan åtta instruktioner utföras simultant. Detta skiljer sig från ARM Cortex-A73 som använder sig stegs pipeline beroende av vilken typ av instruktion som utförs. Detta innebär att varje instruktion kommer ta längre tid att utföra men att antalet simultana instruktioner som kan utföras är större. Både Cortex-A53 och Cortex-A73 är superskalära processorer vilket innebär att de inte bara kan utnyttja olika delar av processorn samtidigt. De kan även exempelvis utföra flera beräkningar simultant. Prestandan baseras sedan på hur många samtidiga instruktioner processorn klarar att utföra, som i sin tur baseras på andra egenskaper hos processorn. Om processorn klarar att hålla sin pipeline full, genom att exempelvis implementera en bra hopprediktion kommer detta gynna processorn och ge bättre prestanda. Klarar inte processorn att hantera det stora antalet simultana instruktioner kommer detta istället att lämna delar av processorn tom under exekveringen av ett program och ge en sämre prestanda. Det gäller alltså för tillverkaren att hitta en medelväg där så billig hårdvara som möjligt kan prestera så bra som möjligt utan att det sker fördröjningar i exekveringen. Att implementera mer resurser än vad processorn kan utnyttja är onödigt. Att Cortex-A73 kan utföra fler samtidiga instruktioner ger den en teoretiskt högre prestanda än Cortex-A53. Out of order exekvering Många operationer som utförs kan vara krävande operationer som tar lång tid att utföra och därmed stannar upp resten av exekveringen onödigt länge. Exempel på en sådan instruktion är en flyttalsberäkning som ofta kräver fler instruktionscykler för att beräknas än en addition eller subtraktion. När denna typ av instruktioner börjar användas skapar det problem för pipelinen i form av att rytmen i exekveringen bryts och stalls kommer att ske. Detta problem kan lösas genom att använda sig av en så kallar superskalär processor där flera parallella enheter som kan utföra olika instruktioner samtidigt. På så sätt kan exempelvis någon enhet för flyttalsberäkningar och någon annan för andra instruktioner implementeras vilket gör att 3
5 varje individuell pipeline utnyttjas till sin maximala kapacitet. Problemet med data-hasarder kvarstår dock fortfarande då många på varandra följande instruktioner ofta är beroende av varandra. På grund av detta kommer utnyttjandet av de andra beräkningsenheterna vara mycket låg och effektiviteten kommer inte att vara mycket högre än hos en icke-superskalär processor. Detta kan lösas med hjälp av en metod som heter Out-Of-Order exekvering vars filosofi är att instruktioner inte behöver exekveras i den följd som kompilatorn genererat. På så sätt kan alla pipelines agera individuellt genom att en fördelningsenhet avgör vilka instruktioner som kan utföras simultant. De instruktioner som dispatchern kan välja mellan kallas instruktionsfönster och är en buffert av avkodade instruktioner som fördelningsenheten kan dela ut till de olika beräkningsenheterna. Denna teknik är mycket mer komplicerad att konstruera eftersom fler konflikter behöver kunna hanteras på grund av att instruktioner inte kommer att utföras i rätt ordning. Tidigare har vi nämnt data-hasard som innebär att en instruktion vill ha resultatet från den tidigare instruktionen innan det blivit beräknat, vidare kallat True Data dependency. Med OoO uppstår två nya konflikter som faller inom samma kategori: Output dependency Anti-dependency Dessa två sker till skillnad av True Data dependency inte på grund av kompilatorn utan på grund av att instruktionerna utförs i en annan ordning än kompilatorn tänkt. Output dependency innebär att två, eller fler, instruktioner vill lagra information på samma plats samtidigt. Detta kan undvikas med en metod som kallas register renaming, vilket innebär att de man ändrar instruktionerna så att de skriver till olika register. Anti-dependency innebär att en instruktion vill läsa från ett register medans en annan instruktion skriver till samma register. Även denna konflikt kan lösas med register renaming. En processor som stödjer funktionerna nödvändiga för att lösa dessa konflikter är processor som utnyttjar sina resurser maximalt genom att antalet fördröjningar som kommer ske på grund av data-hasarder minimerats. Mer tidskrävande beräkningar kommer inte heller att hindra andra instruktioner från att exekveras. (Etsion, Y. 2013) Här skiljer sig Cortex-A53 och Cortex-A73 åt då det endast är Cortex-A73 som har Out-of-Order exekvering. Detta betyder att Cortex-A73 är en effektivare processor som, i många fall, kan exekvera program märkbart snabbare än Cortex-A53 men som kräver mer avancerad teknik för att kunna hantera de problem som uppstår med OoO exekvering. På grund av att Cortex-A73 använder sig av out-of-order exekvering kan den dra nytta av ett större antal samtidiga beräkningar vilket ger en stor prestandaskillnad mellan de två processorerna. 4
 Cortex-A53 har tre ALU enheter för heltalsberäkningar, en för hoppinstruktioner, en AGU enhet för LOAD/STORE samt en NEON enhet för flyttalsberäkningar.")
6 Cortex-A73 har två ALU enheter för heltalsberäkningar, en enhet för hoppinstruktioner, två AGU enheter för LOAD/STORE operationer och två för NEON enheter för flyttalsoperationer enligt Fig. 1. (Frumusuanu, 2016) Cortex-A53 har tre ALU enheter för heltalsberäkningar, en för hoppinstruktioner, en AGU enhet för LOAD/STORE samt en NEON enhet för flyttalsberäkningar. Antalet enheter och typerna av enheter skiljer sig mellan de två processorerna men den största skillnaden är hur många simultana instruktioner de två enheterna kan utföra. Cortex-A73 implementerar multiple issue vilket innebär att alla beräkningsenheter kan användas simultant. Cortex-A53 implementerar dual issue, dvs att endast två enheter kan användas simultant. Det hade inte varit svårt implementera multiple issue hos Cortex-A53 men som tidigare nämnt så hade ökningen i prestanda varit minimal och i förhållande till kostnaden av de ytterligare beräkningsenheterna hade gett sämre prestanda i förhållande till priset. Att implementera OoO är både dyrt och energikrävande, därför har ARM gjort allt de kan för att utnyttja alla komponenter maximalt utan att behöva implementera OoO. Det är alltså viktigt att hitta den optimala konstruktionen för att dra maximal nytta av alla komponenter. Dvs att minimera flaskhalsarna i processorn. Hopprediktion Ett stort problem som uppstår vid pipelining är att avgöra hur processorn skall agera vid hopp, dvs när instruktionen på nästa adressrad inte längre är nästa instruktion som skall exekveras. Hade situationen varit att dessa hopp med säkerhet tas hade inte effekterna på exekveringstiden varit stora men då det hos de allra flesta processorer finns villkorliga hopp. Dessa hopp är instruktioner som ofta beror på resultatet av en, eller ett par, instruktioner tidigare. På grund av att det inte går att avgöra om hoppet sker eller inte går det inte heller vara säker på vilken som är nästa instruktion som sker. På de tidiga processorerna, som implementerade pipeline, används ofta statiska beslut. Exempelvis att antogs att hoppet alltid skulle tas och tog beslutet att nästa instruktion var instruktionen dit hoppet skulle gjorts. Detta är dock en metod som skapar mycket fördröjningar eftersom fel instruktion börjat exekvera om hoppet inte skulle göras. Detta 5
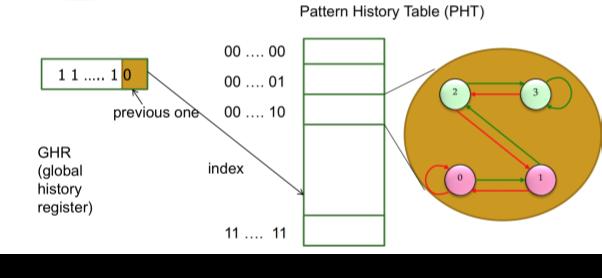
7 resulterade i tekniker för att göra bättre beslut om ett hopp kommer att göras eller inte. Dessa tekniker brukar sammanfattas som dynamiska hopprediktioner och innebär att processorn under tiden programmet exekverar på olika sätt skapar en statistik över om tidigare villkorliga hopp gjorts eller inte, för att öka träffsäkerheten på framtida prediktioner. Cortex-A73 använder sig av en teknik som kallas: Two-Level Branch prediction, dvs två-nivå hopprediktion. Denna teknik består av två nivåer och har visats mycket effektiv som teknik för hopprediktion. Tekniken går ut på att man i första nivån har en GHR (Global History Register) som är en bitsekvens som beskriver om tidigare branches har gjorts eller inte. När ett hopp sker skiftas de tidigare bitarna åt vänster för att göra plats åt resultatet från det aktuella hoppet. Längden på bitsekvensen bestäms av hur lång historik som ger den bästa prediktionen i förhållande till hur lång tid det tar att bygga upp en historik. (Lee, Malishevsky, Beck, Schmid and Landry). Denna bitsekvens används senare som address i Pattern History Table, vidare kallat PHT. PHT är en tabell vars rader, entries, består av en adress samt två bitar som beskriver om hoppet skall tas eller inte. Dessa två bitar agerar som ett skiftregister vars tillstånd bestämmer om ett hopp kommer att tas eller inte. De två bitarna symboliserar följande fyra tillstånd: 00: Hoppet kommer med hög säkerhet inte att tas 01: Hoppet kommer förmodligen inte tas 10: Hoppet kommer förmodligen att tas 11: Hoppet kommer med hög säkerhet att tas Beroende av vilket tillstånd registret befinner sig i gör processorn ett beslut vilket med hög sannolikhet kommer stämma när programmet som exekverar beter sig enligt ett mönster. När processorn tagit ett beslut så uppdateras registret beroende av om antagandet var korrekt eller inte enligt Fig.2 där röda pilar symboliserar att hoppet inte togs och gröna pilar symboliserar att hoppet togs. Detta för att kunna göra en mer kvalificerad prediktering nästa gång GHR ser likadant ut. Det finns dock en nackdel till denna teknik. Det tar relativt lång tid för PHT att byggas upp vilket innebär att det kommer att ske många fördröjningar tidigt i exekveringen eftersom en bra predikteringshistorik inte har byggts upp (Mutlu, O 2013) ARM Cortex-A73 använder sig av en PHT med 256 Entries vilket innebär att dess BGH består av 8 bitar för att kunna adressera de 256 entries som finns. Detta innebär att BGH innehåller information om vad som hänt vid de senaste 8 hoppen. Varje unikt fall av de 256 möjligheterna har två bitar som beskriver hur hoppet skall hanteras enligt Fig. 2. Denna teknik implementeras inte av ARM Cortex-A53 då det är en kostsam teknik. Den använder sig istället av en conditional and indirect branching. (Driesen and Hölzle 1997) Detta är en teknik som till viss del kan liknas vid two-level prediction. Man använder sig av samma typ av PHT för att kunna avgöra vilka tidigare hopp som gjorts men man saknar det tvåbitars skiftregister som finns i Cortex-A73, vilket innebär att dess prediktioner inte kommer vara lika precisa som hos Cortex-A73. 6
8 7
9 Slutsats ARM Cortex-A73 och Cortex-A53 är två mycket olika processorer där den förstnämnda prioriterar prestanda och den sistnämnda prioriterar effektivitet och kostnad. De två egenskaper som behandlats i denna rapport behandlar parallellism och hantering av hopp. Skillnaden i teoretisk prestanda mellan de två jämförda processorerna är stor då parallellism och hopp är två av de funktioner som ger störst prestandaskillnad i en processor. Att Cortex-A73 använder sig av en two-level branch prediction gör den överlägsen Cortex-A53 när det gäller exekveringstid i program där frekventa hopp sker, exempelvis i program där mycket loopar förekommer eller där samma metoder anropas frekvent. Den är också, i de flesta fall, överlägsen på att hantera många processer parallellt då den kan exekvera beräkningar OoO och på så sätt kan utnyttja hela sin pipeline. Men all denna prestanda kommer till ett pris. Den extra kostnaden hos Cortex-A73 kommer rättfärdiga sig i enheter där kostnaden inte är den viktigaste faktorn utan där maximal prestanda prioriteras. Ett praktexempel på detta är Qualcomm Snapdragon 835 som tillhör företagets prestanda-inriktade serie och exempelvis används i många telefontillverkares flaggskeppsenheter. Då är det viktigaste att kunna exekvera dessa funktioner parallellt och att användaren får en så sömlös användarupplevelse som möjligt. Motsatsen till detta är exempelvis Raspberry Pi 3 som vill ha maximal prestanda för en så liten kostnad som möjligt, där det inte spelar så stor roll om ett program exekverar långsammare så länge det håller kostanden nere. Det finns även andra faktorer som spelar in på en processors prestanda vilket inte har behandlats i denna rapport. 8
10 Referenser Driesen, K. and Hölzle, U. (1997). Limits of Indirect Branch Prediction. Techincal Report TRCS Santa Barbara, CA 93106: Department of Computer Science, University of California. Prof. Lee, B. Malishevsky, A. Beck, D. Schmid, A. and Landry, E. Dynamic Branch Prediction. ECE 570 High Performance Computer Architecture. Department of Computer Engineering, Oregon State Univerity. Prof. Mutlu, O. (2013). Lecture 11: Branch Prediction Computer Architecture. Carnegie Mellon Univerity -branch-prediction-afterlecture.pdf Frumusanu, A. and Smith, R. (2015). ARM A53/A57/T760 investigated - Samsung Galaxy Note 4 Exynos Review. Anandtech.com. [Hämtad 23 Nov. 2017]. Frumusanu, A. (2016). The ARM Cortex A73 - Artemis Unveiled. Anandtech.com. [Hämtad 23 Nov. 2017] Etsion, Y Out-of-order exekvering. Computer Engineering 9
Lunds Tekniska Högskola Datorarkitektur med operativsystem EITF60. Superscalar vs VLIW. Cornelia Kloth IDA2. Inlämningsdatum:
 Lunds Tekniska Högskola Datorarkitektur med operativsystem EITF60 Superscalar vs VLIW Cornelia Kloth IDA2 Inlämningsdatum: 2018-12-05 Abstract Rapporten handlar om två tekniker inom multiple issue processorer
Lunds Tekniska Högskola Datorarkitektur med operativsystem EITF60 Superscalar vs VLIW Cornelia Kloth IDA2 Inlämningsdatum: 2018-12-05 Abstract Rapporten handlar om två tekniker inom multiple issue processorer
Tentamen den 18 mars svar Datorteknik, EIT070
 Lunds Universitet LTH Tentamen den 18 mars 2015 - svar Datorteknik, EIT070 Skrivtid: 14.00-19.00 Tillåtna hjälpmedel: Inga. Maximalt antal poäng: 50 poäng För betyg 3 krävs 20 poäng För betyg 4 krävs 30
Lunds Universitet LTH Tentamen den 18 mars 2015 - svar Datorteknik, EIT070 Skrivtid: 14.00-19.00 Tillåtna hjälpmedel: Inga. Maximalt antal poäng: 50 poäng För betyg 3 krävs 20 poäng För betyg 4 krävs 30
Hantering av hazards i pipelines
 Datorarkitektur med operativsystem Hantering av hazards i pipelines Lisa Arvidsson IDA2 Inlämningsdatum: 2018-12-05 Abstract En processor som använder pipelining kan exekvera ett flertal instruktioner
Datorarkitektur med operativsystem Hantering av hazards i pipelines Lisa Arvidsson IDA2 Inlämningsdatum: 2018-12-05 Abstract En processor som använder pipelining kan exekvera ett flertal instruktioner
Datorarkitekturer med operativsystem ERIK LARSSON
 Datorarkitekturer med operativsystem ERIK LARSSON Dator Primärminne Instruktioner och data Data/instruktioner Kontroll Central processing unit (CPU) Fetch instruction Execute instruction Programexekvering
Datorarkitekturer med operativsystem ERIK LARSSON Dator Primärminne Instruktioner och data Data/instruktioner Kontroll Central processing unit (CPU) Fetch instruction Execute instruction Programexekvering
Pipelining i Intel Pentium II
 Pipelining i Intel Pentium II John Abdulnoor Lund Universitet 04/12/2017 Abstract För att en processor ska fungera måste alla komponenter inuti den samarbeta för att nå en acceptabel nivå av prestanda.
Pipelining i Intel Pentium II John Abdulnoor Lund Universitet 04/12/2017 Abstract För att en processor ska fungera måste alla komponenter inuti den samarbeta för att nå en acceptabel nivå av prestanda.
Närliggande allokering Datorteknik
 Närliggande allokering Datorteknik ERIK LARSSON TID Problem: Minnet blir fragmenterat Paging Demand paging Sida (S) Dela upp primärminnet i ramar (frames) och program i sidor (pages) Program 0 RD.0 1 RD.1
Närliggande allokering Datorteknik ERIK LARSSON TID Problem: Minnet blir fragmenterat Paging Demand paging Sida (S) Dela upp primärminnet i ramar (frames) och program i sidor (pages) Program 0 RD.0 1 RD.1
Effektivitetsmätning av multitrådning på ARM Cortex-A53 mikroarkitektur
 Lunds universitet Effektivitetsmätning av multitrådning på ARM Cortex-A53 mikroarkitektur Johan Hermansson EITF60 Kursansvarig: Erik Larsson 4 december 2017 Sammanfattning I projektet utvecklades multitrådad
Lunds universitet Effektivitetsmätning av multitrådning på ARM Cortex-A53 mikroarkitektur Johan Hermansson EITF60 Kursansvarig: Erik Larsson 4 december 2017 Sammanfattning I projektet utvecklades multitrådad
Arm Cortex-A8 Pipeline
 Marcus Havrell Dahl - 941206 Arm Cortex-A8 Pipeline Sammanfattning Arm Cortex-A8 processorn är en energisnål men samtidigt kraftfull enhet. Beroende på implementationen kan den ha en klockhastighet på
Marcus Havrell Dahl - 941206 Arm Cortex-A8 Pipeline Sammanfattning Arm Cortex-A8 processorn är en energisnål men samtidigt kraftfull enhet. Beroende på implementationen kan den ha en klockhastighet på
Spekulativ exekvering i CPU pipelining
 Spekulativ exekvering i CPU pipelining Max Faxälv Datum: 2018-12-05 1 Abstrakt Speculative execution is an optimisation technique used by modern-day CPU's to guess which path a computer code will take,
Spekulativ exekvering i CPU pipelining Max Faxälv Datum: 2018-12-05 1 Abstrakt Speculative execution is an optimisation technique used by modern-day CPU's to guess which path a computer code will take,
LUNDS UNIVERSITET. Parallell exekvering av Float32 och INT32 operationer
 LUNDS UNIVERSITET Parallell exekvering av Float32 och INT32 operationer Samuel Molin Kursansvarig: Erik Larsson Datum 2018-12-05 Referat Grafikkort utför många liknande instruktioner parallellt då typiska
LUNDS UNIVERSITET Parallell exekvering av Float32 och INT32 operationer Samuel Molin Kursansvarig: Erik Larsson Datum 2018-12-05 Referat Grafikkort utför många liknande instruktioner parallellt då typiska
Datorteknik ERIK LARSSON
 Datorteknik ERIK LARSSON Så här långt. FÖ2 RISC/CISC FÖ1 Primärminne Instruktioner och data Address Instruction 00001000 0000101110001011 00001001 0001101110000011 00001010 0010100000011011 00001011 0001001110010011
Datorteknik ERIK LARSSON Så här långt. FÖ2 RISC/CISC FÖ1 Primärminne Instruktioner och data Address Instruction 00001000 0000101110001011 00001001 0001101110000011 00001010 0010100000011011 00001011 0001001110010011
Parallellism i CDC 7600, pipelinens ursprung
 Lunds universitet Parallellism i CDC 7600, pipelinens ursprung Henrik Norrman EITF60 Datorarkitekturer med operativsystem Kursansvarig: Erik Larsson 4 december 2017 INNEHÅLL Parallellism i CDC 7600 Innehåll
Lunds universitet Parallellism i CDC 7600, pipelinens ursprung Henrik Norrman EITF60 Datorarkitekturer med operativsystem Kursansvarig: Erik Larsson 4 december 2017 INNEHÅLL Parallellism i CDC 7600 Innehåll
Datorteknik ERIK LARSSON
 Datorteknik ERIK LARSSON Programexekvering (1) Hämta instruktion på 00001000 (där PC pekar) Fetch (2) Flytta instruktionen 0000101110001011 till CPU (3) Avkoda instruktionen: 00001 MOVE, 01110001 Adress,
Datorteknik ERIK LARSSON Programexekvering (1) Hämta instruktion på 00001000 (där PC pekar) Fetch (2) Flytta instruktionen 0000101110001011 till CPU (3) Avkoda instruktionen: 00001 MOVE, 01110001 Adress,
Tentamen den 14 januari 2015 Datorarkitekturer med operativsystem, EDT621, 7,5 poäng
 Lunds Universitet LTH Ingenjörshögskolan, Helsingborg Tentamen den 14 januari 2015 Datorarkitekturer med operativsystem, EDT621, 7,5 poäng Skrivtid: 08.00-13.00 Tillåtna hjälpmedel: Inga. Maximalt antal
Lunds Universitet LTH Ingenjörshögskolan, Helsingborg Tentamen den 14 januari 2015 Datorarkitekturer med operativsystem, EDT621, 7,5 poäng Skrivtid: 08.00-13.00 Tillåtna hjälpmedel: Inga. Maximalt antal
Datorteknik ERIK LARSSON
 Datorteknik ERIK LARSSON Fetch-Execute Utan pipelining: Tid: 1 2 3 4 5 6 Instruktion 1 Instruktion 2 Instruktion 3 Fetch Execute Fetch Execute Fetch Execute Med pipelining: Tid: 1 2 3 4 Instruktion 1 Instruktion
Datorteknik ERIK LARSSON Fetch-Execute Utan pipelining: Tid: 1 2 3 4 5 6 Instruktion 1 Instruktion 2 Instruktion 3 Fetch Execute Fetch Execute Fetch Execute Med pipelining: Tid: 1 2 3 4 Instruktion 1 Instruktion
Superscalar Bra: Hårdvaran löser allt: Hårdvara detekterar poten6ell parallellism av instruk6oner Hårdvara försöker starta exekvering (issue) av så
 av så") 1 Superscalar Bra: Hårdvaran löser allt: Hårdvara detekterar poten6ell parallellism av instruk6oner Hårdvara försöker starta exekvering (issue) av så många instruk6oner som möjligt parallellt Hårdvara
1 Superscalar Bra: Hårdvaran löser allt: Hårdvara detekterar poten6ell parallellism av instruk6oner Hårdvara försöker starta exekvering (issue) av så många instruk6oner som möjligt parallellt Hårdvara
Hantering av hazards i multi-pipelines
 Campus Helsingborg IDA2 Hantering av hazards i multi-pipelines Av: Mounir Salam Abstract Det finns tre olika problem som kan uppstå när vi kör en pipeline med flera steg. De tre problemen även så kallade
Campus Helsingborg IDA2 Hantering av hazards i multi-pipelines Av: Mounir Salam Abstract Det finns tre olika problem som kan uppstå när vi kör en pipeline med flera steg. De tre problemen även så kallade
Hur det går att minska effektutvecklingen i en processor genom att ändra pipeline
 Hur det går att minska effektutvecklingen i en processor genom att ändra pipeline Linda Wapner HT2018 EITF60 Sammanfattning Effektutvecklingen i en processor har länge ökat genom att klockfrekvensen för
Hur det går att minska effektutvecklingen i en processor genom att ändra pipeline Linda Wapner HT2018 EITF60 Sammanfattning Effektutvecklingen i en processor har länge ökat genom att klockfrekvensen för
CDC en jämförelse mellan superskalära processorer. EDT621 Campus Helsingborg av: Marcus Karlsson IDA
 CDC6600 - en jämförelse mellan superskalära processorer av: Marcus Karlsson Sammanfattning I denna rapport visas konkret information om hur den första superskalära processorn såg ut och hur den använde
CDC6600 - en jämförelse mellan superskalära processorer av: Marcus Karlsson Sammanfattning I denna rapport visas konkret information om hur den första superskalära processorn såg ut och hur den använde
SVAR TILL TENTAMEN I DATORSYSTEM, VT2013
 Rahim Rahmani (rahim@dsv.su.se) Division of ACT Department of Computer and Systems Sciences Stockholm University SVAR TILL TENTAMEN I DATORSYSTEM, VT2013 Tentamensdatum: 2013-03-21 Tentamen består av totalt
Rahim Rahmani (rahim@dsv.su.se) Division of ACT Department of Computer and Systems Sciences Stockholm University SVAR TILL TENTAMEN I DATORSYSTEM, VT2013 Tentamensdatum: 2013-03-21 Tentamen består av totalt
Hyper Threading Intels implementation av SMT. Datorarkitekturer med operativsystem - EITF60. Felix Danielsson IDA2
 Hyper Threading Intels implementation av SMT Datorarkitekturer med operativsystem - EITF60 Felix Danielsson IDA2 Sammanfattning Simultaneous multithreading (SMT) är en teknik som används i processorer
Hyper Threading Intels implementation av SMT Datorarkitekturer med operativsystem - EITF60 Felix Danielsson IDA2 Sammanfattning Simultaneous multithreading (SMT) är en teknik som används i processorer
Datorarkitekturer med operativsystem ERIK LARSSON
 Datorarkitekturer med operativsystem ERIK LARSSON Pipelining Tid SSA P Pipelining FI DI CO FO EI WO FI DI CO FO EI WO FI DI CO FO EI WO FI DI CO FO EI WO Superscalar pipelining FI DI CO FO EI WO FI DI
Datorarkitekturer med operativsystem ERIK LARSSON Pipelining Tid SSA P Pipelining FI DI CO FO EI WO FI DI CO FO EI WO FI DI CO FO EI WO FI DI CO FO EI WO Superscalar pipelining FI DI CO FO EI WO FI DI
Fetch-Execute. Datorteknik. Pipelining. Pipeline diagram (vid en viss tidpunkt)
") Datorteknik ERIK LRSSON Fetch- Utan pipelining: Tid: 1 2 3 4 5 6 Instruktion 1 Instruktion 2 Instruktion 3 Fetch Fetch Fetch Med pipelining: Tid: 1 2 3 4 Instruktion 1 Instruktion 2 Instruktion 3 Fetch
Datorteknik ERIK LRSSON Fetch- Utan pipelining: Tid: 1 2 3 4 5 6 Instruktion 1 Instruktion 2 Instruktion 3 Fetch Fetch Fetch Med pipelining: Tid: 1 2 3 4 Instruktion 1 Instruktion 2 Instruktion 3 Fetch
Svar till tentamen den 16 december 2013 Datorarkitekturer med operativsystem, EDT621, 7,5 poäng
 Lunds Universitet LTH Ingenjörshögskolan, Helsingborg Svar till tentamen den 16 december 2013 Datorarkitekturer med operativsystem, EDT621, 7,5 poäng Skrivtid: 08.00-13.00 Tillåtna hjälpmedel: Inga. Maximalt
Lunds Universitet LTH Ingenjörshögskolan, Helsingborg Svar till tentamen den 16 december 2013 Datorarkitekturer med operativsystem, EDT621, 7,5 poäng Skrivtid: 08.00-13.00 Tillåtna hjälpmedel: Inga. Maximalt
Datorarkitekturer med operativsystem ERIK LARSSON
 Datorarkitekturer med operativsystem ERIK LARSSON Översikt Reduced instruction set computers (RISC) Superscalar processors Semantic gap Alltmer avancerade programmeringsspråk tas fram för att göra programvaruutveckling
Datorarkitekturer med operativsystem ERIK LARSSON Översikt Reduced instruction set computers (RISC) Superscalar processors Semantic gap Alltmer avancerade programmeringsspråk tas fram för att göra programvaruutveckling
Datorarkitekturer med operativsystem ERIK LARSSON
 Datorarkitekturer med operativsystem ERIK LARSSON Semantic gap Alltmer avancerade programmeringsspråk tas fram för att göra programvaruutveckling mer kraftfull Dessa programmeringsspråk (Ada, C++, Java)
Datorarkitekturer med operativsystem ERIK LARSSON Semantic gap Alltmer avancerade programmeringsspråk tas fram för att göra programvaruutveckling mer kraftfull Dessa programmeringsspråk (Ada, C++, Java)
Digitala System: Datorteknik ERIK LARSSON
 Digitala System: Datorteknik ERIK LARSSON Dator Primärminne Instruktioner och data Data/instruktioner Kontroll Central processing unit (CPU) Fetch instruction Execute instruction Programexekvering (1)
Digitala System: Datorteknik ERIK LARSSON Dator Primärminne Instruktioner och data Data/instruktioner Kontroll Central processing unit (CPU) Fetch instruction Execute instruction Programexekvering (1)
Tentamen den 17 mars 2016 Datorteknik, EIT070
 Lunds Universitet LTH Tentamen den 17 mars 2016 Datorteknik, EIT070 Skrivtid: 14.00-19.00 Tillåtna hjälpmedel: Inga. Maximalt antal poäng: 50 poäng För betyg 3 krävs 20 poäng För betyg 4 krävs 30 poäng
Lunds Universitet LTH Tentamen den 17 mars 2016 Datorteknik, EIT070 Skrivtid: 14.00-19.00 Tillåtna hjälpmedel: Inga. Maximalt antal poäng: 50 poäng För betyg 3 krävs 20 poäng För betyg 4 krävs 30 poäng
En Von Neumann-arkitektur ( Von Neumann-principen i föreläsning 1) innebär:
 innebär:") Lösningsförslag för 725G45-tentan 3/11-10 1. Vad menas med Von Neumann-arkitektur? (2p) En Von Neumann-arkitektur ( Von Neumann-principen i föreläsning 1) innebär: Data och instruktioner lagras i samma
Lösningsförslag för 725G45-tentan 3/11-10 1. Vad menas med Von Neumann-arkitektur? (2p) En Von Neumann-arkitektur ( Von Neumann-principen i föreläsning 1) innebär: Data och instruktioner lagras i samma
Processor pipelining genom historien (Intel i9-intel i7)
") Processor pipelining genom historien (Intel i9-intel i7) Besnik Redzepi Lunds Universitet Abstrakt/Sammanfattning Syftet med denna uppsats är att jämföra Intels nya generation processorer och deras pipelining.
Processor pipelining genom historien (Intel i9-intel i7) Besnik Redzepi Lunds Universitet Abstrakt/Sammanfattning Syftet med denna uppsats är att jämföra Intels nya generation processorer och deras pipelining.
TSEA28 Datorteknik Y (och U)
") Praktiska kommentarer TSEA8 Datorteknik Y (och U) Föreläsning Kent Palmkvist, ISY Dagens föreläsning RISC Mer information om hur arkitekturen fungerar Begränsningar Lab extra tillfälle för redovisning
Praktiska kommentarer TSEA8 Datorteknik Y (och U) Föreläsning Kent Palmkvist, ISY Dagens föreläsning RISC Mer information om hur arkitekturen fungerar Begränsningar Lab extra tillfälle för redovisning
TSEA28 Datorteknik Y (och U)
") Praktiska kommentarer TSEA8 Datorteknik Y (och U) Föreläsning Kent Palmkvist, ISY Dagens föreläsning Latens/genomströmning Pipelining Laboration tips Sorteringsalgoritm använder A > B i flödesschemat Exemplet
Praktiska kommentarer TSEA8 Datorteknik Y (och U) Föreläsning Kent Palmkvist, ISY Dagens föreläsning Latens/genomströmning Pipelining Laboration tips Sorteringsalgoritm använder A > B i flödesschemat Exemplet
Pipelining i RISC-processorn. Joakim Lindström Institutionen för informationsbehandling Åbo Akademi E-post: jolindst@abo.fi
 Pipelining i RISC-processorn Joakim Lindström Institutionen för informationsbehandling Åbo Akademi E-post: jolindst@abo.fi Innehållsförteckning 1. Inledning 2. Historia: Intel 8086 (1978) till Pentium
Pipelining i RISC-processorn Joakim Lindström Institutionen för informationsbehandling Åbo Akademi E-post: jolindst@abo.fi Innehållsförteckning 1. Inledning 2. Historia: Intel 8086 (1978) till Pentium
Multi-ported cache En rapport om några lösningar till att få flera minnesaccesser simultant.
 Multi-ported cache En rapport om några lösningar till att få flera minnesaccesser simultant. Sammanfattning När processorns klockhastighet ökar medför det en ökning av instruktioner vilket såklart ökar
Multi-ported cache En rapport om några lösningar till att få flera minnesaccesser simultant. Sammanfattning När processorns klockhastighet ökar medför det en ökning av instruktioner vilket såklart ökar
Exempeltentamen Datorteknik, EIT070,
 Lunds Universitet LTH Exempeltentamen Datorteknik, EIT070, Skrivtid: xx.00-xx.00 Tillåtna hjälpmedel: Inga. Maximalt antal poäng: 50 poäng För betyg 3 krävs 20 poäng För betyg 4 krävs 30 poäng För betyg
Lunds Universitet LTH Exempeltentamen Datorteknik, EIT070, Skrivtid: xx.00-xx.00 Tillåtna hjälpmedel: Inga. Maximalt antal poäng: 50 poäng För betyg 3 krävs 20 poäng För betyg 4 krävs 30 poäng För betyg
Digitala System: Datorteknik ERIK LARSSON
 Digitala System: Datorteknik ERIK LARSSON Huvudled (H) Trafikljus för övergångsställe Trafikljus för huvudled (H) Trafikljus: Sväng vänster (H->T) Gående - vänta Trafikljus för tvärgata (T) Tvärgata (T)
Digitala System: Datorteknik ERIK LARSSON Huvudled (H) Trafikljus för övergångsställe Trafikljus för huvudled (H) Trafikljus: Sväng vänster (H->T) Gående - vänta Trafikljus för tvärgata (T) Tvärgata (T)
Hyper-Threading i Intelprocessorer
 Lunds Tekniska Högskola Campus Helsingborg DATORARKITEKTURER MED OPERATIVSYSTEM EITF60 RAPPORT Hyper-Threading i Intelprocessorer 4 december 2017 Rasmus Hanning IDA2 Sammanfattning Det har sedan den första
Lunds Tekniska Högskola Campus Helsingborg DATORARKITEKTURER MED OPERATIVSYSTEM EITF60 RAPPORT Hyper-Threading i Intelprocessorer 4 december 2017 Rasmus Hanning IDA2 Sammanfattning Det har sedan den första
Parallellism i NVIDIAs Fermi GPU
 Parallellism i NVIDIAs Fermi GPU Thien Lai Phu IDA2 Abstract This report investigates what kind of computer architecture, based on Flynn s taxonomy, is used on NVIDIAs Fermi-based GPU to achieve parallellism
Parallellism i NVIDIAs Fermi GPU Thien Lai Phu IDA2 Abstract This report investigates what kind of computer architecture, based on Flynn s taxonomy, is used on NVIDIAs Fermi-based GPU to achieve parallellism
Tentamen den 14 januari 2016 Datorarkitektur med operativsystem, EDT621
 Lunds Universitet LTH Tentamen den 14 januari 2016 Datorarkitektur med operativsystem, EDT621 Skrivtid: 08.00-13.00 Tillåtna hjälpmedel: Inga. Maximalt antal poäng: 50 poäng För betyg 3 krävs 20 poäng
Lunds Universitet LTH Tentamen den 14 januari 2016 Datorarkitektur med operativsystem, EDT621 Skrivtid: 08.00-13.00 Tillåtna hjälpmedel: Inga. Maximalt antal poäng: 50 poäng För betyg 3 krävs 20 poäng
Datormodell. Datorns uppgifter -Utföra program (instruktioner) Göra beräkningar på data Flytta data Interagera med omvärlden
 Göra beräkningar på data Flytta data Interagera med omvärlden") Datormodell Datorns uppgifter -Utföra program (instruktioner) Göra beräkningar på data Flytta data Interagera med omvärlden Intel 4004 från 1971 Maximum clock speed is 740 khz Separate program and data
Datormodell Datorns uppgifter -Utföra program (instruktioner) Göra beräkningar på data Flytta data Interagera med omvärlden Intel 4004 från 1971 Maximum clock speed is 740 khz Separate program and data
SIMD i Intel s P5- baserade Pentium MMX
 SIMD i Intel s P5- baserade Pentium MMX Maurits Gabriel Johansson - IDA2 Datorarkitekturer med operativsystem - 4 december 2016 SIMD I INTEL S P5-BASERADE PENTIUM MMX 1 Abstrakt Moderna CPU s (Central
SIMD i Intel s P5- baserade Pentium MMX Maurits Gabriel Johansson - IDA2 Datorarkitekturer med operativsystem - 4 december 2016 SIMD I INTEL S P5-BASERADE PENTIUM MMX 1 Abstrakt Moderna CPU s (Central
Tentamen den 12 januari 2017 Datorarkitektur med operativsystem, EDT621
 Lunds Universitet LTH Tentamen den 12 januari 2017 Datorarkitektur med operativsystem, EDT621 Skrivtid: 8.00-13.00 Inga tillåtna hjälpmedel Uppgifterna i tentamen ger maximalt 60 poäng. Uppgifterna är
Lunds Universitet LTH Tentamen den 12 januari 2017 Datorarkitektur med operativsystem, EDT621 Skrivtid: 8.00-13.00 Inga tillåtna hjälpmedel Uppgifterna i tentamen ger maximalt 60 poäng. Uppgifterna är
DEC Alpha instruktions Arkitektur
 DEC Alpha instruktions Arkitektur David Ekberg December 4, 2017 Innehållsförteckning 1 Sammanfattning...3 2 Bakgrund...3 3 Syfte...3 4 Pipeline...4 4.1 Datatyper...4 4.2 Instruktions arkitektur...5 5 Slutsats...6
DEC Alpha instruktions Arkitektur David Ekberg December 4, 2017 Innehållsförteckning 1 Sammanfattning...3 2 Bakgrund...3 3 Syfte...3 4 Pipeline...4 4.1 Datatyper...4 4.2 Instruktions arkitektur...5 5 Slutsats...6
Moment 2 Digital elektronik. Föreläsning Inbyggda system, introduktion
 Moment 2 Digital elektronik Föreläsning Inbyggda system, introduktion Jan Thim 1 Inbyggda system, introduktion Innehåll: Historia Introduktion Arkitekturer Mikrokontrollerns delar 2 1 Varför lär vi oss
Moment 2 Digital elektronik Föreläsning Inbyggda system, introduktion Jan Thim 1 Inbyggda system, introduktion Innehåll: Historia Introduktion Arkitekturer Mikrokontrollerns delar 2 1 Varför lär vi oss
Datorsystem 2 CPU. Förra gången: Datorns historia Denna gång: Byggstenar i en dators arkitektur. Visning av Akka (för de som är intresserade)
") Datorsystem 2 CPU Förra gången: Datorns historia Denna gång: Byggstenar i en dators arkitektur CPU Visning av Akka (för de som är intresserade) En dators arkitektur På en lägre nivå kan vi ha lite olika
Datorsystem 2 CPU Förra gången: Datorns historia Denna gång: Byggstenar i en dators arkitektur CPU Visning av Akka (för de som är intresserade) En dators arkitektur På en lägre nivå kan vi ha lite olika
Datorsystemteknik DVGA03 Föreläsning 8
 Datorsystemteknik DVGA03 Föreläsning 8 Processorns uppbyggnad Pipelining Större delen av materialet framtaget av :Jan Eric Larsson, Mats Brorsson och Mirec Novak IT-inst LTH Innehåll Repetition av instruktionsformat
Datorsystemteknik DVGA03 Föreläsning 8 Processorns uppbyggnad Pipelining Större delen av materialet framtaget av :Jan Eric Larsson, Mats Brorsson och Mirec Novak IT-inst LTH Innehåll Repetition av instruktionsformat
IBM POWER4, den första flerkärniga processorn och dess pipelines.
 IBM POWER4, den första flerkärniga processorn och dess pipelines. 5 DECEMBER 2016 FÖRFATTARE: OSCAR STRANDMARK EXAMINATOR: ERIK LARSSON Abstract Rapporten redovisar IBM:s POWER-serie, generation ett till
IBM POWER4, den första flerkärniga processorn och dess pipelines. 5 DECEMBER 2016 FÖRFATTARE: OSCAR STRANDMARK EXAMINATOR: ERIK LARSSON Abstract Rapporten redovisar IBM:s POWER-serie, generation ett till
Anujan Balasingam IDA14 NAND flashminnen
 Anujan Balasingam IDA14 NAND flashminnen Hur kan prestandan och kapaciteten förbättras? Kursansvarig: Erik Larsson Datorarkitektur med operativsystem 7,5 hp 04-12-2015 Innehållsförteckning 1. Inledning...
Anujan Balasingam IDA14 NAND flashminnen Hur kan prestandan och kapaciteten förbättras? Kursansvarig: Erik Larsson Datorarkitektur med operativsystem 7,5 hp 04-12-2015 Innehållsförteckning 1. Inledning...
Pipelining i Intel 80486
 Lunds Universitet Pipelining i Intel 80486 EITF60 Datorarkitekturer med operativsystem Martin Wiezell 2017-12-04 Abstract This paper gives a brief description of the instruction pipeline of the Intel 80486
Lunds Universitet Pipelining i Intel 80486 EITF60 Datorarkitekturer med operativsystem Martin Wiezell 2017-12-04 Abstract This paper gives a brief description of the instruction pipeline of the Intel 80486
Vad bör göras? Steg 1. RISC => pipelining. Parallellism. Pipelining. Nya LDA 13. RISC(reduced instruction set computer) Öka klockfrekvensen
 Öka klockfrekvensen") Föreläsning 11 OR-datorn är för långsam! Alternativa arkitekturer kritik av OR-datorn RISC => pipelining LDA 13 (exempelvis) Hämta : 3CP 2 1 CP Absolut,1: 3 CP EXE: 4 CP Summa: 11 CP mem ADR XR SP DR TR
Föreläsning 11 OR-datorn är för långsam! Alternativa arkitekturer kritik av OR-datorn RISC => pipelining LDA 13 (exempelvis) Hämta : 3CP 2 1 CP Absolut,1: 3 CP EXE: 4 CP Summa: 11 CP mem ADR XR SP DR TR
TENTAMEN Datorteknik (DO2005) D1/E1/Mek1/Ö1
 D1/E1/Mek1/Ö1") Halmstad University School of Information Science, Computer and Electrical Engineering Tomas Nordström, CC-lab TENTAMEN Datorteknik (DO2005) D1/E1/Mek1/Ö1 Datum: 2012-05- 23 Tid och plats: 9:00 13:00 i
Halmstad University School of Information Science, Computer and Electrical Engineering Tomas Nordström, CC-lab TENTAMEN Datorteknik (DO2005) D1/E1/Mek1/Ö1 Datum: 2012-05- 23 Tid och plats: 9:00 13:00 i
Öka prestanda i Shared-Cache multi-core processorer
 Öka prestanda i Shared-Cache multi-core processorer 1. Abstract Många processorer har nuförtiden flera kärnor. Det är även vanligt att dessa kärnor delar på högsta nivås cachen för att förbättra prestandan.
Öka prestanda i Shared-Cache multi-core processorer 1. Abstract Många processorer har nuförtiden flera kärnor. Det är även vanligt att dessa kärnor delar på högsta nivås cachen för att förbättra prestandan.
MESI i Intel Core 2 Duo
 MESI i Intel Core 2 Duo Sammanfattning Denna rapport beskriver en processor (Intel Core 2 Duo) vars cache coherence protokoll är MESI. Rapporten beskriver hur processorn är uppbyggd, hur många kärnor den
MESI i Intel Core 2 Duo Sammanfattning Denna rapport beskriver en processor (Intel Core 2 Duo) vars cache coherence protokoll är MESI. Rapporten beskriver hur processorn är uppbyggd, hur många kärnor den
Utvecklingen från en 8 bitars till en 16 bitars mikroprocessor
 Utvecklingen från en 8 bitars till en 16 bitars mikroprocessor Sammanfattning: Utvecklingen från processor till processor är inte lätt. Det finns många beslut som måste tas när det gäller kompatibilitet,
Utvecklingen från en 8 bitars till en 16 bitars mikroprocessor Sammanfattning: Utvecklingen från processor till processor är inte lätt. Det finns många beslut som måste tas när det gäller kompatibilitet,
Datorteknik. Föreläsning 6. Processorns uppbyggnad, pipelining. Institutionen för elektro- och informationsteknologi, LTH. Mål
 Datorteknik Föreläsning 6 Processorns uppbyggnad, pipelining Mål Att du ska känna till hur processorn byggs upp Att du ska kunna de viktigaste byggstenarna i processorn Att du ska känna till begreppet
Datorteknik Föreläsning 6 Processorns uppbyggnad, pipelining Mål Att du ska känna till hur processorn byggs upp Att du ska kunna de viktigaste byggstenarna i processorn Att du ska känna till begreppet
Grundläggande datavetenskap, 4p
 Grundläggande datavetenskap, 4p Kapitel 2 Datamanipulation, Processorns arbete Utgående från boken Computer Science av: J. Glenn Brookshear 2004-11-09 IT och Medier 1 Innehåll CPU ALU Kontrollenhet Register
Grundläggande datavetenskap, 4p Kapitel 2 Datamanipulation, Processorns arbete Utgående från boken Computer Science av: J. Glenn Brookshear 2004-11-09 IT och Medier 1 Innehåll CPU ALU Kontrollenhet Register
IT för personligt arbete F5
 IT för personligt arbete F5 Datalogi del 1 DSV Peter Mozelius 1 En dators beståndsdelar 1) Minne 2) Processor 3) Inmatningsenheter 1) tangentbord 2) scanner 3) mus 4) Utmatningsenheter 1) bildskärm 2)
IT för personligt arbete F5 Datalogi del 1 DSV Peter Mozelius 1 En dators beståndsdelar 1) Minne 2) Processor 3) Inmatningsenheter 1) tangentbord 2) scanner 3) mus 4) Utmatningsenheter 1) bildskärm 2)
TSEA28 Datorteknik Y (och U)
") TSEA28 Datorteknik Y (och U), föreläsning 14, Kent Palmkvist 2018-05-14 3 Praktiska kommentarer TSEA28 Datorteknik Y (och U) Föreläsning 15 Kent Palmkvist, ISY Lab 4 extra tillfälle för redovisning Tisdag
TSEA28 Datorteknik Y (och U), föreläsning 14, Kent Palmkvist 2018-05-14 3 Praktiska kommentarer TSEA28 Datorteknik Y (och U) Föreläsning 15 Kent Palmkvist, ISY Lab 4 extra tillfälle för redovisning Tisdag
Datorteknik. Tomas Nordström. Föreläsning 2. För utveckling av verksamhet, produkter och livskvalitet.
 Datorteknik Tomas Nordström Föreläsning 2 För utveckling av verksamhet, produkter och livskvalitet. Föreläsning 2 Check av övningar Von Neumann arkitekturen Minne, CPU, I/O Instruktioner och instruktionscykeln
Datorteknik Tomas Nordström Föreläsning 2 För utveckling av verksamhet, produkter och livskvalitet. Föreläsning 2 Check av övningar Von Neumann arkitekturen Minne, CPU, I/O Instruktioner och instruktionscykeln
Program kan beskrivas på olika abstrak3onsnivåer. Högnivåprogram: läsbart (för människor), hög abstrak3onsnivå, enkelt a> porta (fly>a 3ll en annan ar
, hög abstrak3onsnivå, enkelt a> porta (fly>a 3ll en annan ar") 1 Program kan beskrivas på olika abstrak3onsnivåer. Högnivåprogram: läsbart (för människor), hög abstrak3onsnivå, enkelt a> porta (fly>a 3ll en annan arkitektur), hårdvara osynlig Assembly- och maskinprogram:
1 Program kan beskrivas på olika abstrak3onsnivåer. Högnivåprogram: läsbart (för människor), hög abstrak3onsnivå, enkelt a> porta (fly>a 3ll en annan arkitektur), hårdvara osynlig Assembly- och maskinprogram:
Andreas Ehliar
 En casestudy i processordesign (Eller konsten att dissekera en 68000) Andreas Ehliar Informationskällor US patent 4325121 Two level Control Store for Microprogrammed Data processor
En casestudy i processordesign (Eller konsten att dissekera en 68000) Andreas Ehliar Informationskällor US patent 4325121 Two level Control Store for Microprogrammed Data processor
Tentamen Datorteknik D del 2, TSEA49
 Tentamen Datorteknik D del 2, TSEA49 Datum 2012-05-24 Lokal TER2 Tid 8-12 Kurskod TSEA49 Provkod TEN1 Kursnamn Datorteknik D del 2 Institution ISY Antal frågor 6 Antal sidor (inklusive denna 10 sida) Kursansvarig
Tentamen Datorteknik D del 2, TSEA49 Datum 2012-05-24 Lokal TER2 Tid 8-12 Kurskod TSEA49 Provkod TEN1 Kursnamn Datorteknik D del 2 Institution ISY Antal frågor 6 Antal sidor (inklusive denna 10 sida) Kursansvarig
Tentamen den 9 januari 2018 Datorarkitekturer med operativsystem (EITF60)
") Lunds Universitet LTH Tentamen den 9 januari 2018 Datorarkitekturer med operativsystem (EITF60) Skrivtid: 08.00-13.00 Tillåtna hjälpmedel: Inga. Maximalt antal poäng: 50 poäng För betyg 3 krävs 20 poäng
Lunds Universitet LTH Tentamen den 9 januari 2018 Datorarkitekturer med operativsystem (EITF60) Skrivtid: 08.00-13.00 Tillåtna hjälpmedel: Inga. Maximalt antal poäng: 50 poäng För betyg 3 krävs 20 poäng
Tentamen i Digitala system - EITA15 15hp varav denna tentamen 4,5hp
 Tentamen i Digitala system EITA5 5hp varav denna tentamen 4,5hp Institutionen för elektro och informationsteknik Campus Helsingborg, LTH 289 8. 3. (förlängd 4.) Uppgifterna i tentamen ger totalt 6 poäng.
Tentamen i Digitala system EITA5 5hp varav denna tentamen 4,5hp Institutionen för elektro och informationsteknik Campus Helsingborg, LTH 289 8. 3. (förlängd 4.) Uppgifterna i tentamen ger totalt 6 poäng.
Prestanda och skalbarhet
 Prestanda och skalbarhet Grama et al. Introduction to Parallel Computing Kapitel 5 Erik Elmroth Översikt 2 Exekveringstid Uppsnabbning Effektivitet Kostnad Kostnadsoptimal algoritm Ahmdals lag Gustafson-Barsis
Prestanda och skalbarhet Grama et al. Introduction to Parallel Computing Kapitel 5 Erik Elmroth Översikt 2 Exekveringstid Uppsnabbning Effektivitet Kostnad Kostnadsoptimal algoritm Ahmdals lag Gustafson-Barsis
Tentamen i Digitala system - EITA15 15hp varav denna tentamen 4,5hp
 Tentamen i Digitala system - EITA15 15hp varav denna tentamen 4,5hp Institutionen för elektro- och informationsteknik Campus Helsingborg, LTH 2018-01-09 8.00-13.00 (förlängd 14.00) Uppgifterna i tentamen
Tentamen i Digitala system - EITA15 15hp varav denna tentamen 4,5hp Institutionen för elektro- och informationsteknik Campus Helsingborg, LTH 2018-01-09 8.00-13.00 (förlängd 14.00) Uppgifterna i tentamen
Jämförelse av skrivtekniker till cacheminne
 Jämförelse av skrivtekniker till cacheminne 1 Innehåll 1. Sammanfattning 2. Inledning 3. Diskussion 4. Referenslista 1. Sammanfattning En rapport innehållande jämförelser av olika skrivtekniker till minnen
Jämförelse av skrivtekniker till cacheminne 1 Innehåll 1. Sammanfattning 2. Inledning 3. Diskussion 4. Referenslista 1. Sammanfattning En rapport innehållande jämförelser av olika skrivtekniker till minnen
Prestandapåverkan på databashanterare av flertrådiga processorer. Jesper Dahlgren
 Prestandapåverkan på databashanterare av flertrådiga processorer av Sammanfattning Behandling av information bli vanligare i dagens samhälle och för att klara denna uppgiften används ofta en databashanterare
Prestandapåverkan på databashanterare av flertrådiga processorer av Sammanfattning Behandling av information bli vanligare i dagens samhälle och för att klara denna uppgiften används ofta en databashanterare
DatorsystemteknikDAVA14 Föreläsning 9
 DatorsystemteknikDAVA14 Föreläsning 9 epetition: MP likainstruktioneri Exempel på instruktionstyper Processorns uppbyggnad Pipelining törre delen av materialet framtaget av :Jan Eric Larsson, Mats Brorsson
DatorsystemteknikDAVA14 Föreläsning 9 epetition: MP likainstruktioneri Exempel på instruktionstyper Processorns uppbyggnad Pipelining törre delen av materialet framtaget av :Jan Eric Larsson, Mats Brorsson
Grunderna i stegkodsprogrammering
 Kapitel 1 Grunderna i stegkodsprogrammering Följande bilaga innehåller grunderna i stegkodsprogrammering i den form som används under kursen. Vi kommer att kort diskutera olika datatyper, villkor, operationer
Kapitel 1 Grunderna i stegkodsprogrammering Följande bilaga innehåller grunderna i stegkodsprogrammering i den form som används under kursen. Vi kommer att kort diskutera olika datatyper, villkor, operationer
Introduktion till ARM Cortex-M4
 Introduktion till ARM Cortex-M4 Ur innehållet: Historik - ARM ARM/Thumb instruktionsuppsättning Register Adresseringssätt 1 ARM Tidiga datorer Programmering av inbyggda system 1979 Acorn Computers Acorn
Introduktion till ARM Cortex-M4 Ur innehållet: Historik - ARM ARM/Thumb instruktionsuppsättning Register Adresseringssätt 1 ARM Tidiga datorer Programmering av inbyggda system 1979 Acorn Computers Acorn
Tentamen i Digitala system - EDI610 15hp varav denna tentamen 4,5hp
 Tentamen i Digitala system - EDI610 15hp varav denna tentamen 4,5hp Institutionen för elektro- och informationsteknik Campus Helsingborg, LTH 2016-12-22 8.00-13.00 Uppgifterna i tentamen ger totalt 60
Tentamen i Digitala system - EDI610 15hp varav denna tentamen 4,5hp Institutionen för elektro- och informationsteknik Campus Helsingborg, LTH 2016-12-22 8.00-13.00 Uppgifterna i tentamen ger totalt 60
Datorarkitekturer med operativsystem ERIK LARSSON
 Datorarkitekturer med operativsystem ERIK LARSSON Parallellberäkning Konstant behov av högre prestanda Prestanda har uppnåtts genom: Utveckling inom halvledarteknik Tekniker som:» Cacheminne» Flera bussar»
Datorarkitekturer med operativsystem ERIK LARSSON Parallellberäkning Konstant behov av högre prestanda Prestanda har uppnåtts genom: Utveckling inom halvledarteknik Tekniker som:» Cacheminne» Flera bussar»
Cacheminne i en Intel Core 2 Duo-processor
 Peter Hesslow EDT621 Cacheminne i en Intel Core 2 Duo-processor Abstrakt Det finns många olika sätt att bygga upp ett datorminne på, och med en flerkärnig processor så blir alternativen ännu fler. Denna
Peter Hesslow EDT621 Cacheminne i en Intel Core 2 Duo-processor Abstrakt Det finns många olika sätt att bygga upp ett datorminne på, och med en flerkärnig processor så blir alternativen ännu fler. Denna
4. Pipelining. 4. Pipelining
 4. Pipelining 4. Pipelining Det finns en pipelinad biltvätt i Linköping spoltvätttork spoltvätt tork spolning tvätt tork De tre momenten tar lika lång tid Alla bilar går igenom samma program Väntetid 1/3
4. Pipelining 4. Pipelining Det finns en pipelinad biltvätt i Linköping spoltvätttork spoltvätt tork spolning tvätt tork De tre momenten tar lika lång tid Alla bilar går igenom samma program Väntetid 1/3
AVR 3 - datorteknik. Avbrott. Digitala system 15 hp. Förberedelser
 Namn: Laborationen godkänd: Digitala system 15 hp AVR 3 - datorteknik LTH Ingenjörshögskolan vid Campus Helsingborg Avbrott. Syften med den här laborationen är att introducera avbrott. Avbrott som uppkommer
Namn: Laborationen godkänd: Digitala system 15 hp AVR 3 - datorteknik LTH Ingenjörshögskolan vid Campus Helsingborg Avbrott. Syften med den här laborationen är att introducera avbrott. Avbrott som uppkommer
Multithreading in Intel Pentium 4 - Hyperthreading
 Multithreading in Intel Pentium 4 - Hyperthreading Sammanfattning Hyper-threading är en implementation av SMT(Simultaneous Multithreading) teknologi som används på Intel processorer. Implementationen användes
Multithreading in Intel Pentium 4 - Hyperthreading Sammanfattning Hyper-threading är en implementation av SMT(Simultaneous Multithreading) teknologi som används på Intel processorer. Implementationen användes
TSEA28 Datorteknik Y (och U)
") TSEA28 Datorteknik Y (och U), föreläsning 15, Kent Palmkvist 2016-05-16 2 TSEA28 Datorteknik Y (och U) Föreläsning 15 Kent Palmkvist, ISY Praktiska kommentarer Lab 4 extratillfälle idag 16/5 kl 15-17 Med
TSEA28 Datorteknik Y (och U), föreläsning 15, Kent Palmkvist 2016-05-16 2 TSEA28 Datorteknik Y (och U) Föreläsning 15 Kent Palmkvist, ISY Praktiska kommentarer Lab 4 extratillfälle idag 16/5 kl 15-17 Med
TSEA28 Datorteknik Y (och U)
") TSEA28 Datorteknik Y (och U), föreläsning 16, Kent Palmkvist 2018-05-21 3 Dagens föreläsning TSEA28 Datorteknik Y (och U) Föreläsning 16 Kent Palmkvist, ISY Mer avancerade sätt att öka prestanda Applikationsspecifika
TSEA28 Datorteknik Y (och U), föreläsning 16, Kent Palmkvist 2018-05-21 3 Dagens föreläsning TSEA28 Datorteknik Y (och U) Föreläsning 16 Kent Palmkvist, ISY Mer avancerade sätt att öka prestanda Applikationsspecifika
32 Bitar Blir 64 Sammanfattning
 32 Bitar Blir 64 Sammanfattning Syftet med rapporten är att ge en insyn i det tillvägagångssätt och problem som uppstod i utvecklingen från 32 bitars CPUs till 64 bitars CPUs samt inblick i skillnaden
32 Bitar Blir 64 Sammanfattning Syftet med rapporten är att ge en insyn i det tillvägagångssätt och problem som uppstod i utvecklingen från 32 bitars CPUs till 64 bitars CPUs samt inblick i skillnaden
SVAR TILL TENTAMEN I DATORSYSTEM, HT2013
 Rahim Rahmani (rahim@dsv.su.se) Division of SAS Department of Computer and Systems Sciences Stockholm University SVAR TILL TENTAMEN I DATORSYSTEM, HT2013 Tentamensdatum: 2013-10-30 Tentamen består av totalt
Rahim Rahmani (rahim@dsv.su.se) Division of SAS Department of Computer and Systems Sciences Stockholm University SVAR TILL TENTAMEN I DATORSYSTEM, HT2013 Tentamensdatum: 2013-10-30 Tentamen består av totalt
Besvara de elektroniska frågorna (se kurshemsidan). Läs kapitel i kursbok.
. Läs kapitel i kursbok.") Namn: Laborationen godkänd: Laboration 3. Pipeline Laborationens syfte I laborationen ska du bekanta dig med pipelining. Genom laborationen fås kunskap om hur pipelines är konstruerade och hur de används.
Namn: Laborationen godkänd: Laboration 3. Pipeline Laborationens syfte I laborationen ska du bekanta dig med pipelining. Genom laborationen fås kunskap om hur pipelines är konstruerade och hur de används.
Datorsystemteknik för E/D
 Tentamen i kursen Datorsystemteknik (EDA330 för D och EDA370 för E) 19/8 2000 1(8) Tentamen i kursen Datorsystemteknik (EDA330 för D och EDA370 för E) Datorsystemteknik för E/D 19/8 2000 Tentamensdatum:
Tentamen i kursen Datorsystemteknik (EDA330 för D och EDA370 för E) 19/8 2000 1(8) Tentamen i kursen Datorsystemteknik (EDA330 för D och EDA370 för E) Datorsystemteknik för E/D 19/8 2000 Tentamensdatum:
General Purpose registers ALU I T H S V N Z C SREG. Antag att vi behöver skriva in talet 25 till register R18
 F3 Föreläsning i Mikrodatorteknink 2006-08-29 Kärnan i microcontrollern består av ett antal register och en ALU. Till detta kommer också ett antal portar. Det finns 64 st portar. Några är anslutna mot
F3 Föreläsning i Mikrodatorteknink 2006-08-29 Kärnan i microcontrollern består av ett antal register och en ALU. Till detta kommer också ett antal portar. Det finns 64 st portar. Några är anslutna mot
Omtentamen i CDT204 - Datorarkitektur
 Omtentamen i CDT204 - Datorarkitektur 2012-11-05 Skrivtid: 08.10-12.30 Hjälpmedel: Miniräknare och valfritt skriftligt (ej digitalt) material. Lärare: Stefan Bygde, kan nås på 070-619 52 83. Tentamen är
Omtentamen i CDT204 - Datorarkitektur 2012-11-05 Skrivtid: 08.10-12.30 Hjälpmedel: Miniräknare och valfritt skriftligt (ej digitalt) material. Lärare: Stefan Bygde, kan nås på 070-619 52 83. Tentamen är
INSTITUTIONEN FÖR DATA- OCH INFORMATIONSTEKNIK
 INSTITUTIONEN FÖR DATA- OCH INFORMATIONSTEKNIK DIT162 Realtidssystem, 7,5 högskolepoäng Real-Time Systems, 7.5 credits Fastställande Kursplanen är fastställd av Institutionen för data- och informationsteknik
INSTITUTIONEN FÖR DATA- OCH INFORMATIONSTEKNIK DIT162 Realtidssystem, 7,5 högskolepoäng Real-Time Systems, 7.5 credits Fastställande Kursplanen är fastställd av Institutionen för data- och informationsteknik
HF0010. Introduktionskurs i datateknik 1,5 hp
 HF0010 Introduktionskurs i datateknik 1,5 hp Välkommna - till KTH, Haninge, Datateknik, kursen och till första steget mot att bli programmerare! Er lärare och kursansvarig: Nicklas Brandefelt, bfelt@kth.se
HF0010 Introduktionskurs i datateknik 1,5 hp Välkommna - till KTH, Haninge, Datateknik, kursen och till första steget mot att bli programmerare! Er lärare och kursansvarig: Nicklas Brandefelt, bfelt@kth.se
Tenta i Digitalteknik
 Tenta i Digitalteknik Kurskod D0011E Tentamensdatum 2011-08-26 Skrivtid 9.00-14.00 Maximalt resultat 50 poäng Godkänt resultat 25 poäng Jourhavande lärare Per Lindgren Tel 070 376 8150 Tillåtna hjälpmedel
Tenta i Digitalteknik Kurskod D0011E Tentamensdatum 2011-08-26 Skrivtid 9.00-14.00 Maximalt resultat 50 poäng Godkänt resultat 25 poäng Jourhavande lärare Per Lindgren Tel 070 376 8150 Tillåtna hjälpmedel
Tentamen. Datorteknik Y, TSEA28
 Tentamen Datorteknik Y, TSEA28 Datum 2016-05-31 Lokal Kåra, T1, T2, U1, U15 Tid 14-18 Kurskod TSEA28 Provkod TEN1 Kursnamn Provnamn Datorteknik Y Skriftlig tentamen Institution ISY Antal frågor 6 Antal
Tentamen Datorteknik Y, TSEA28 Datum 2016-05-31 Lokal Kåra, T1, T2, U1, U15 Tid 14-18 Kurskod TSEA28 Provkod TEN1 Kursnamn Provnamn Datorteknik Y Skriftlig tentamen Institution ISY Antal frågor 6 Antal
Emil Kristiansson Kurs: EDT621 Delmoment: Rapport. En introduktion till Smart cache
 En introduktion till Smart cache 1 Sammanfattning Syftet med den här rapporten är att ge en introduktion till tekniken smart cache för läsaren. Smart cache är en teknik som låter de olika cacheminnena
En introduktion till Smart cache 1 Sammanfattning Syftet med den här rapporten är att ge en introduktion till tekniken smart cache för läsaren. Smart cache är en teknik som låter de olika cacheminnena
Föreläsningsanteckningar 5. Cacheminnen
 Föreläsningsanteckningar 5. Cacheminnen Olle Seger 2012 Anders Nilsson 2016 1 Inledning Bakgrunden till att cacheminnen behövs för nästan alla datorer är enkel. Vi kan kallt räkna med att processorn är
Föreläsningsanteckningar 5. Cacheminnen Olle Seger 2012 Anders Nilsson 2016 1 Inledning Bakgrunden till att cacheminnen behövs för nästan alla datorer är enkel. Vi kan kallt räkna med att processorn är
Snapdragon 810: Cacheminnet
 Snapdragon 810: Cacheminnet Daniel Eckerström dat14dec@student.lu.se Sammanfattnig Snapdragon 810 innehåller två olika processor arkitekturer, ARM Cortex-A53 samt Cortex-A57. Detta för att kunna på ett
Snapdragon 810: Cacheminnet Daniel Eckerström dat14dec@student.lu.se Sammanfattnig Snapdragon 810 innehåller två olika processor arkitekturer, ARM Cortex-A53 samt Cortex-A57. Detta för att kunna på ett
TSEA28 Datorteknik Y (och U)
") TSEA28 Datorteknik Y (och U), föreläsning 16, Kent Palmkvist 2019-05-16 3 TSEA28 Datorteknik Y (och U) Föreläsning 16 Kent Palmkvist, ISY Praktiska kommentarer Lab 1-3 redovisningstillfälle Fredag 24/5
TSEA28 Datorteknik Y (och U), föreläsning 16, Kent Palmkvist 2019-05-16 3 TSEA28 Datorteknik Y (och U) Föreläsning 16 Kent Palmkvist, ISY Praktiska kommentarer Lab 1-3 redovisningstillfälle Fredag 24/5
BILAGA. till. Kommissionens delegerade förordning
 EUROPEISKA KOMMISSIONEN Bryssel den 26.9.2017 C(2017) 6321 final ANNEX 1 PART 6/11 BILAGA till Kommissionens delegerade förordning om ändring av rådets förordning (EG) nr 428/2009 om upprättande av en
EUROPEISKA KOMMISSIONEN Bryssel den 26.9.2017 C(2017) 6321 final ANNEX 1 PART 6/11 BILAGA till Kommissionens delegerade förordning om ändring av rådets förordning (EG) nr 428/2009 om upprättande av en
GRUNDER I VHDL. Innehåll. Komponentmodell Kodmodell Entity Architecture Identifierare och objekt Operationer för jämförelse
 GRUNDER I VHDL Innehåll Komponentmodell Kodmodell Entity Architecture Identifierare och objekt Operationer för jämförelse KOMPONENTMODELL Modell för att beskriva komponenter Externt interface Intern funktion
GRUNDER I VHDL Innehåll Komponentmodell Kodmodell Entity Architecture Identifierare och objekt Operationer för jämförelse KOMPONENTMODELL Modell för att beskriva komponenter Externt interface Intern funktion
En något mer detaljerad bild av en processor. De tre delarna i processorn är: Nere 3ll vänster finns e' antal register som används för a' lagra data.
 1 3 4 Antag a' processorn ska exekvera instruk3onen ADD R1, R3. När instruk3onen är exekverad så a' processorn tagit innehållet i R1 och R3 och med hjälp av ALU:n är värdena adderade och resultatet är
1 3 4 Antag a' processorn ska exekvera instruk3onen ADD R1, R3. När instruk3onen är exekverad så a' processorn tagit innehållet i R1 och R3 och med hjälp av ALU:n är värdena adderade och resultatet är
En något mer detaljerad bild av en processor. De tre delarna i processorn är: Nere 3ll vänster finns e' antal register som används för a' lagra data.
 1 2 3 Antag a' processorn ska exekvera instruk3onen ADD R1, R3. När instruk3onen är exekverad så a' processorn tagit innehållet i R1 och R3 och med hjälp av ALU:n är värdena adderade och resultatet är
1 2 3 Antag a' processorn ska exekvera instruk3onen ADD R1, R3. När instruk3onen är exekverad så a' processorn tagit innehållet i R1 och R3 och med hjälp av ALU:n är värdena adderade och resultatet är
Henrik Asp. Allt du behöver veta för att KÖPA DATOR
 Allt du behöver veta för att KÖPA DATOR Henrik Asp DEL 1 KOMPONENTER OCH PROGRAMVARA DEL 3 EFTER KÖPET 1. INTRODUKTION TILL BOKEN... 3 2. DATORNS HISTORIA... 4 A. Pc...5 B. Mac...6 C. HTPC...7 3. DATORNS
Allt du behöver veta för att KÖPA DATOR Henrik Asp DEL 1 KOMPONENTER OCH PROGRAMVARA DEL 3 EFTER KÖPET 1. INTRODUKTION TILL BOKEN... 3 2. DATORNS HISTORIA... 4 A. Pc...5 B. Mac...6 C. HTPC...7 3. DATORNS
F2: Motorola Arkitektur. Assembler vs. Maskinkod Exekvering av instruktioner i Instruktionsformat MOVE instruktionen
 68000 Arkitektur F2: Motorola 68000 I/O signaler Processor arkitektur Programmeringsmodell Assembler vs. Maskinkod Exekvering av instruktioner i 68000 Instruktionsformat MOVE instruktionen Adresseringsmoder
68000 Arkitektur F2: Motorola 68000 I/O signaler Processor arkitektur Programmeringsmodell Assembler vs. Maskinkod Exekvering av instruktioner i 68000 Instruktionsformat MOVE instruktionen Adresseringsmoder
0.1. INTRODUKTION 1. 2. Instruktionens opcode decodas till en språknivå som är förstålig för ALUn.
 0.1. INTRODUKTION 1 0.1 Introduktion Datorns klockfrekvens mäts i cykler per sekund, eller hertz. En miljon klockcykler är en megahertz, MHz. L1 cache (level 1) är den snabbaste formen av cache och sitter
0.1. INTRODUKTION 1 0.1 Introduktion Datorns klockfrekvens mäts i cykler per sekund, eller hertz. En miljon klockcykler är en megahertz, MHz. L1 cache (level 1) är den snabbaste formen av cache och sitter